Décoder les modèles de langue
🎙️ Mike LewisRecherche en faisceau
La recherche en faisceau est une autre technique pour décoder un modèle de langue et produire du texte. À chaque étape, l’algorithme garde une trace des $k$ plus probables (meilleures) traductions partielles (hypothèses). Le score de chaque hypothèse est égal à son logarithme de probabilité.
L’algorithme sélectionne la meilleure hypothèse basée sur un score.
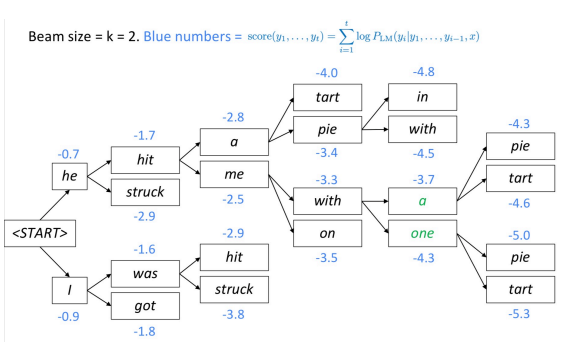
Figure 1 : Décodage en faisceau
A quelle profondeur l’arbre des faisceaux se ramifie-t-il ?
L’arbre des faisceaux continue jusqu’à ce qu’il atteigne le token de fin de phrase. Une fois le token de fin de phrase émis, l’hypothèse est terminée.
Pourquoi les très grandes tailles de faisceau entraînent-elles souvent des traductions vides ?
Au moment de l’entraînement, l’algorithme n’utilise souvent pas de faisceau, car c’est très coûteux. Il utilise plutôt la factorisation auto-régressive (en fonction des sorties correctes précédentes, prédire les premiers mots $n+1$). Le modèle n’est pas exposé à ses propres erreurs pendant l’entraînement, il est donc possible que des absurdités apparaissent dans le faisceau.
Résumé : continuer la recherche de faisceau jusqu’à ce que toutes les hypothèses $k$ produisent un token de fin ou jusqu’à ce que la limite maximale de décodage $T$ soit atteinte.
Échantillonnage
Nous ne voulons peut-être pas la séquence la plus probable. Nous pouvons plutôt prélever un échantillon à partir de la distribution du modèle.
Cependant, l’échantillonnage à partir de la distribution du modèle pose son propre problème. Une fois qu’un mauvais choix est échantillonné, le modèle se trouve dans un état auquel il n’a jamais été confronté pendant l’entraînement, ce qui augmente la probabilité qu’une mauvaise évaluation continue. L’algorithme peut donc se retrouver coincé dans d’horribles boucles de rétroaction.
Echantillonnage top-k
Une technique d’échantillonnage où l’on tronque la distribution au meilleur $k$, puis on la renormalise et on prélève un échantillon de la distribution.
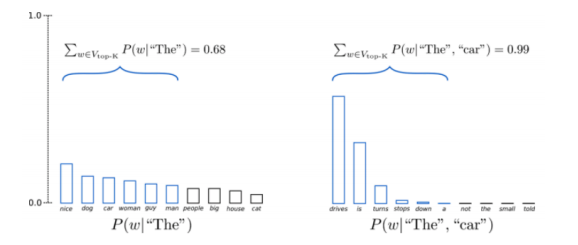
Figure 2 : Echantillonnage top-k
Question : Pourquoi l’échantillonnage top-k fonctionne-t-il si bien ?
Cette technique fonctionne bien parce qu’en utilisant seulement la tête de la distribution et en coupant la queue, elle essaie essentiellement d’éviter de tomber dans la multitude des bonnes langues lorsque nous échantillonnons quelque chose de mauvais.
Évaluation de la génération de texte
Pour évaluer le modèle linguistique, il suffit d’enregistrer la probabilité des données retenues. Cependant, il est difficile d’évaluer le texte. On utilise généralement des mesures de chevauchement des mots avec une référence (BLEU, ROUGE, etc.), mais elles ont leurs propres problèmes.
