Apprentissage autosupervisé et tâches de prétexte
🎙️ Ishan MisraSuccès de la supervision : le pré-entraînement
Au cours de la dernière décennie, l’une des principales approches ayant eu du succès pour de nombreux problèmes de vision par ordinateur a été l’apprentissage des représentations visuelles en effectuant un apprentissage supervisé sur ImageNet. Les représentations et les poids alors appris ont pu être réutilisé comme initialisation pour d’autres tâches de vision par ordinateur où un grand nombre de données étiquetées pouvaient ne pas être disponibles.
Cependant, annoter un jeu de données de l’ampleur d’ImageNet est extrêmement long et coûteux. Par exemple l’étiquetage d’ImageNet avec 14 millions d’images a pris environ 22 années humaines.
C’est pourquoi la communauté a commencé à chercher d’autres procédés d’étiquetage, comme les mots-dièse pour les images des médias sociaux, les localisations GPS ou les approches autosupervisées où le label est une propriété de l’échantillon de données lui-même.
Mais une question importante se pose avant de chercher d’autres procédés d’étiquetage :
Combien de données étiquetées pouvons-nous obtenir ?
- Si nous recherchons toutes les images avec une catégorie au niveau de l’objet et des annotations pour les boîtes de délimitation, nous obtenons environ un million d’images.
- Maintenant, si la contrainte pour les coordonnées des boîtes de délimitation est assouplie, le nombre d’images disponibles passe à environ 14 millions.
- Cependant, si nous considérons toutes les images disponibles sur Internet, il y a un saut d’un facteur 5 dans la quantité de données disponibles.
- Et puis, il y a les données autres que les images, qui nécessitent d’autres entrées sensorielles pour être saisies ou comprises.
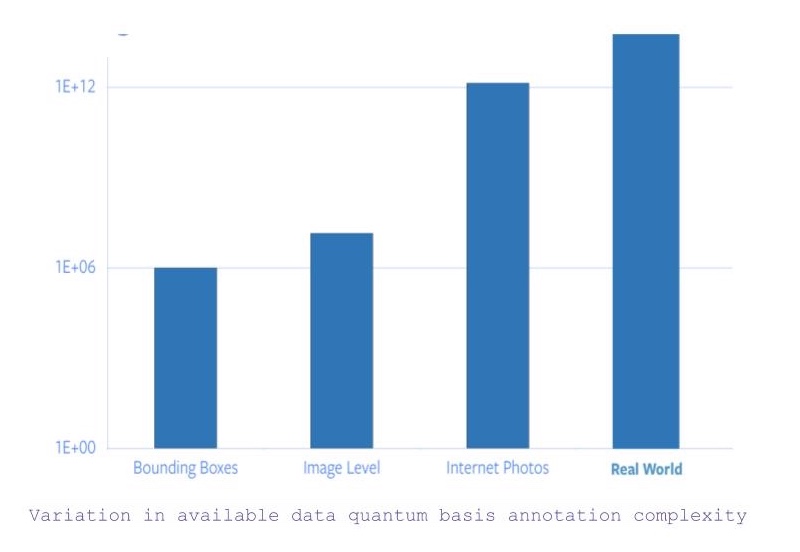
Figure 1 : Variation des données disponibles selon la complexité de l'annotation
Par conséquent, si l’on considère que l’annotation d’ImageNet a pris à elle seule 22 années humaines, il est totalement impossible de mettre à l’échelle l’étiquetage de toutes les photos sur Internet ou au-delà.
Problème des concepts rares (problème de la longue queue)
En général, la distribution des labels pour les images disponibles sur internet ressemble à une longue queue. C’est-à-dire que la plupart des images correspondent à très peu de labels, alors qu’il existe un grand nombre de labels pour lesquelles peu d’images sont présentes. Ainsi, pour obtenir des échantillons annotés pour les catégories vers la fin de la queue, il faut étiqueter d’énormes quantités de données en raison de la nature de la distribution des catégories.
