Apprentissage autosupervisé, ClusterFit et PIRL
🎙️ Ishan MisraQue manque-t-il aux tâches de prétexte ? L’espoir de la généralisation
La tâche de prétexte comprend généralement des étapes de pré-entraînement qui sont autosupervisées. Puis nous avons nos tâches de transfert qui sont souvent de classification ou de détection. Nous espérons que la tâche de pré-entraînement et les tâches de transfert sont « alignées », c’est-à-dire que la résolution de la tâche de prétexte aide à résoudre notre tâche de transfert. Ainsi, beaucoup de recherches sont nécessaires afin de concevoir une tâche de prétexte et la mettre en œuvre de façon optimale.
Cependant, il est très difficile de savoir pourquoi l’exécution d’une tâche non sémantique produit de bonnes caractéristiques. Par exemple, pourquoi devrions-nous nous attendre à apprendre la « sémantique » tout en résolvant quelque chose comme un puzzle ? Ou pourquoi prédire les mots-dièse à partir d’images aide à apprendre un classifieur sur des tâches de transfert ? Comment concevoir de bonnes tâches de pré-entraînement qui soient bien alignées avec les tâches de transfert ?
Une façon d’évaluer ce problème est d’examiner les représentations à chaque couche (voir figure 1). Si les représentations de la dernière couche ne sont pas bien alignées avec la tâche de transfert, alors la tâche de pré-entraînement peut ne pas être la bonne tâche à résoudre.
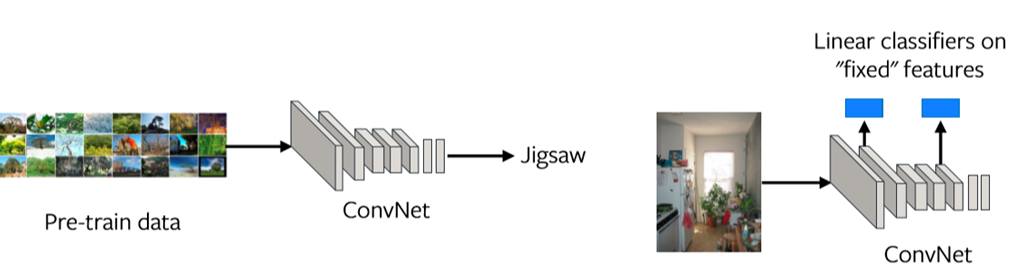
Figure 1 : Représentation des éléments à chaque couche
La figure 2 représente la précision moyenne à chaque couche pour des classifieurs linéaires sur le jeu de données VOC07 avec un pré-entraînement Jigsaw. Il est clair que la dernière couche est très spécialisée pour le problème Jigsaw.
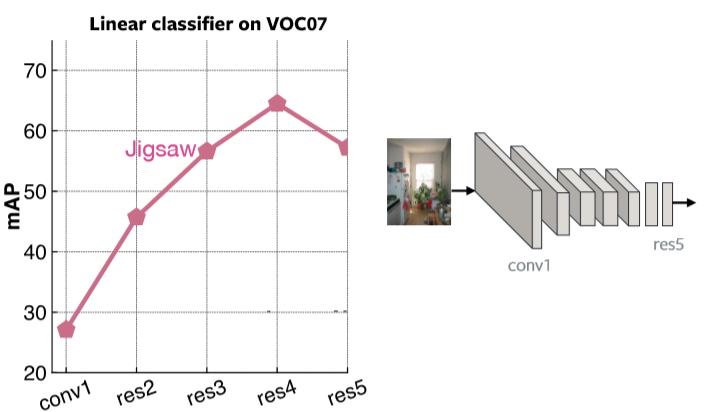
Figure 2 : Performance de Jigsaw en fonction de chaque couche
Qu’attendons-nous des caractéristiques pré-entraînées ?
-
Représenter la façon dont les images sont liées les unes aux autres => ClusterFit : améliorer la généralisation des représentations visuelles
-
Être robuste aux facteurs de nuisance, c’est à dire être invariant, par exemple à l’éclairage, l’emplacement exact des objets, la couleur => PIRL : apprentissage autosupervisé des représentations invariantes du prétexte
Deux moyens d’atteindre les propriétés ci-dessus sont le clustering et l’apprentissage contrastif. Ils ont commencé à fonctionner bien mieux que les tâches de prétexte conçues jusqu’à présent. Une méthode qui appartient au clustering est ClusterFit et une autre qui tombe dans l’invariance est PIRL.
