Самостоятельное обучение - Предварительные Задачи
🎙️ Ishan MisraИстории успеха обучения с учителем: Предварительная тренировка (Pre-training)
На протяжении последнего десятилетия одним из главных рецептов успеха для различных задач Компьютерного Зрения было получение визуальных представлений применяя методы обучения с учителем для ImageNet классификации. Затем эти представления или веса модели использовали для инициализации других задач Компьютерного Зрения для которых существует нехватка тренировочных данных.
Однако получение аннотаций для набора данных масштаба ImageNet занимает очень много времени и это достаточно дорого. К примеру: для разметки 14 миллионов изображений из ImageNet потребовалось примерно 22 человеко-года.
Поэтому сообщество начало искать альтернативные способы разметки, такие как хэштеги для изображений в социальных сетях, GPS локации или подходы самостоятельного обучения, когда метка является свойством самой выборки данных.
Но перед поиском альтернативных процессов разметки возникает важный вопрос:
Как много размеченных данных мы вообще можем получить?
- Если мы ищем все изображения с категориями на уровне объекта и аннотациями ограничивающих рамок, то получим примерно 1 миллион изображений.
- Теперь, если ослабить ограничение на координаты ограничивающей рамки, количество доступных изображений увеличится приблизительно до 14 миллионов.
- Однако, если рассматривать все изображения, доступные в Интернете, количество доступных данных увеличивается на 5 порядков.
- Кроме того, есть данные, помимо изображений, которые требуют вовлечение других сенсоров для их понимания.
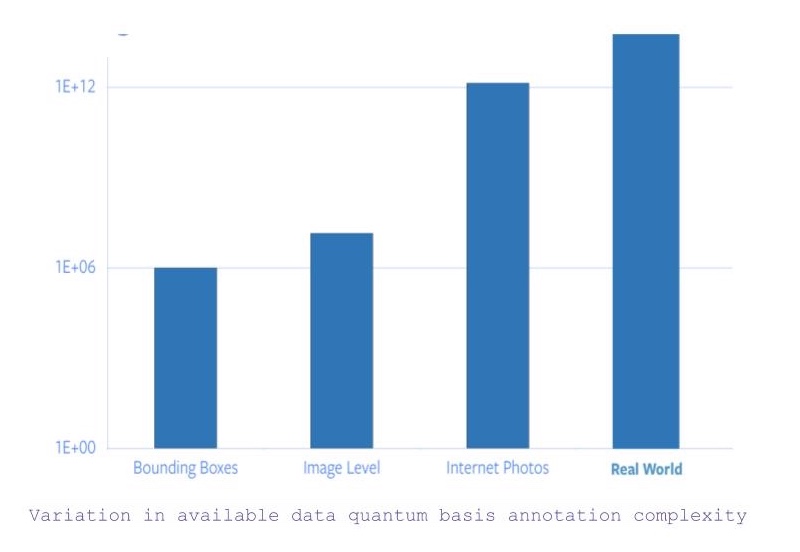
Рисунок 1: Количество данных и сложность их разметки
Следовательно, исходя из того факта, что одна только аннотация ImageNet заняла 22 человеческих года, масштабирование разметки для всех фотографий в Интернете или за его пределами совершенно невозможно.
Проблема редких концепций (Проблема длинного хвоста)
В целом график распределения меток для изображений в Интернете выглядит как длинный хвост. То есть большинство изображений соответствуют очень немногим меткам, тогда как существует большое количество меток, для которых присутствует немного изображений. Таким образом, получение аннотированных выборок для категорий ближе к концу хвоста требует маркировки огромных объемов данных из-за характера распределения категорий.