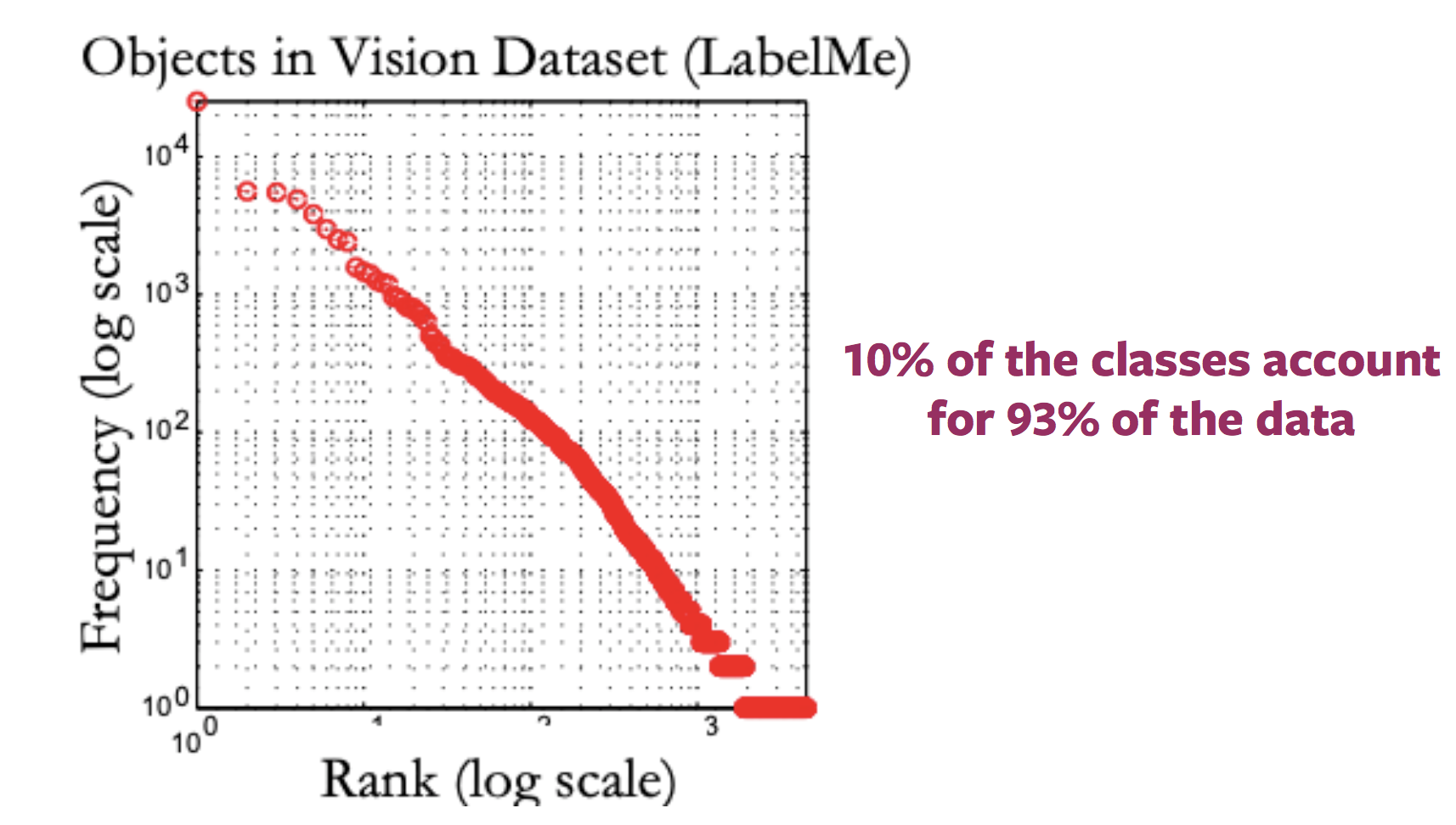
Figure 2 : Variation de la distribution des images disponibles avec labels
Problème de la différence de domaine
Cette méthode de pré-entraînement et de finetuning d’ImageNet sur les tâches en aval devient encore plus obscure lorsque les images des tâches en aval appartiennent à un domaine complètement différent, comme l’imagerie médicale.
Qu’est-ce que l’apprentissage autosupervisé ?
Deux façons de définir l’apprentissage autosupervisé :
- En se basant sur la définition de l’apprentissage supervisé c’est-à-dire que le réseau suit un apprentissage supervisé où les labels sont obtenus de manière semi-automatique, sans intervention humaine.
- En voyant la tâche comme un problème de prédiction où une partie des données est cachée et le reste visible. L’objectif est soit de prédire les données cachées, soit de prédire certaines propriétés des données cachées.
Comment l’apprentissage autosupervisé diffère-t-il de l’apprentissage supervisé et de l’apprentissage non supervisé ?
- Les tâches d’apprentissage supervisé ont des labels prédéfinis (et généralement fournis par l’homme),
- L’apprentissage non supervisé ne dispose que des échantillons de données sans aucune supervision, label ou sortie correcte.
- L’apprentissage autosupervisé tire ses labels d’une modalité concomitante pour l’échantillon de données donné ou d’une partie concomitante de l’échantillon de données lui-même.
L’apprentissage autosupervisé dans le traitement du langage naturel
Word2Vec
- À partir d’une phrase d’entrée, la tâche consiste à prédire un mot manquant dans cette phrase, qui est spécifiquement omis dans le but de construire une tâche de prétexte.
- Ainsi, l’ensemble des labels devient tous les mots possibles du vocabulaire et le label correct est le mot qui a été omis de la phrase.
- Ainsi, le réseau peut ensuite être entraîné à l’aide de méthodes régulières basées sur des gradients pour apprendre les représentations au niveau des mots.
Pourquoi un apprentissage autosupervisé ?
- L’apprentissage autosupervisé permet d’apprendre des représentations de données en observant simplement comment différentes parties des données interagissent.
- Cela permet de réduire le nombre de données annotées.
- De plus, il permet de tirer parti des multiples modalités qui peuvent être associées à un seul échantillon de données.
Apprentissage autosupervisé en vision par ordinateur
En général, les pipelines de vision par ordinateur qui font appel à l’apprentissage autosupervisé impliquent l’exécution de deux tâches, une tâche prétexte et une tâche réelle (en aval).