ClusterFit : améliorer la généralisation des représentations visuelles
Le clustering de l’espace des caractéristiques est un moyen de voir quelles images sont liées les unes aux autres.
Méthode
ClusterFit suit deux étapes. L’une est l’étape du cluster, l’autre est l’étape de la prédiction.
Cluster : regroupement des caractéristiques
Nous prenons un réseau pré-entraîné et l’utilisons pour extraire un ensemble de caractéristiques d’un ensemble d’images. Le réseau peut être n’importe quel type de réseau pré-entraîné. Les $K$-means sont alors effectués sur ces caractéristiques, de sorte que chaque image appartient à un cluster qui devient son label.

Figure 3 : Etape du cluster
Entraînement : prévoir l’affectation des clusters
Pour cette étape, nous entraînons un réseau à partir de zéro afin de prédire les pseudo labels des images. Ces pseudo labels sont ceux que nous avons obtenus lors de la première étape par le clustering.
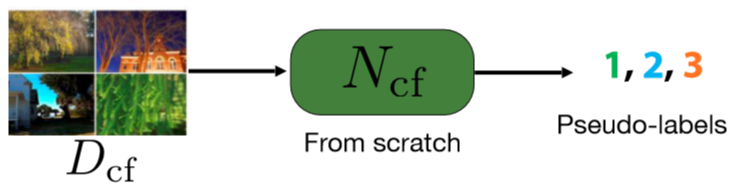
Figure 4 : Etape de prédiction
Une tâche standard de pré-entraînement et de transfert pré-entraîne d’abord un réseau et l’évalue ensuite sur des tâches en aval, comme le montre la première ligne de la figure 5. ClusterFit effectue le pré-entraînement sur un jeu de données $D_{cf}$ pour obtenir le réseau pré-entraîné $N_{pre}$. Le pré-entraînement $N_{pre}$ est effectué sur un jeu de données $D_{cf}$ pour générer des clusters. Nous apprenons ensuite un nouveau réseau $N_{cf}$ à partir de zéro sur ces données. Enfin, on utilise $N_{cf}$ pour toutes les tâches en aval.