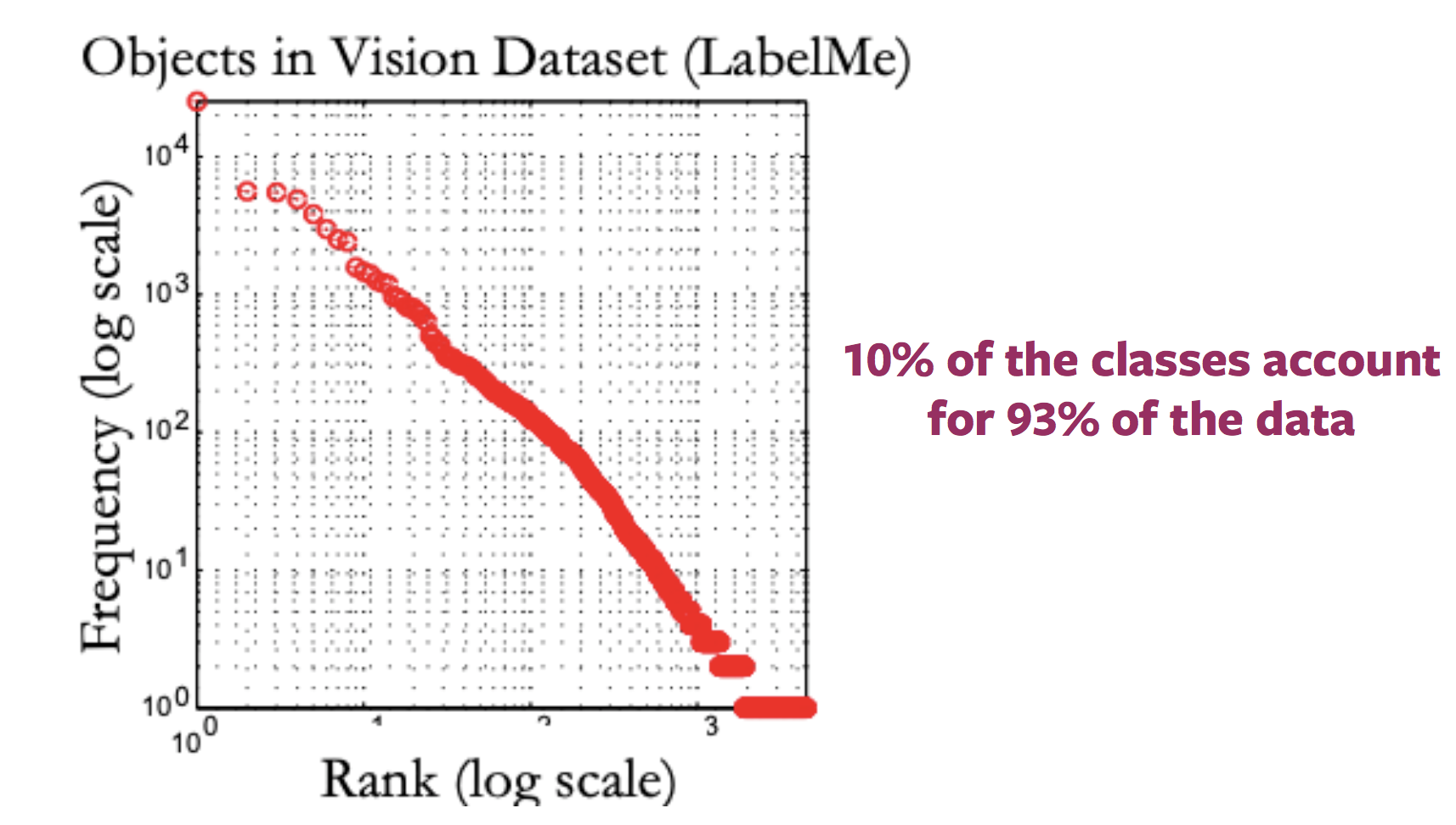
Рисунок 2: Вариация распределения доступных изображений с метками
Проблема разных доменов
Этот метод предварительного обучения и тонкой настройки ImageNet для последующих задач становится еще более сомнительным, когда изображения последующих задач относятся к совершенно другой области, например, к медицинской. Часто невозможно получить количество данных сопоставимых в масштабах с ImageNet для предварительного обучения в разных доменах.
Что такое Самостоятельное обучение?
Два способа определения самостоятельного обучения
- Базовое определение обучения с учителем, то есть обучения на метках полученных полуавтоматическим способом, без участия человека.
- Проблема прогнозирования, когда одна часть данных скрыта, а другая часть доступна. Следовательно, цель состоит в том, чтобы либо предсказать скрытые данные, либо предсказать некоторые свойства скрытых данных.
В чём отличия самостоятельного обучения от обучения с/без учителя?
- Задачи обучения с учителем имеют заранее определенные (и обычно предоставляемые человеком) метки,
- При обучении без учителя используются только объекты без какого-либо контроля, меток или правильного ответа.
- Самостоятельное обучение получает свои метки из совпадения свойств для данного объекта выборки или из возникающих вместе (co-occurring) частей самой выборки данных.
Самостоятельное обучение для Обработки Естественного Языка (NLP)
Word2Vec
- Имея входное предложение, задача состоит в предсказании пропущенного слова из этого предложения, которое специально пропущено с целью создания предварительной задачи (pretext task).
- Следовательно, набором меток становится весь словарь, и правильная метка - это слово, которое было опущено в предложении.
- Таким образом можно обучить сеть для получение представлений слов используя стандартные градиентные методы.
Почему именно Самостоятельное обучение?
- Самостоятельное обучение позволяет изучать представления данных, просто наблюдая за тем, как взаимодействуют различные части данных.
- Тем самым отпадает потребность в огромном количестве аннотированных данных.
- Кроме того оно позволяет использовать несколько модальностей, которые могут быть связаны с одной выборкой данных.
Самостоятельное обучение в Компьютерном Зрении
Как правило, решения задач компьютерного зрения, использующие сомообучение, включают в себя выполнение двух задач: предварительной задачи и реальной (нисходящей) задачи.
- Реальная (нисходящая) задача может быть чем угодно, например задачей классификации или обнаружения, с недостаточными выборками аннотированных данных.