- La tâche réelle (en aval) peut être par exemple une tâche de classification ou de détection, avec des échantillons de données annotés insuffisants.
- La tâche prétexte est la tâche d’apprentissage autosupervisée résolue pour apprendre des représentations visuelles, dans le but d’utiliser les représentations apprises ou les poids de modèle obtenus dans le processus, pour la tâche en aval.
Développer des tâches de prétexte
- Les tâches de prétexte pour les problèmes de vision par ordinateur peuvent être développées en utilisant soit des images, soit de la vidéo, soit de la vidéo et du son.
- Dans chaque tâche de prétexte, il y a une partie de données visibles et une partie de données cachées, tandis que la tâche consiste à prédire soit les données cachées, soit une certaine propriété des données cachées.
Exemple de tâches de prétexte : prédire la position relative des patchs d’image
- Entrée : 2 patchs d’image, l’un est le patch d’image d’ancrage et l’autre est le patch d’image requête.
- Compte tenu des deux correctifs d’image, le réseau doit prévoir la position relative du correctif d’image requête par rapport au correctif d’image d’ancrage.
- Ainsi, ce problème peut être modélisé comme un problème de classification à 8 classes, puisqu’il y a 8 emplacements possibles pour une image requête, avec une ancre.
- Et le label pour cette tâche peut être généré automatiquement en indiquant la position relative de la zone de recherche par rapport à l’ancre.
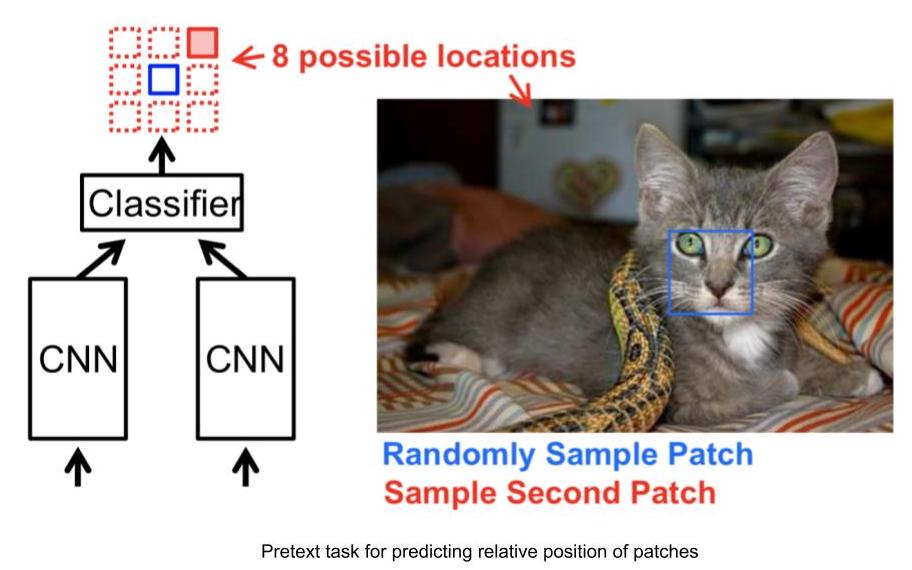
Figure 3 : Tâche de position relative
Représentations visuelles apprises par la tâche de prédiction de la position relative
Nous pouvons évaluer l’efficacité des représentations visuelles apprises en vérifiant chez les voisins les plus proches les représentations des caractéristiques de base d’un patch d’image donné fournies par le réseau. Pour calculer les voisins les plus proches d’une image donnée :
- Calculer les caractéristiques du ConvNet pour toutes les images du jeu de données, qui serviront d’échantillon pool pour la recherche.
- Calculer les caractéristiques du ConvNet pour le correctif d’image requis.
- Identifier les voisins les plus proches pour le vecteur de caractéristique de l’image requise, à partir de la mise en commun de vecteurs de caractéristiques des images disponibles.
La tâche de position relative permet de trouver des zones d’image très similaires à la zone d’image d’entrée, tout en maintenant l’invariance de facteurs tels que la couleur de l’objet. Ainsi, la tâche de position relative est capable d’apprendre des représentations visuelles, où les représentations pour des taches d’image avec un aspect visuel similaire sont également plus proches dans l’espace de représentation.

Figure 4 : Position relative : voisins les plus proches
Prédire la rotation des images
- La prévision des rotations est l’une des tâches de prétexte les plus populaires ayant une architecture simple et directe, et nécessitant un échantillonnage minimal.
- Nous appliquons des rotations de 0, 90, 180, 270 degrés à l’image et nous envoyons ces images au réseau pour prédire quel type de rotation a été appliqué à l’image. Le réseau effectue simplement une classification à 4 classes pour prédire la rotation.
- La prédiction des rotations n’a aucun sens sémantique, nous utilisons simplement cette tâche prétexte comme un proxy pour apprendre certaines caractéristiques et représentations à utiliser dans une tâche en aval.
