Apprentissage profond pour le traitement du langage naturel
🎙️ Mike LewisVue d’ensemble
- Progrès impressionnants au cours des dernières années :
- Les humains préfèrent la traduction automatique aux traducteurs humains pour certaines langues
- Des performances supérieures à l’humaine pour de nombreux jeux de données de réponse aux questions
- Les modèles linguistiques génèrent des paragraphes fluides (par exemple Radford et al. (2019))
- Un minimum de techniques spécialisées nécessaires par tâche, peut être réalisé avec des modèles assez génériques
Modèles de langue
- Les modèles linguistiques attribuent une probabilité à un texte : $p(x_0, \cdots, x_n)$
- Beaucoup de phrases possibles donc on ne peut pas juste entraîner un classifieur
- La méthode la plus populaire consiste à factoriser la distribution en utilisant la règle de la chaîne :
Modèles de langue neuronaux
Grossièrement, nous entrons le texte dans un réseau de neurones qui va associer tout le contexte à un vecteur. Ce vecteur représente le mot suivant et nous disposons d’une matrice d’enchâssement de mots importants. Cette matrice contient un vecteur pour chaque mot possible que le modèle peut produire. Nous calculons la similarité par le produit scalaire du vecteur de contexte et de chacun des vecteurs de mots. Nous obtenons une probabilité de prédire le mot suivant, puis nous entraînons ce modèle par maximum de vraisemblance. Le détail clé ici est que nous ne traitons pas directement les mots mais des sous-mots ou des caractères.
\[p(x_0 \mid x_{0, \cdots, n-1}) = \text{softmax}(E f(x_{0, \cdots, n-1}))\]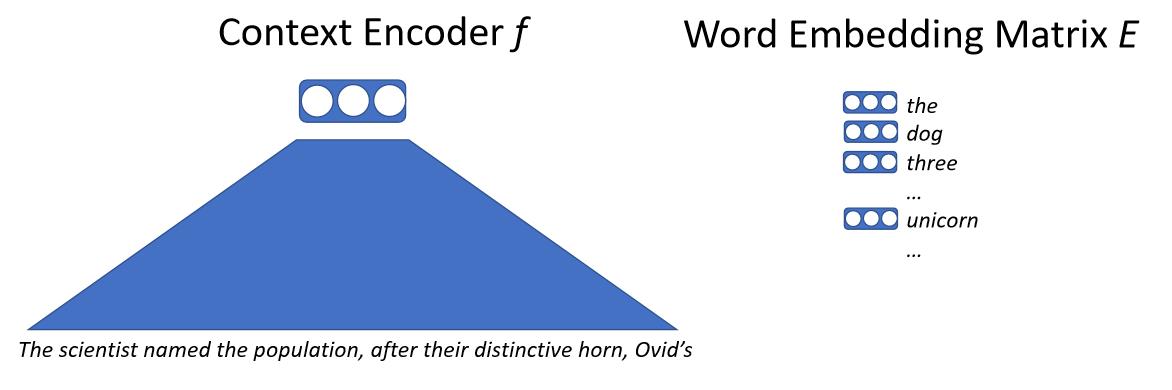
Modèles de langue convolutifs
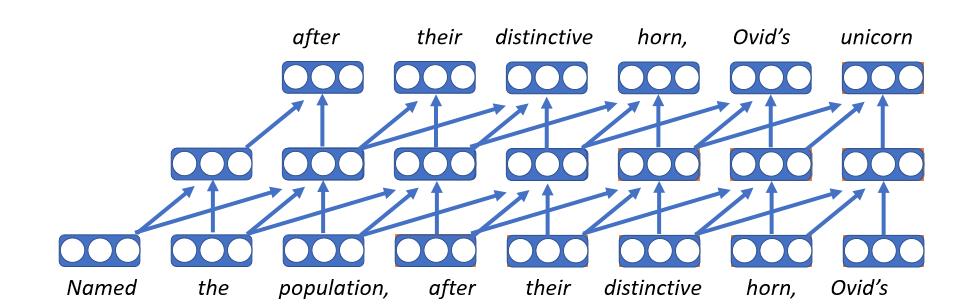
- Il s’agit du premier type de modèle linguistique neuronal.