- Предзадача (pretext) - это задача самостоятельного обучения, решаемая для получения визуальных представлений с целью использования полученных представлений или весов модели, в процессе обучения последующей задачи.
Создание предзадач
- Предварительные задачи для компьютерного зрения могут быть разработаны с использованием изображений, видео или видео и звука.
- В каждой предзадаче есть частично видимые и частично скрытые данные, тогда как задача состоит в том, чтобы предсказать либо скрытые данные, либо какое-то свойство скрытых данных.
Пример предзадачи: Предсказание относительного расположения частей изображения
- Вход: 2 фрагмента изображения, один - фрагмент от которого ведётся отсчёт, а второй - фрагмент-запрос.
- Дано 2 фрагмента изображения, сеть должна спрогнозировать их относительное положение.
- Таким образом эта проблема может быть смоделирована как проблема 8-классовой классификации, поскольку существует 8 возможных местоположений для фрагмента- запроса относительно данного фрагмента.
- И метка для этой задачи может быть автоматически сгенерирована путем подачи относительной позиции фрагмента-запроса относительно первого фрагмента.
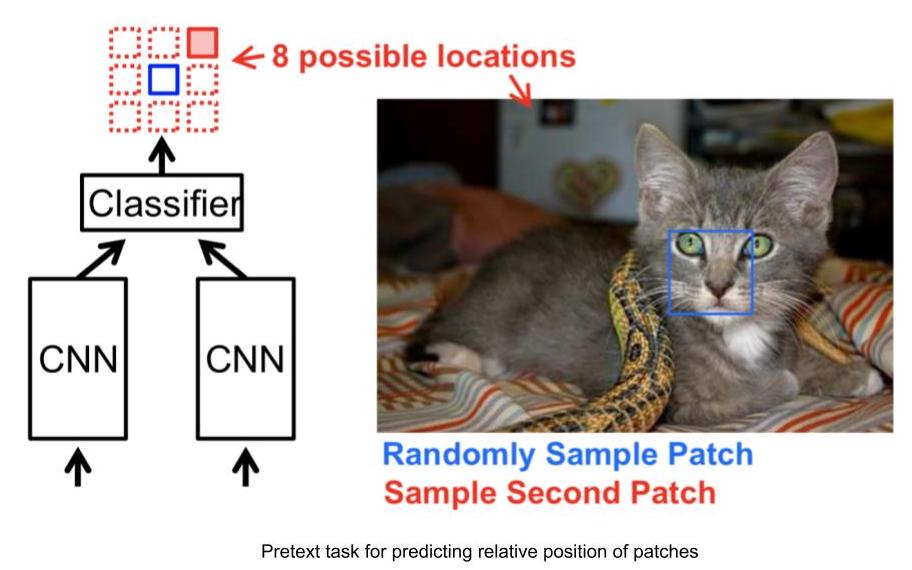
Рисунок 3: Задача относительной позиции
Визуальное представление полученное из задачи предсказания относительной позиции
Мы можем оценить эффективность изученных визуальных представлений, проверив ближайших соседей в пространстве признаков полученных из обученной сети. Для вычисления ближайших соседей данного участка изображения,
- Вычислить функции CNN для всех изображений в наборе данных, которые будут выступать в качестве пула образцов для поиска.
- Вычислить CNN признаки для рассматриваемого фрагмента изображения.
- Определите ближайших соседей для вектора признаков рассматриваемого изображения из пула векторов признаков всех доступных изображений.
Задача относительного положения обнаруживает фрагменты изображения, которые очень похожи на фрагмент-запрос, но при этом сохраняет инвариантность к таким факторам, как цвет объекта. Таким образом, задача относительного положения может изучать визуальные представления, где представления для похожих фрагментов изображения также близки в пространстве представлений.

Рисунок 4: Отосительная Позиция: Ближайшие Соседи
Предсказание поворота изображения
- Прогнозирование поворота - одна из самых популярных предзадач, которая имеет простую и понятную архитектуру и требует минимальной выборки.
- Мы применяем поворот к изображению на 0, 90, 180, 270 градусов и отправляем эти повернутые изображения в сеть, чтобы предсказать, какой тип поворота был применен к изображению, и сеть просто выполняет 4-классовую классификацию для прогнозирования поворота.
- Прогнозирование поворота не имеет никакого семантического смысла, мы просто используем эту предзадачу в качестве прокси для изучения некоторых признаков и представлений, которые будут использоваться в последующих задачах.