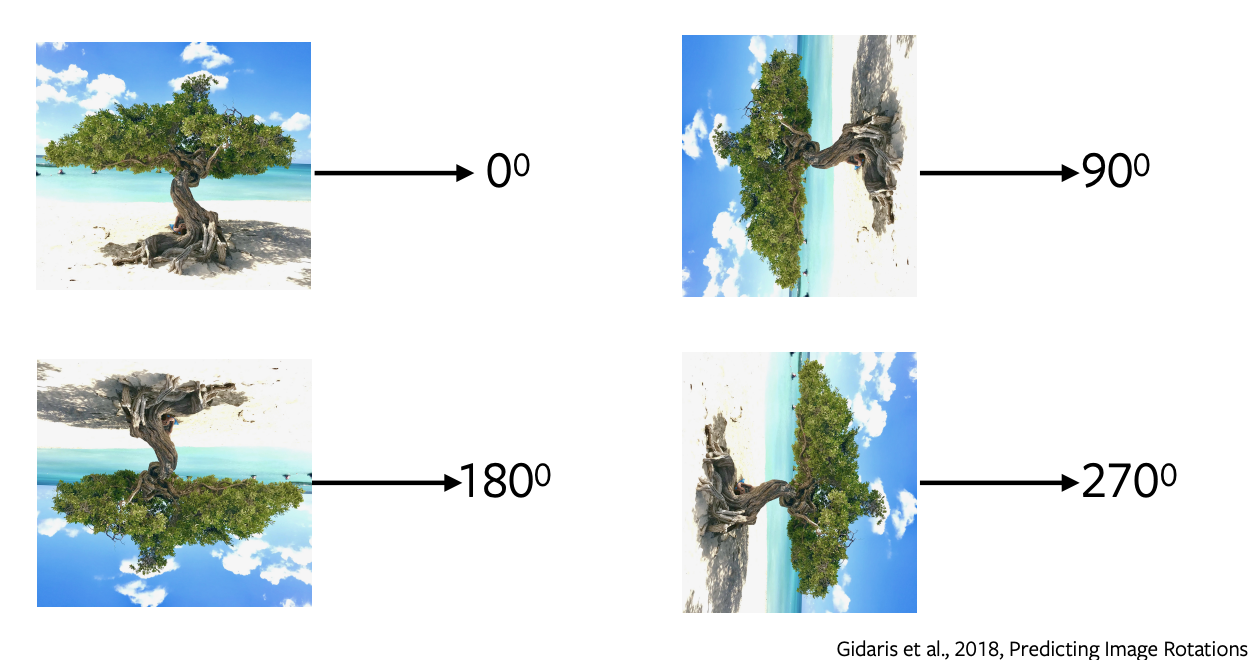
Figure 5 : Rotations de l'image
Pourquoi la rotation est-elle utile ou pourquoi fonctionne-t-elle ?
Il a été prouvé qu’elle fonctionne de manière empirique. L’intuition qui sous-tend cette méthode est que pour prédire les rotations, le modèle doit comprendre les limites approximatives et la représentation d’une image. Par exemple, il devra séparer le ciel de l’eau ou le sable de l’eau ou comprendre que les arbres poussent vers le haut, etc.
Colorisation

Figure 6 : Colorisation
Dans cette tâche de prétexte, on prédit les couleurs d’une image grise. Elle peut être formulée pour n’importe quelle image, il suffit d’enlever la couleur et de donner cette image en niveaux de gris au réseau pour prédire sa couleur. Cette tâche est utile à certains égards, comme pour coloriser les vieux films en niveaux de gris. L’intuition derrière cette tâche est que le réseau doit comprendre certaines informations significatives comme le fait que les arbres sont verts, le ciel est bleu, etc.
Il est important de noter que l’association des couleurs n’est pas déterministe, et que plusieurs vraies solutions existent. Ainsi, pour un objet, s’il y a plusieurs couleurs possibles, le réseau le colorera en gris, ce qui est la moyenne de toutes les solutions possibles. Des travaux récents ont utilisé des auto-encodeurs variationnels et des variables latentes pour diverses colorisations.
Remplir les blancs
Nous cachons une partie d’une image et nous prédisons la partie cachée de la partie restante de l’image qui l’entoure. Cela fonctionne parce que le réseau apprend la structure implicite des données, par exemple pour représenter le fait que les voitures roulent sur les routes, que les bâtiments sont composés de fenêtres et de portes, etc.
Tâches de prétexte pour les vidéos
Les vidéos sont composées de séquences d’images et cette notion est l’idée qui sous-tend l’autosupervision, qui peut être mise à profit pour certaines tâches de prétexte comme la prédiction de l’ordre des images, le remplissage des blancs et le suivi des objets.
Mélanger et apprendre (Shuffle & Learn)

Figure 7 : Interpolation
Lorsque nous avons plusieurs images, nous en extrayons trois et si elles sont extraites dans le bon ordre, nous les qualifions de positives. Dans le cas où elles sont mélangées, nous les qualifions de négatives. Cela devient alors un problème de classification binaire pour prédire si les images sont dans le bon ordre ou non. Ainsi, en donnant un point de départ et un point d’arrivée, nous vérifions si le milieu est une interpolation valide des deux.