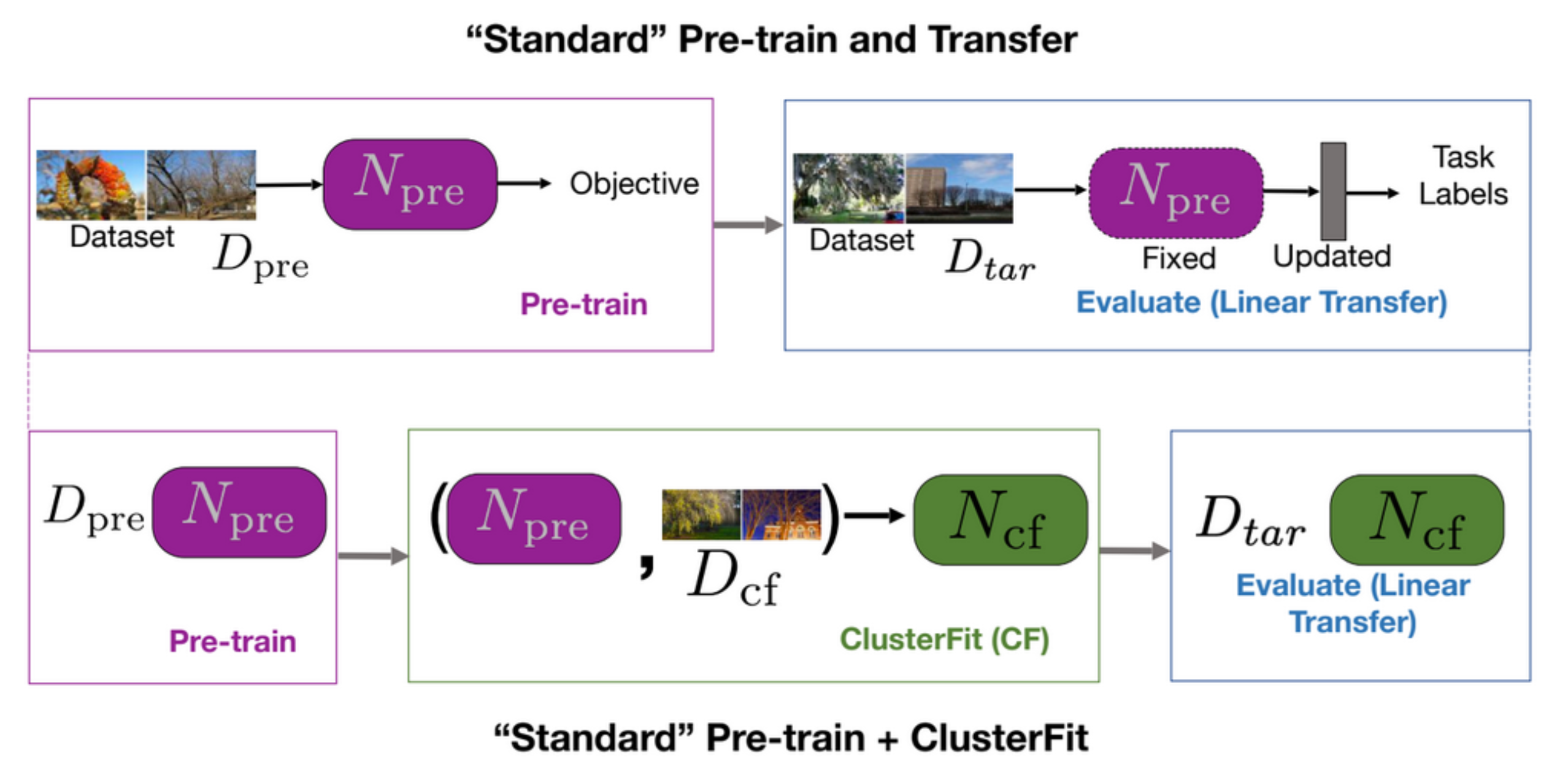
Figure 5 Pré-entraînement standard + transfert vs Pré-entraînement standard + ClusterFit
Pourquoi ClusterFit fonctionne ?
La raison pour laquelle ClusterFit fonctionne est que lors de l’étape de clustering, seules les informations essentielles sont saisies et les artefacts sont jetés, ce qui permet au second réseau d’apprendre quelque chose de légèrement plus générique.
Pour comprendre ce point, une expérience assez simple est réalisée. Nous ajoutons un bruit de label à ImageNet-1K et entraînons un réseau basé sur ce jeu de données. Ensuite, nous évaluons la représentation des caractéristiques de ce réseau sur une tâche en aval sur ImageNet-9K. Comme le montre la figure 6, nous ajoutons différentes quantités de bruit de label au réseau ImageNet-1K et nous évaluons les performances de transfert de différentes méthodes sur ImageNet-9K.
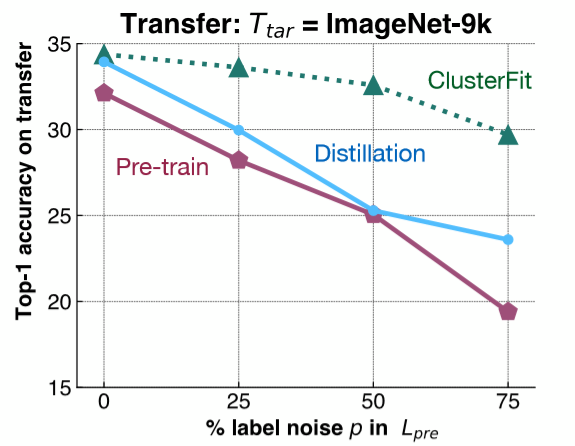
Figure 6 : Expérience de contrôle
La ligne rose indique les performances du réseau pré-entraîné, qui diminuent à mesure que le bruit du label augmente. La ligne bleue représente la distillation du modèle où nous prenons le réseau initial et l’utilisons pour générer des labels. La distillation est généralement plus performante que le réseau pré-entraîné. La ligne verte, ClusterFit, est toujours meilleure que l’une ou l’autre de ces méthodes. Ce résultat valide notre hypothèse.