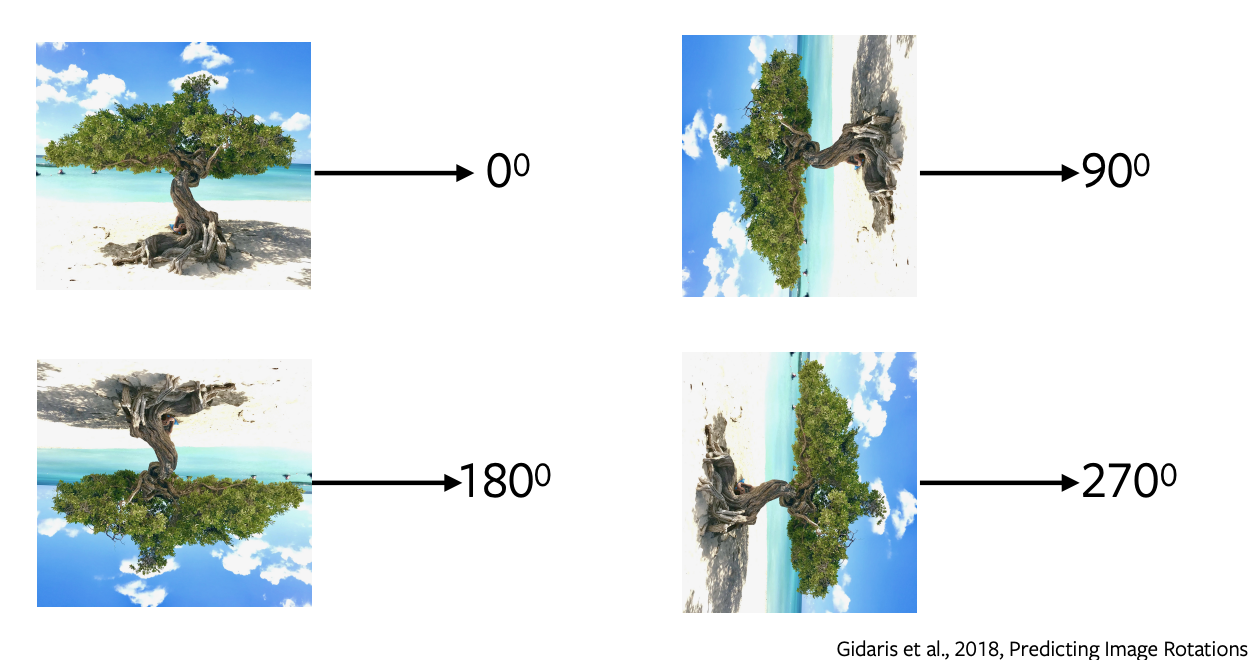
Рисунок 5: Поворот изображения
Почему предзадача поворота полезна и как это работает?
Эмпирическим путём было доказано что это работает. Интуитивно можно понять что для того чтобы предсказать поворот модель должна изучить приблизительные границы и представления изображения. К примеру, она должна была бы различать небо и воду или песок и воду, или понимать что деревья растут вверх и так далее.
Раскраска

Рисунок 6: Раскраска
В этой предзадаче мы предсказываем цвета в черно-белом изображении. Эта задача может быть сформулирована для любого изображения, мы просто убираем цвет и отдаём черно-белое изображение сети для предсказания цвета. Эта задача полезна к примеру для раскраски старой черно-белой фотографии. Интуитивно эта задача заставляет сеть изучить информацию что, допустим, деревья зелёные, небо голубое и т.д.
Важно заметить, что соответствие объектов цветам не детерминировано, и существует несколько правильных ответов. Тогда если для объекта существует несколько возможных раскрасок сеть выдаст серый цвет, который является средним из всех возможных решений.
Заполните пробелы
Мы закрываем часть картинки и затем пытаемся предсказать закрытую часть по оставшейся видимой части. Это работает потому что сеть выучит неявную структуру данных, как допустим то что машины ездят по дорогам, а у зданий есть окна и двери, и т.д.
Предварительные задачи для видео
Видео состоят из последовательности кадров и именно это используется для построения предварительных задач для самостоятельного обучения, таких как предсказание порядка кадров, заполнение пробелом и отслеживание объектов.
Перестановка и обучение (Shuffle & Learn)

Рисунок 7: Интерполяция
Возьмём набор кадров и извелечем три кадра, и если они были извелечены в правильном порядке мы присваиваем позитивную метку, в противном случае кадры перемешиваються и получают негативную метку. Таким образом это представляет собой задачу бинарной классификации - предсказать в правильно ли порядке росположены кадры. При данном первом и последнем кадрах мы проверяем являеться ли средний кадр интерполяцией между ними.