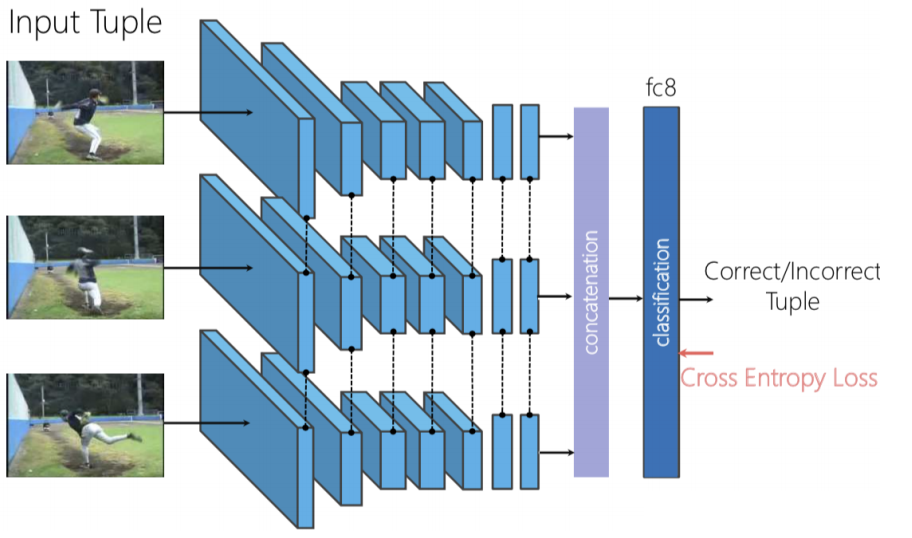
Figure 8 : Architecture Shuffle & Learn
Nous pouvons utiliser un réseau siamois en triplet, où les trois images sont transmises indépendamment, puis nous concaténons les caractéristiques générées et effectuons la classification binaire pour prédire si les images sont mélangées ou non.

Figure 9 : Représentation des voisins les plus proches
Là encore, nous pouvons utiliser l’algorithme des plus proches voisins pour visualiser ce que nos réseaux apprennent. Dans la figure 9 ci-dessus, nous avons d’abord une image requête que nous donnons au réseau pour obtenir une représentation des caractéristiques, puis nous regardons les voisins les plus proches dans l’espace de représentation. En comparant, nous pouvons observer une différence marquée entre les voisins obtenus à partir d’ImageNet, de Shuffle & Learn et de Random.
ImageNet est capable de réduire l’ensemble de la sémantique, car il comprend qu’il s’agit d’une scène de gymnastique pour la première entrée. De même, il peut comprendre qu’il s’agit d’une scène de plein air avec de l’herbe, etc. pour la deuxième requête. En revanche, lorsque nous observons Random, nous pouvons voir qu’il accorde une grande importance à la couleur de l’arrière-plan.
En observant Shuffle & Learn, il n’est pas immédiatement possible de savoir s’il se concentre sur la couleur ou sur le concept sémantique. Après une inspection plus poussée et l’observation de divers exemples, on a constaté qu’il s’agit de la pose de la personne. Par exemple, dans la première image, la personne est à l’envers et dans la seconde, les pieds sont dans une position particulière similaire à celle du cadre de la requête, ignorant la couleur de la scène ou de l’arrière-plan. Le raisonnement est de notre tâche de prétexte était de prédire si les images sont dans le bon ordre ou non, et pour ce faire, le réseau doit se concentrer sur ce qui bouge dans la scène, dans ce cas, la personne.
Cela a été vérifié quantitativement en ajustant cette représentation à la tâche d’estimation des points clés humains, où, étant donné une image humaine, nous prédisons où se trouvent certains points clés comme le nez, l’épaule gauche, l’épaule droite, le coude gauche, le coude droit, etc. Cette méthode est utile pour le suivi et l’estimation de la pose.
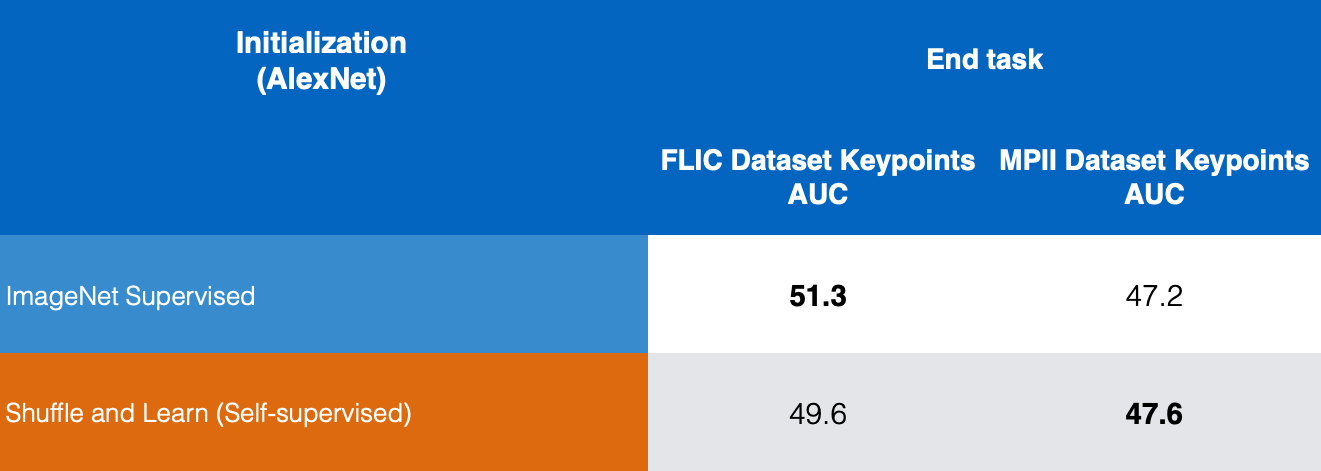
Figure 10 : Comparaison des estimations des points clés
Dans la figure 10, nous comparons les résultats d’ImageNet supervisé et de Shuffle & Learn autosupervisé sur les jeux de données FLIC et MPII. Nous pouvons voir que Shuffle & Learn donne de bons résultats pour l’estimation des points clés.