Pourquoi utiliser la méthode de distillation pour comparer ? Quelle est la différence entre la distillation et ClusterFit ?
Dans la distillation de modèle, nous prenons le réseau pré-entraîné et utilisons les labels que le réseau a prédits de manière plus douce pour générer des labels pour nos images. Par exemple, nous obtenons une répartition sur toutes les classes et utilisons cette répartition pour entraîner le second réseau. La distribution plus douce permet d’améliorer les classes initiales que nous avons. Dans ClusterFit, nous ne nous soucions pas de l’espace du label.
Performance
Nous appliquons cette méthode à l’apprentissage autosupervisé. Ici, Jigsaw est appliqué pour obtenir le réseau pré-entraîné $N_{pre}$ dans ClusterFit. La figure 7 montre que les performances de transfert sur différents jeux de données montrent des gains surprenants par rapport à d’autres méthodes autosupervisées.
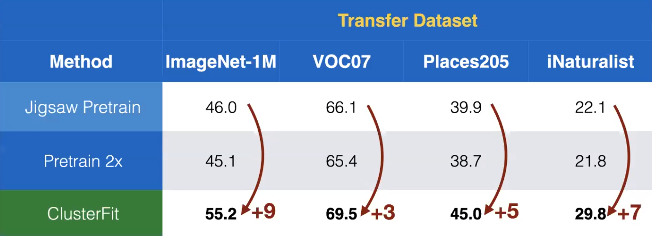
Figure 7 : Performances de transfert sur différents jeux de données
ClusterFit fonctionne pour tout réseau pré-entraîné. Les gains sans données supplémentaires, labels ou changements d’architecture sont visibles dans la figure 8. D’une certaine manière, on peut donc considérer ClusterFit comme une étape de finetuning autosupervisée améliorant la qualité de la représentation.
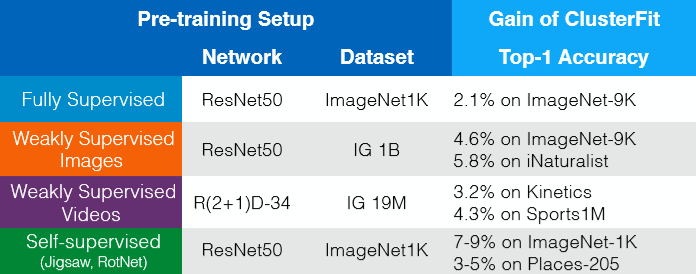
Figure 8 : Gains sans données supplémentaires, sans labels ni changements d'architecture
PIRL : apprentissage autosupervisé des représentations invariantes de prétexte
Apprentissage contrastif
L’apprentissage contrastif est un cadre général qui tente d’apprendre un espace de caractéristiques afin de combiner/rassembler des points qui sont liés et écarter des points qui ne sont pas liés.

Figure 9 : Groupes d'images liées et non liées
Dans ce cas, imaginons que les cases bleues sont liées, les vertes sont liées et les violettes sont liés.
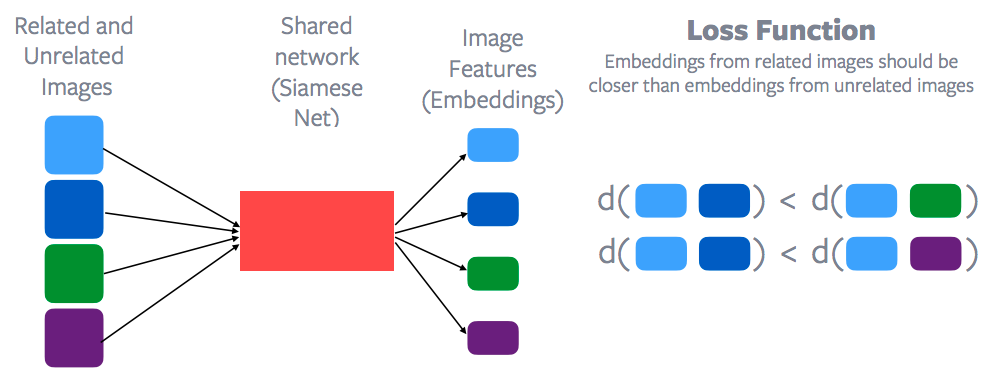
Figure 10 : Fonction de perte et apprentissage contrastif
Les caractéristiques de chacun de ces points de données sont extraites par le biais d’un réseau partagé, appelé réseau siamois. Ensuite, une fonction de perte contrastive est appliquée pour essayer de minimiser la distance entre les points bleus par opposition, par exemple, à la distance entre le point bleu et le point vert. Ou du moins la distance entre les points bleus devrait être inférieure à la distance entre le point bleu et le point vert ou bien entre le point bleu et le point violet. Ainsi, l’espace d’enchâssement des échantillons apparentés doit être beaucoup plus proche que l’espace d’enchâssement des échantillons non apparentés. C’est l’idée générale de ce qu’est l’apprentissage contrastif dont Yann a été l’un des premiers à proposer le principe. L’apprentissage contrastif fait donc un retour en force dans l’apprentissage autosupervisé puisqu’une grande partie des méthodes de pointe dans le domaine sont basées sur l’apprentissage contrastif.