Modèles de séquence à séquence
Modèles de langue conditionnels
Les modèles linguistiques conditionnels ne sont pas utiles pour générer des échantillons d’anglais aléatoires, mais ils sont utiles pour générer un texte à partir d’une entrée.
Exemples :
- A partir d’une phrase française, générer la traduction anglaise
- A partir d’un document, générer un résumé
- Après un dialogue, générer la réponse suivante
- Face à une question, générer la réponse
Modèles de séquence à séquence
En général, le texte d’entrée est encodé. L’enchâssement résultant est connu sous le nom de « vecteur de pensée », qui est ensuite transmis au décodeur pour générer des tokens mot par mot.
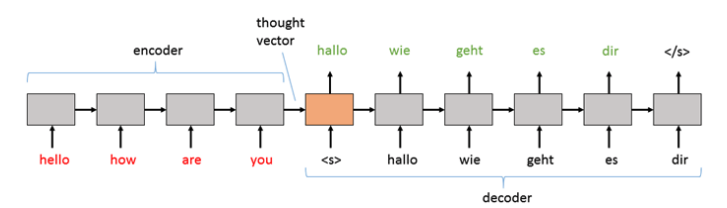
Figure 3 : Vecteur de pensée
Transformer séquence à séquence
La variation séquence à séquence des transformers a 2 piles :
-
Pile d’encodeurs : l’auto-attention n’est pas masquée, de sorte que chaque jeton de l’entrée peut regarder tous les autres jetons de l’entrée
-
Pile de décodeurs : en plus d’utiliser l’auto-attention, l’attention est également appliquée sur toutes les entrées
Figure 4 : Transformer séquence à séquence
Chaque jeton de la sortie a un lien direct avec chaque jeton précédent de la sortie, ainsi qu’avec chaque mot de l’entrée. Ces connexions rendent les modèles très expressifs et puissants. Les transformers ont permis d’améliorer le score de traduction par rapport aux modèles convolutifs et récurrents précédents.
Rétro-traduction
Lorsque nous entraînons ces modèles, nous nous appuyons généralement sur de grandes quantités de texte labellisé. Une bonne source de données provient des procédures du Parlement européen où le texte est traduit manuellement dans différentes langues que nous pouvons ensuite utiliser comme entrées et sorties du modèle.
Problèmes
-
Toutes les langues ne sont pas représentées au Parlement européen, ce qui signifie que nous n’avons pas de paire de traduction pour toutes les langues qui pourraient nous intéresser. Comment trouver un texte à entraîner dans une langue pour laquelle nous ne pouvons pas nécessairement obtenir les données ?
-
Puisque des modèles comme les transformers fonctionnent beaucoup mieux avec plus de données, comment utiliser efficacement un texte monolingue, c’est-à-dire sans paires d’entrée/sortie ?
Supposons que nous voulions entraîner un modèle à traduire de l’allemand en anglais. L’idée de la rétro-traduction est d’entraîner d’abord un modèle inverse de l’anglais vers l’allemand.
En utilisant quelques bi-textes limités, nous pouvons acquérir les mêmes phrases dans 2 langues différentes. Une fois que nous aurons un modèle anglais-allemand, on peut traduire beaucoup de mots monolingues de l’anglais vers l’allemand. Enfin, on peut entraîner le modèle anglais-allemand en utilisant les mots allemands qui ont été « retro-traduits » lors de l’étape précédente.
A noter que :
- Peu importe la qualité du modèle inverse nous pouvons avoir des traductions allemandes bruyantes mais nous finissons par traduire en anglais propre.
- Nous devons apprendre à comprendre l’anglais bien au-delà des données des paires anglais/allemand (déjà traduites) / utiliser de grandes quantités d’anglais monolingue.
Retro-traduction itérative
- Nous pouvons itérer la procédure de rétro-traduction afin de générer encore plus de données bi-texte et d’atteindre de bien meilleures performances : il suffit de continuer à s’entraîner en utilisant des données monolingues.