Tâches de prétexte pour les vidéos et le son
La vidéo et le son sont multimodaux, c’est-à-dire que nous avons deux modalités ou entrées sensorielles, une pour la vidéo et une pour le son. Nous essayons de prédire si le clip vidéo donné correspond ou non au clip audio.

Figure 11 : Echantillonnage vidéo et sonore
Dans le cas d’une vidéo avec le son d’un tambour, nous échantillons la vidéo en images avec le son correspondant et nous appelons ça un ensemble positif. Ensuite, nous prenons l’audio d’une batterie et l’image d’une guitare et les marquons comme un ensemble négatif. Nous pouvons maintenant entraîner un réseau à résoudre ce problème de classification binaire.
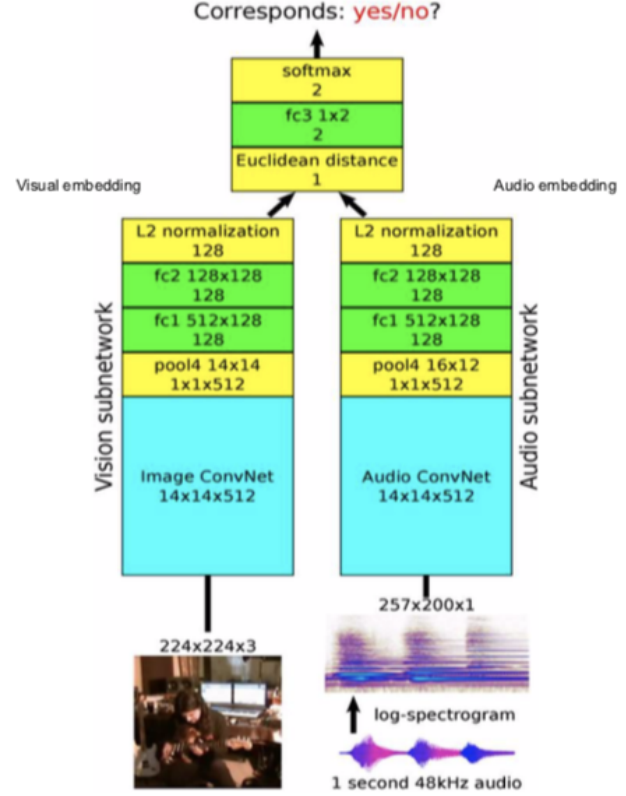
Figure 12 : Architecture
Architecture : nous passons les images vidéo au sous-réseau de vision et l’audio au sous-réseau audio, ce qui donne des caractéristiques et des enchâssements en 128 dimensions. Nous les fusionnons et résolvons comme un problème de classification binaire prédisant si elles correspondent ou non entre elles.
Cela peut être utilisé pour prédire ce qui, dans l’image, pourrait produire un son. L’intuition est que s’il s’agit du son d’une guitare, le réseau doit comprendre l’aspect de la guitare. Même logique pour la batterie.