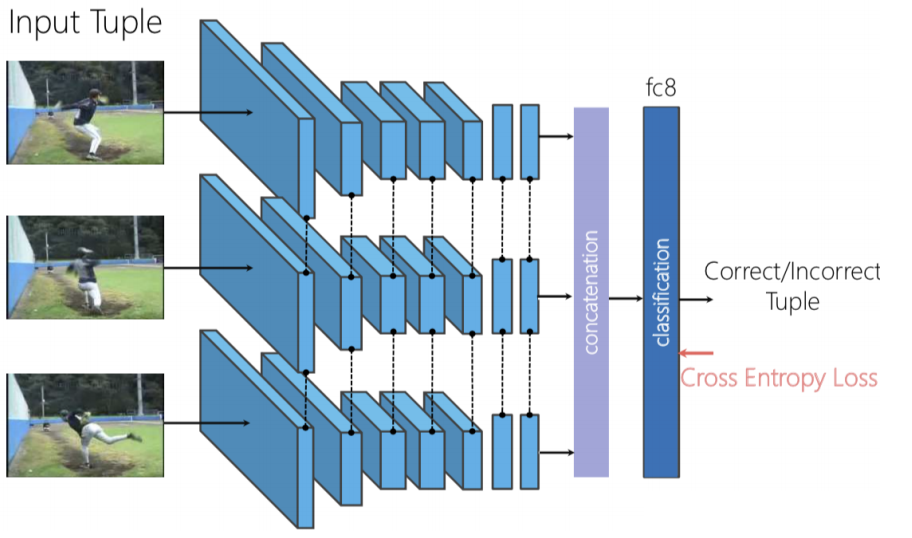
Рисунок 8: Архитектура Перемешивания и Обучения
Мы можем использовать триплетную сиамскую сеть, в которую независимо подаються три кадра, затем полученные признаки конкатенируються и производиться бинарная классификация, предсказывающая перемешаны кадры или нет.

Рисунок 8: Представления Ближайших Соседей
Опять таки, мы можем использовать алгоритм ближайших соседей, для визуализвции того, что изучает наша сеть. На рис. 9 выше, сперва у нас есть кадр запроса, который мы передаем cети, чтобы получить набор признаков, а затем смотрим на ближайших соседей в этом пространстве. При сравнении мы можем наблюдать резкую разницу между соседями, полученными из ImageNet, Перемешивании и Обучении (Shuffle & Learn) и Случайным выбором.
ImageNet хороша в представлении всей семантики изображения, поскольку она может определить, что в первом случае это сцена спортзала. Точно так же она может определить, что это сцена на природе, с травой и т.д. во втором случае. В то же время, мы видим, что Случайный выбор придает большое значение цвету фона.
При наблюдении за Shuffle & Learn не совсем очевидно фокусируется ли она на цвете или на семантике изображения. После дальнейшего рассмотрения и наблюдения за различными примерами было замечено, что она смотрит на позу человека. Например, на первом изображении человек перевернут, а на втором - ноги находятся в определенном положении, аналогичном кадру запроса, без учета сцены или цвета фона. Причина этого в том, что наша предварительная задача заключалась в предсказании в правильном ли порядке находяться данные кадры, и для этого сети необходимо сосредоточиться на том, что движется, в данном случае - на человеке.
Это было подтверждено количественно путем дообучения этих представлений для задачи оценки ключевых точек человека, где при данном изображении человека мы предсказываем, где находятся определенные ключевые точки, такие как нос, левое плечо, правое плечо, левый локоть, правый локоть и т.д. Этот метод полезен для отслеживания и оценки позы.
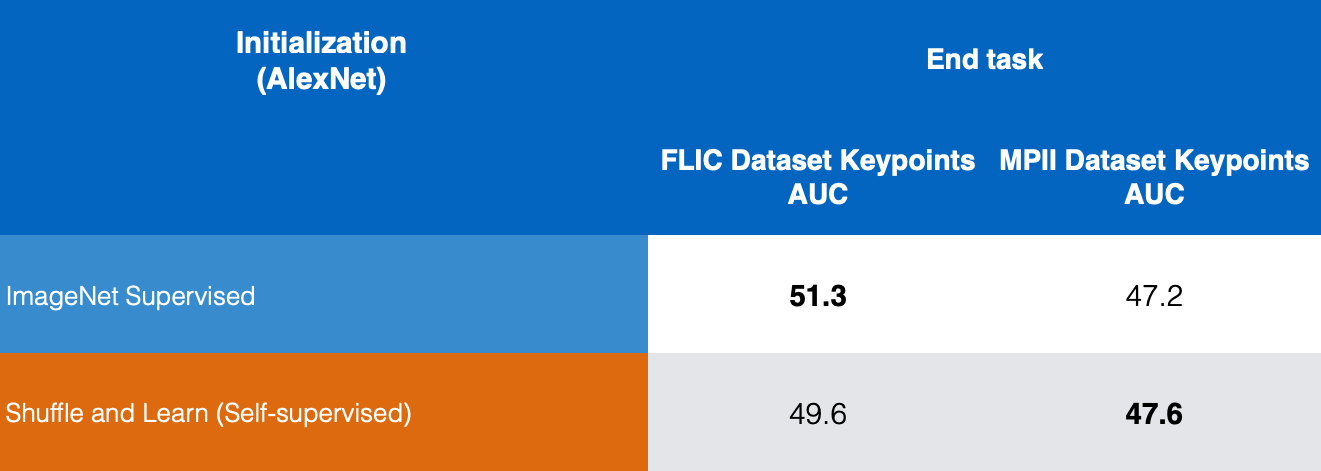
Рисунок 10: Сравнение качества Оценки Ключевых Точек.