- Cela aide beaucoup quand il n’y a pas beaucoup de données parallèles.
Traducteur multilingue
Figure 5 : Traducteur multilingue
- Au lieu d’essayer d’apprendre une traduction d’une langue à une autre, essayons de construire un réseau neuronal pour apprendre des traductions en plusieurs langues.
- Le modèle permet d’apprendre des informations générales indépendantes de la langue.

Figure 6 : Résultats réseaux de neurones multilingues
De bons résultats, surtout si nous voulons entraîner un modèle à traduire dans une langue qui n’a pas beaucoup de données disponibles pour nous (langue à faible ressource).
Apprentissage non supervisé en traitement du langage naturel
Il y a d’énormes quantités de texte sans aucun label et peu de données contrôlées. Que pouvons-nous apprendre sur la langue en lisant simplement un texte non étiqueté ?
Word2vec
L’intuition est que si des mots apparaissent proches les uns des autres dans le texte, ils sont probablement liés. Nous espérons donc qu’en regardant simplement un texte anglais non labellisé, nous pouvons apprendre ce qu’ils signifient.
- L’objectif est d’apprendre les représentations spatiales vectorielles des mots (apprendre les enchâssements).
Tâche de pré-entraînement : masquer un mot et utiliser les mots voisins pour remplir les blancs.

Figure 7 : Word2vec masquant le visuel
Par exemple, ici, l’idée est que les « cornes » et les « cheveux argentés » sont plus susceptibles d’apparaître dans le contexte de la « licorne » que d’autres animaux.
En appliquant une projection linéaire sur les mots :
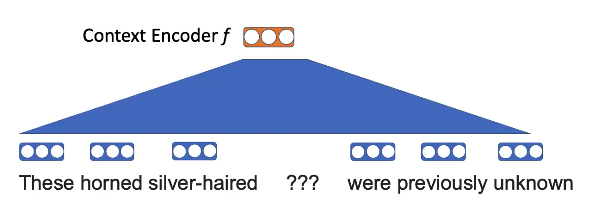
Figure 8 : Enchâssements de Word2vec
On veut savoir
\[p(\texttt{licorne} \mid \texttt{Ces cheveux argentés étaient auparavant inconnus})\] \[p(x_n \mid x_{-n}) = \text{softmax}(\text{E}f(x_{-n}))\]Les enchâssements de mots contiennent une certaine structure :
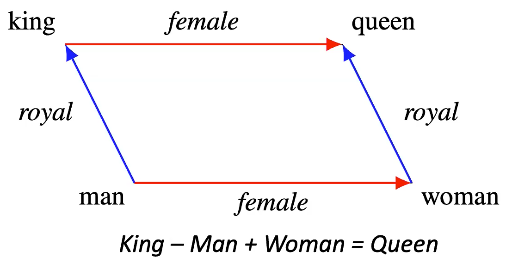
Figure 9 : Exemple de structure d’enchâssements
- L’idée est que si nous prenons la représentation vectorielle de « roi » après l’entraînement et que nous ajoutons celle pour « femelle », nous obtiendrons une représentation très proche de celle de « reine ».
Questions d’étudiants
Le mot « représentation » dépend-il ou non du contexte ?
Indépendant et n’a aucune idée des relations avec d’autres mots.
Quel serait un exemple de situation dans laquelle ce modèle aurait du mal ?
Les enchâssements de mots dépendent fortement du contexte. Ainsi, dans le cas de mots ambigus, des mots qui peuvent avoir des significations multiples, le modèle aura du mal car les vecteurs ne captureront pas le contexte nécessaire pour comprendre correctement le mot.
GPT
Pour ajouter du contexte, nous pouvons entraîner un modèle de langue conditionnel. Ensuite, étant donné ce modèle qui prédit un mot à chaque pas de temps, on remplace chaque sortie du modèle par une autre caractéristique.