Comment définir ce qui est lié ou non lié ?
La question principale est de savoir comment définir ce qui est lié et ce qui ne l’est pas. Dans le cas de l’apprentissage supervisé, il est assez clair que toutes les images de chiens sont des images liées et toute image qui n’est pas un chien est fondamentalement une image non liée. Mais il n’est pas aussi clair de définir ce qui est lié et ce qui ne l’est pas dans le cas d’apprentissage autosupervisé. L’autre grande différence avec une tâche de prétexte est que l’apprentissage contrastif raisonne avec vraiment beaucoup de données à la fois. La fonction de perte implique toujours plusieurs images. Dans la première ligne, il s’agit essentiellement d’images bleues et d’images vertes, et dans la deuxième ligne, d’images bleues et d’images violettes. Mais pour une tâche de prétexte comme par exemple Jigsaw ou la rotation, nous raisonnons toujours sur une seule image de manière indépendante. C’est donc une autre différence : l’apprentissage contrastif raisonne sur plusieurs points de données à la fois.
On pourrait utiliser des techniques similaires à celles qui ont été évoquées précédemment : des images vidéo ou la nature séquentielle des données. Les images qui sont proches dans une vidéo sont liées et les images d’une autre vidéo ou qui sont plus éloignées dans le temps ne sont pas liées. Ces techniques ont constitué la base de nombreuses méthodes d’apprentissage autosupervisées dans ce domaine. Cette méthode est appelée CPC (codage prédictif contrastif) et repose sur la nature séquentielle d’un signal. Les échantillons qui sont proches, comme dans l’espace-temps, sont liés et les échantillons qui sont plus éloignés dans l’espace-temps ne sont pas liés. Une quantité assez importante de travaux exploite ce principe : il peut s’agir de la parole, de la vidéo, du texte ou d’images. Récemment, des travaux ont porté sur la vidéo et l’audio, ce qui signifie qu’une vidéo et son audio correspondant sont des échantillons liés et que la vidéo et l’audio d’une autre vidéo sont des échantillons non liés.
Suivi des objets (tracking)
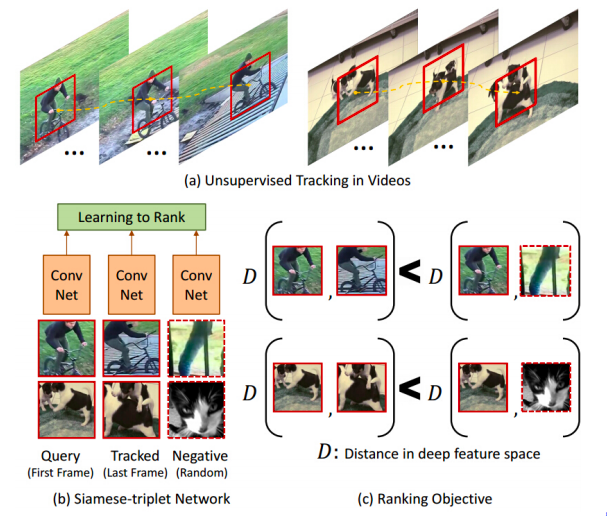
Figure 11 : Suivi des objets
En passant un tracker d’objets sur une vidéo cela nous donne un patch mobile. Tout patch qui a été suivi par le tracker est lié au patch original. En revanche, tout patch provenant d’une autre vidéo n’est pas un patch apparenté. Cela donne donc un ensemble d’échantillons liés et non liés. Cette notation de distance est visible dans la figure 11(c). Le réseau essaie d’apprendre que les patchs provenant d’une même vidéo sont liés et que les patchs provenant de vidéos différentes ne sont pas liés. D’une certaine manière, il apprend automatiquement les différentes poses d’un objet. Il essaie de regrouper ensemble les images de vélo vu sous différents angles de même pour les images de chien.