Comprendre ce que la tâche prétexte apprend
-
Les tâches de prétexte doivent être complémentaires
- Prenons par exemple les tâches de prétexte Position relative et Colorisation. Nous pouvons améliorer les performances en entraînant un modèle pour apprendre les deux tâches de prétexte comme indiqué ci-dessous :
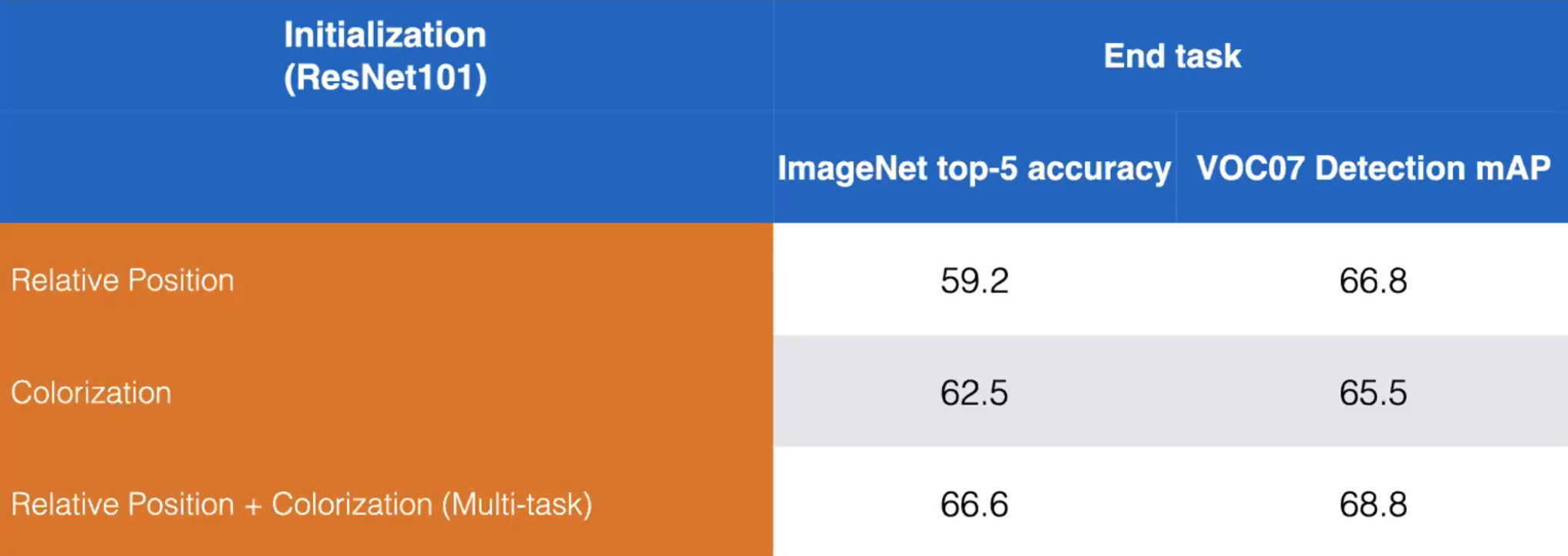
Figure 13 : Comparaison entraînement disjoint vs entraînement combiné des tâches de prétexte de Position Relative et de la Colorisation
-
Une seule tâche de prétexte peut ne pas être la bonne réponse pour apprendre les représentations autosupervisées
-
Les tâches de prétexte varient beaucoup dans ce qu’elles essaient de prédire (difficilement)
- La position relative est facile puisqu’il s’agit d’une simple classification
- Le masquage et le remplissage sont beaucoup plus difficiles => meilleure représentation
- Les méthodes contrastives génèrent encore plus d’informations que les tâches prétexte
-
Comment entraîner de multiples tâches de pré-entraînement ?
- La sortie de la prétexte dépend de l’entrée. La dernière couche entièrement connectée du réseau peut être intervertie en fonction du type de lot.
- Par exemple : un batch d’images en noir et blanc est envoyé au réseau dans lequel le modèle doit produire une image en couleur. Ensuite, la couche finale est permutée et reçoit un batch de patchs pour prédire la position relative.
- En quelle quantité devons-nous entraîner une tâche de prétexte ?
- Règle empirique : avoir une tâche de prétexte très difficile telle qu’elle améliore la tâche en aval.
- En pratique, la tâche de prétexte est entraînée et ne peut pas être ré-entraînée. En développement, elle est entraînée dans le cadre de l’ensemble du pipeline.
Mise à l’échelle de l’apprentissage autosupervisé
Puzzles Jigsaw
-
Partitionner une image en plusieurs tuiles et mélanger ces tuiles. Le modèle est ensuite chargé de rétablir la configuration d’origine des tuiles (Noorozi & Favaro, 2016).
- Prédire quelle permutation a été appliquée à l’entrée
- Cela se fait en créant des lots de tuiles de telle sorte que chaque tuile d’une image soit évaluée indépendamment. Les sorties de convolution sont ensuite concaténées et la permutation est prédite comme dans la figure ci-dessous :
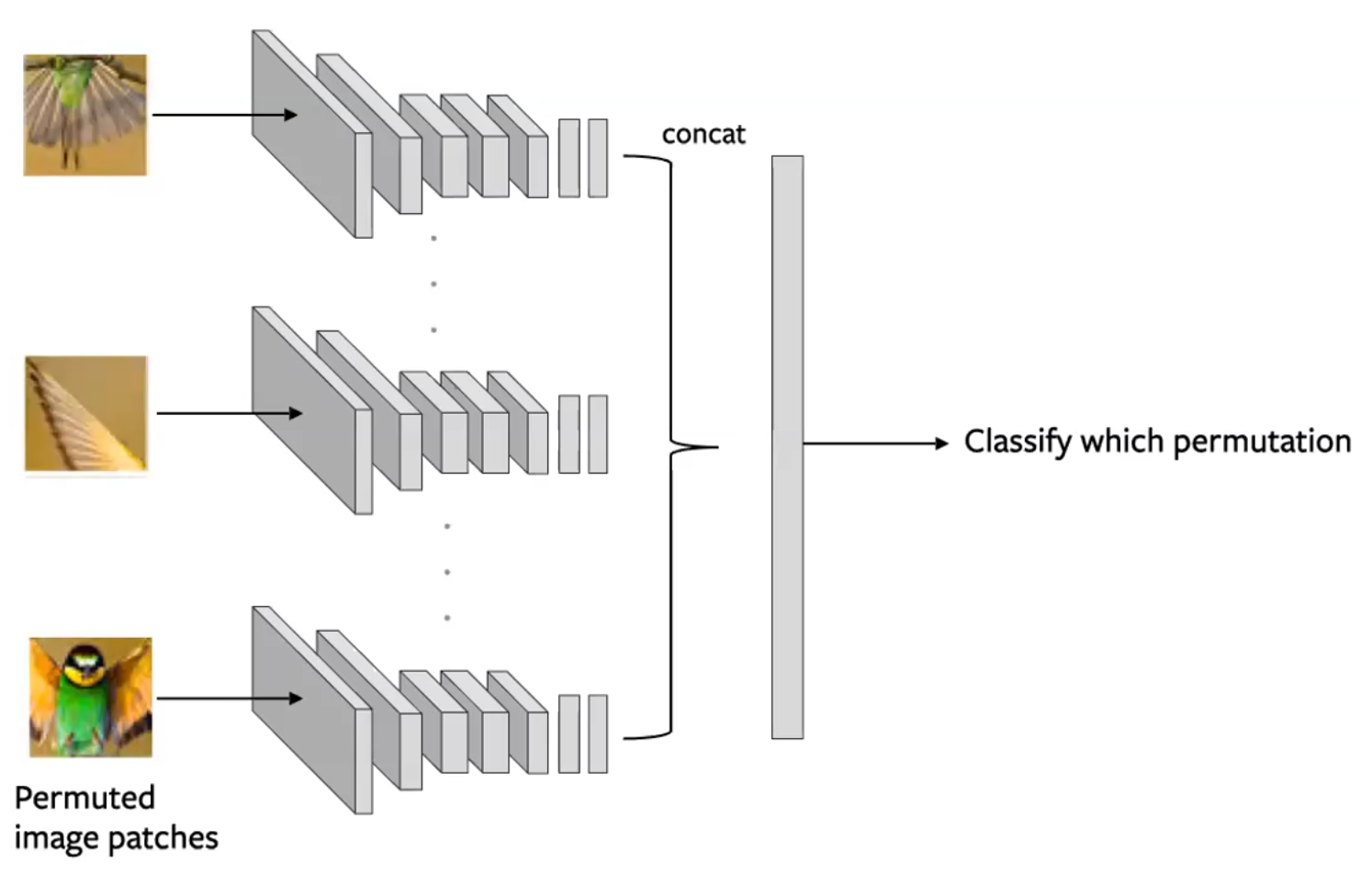
Figure 14 : Architecture d’un réseau siamois pour une tâche de prétexte Jigsaw. Chaque tuile est traversée indépendamment, avec des codages concaténés pour prédire une permutation