- Pré-entraînement : prédire le mot suivant
- Finetuning : modification d’une tâche spécifique comme par exemple
- Prédire si un mot est un nom ou un adjectif
- Prédire le score de sentiment pour une critique de film
Cette approche est bonne car nous pouvons réutiliser le modèle. Nous pré-entraînons un grand modèle et pouvons l’adapter à d’autres tâches.
ELMo
Le GPT ne tient compte que du contexte à gauche (du mot qu’il est en train de traiter), ce qui signifie que le modèle ne peut pas dépendre de mots futurs, ce qui limite beaucoup ce que le modèle peut faire.
L’approche consiste ici à entraîner deux modèles de langue :
- un sur le texte de gauche à droite
- un sur le texte de droite à gauche On peut alors concaténer les résultats des deux modèles afin d’obtenir la représentation des mots. On peut maintenant conditionner le contexte à droite et à gauche.
Il s’agit toujours d’une combinaison superficielle et nous voulons une interaction plus complexe entre les contextes gauche et droit.
BERT
BERT est similaire à Word2vec dans le sens où nous avons également une tâche de remplissage. Cependant, dans Word2vec, nous avions des projections linéaires, alors que dans BERT, il y a un grand transformer qui est capable de regarder plus de contexte. Pour entraîner, nous masquons 15 % des jetons et nous essayons de prédire ce qui a été masqué.
Il est possible de passer à l’échelle BERT (RoBERTa) en :
- simplifiant l’objectif de pré-entraînement de BERT
- augmentant la taille des batchs
- entraînant sur de grandes quantités de GPU
- entraînant sur encore plus de texte
On obtient alors par exemple une performance supérieure à l’humaine sur la tâche de réponse aux questions.
Pré-entraînement en traitement du langage naturel
Examinons rapidement les différentes approches de pré-entraînement autosupervisé qui ont été étudiées en en traitement du langage naturel :
-
XLNet : Au lieu de prédire tous les tokens masqués de façon conditionnelle et indépendante, XLNet prédit les tokens masqués de façon auto-régressive et dans un ordre aléatoire
-
SpanBERT Les masques s’étendent (séquence de mots consécutifs) au lieu des jetons
-
ELECTRA : Plutôt que de masquer les mots, nous remplaçons les jetons par des mots similaires. Ensuite, nous résolvons un problème de classification binaire en essayant de prédire si les jetons ont été substitués ou non.
-
ALBERT (A Lite Bert) : Nous modifions BERT et le rendons plus léger en liant les poids entre les couches. Cela réduit les paramètres du modèle et les calculs impliqués. Il est intéressant de noter que les auteurs d’ALBERT n’ont pas eu à faire beaucoup de compromis sur la précision.
-
XLM : Il s’agit d’un BERT multilingue. Au lieu d’alimenter un texte en anglais, nous alimentons un texte en plusieurs langues. Comme prévu, il a mieux appris les connexions interlinguistiques.
Les principaux enseignements tirés des différents modèles mentionnés ci-dessus sont les suivants :
- De nombreux objectifs de pré-entraînement différents fonctionnent bien !
- Il est essentiel de modéliser les interactions profondes et bidirectionnelles entre les mots
- Des gains importants grâce à l’intensification du pré-entraînement, sans encore de limites claires
La plupart des modèles évoqués ci-dessus sont conçus pour résoudre le problème de la classification de textes. Cependant, pour résoudre le problème de la génération de texte, où nous générons les résultats de manière séquentielle comme le modèle seq2seq, nous avons besoin d’une approche légèrement différente du pré-entraînement.
Pré-entraînement pour la génération conditionnelle : BART et T5
BART : pré-entraînement des modèles seq2seq par le débruitage de texte.
Dans BART, pour le pré-entraînement, nous prenons une phrase et la corrompons en masquant des jetons au hasard. Au lieu de prédire les jetons masqués (comme dans l’objectif de BERT), nous donnons toute la séquence corrompue et essayons de prédire toute la séquence correcte.