Patchs proches vs patchs lointains dans une image
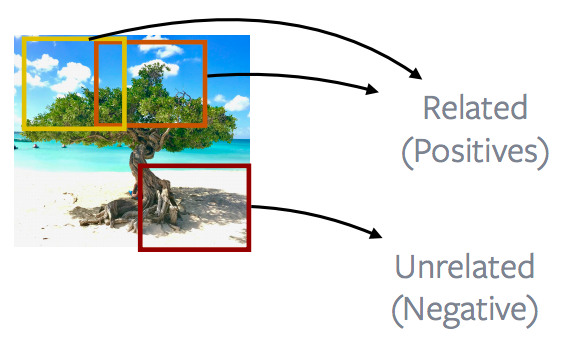
Figure 12 : Patchs proches vs patchs éloignés
Les méthodes CPCv1 et CPCv2 exploitent la distance entre deux patchs dans une image donnée. Ainsi, les patchs d’images proches sont appelés positifs et les patchs d’images plus éloignés sont appelées négatifs. Le but est de minimiser la perte contrastive en utilisant cette définition de positifs et de négatifs.
Patchs d’une image vs patchs d’autres images
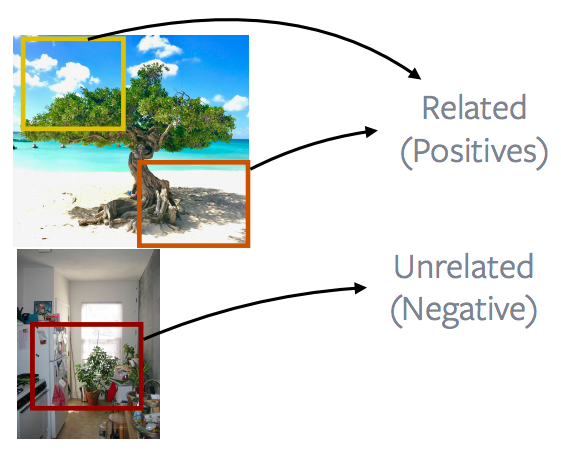
Figure 13 : Patchs d'une image vs Patchs d'autres images
La façon la plus populaire ou la plus performante de procéder consiste à regarder les patchs provenant d’une image et à les mettre en contraste avec les patchs provenant d’une autre image. Ceci constitue la base de nombreuses méthodes populaires comme la discrimination d’instance, MoCo, PIRL, SimCLR. L’idée est essentiellement ce qui est montré dans la figure 13. Pour aller plus dans les détails, ces méthodes consistent à extraire d’une image des taches complètement aléatoires. Ces patchs peuvent se chevaucher, être contenus les uns dans les autres ou s’effondrer complètement, puis appliquer une augmentation des données. Dans ce cas, par exemple, flouter une couleur ou en enlever une.
Ces deux taches sont alors définies comme des exemples positifs. Un autre patch est extrait d’une image différente. Il s’agit là encore d’une tache aléatoire qui sert à créer nos négatifs.
Beaucoup de ces méthodes extraient énormément d’exemples négatifs et puis effectuent un apprentissage contrastif.
Principe sous-jacent pour les tâches de prétexte
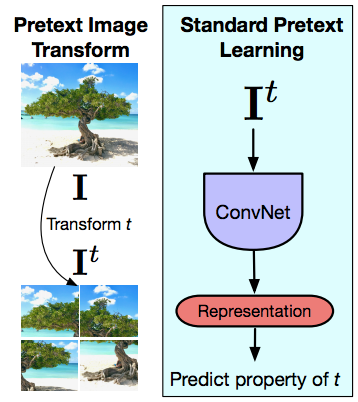
Figure 14 : Transformation des images du prétexte et apprentissage du prétexte standard
Passons maintenant à PIRL et essayons de comprendre quelle est la principale différence entre les tâches de prétexte et comment l’apprentissage contrastif est très différent des tâches de prétexte.