- Il consiste à enchâsser chaque mot comme un vecteur, qui est une table de recherche de la matrice d’enchâssement, de sorte que le mot a le même vecteur quel que soit le contexte dans lequel il apparaît. On applique ensuite le même réseau feed forward à chaque pas de temps.
- Malheureusement, la longueur fixe signifie qu’il ne peut être conditionné qu’à un contexte délimité.
- Ces types de modèles ont l’avantage d’être très rapides.
Modèles de langue récurrents
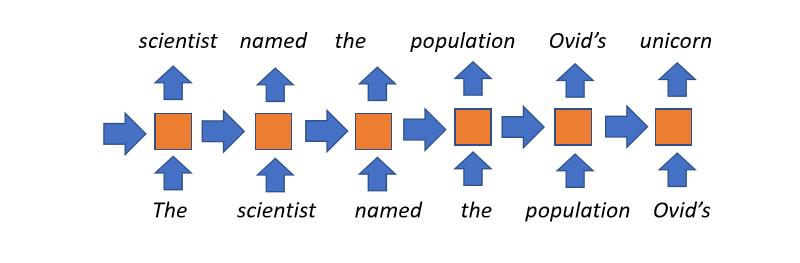
- L’approche la plus populaire jusqu’à il y a quelques années.
- Conceptuellement simple : à chaque pas de temps, nous maintenons un certain état (reçu du pas de temps précédent, qui représente ce que nous avons lu jusqu’à présent). Ceci est combiné avec le mot courant qui est lu et utilisé à l’état ultérieur. Ensuite, nous répétons ce processus pour autant de pas de temps que nécessaire.
- Utilise un contexte sans limite : en principe, le titre d’un livre affecterait les états cachés du dernier mot du livre.
- Inconvénients :
- Toute l’histoire de la lecture du document est compressée en un vecteur de taille fixe à chaque étape temporelle, ce qui constitue le goulot d’étranglement de ce modèle.
- Les gradients ont tendance à disparaître avec des contextes longs.
- Impossible de paralléliser les étapes temporelles donc l’entraînement est lent.
Modèles de langue basé sur un transformer
- Modèle le plus récent en traitement du langage naturel.
- Pénalité révolutionnaire.
- Trois grandes étapes :
- Étape d’entrée
- $n$ fois les blocs de transformer (couches d’encodage) avec différents paramètres
- Etape de sortie
- Exemple avec 6 modules de transformer (couches d’encodage) dans le papier introduisant le transformer :
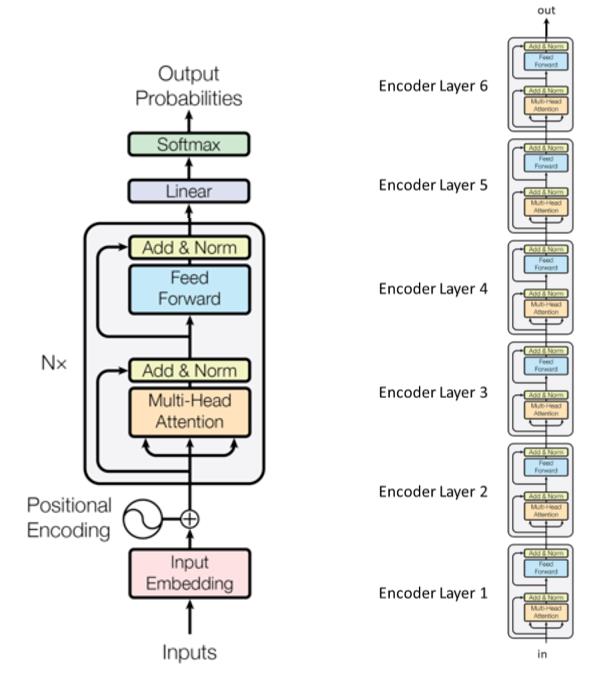
Les sous-couches sont reliées par les cases intitulées Add&Norm. La partie Add signifie qu’il s’agit d’une connexion résiduelle, qui contribue à empêcher la disparition du gradient. La partie Norm désigne ici la normalisation des couches.