На рисунке 10 мы сравниваем результаты для обученной с учителем ImageNet и самообученной Shuffle & Learn на датасетах FLIC и MPII. Мы видим что Shuffle & Learn показывает хорошый результат на задаче оценки ключевых точек.
Предварительные задачи для видео и аудио
Видео и аудио - мультимодальны, им присущи две модальности или сенсорных входа: один для видео и один для аудио. Мы попытаемся определить относится ли данный видео клип к данному аудио клипу.

Рисунок 11: Сэмплирование видео и аудио
Дано видео со звуком барабана, выбираем видеокадр с соответствующим звуком и называем это положительным набором. Затем возьмём звук барабана и видеокадр гитары и назовём это негативным набором. Теперь мы можем обучить сеть решать эту задачу как задачу бинарной классификации.
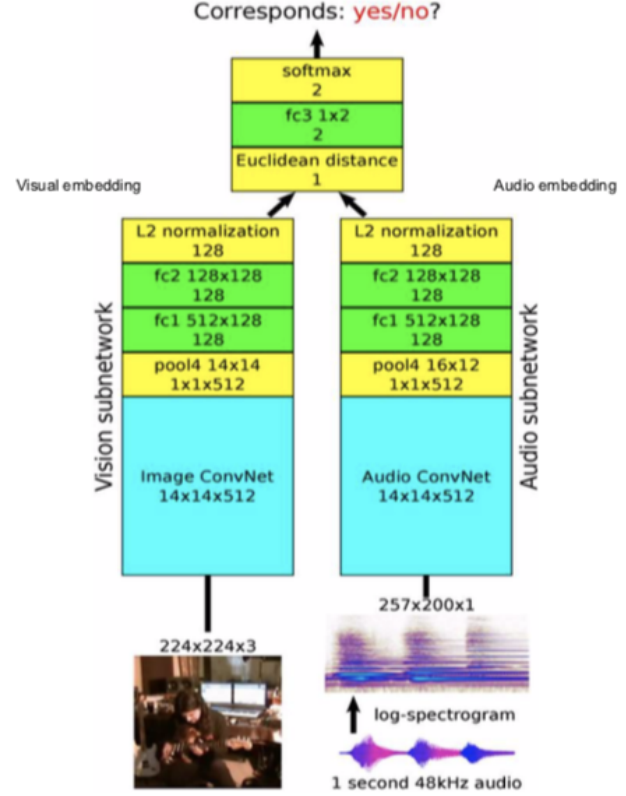
Рисунок 12: Архитектура
Архитектура: Передаём видеокадры в подсеть для изображений а звук - в подсеть для аудио, из которой получаем 128-мерные представления, затем мы объединяем их вместе и решаем как задачу бинарной классификации, предсказывающей соответствуют ли они друг другу.
Это может использоваться, для предсказывания что именно издает звук в кадре. Интуиция состоит в том, что если это звук гитары, сети примерно необходимо понимать, как выглядит гитара, то же самое должно быть верно и для ударных.
Что изучает “предварительня” задача
- Предварительная задача должна дополнять
- Возьмём, к примеру, предварительную задачу Относительной Позиции и Расскраски. Мы можем улучшить качество тренируя модель использовать обе эти задачи, как показано ниже:
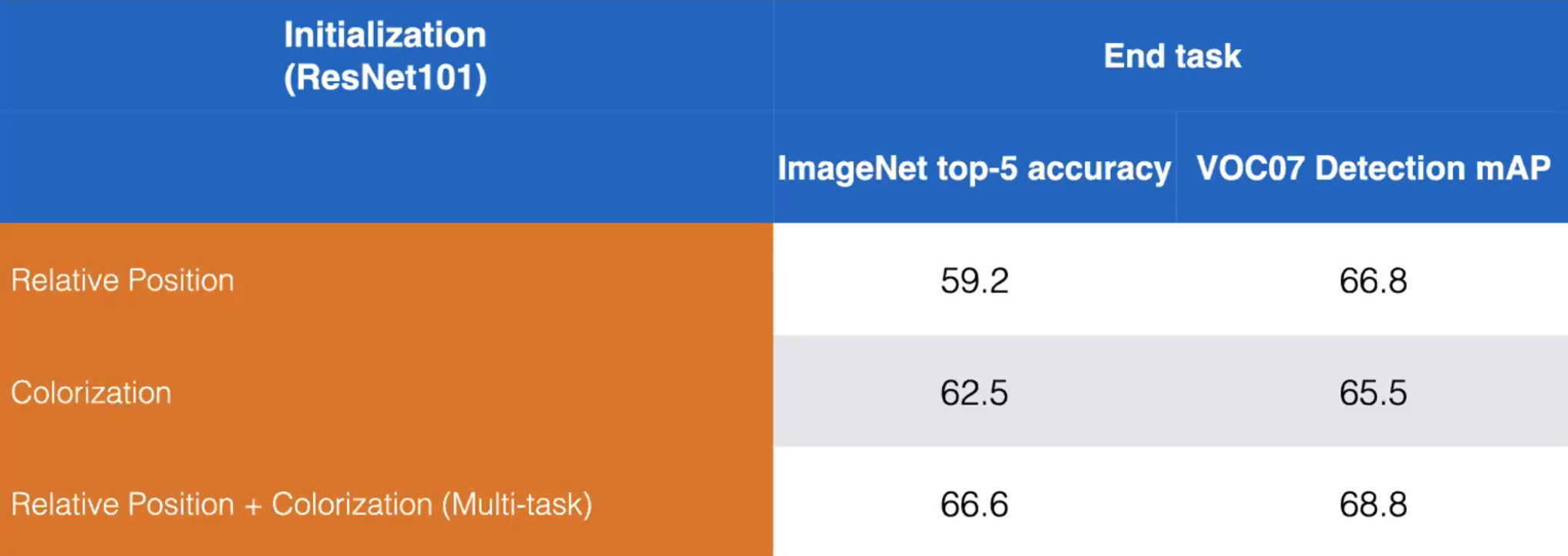
Рисунок 13: Сравнение раздельных и совместных использований предварительных задач Относительной Позиции (Relative Position) и Расскраски (Colourisation) и их влияние на качество модели на основной задаче. ResNet101. (Misra)
- Одной предварительной задачи может быть не достаточно для получения представлений самообучением
- Предварительные задачи очень разнятся в зависимости от того что они пытаются предсказать (по сложности)
- Задача относительной позиции сравнительно проста так как сводится к простой классификации
- Маскировка и заполнение куда сложнее ==> соответственно получает лучшие представления
- Контрастивные методы генерируют еще больше информации чем даже предвариетльные задачи