L’idée des tâches de prétexte est de donner à une image une transformation préalable (une transformation Jigsaw pour PIRL), puis de passer cette image transformée dans un ConvNet pour essayer de prédire la propriété de la transformation qui a été appliquée (permutation, rotation, changement de couleur, etc.). Ainsi, les tâches de prétexte raisonnent toujours à propos d’une seule image à la fois. Le deuxième point est que la tâche que nous effectuons doit capturer une certaine propriété de la transformation. Mais malheureusement, cela signifie que les représentations de la dernière couche capturent une propriété de très bas niveau du signal comme la rotation par exemple. Alors que ce qui est conçu ou ce que l’on attend de ces représentations, est qu’elles soient invariantes. Par exemple être capable de reconnaître un chat, peu importe si le chat est debout ou que le chat est tourné à 90 degrés. Alors que lorsque nous résolvons cette tâche de prétexte, nous imposons la chose exactement inverse. Nous disons que nous devrions être capables de reconnaître si l’image a été tourné sur un côté. Il y a de nombreuses exceptions où l’on veut vraiment que ces représentations de bas niveau soient covariantes mais ces exceptions sont liées aux tâches (en aval) que nous effectuons.
Quelle est l’importance de l’invariance ?
L’invariance a été le mot d’ordre pour l’apprentissage des caractéristiques. Les réseaux supervisés, comme par exemple AlexNet, sont entraînés à être invariants à l’augmentation des données. Vous voulez que le réseau classifie différentes générations ou différentes rotations d’une image plutôt que de lui demander de prédire quelle a été la transformation appliquée à l’entrée.
PIRL
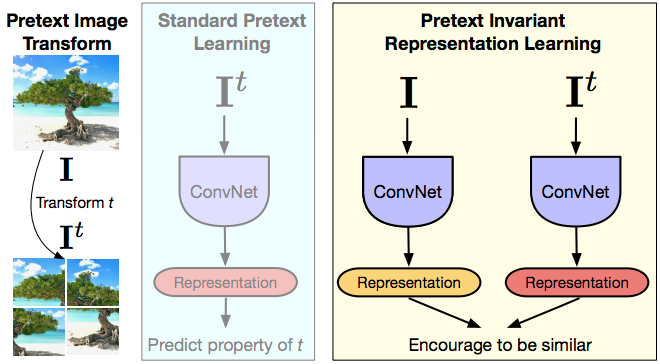
Figure 15 : PIRL
PIRL est l’acronyme de « Pretext Invariant Representation Learning », où nous souhaitons que la représentation soit invariante ou capture le moins d’informations possible de la transformation d’entrée. Ainsi, nous avons l’image, la version transformée de cette image et donnons ces deux images à un ConvNet. Nous obtenons des représentations et les encourageons à être similaires. En ce qui concerne la notation mentionnée plus haut, l’image $I$ et toute version transformée de cette image $I^t$ sont des échantillons apparentés et toute autre image est un échantillon non lié. Nous espérons alors que la représentation contient très peu d’informations sur la transformée $t$.
La partie liée à l’apprentissage contrastif consiste donc à avoir la caractéristique sauvegardée $v_I$ provenant de l’image originale $I$ et la caractéristique $v_{I^t}$ provenant de la version transformée et à vouloir que ces deux représentations soient identiques. D’une certaine manière, c’est comme un apprentissage multitâche, mais sans vraiment essayer de prédire les deux rotations conçues.
Ici nous essayons d’être invariant à la tâche de Jigsaw.
Utilisation d’un grand nombre de négatifs
L’élément clé qui a fait que l’apprentissage contrastif a bien fonctionné dans le passé est l’utilisation d’un grand nombre de négatifs. Le papier de Wu et al. (2018) a introduit le concept de banque de mémoire. C’est un outil puissant et la plupart des méthodes de pointes actuelles s’articulent autour de cette idée. La banque de mémoire est un bon moyen d’obtenir un grand nombre de négatifs sans vraiment augmenter les besoins informatiques. Ce qui est fait, est que nous stockons un vecteur de caractéristiques par image dans la mémoire, puis utilisons ce vecteur de caractéristiques dans votre apprentissage contrastif.