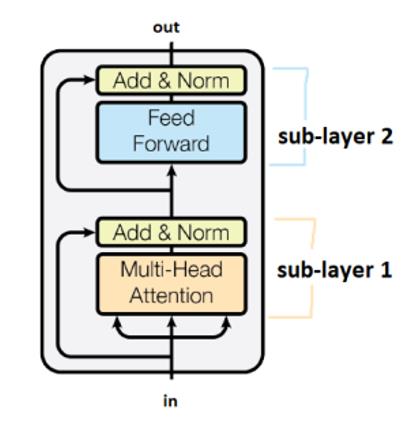
Il convient de noter que les transformers partagent les poids entre les étapes du temps.
Attention multi-têtes
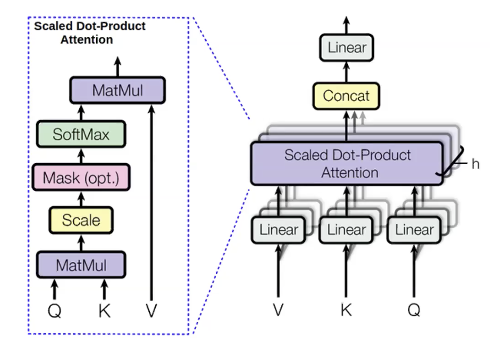
Pour les mots que nous essayons de prédire, nous calculons des valeurs appelées query(q). Nous appelons keys(k) tous les mots précédents utilisés pour prédire. La requête (q) nous renseigne sur le contexte, par exemple les adjectifs précédents. La clé (k) est comme un label contenant des informations sur le mot courant, par exemple si c’est un adjectif ou non. Une fois que q est calculée, nous pouvons dériver la distribution des mots précédents ($p_i$) :
\[p_i = \text{softmax}(q,k_i)\]Ensuite, nous calculons des quantités appelées values(v) pour les mots précédents. Les valeurs représentent le contenu des mots.
Une fois que nous avons les valeurs (v), nous calculons les états cachés en maximisant la distribution de l’attention :
\[h_i = \sum_{i}{p_i v_i}\]Nous calculons la même chose avec différentes requêtes, valeurs et clés plusieurs fois en parallèle. La raison en est que nous voulons prédire le mot suivant en utilisant différentes choses. Par exemple, lorsque nous prédisons le mot « licornes » en utilisant les trois mots précédents « Ces », « cornues » et « blanc argenté ». Nous savons que c’est une licorne par « cornue » et « blanc argenté ». Nous pouvons savoir qu’il s’agit du pluriel « licornes » par « Ces ». Par conséquent, nous voulons utiliser ces trois mots pour savoir quel sera le prochain mot. L’attention à plusieurs têtes est une façon de laisser chaque mot regarder plusieurs mots précédents.
Un grand avantage de l’attention multi-têtes est qu’elle est très parallélisable. Contrairement aux RNNs, le calcul de toutes les têtes des modules d’attention multi-têtes et toutes les étapes de temps peut se faire en même temps. Un des problèmes du calcul de tous les pas de temps en une fois est qu’il pourrait également examiner les mots futurs, alors que nous ne voulons que conditionner les mots précédents. Une solution à ce problème est ce que l’on appelle le masquage de l’auto-attention. Le masque est une matrice triangulaire supérieure qui comporte des zéros dans le triangle inférieur et une infinité négative dans le triangle supérieur. L’effet de l’ajout de ce masque à la sortie du module d’attention est que chaque mot à gauche a un score d’attention beaucoup plus élevé que les mots à droite, de sorte que le modèle en pratique se concentre uniquement sur les mots précédents. L’application du masque est cruciale dans le modèle linguistique car elle le rend mathématiquement correct. Cependant, dans les modules encodeurs, le contexte bidirectionnel peut être utile.