- Вопрос: Как нам обучать несколько предварительных задач одновременно?
- Выход предварительной задачи зависит от её входа. Последний полносвязный слой сети может быть заменён в зависимости от типа батча.
- К примеру: Батч чёрно белых изображений отправлется на вход сети, которая должна произвести цветные изображение. Затем последний слой подменяеться и подаётся батч кусков изображения для определения относительной позиции.
- Вопрос: Сколько нужно обучаться на предварительной задаче?
- Как правило: Используйте сложную предварительную задачу, так чтобы она улучшила качество основной задачи.
- На практике производится тренировка на предварительной задаче только один раз. Во время разработки она тренируется как часть всего пайплайна, вместе с основной задачей.
Масштабирование Самостоятельного обучения
Головоломки
- Разделим изображение на несколько кусочков и перемешаем их. Затем модель постарается расставить их по своим местам. (Noorozi & Favaro, 2016)
<!– * Predict which permutation was applied to the input
-
This is done by creating batches of tiles such that each tile of an image is evaluated independently. The convolution output are then concatenated and the permutation is predicted as in figure below–>
- Предсказать какая перестановка произошла
- Это делается путем создания групп кусочков, так что каждый кусочек изображения оценивается независимо. Затем выходные данные свертки (конволюции) объединяются, и перестановка прогнозируется, как показано на рисунке ниже.
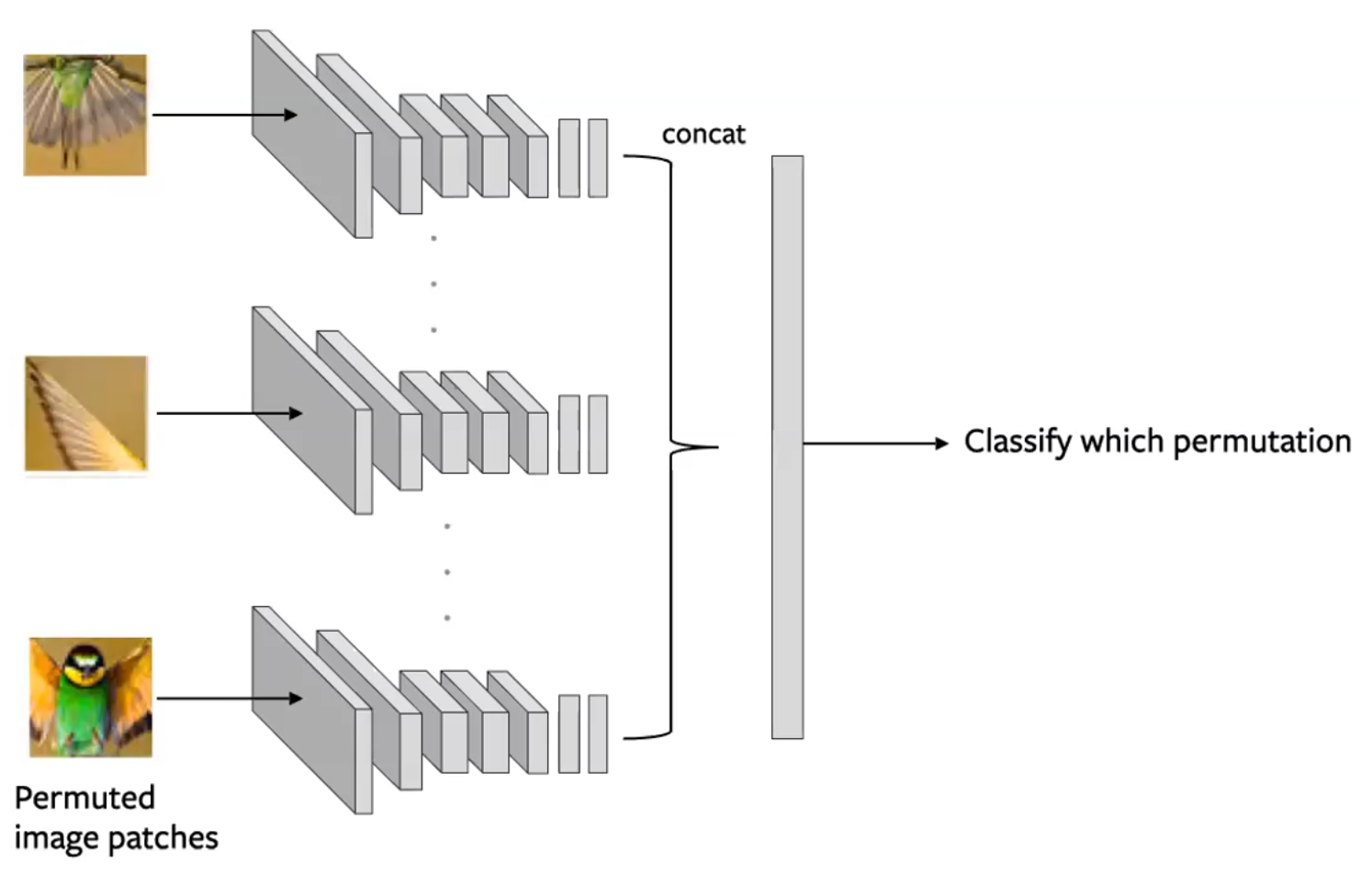
Рисунок 14: Архитектура сиамской сети для предварительной задачи решения Головоломки. Каждый кусочек изображения подаётся независимо, и представления конкатенируются для предсказания перестановки.
- Заметки:
- Использовать подмножество всех возможных перестановок. К примеру не все 9!, а 100)
- Использовать общие параметры между слоями многослойной конволюционной сети
- Сложность проблемы заключается в размере подмножества. Количество информации, которое прогнозируется.
- Иногда этот метод показывает лучшие результаты на основной задаче чем методы обучения с учителем, так как сеть может получить информацию о геометрии входа.
-
Недостатки: Обучение по нескольким примерам: Ограниченое количество тренировочных данных
- Представления, полученный при самообучении, нуждаются в большом количестве данных (используют данные менее ефективно)