- Considérations :
- Utiliser un sous-ensemble de permutations (c’est-à-dire de 9!, utiliser 100)
- Le ConvNet à n classes utilise des paramètres partagés
- La complexité du problème réside dans la taille du sous-ensemble, la quantité d’informations que nous prédisons
-
Parfois, cette méthode peut être plus performante sur les tâches en aval que les méthodes supervisées car le réseau est capable d’apprendre certains concepts sur la géométrie de son entrée.
-
Les lacunes : le few-shot learning (apprentissage avec un nombre limité d’exemples d’entraînement)
- Les représentations autosupervisées ne sont pas aussi efficaces sur l’échantillon
Évaluation : Finetuning vs Classifieur linéaire
Cette forme d’évaluation est une sorte de d’apprentissage par transfert.
- Finetuning : lorsque nous appliquons à notre tâche en aval, nous utilisons notre réseau entier comme une initialisation pour entraîner notre nouveau réseau, en mettant à jour tous les poids.
- Classifieur linéaire : en plus de notre réseau de prétexte, nous entraînons un petit classifieur linéaire pour effectuer notre tâche en aval, en laissant le reste du réseau intact.
Une bonne représentation doit être transférée avec un petit entraînement.
- Il est utile d’évaluer l’apprentissage prétexte sur une multitude de tâches différentes. Nous pouvons le faire en extrayant la représentation créée par les différentes couches du réseau en tant que caractéristiques fixes et en évaluant leur utilité à travers ces différentes tâches.
- Mesure : la précision moyenne (Mean Average Precision en anglais souvent siglée en mAP) de l’ensemble des différentes tâches que nous envisageons.
- Quelques exemples de ces tâches : détection d’objets (en utilisant du finetuning), estimation de la surface (voir le jeu de données NYU-v2)
- Qu’apprend chaque couche ?
- En général, plus les couches sont profondes, plus la précision moyenne sur les tâches en aval utilisant leurs représentations augmente.
- Cependant, la couche finale verra une forte baisse de la mAP en raison de la sur-spécialisation de la couche.
- Cela contraste avec les réseaux supervisés, dans la mesure où la mAP augmente généralement toujours avec la profondeur de la couche.
- Cela montre que la tâche de prétexte n’est pas bien alignée sur la tâche en aval.
📝 Aniket Bhatnagar, Dhruv Goyal, Cole Smith, Nikhil Supekar
Loïck Bourdois
6 Apr 2020