Un détail pour faire fonctionner le transformer est d’ajouter l’enchâssement positionnel à l’entrée (l’ordre des mots dans un texte). Dans le langage, certaines propriétés comme l’ordre sont importantes à interpréter. La technique utilisée ici est l’apprentissage d’enchâssements séparés à différents moments et les ajouter à l’entrée de sorte que l’entrée est maintenant la somme du vecteur mot et du vecteur positionnel. Cela donne des informations sur l’ordre.
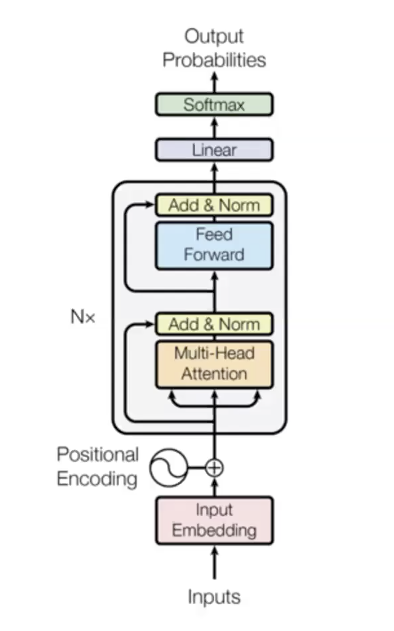
Pourquoi le modèle est si bon :
- Il donne des liens directs entre chaque paire de mots. Chaque mot peut accéder directement aux états cachés des mots précédents, ce qui atténue la disparition des gradients. Il apprend très facilement une fonction très coûteuse.
- Toutes les étapes temporelles sont calculées en parallèle.
- L’auto-attention est quadratique (tous les pas de temps peuvent s’occuper de tous les autres), ce qui limite la longueur maximale des séquences.
Quelques astuces (notamment pour l’attention multi-tête et le codage positionnel) et le décodage des modèles de langue
Astuce 1 : l’utilisation de la normalisation par couches pour stabiliser l’entraînement
- Astuce très importante pour les transformers
Astuce 2 : échauffement (warm-up) et grille d’entraînement utilisant la racine carrée inverse
- Utiliser une grille de taux d’apprentissage fonctionne bien pour que les transformers. Il faut faire décroître le taux d’apprentissage de façon linéaire de zéro à des millièmes de pas.
Truc 3 : soigner l’initialisation
- Vraiment utile pour une tâche comme la traduction automatique
Astuce 4 : lissage
- Vraiment utile pour une tâche comme la traduction automatique
Voici les résultats de certaines méthodes mentionnées ci-dessus. Dans ces tests, la métrique de droite appelée ppl était la perplexité (plus la ppl est basse, mieux c’est).
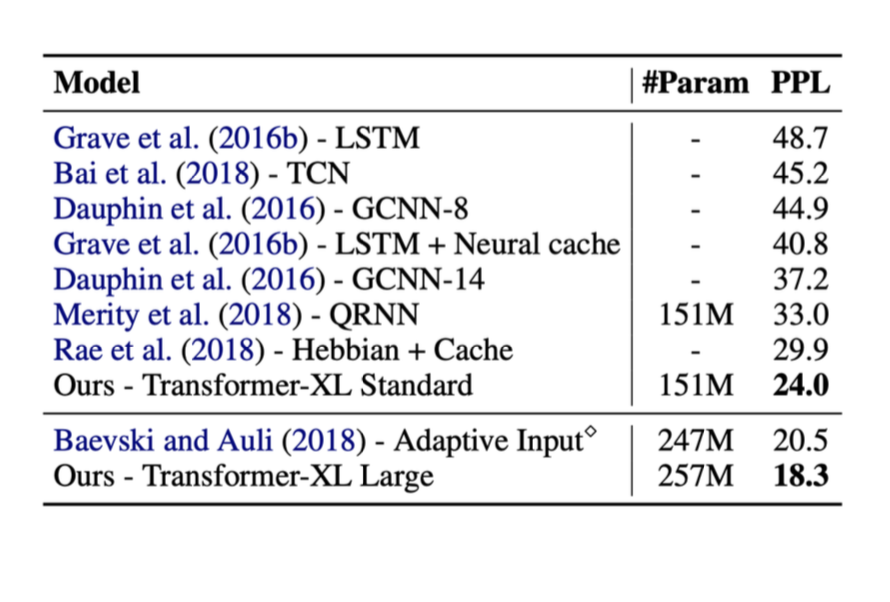
La performance a été grandement améliorée avec l’introduction des transformers.