Оценка качества: Дообучений в сравнении с Линейным Классификатором
Эта форма оценки качества является видом Трансферного обучения.
- Дообучение: Когда мы используем предварительную задачу для основной мы берём всю предобученную сеть как инициальзацию, и дообучаем на основной задаче.
- Линейный Классификатор: На основе нашей предварительной задачи мы строим простой линейный классификатор для основной задачи, и не меняем веса в процессе обучения.
Хорошее представление не будет нуждатся в большом количестве дообучения.
- Полезно оценить качество предарительного обучения на различных задачах. Мы можем это сделать, извлекая представления созданное разными слоями сети и фиксируя эти представления, оценивая их полезность для решения этих различных задач.
<!– * Measurement: Mean Average Precision (mAP) –The precision averaged across all the different tasks we are considering.
- Some examples of these tasks include: Object Detection (using fine-tuning), Surface Normal Estimation (see NYU-v2 dataset)
- What does each layer learn?
- Generally, as the layers become deeper, the mean average precision on downstream tasks using their representations will increase.
- However, the final layer will see a sharp drop in the mAP due to the layer becoming overly specialized.
- This contrasts with supervised networks, in that the mAP generally always increases with depth of layer.
- This shows that the pretext task is not well-aligned to the downstream task.–>
- Измерения: Средняя точность (Mean Average Precision - mAP) - точность, усредненная для всех различных задач, которые мы рассматриваем.
- Некоторые примеры этих задач включают: обнаружение объектов (с использованием дообучения), оценка нормали поверхности (см. Набор данных NYU-v2)
- Что изучает каждый из слоёв?
- Как правило, по мере того, как слои становятся глубже, средняя точность последующих задач, использующих их представления, увеличивается.
- Однако последний слой увидит резкое падение mAP из-за того, что слой стал чрезмерно специализированным.
- Это контрастирует с сетями обучаемые с учителем в том, что mAP обычно всегда увеличивается с глубиной слоя.
- Это показывает, что предварительная задача плохо согласована с последующей задачей.
📝 Aniket Bhatnagar, Dhruv Goyal, Cole Smith, Nikhil Supekar
Kateryna Solonko
6 Apr 2020