Cette approche de pré-entraînement seq2seq nous donne une certaine flexibilité dans la conception de nos schémas de corruption. Nous pouvons mélanger les phrases, supprimer des expressions, en introduire de nouvelles, etc.
BART a pu faire aussi bien que RoBERTa sur les tâches SQUAD et GLUE. Il établit le nouvel état de l’art sur les jeux de données de résumé, de dialogue et les questions/réponses. BART est meilleur que BERT/RoBERTa dans les tâches de génération de texte.
Quelques questions ouvertes en traitement du langage naturel
- Comment intégrer la connaissance du monde ?
- Comment modéliser de longs documents étant donné que les modèles basés sur BERT utilisent généralement seulement 512 jetons ?
- Quelle est la meilleure façon de procéder pour l’apprentissage multitâches ?
- Pouvons-nous procéder à du finetuning avec moins de données ?
- Ces modèles comprennent-ils vraiment le langage ?
Résumé
- Entraîner des modèles sur de nombreuses données bat explicitement la modélisation de la structure linguistique.
Du point de vue de la variance de biais, les transformers sont des modèles à faible biais (très expressifs). Il est préférable de nourrir ces modèles avec beaucoup de texte plutôt que de modéliser explicitement la structure linguistique (biais élevé). Les architectures doivent comprimer les séquences à travers les goulots d’étranglement.
-
Les modèles peuvent apprendre beaucoup sur le langage en prédisant des mots dans un texte non étiqueté. Cela s’avère être un excellent objectif d’apprentissage non supervisé. Il est alors facile de finetuner des tâches spécifiques.
-
Le contexte bidirectionnel est crucial.
Questions posées après le cours par des étudiants
Quels sont les moyens de quantifier la compréhension du langage ? Comment savons-nous que ces modèles sont réellement des modèles de compréhension du langage ?
La phrase « mon trophée ne rentre pas dans mon bagage car il est trop grand » est difficile pour les modèles car ont des problèmes pour résoudre le problème de la référence à « il » dans cette phrase. L’homme est doué pour cette tâche. Il existe un jeu de données constitué d’exemples aussi difficiles et les humains atteignent 95% de performance sur ce jeu de données. Les programmes informatiques n’atteignaient que 60% environ avant la révolution provoquée par les transformers. Les modèles modernes de transformers sont capables d’atteindre plus de 90%. Cela suggère que ces modèles ne se contentent pas de mémoriser/exploiter les données, mais qu’ils apprennent des concepts et des objets grâce aux modèles statistiques des données. En outre, BERT et RoBERTa atteignent des performances supérieures à celle humaine sur les jeux de données SQUAD et GLUE. Les résumés textuels générés par BART semblent très réels pour les humains (scores BLEU élevés). Ces faits sont la preuve que les modèles comprennent le langage d’une certaine manière.
Peut-on évaluer si le modèle a déjà une connaissance du monde ?
La connaissance du monde est un concept abstrait. Nous pouvons tester les modèles, au niveau le plus élémentaire en leur posant des questions simples sur les concepts qui nous intéressent. Des modèles comme BERT, RoBERTa et T5 ont des milliards de paramètres. Si l’on considère que ces modèles sont entraînés sur un énorme corpus de textes informationnels comme Wikipédia, ils mémorisent des faits en utilisant leurs paramètres et sont capables de répondre à nos questions. En outre, nous pouvons également envisager de réaliser le même test de connaissances avant et après le finetuning d’un modèle sur une tâche donnée. Cela nous donnerait une idée de la quantité d’informations que le modèle a « oubliées ».
Qu’est que le langage fondé sur la réalité (grounded Language) ?
L’objectif de ce domaine de recherche est de créer des agents conversationnels capables de bavarder ou de négocier. Le bavardage et la négociation sont des tâches abstraites dont les objectifs ne sont pas clairs par rapport à la classification ou au résumé de texte.
📝 Trevor Mitchell, Andrii Dobroshynskyi, Shreyas Chandrakaladharan, Ben Wolfson
Loïck Bourdois
20 Apr 2020