Quelques faits importants sur les transformers
- Biais inductif minime
- Tous les mots sont directement liés, ce qui atténue la disparition des gradients
- Tous les pas de temps sont calculés en parallèle
L’auto-attention est quadratique (tous les pas de temps peuvent s’occuper de tous les autres), ce qui limite la longueur maximale de la séquence. La nature quadratique entraîne aussi que la dépense augmente linéairement ce qui pourrait poser un problème en pratique.

Les transformers passent à l’échelle très bien
- Des données illimitées pour l’entraînement (n’importe quel texte sur internet), bien plus que ce dont vous avez besoin.
- Le GPT-2 a utilisé 2 milliards de paramètres en 2019.
- Les modèles récents (lors de ce cours en 2020) utilisent plusieurs milliards de paramètres : 17Mds pour le T5, 175Mds pour le GPT3.
Décodage des modèles de langue
Cette section est davantage détaillée dans la partie 2 de la semaine 12 disponible ici.
Nous pouvons maintenant entraîner une distribution de probabilité sur le texte. Grossièrement, nous pouvons obtenir un nombre exponentiel de sorties possibles donc nous ne pouvons pas calculer le maximum. Le choix effectué pour votre premier mot peut avoir une incidence sur toutes les autres décisions. Ainsi, étant donné cela, le décodage gourmand (greedy decoding) a été introduit comme suit.
Le décodage gourmand ne fonctionne pas
Nous prenons les mots les plus vraisemblables à chaque pas de temps. Cependant, rien ne garantit que cela donne la séquence la plus probable car si nous devons franchir cette étape à un moment donné, il n’y a aucun moyen de revenir en arrière pour annuler les sessions précédentes.
Une recherche exhaustive n’est pas non plus possible
Il faut calculer toutes les séquences possibles et en raison de la complexité en $O(V^T)$, c’est trop cher computationnellement.
Questions des étudiants
Quel est l’avantage d’un modèle d’attention à plusieurs têtes par rapport à un modèle d’attention à une seule tête ?
Pour prédire le mot suivant, vous devez observer plusieurs choses séparées, en d’autres termes, l’attention peut être portée sur plusieurs mots précédents en essayant de comprendre le contexte nécessaire pour prédire le mot suivant.
Comment les transformers résolvent-ils les goulots d’étranglement informationnels des ConvNets et des RNNs ?
Les modèles d’attention permettent une connexion directe entre tous les mots, ce qui permet de conditionner chaque mot à tous les mots précédents, éliminant ainsi efficacement ce goulot d’étranglement.
En quoi les transformers diffèrent-ils des RNNs dans la manière dont ils exploitent la parallélisation des GPUs ?
Les modules d’attention multi-têtes des transformers sont hautement parallélisables alors que les RNNs ne le sont pas et ne peuvent donc pas tirer profit de la technologie GPU. En fait, les transformers calculent tous les pas de temps en une seule passe vers l’avant.
📝 Jiayu Qiu, Yuhong Zhu, Lyuang Fu, Ian Leefmans
Loïck Bourdois
20 Apr 2020