Comment cela focntionne
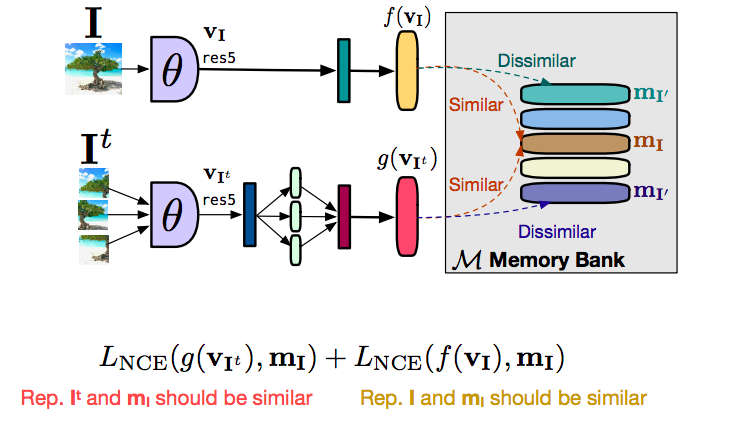
Figure 16 : Fonctionnement de la banque de mémoire
Parlons d’abord de la façon d’appliquer PIRL sans utiliser une banque de mémoire. Nous avons donc une image $I$ et une image $I^t$, et les donnons à un ConvNet. Nous obtenons un vecteur de caractéristique $f(v_I)$ de l’image originale $I$ et une caractéristique $g(v_{I^t})$ des versions transformés (les patches Jigsaw dans ce cas). Ce que nous voulons c’est que les caractéristiques $f$ et $g$ soient similaires, et que les caractéristiques de toute autre image sans rapport soient fondamentalement différentes.
Ce que nous voudrions maintenant c’est que beaucoup d’images négatives soient données en même temps, ce qui signifie qu’il nous faut une très grande taille de batch pour pouvoir faire cela.
Une grande taille de batch n’est pas vraiment bonne pour la mémoire. Le moyen d’y parvenir est d’utiliser ce qu’on appelle une banque de mémoire. Ainsi, cette banque de mémoire stocke un vecteur de caractéristiques pour chacune des images de notre jeu de données, et lorsque nous faisons l’apprentissage contrastif, plutôt que d’utiliser des vecteurs de caractéristiques, nous pouvons simplement récupérer ces caractéristiques en mémoire. En divisant l’objectif en deux parties, il y a un terme contrastif est utilisé pour amener le vecteur de caractéristiques de l’image transformée $g(v_I)$, similaire à la représentation que nous avons en mémoire, donc $m_I$. Et de même, nous avons un second terme contrastif qui tente de rapprocher la caractéristique $f(v_I)$ de la représentation de la caractéristique que nous avons en mémoire. Essentiellement, $g$ est rapproché de $m_I$ et $f$ est rapproché de $m_I$. Par transitivité, $f$ et $g$ sont rapprochés l’un de l’autre.
La raison de cette séparation est que cela stabilise l’entraînement et que nous ne n’arrivons pas à le réaliser sans cela car il ne convergeait pas vraiment.
Pré-entraînement de PIRL
Pour l’apprentissage par transfert, nous pouvons faire un pré-entraînement sur des images sans label. La méthode standard consiste à prendre un réseau d’images, à jeter les labels et à faire semblant de ne pas être supervisé.
Evaluation
L’évaluation peut être effectuée par un finetuning complet (évaluation de l’initialisation) ou par l’entraînement d’un classifieur linéaire (évaluation des caractéristiques). La robustesse de PIRL a été testée en l’entraînant sur des images en milieu naturel, à savoir un million d’images prises au hasard sur Flickr (jeu de données YFCC). Puis il a été appliqué sur différents jeux de données.
Evaluation sur la tâche de détection d’objets
PIRL a d’abord été évalué sur la tâche de détection d’objets. Il a surpassé les réseaux pré-entraînés de manière supervisée sur ImageNet sur les jeux de données VOC07+12 et VOC07. En fait, PIRL a même surpassé les critères d’évaluation les plus stricts, $AP^{all}$.
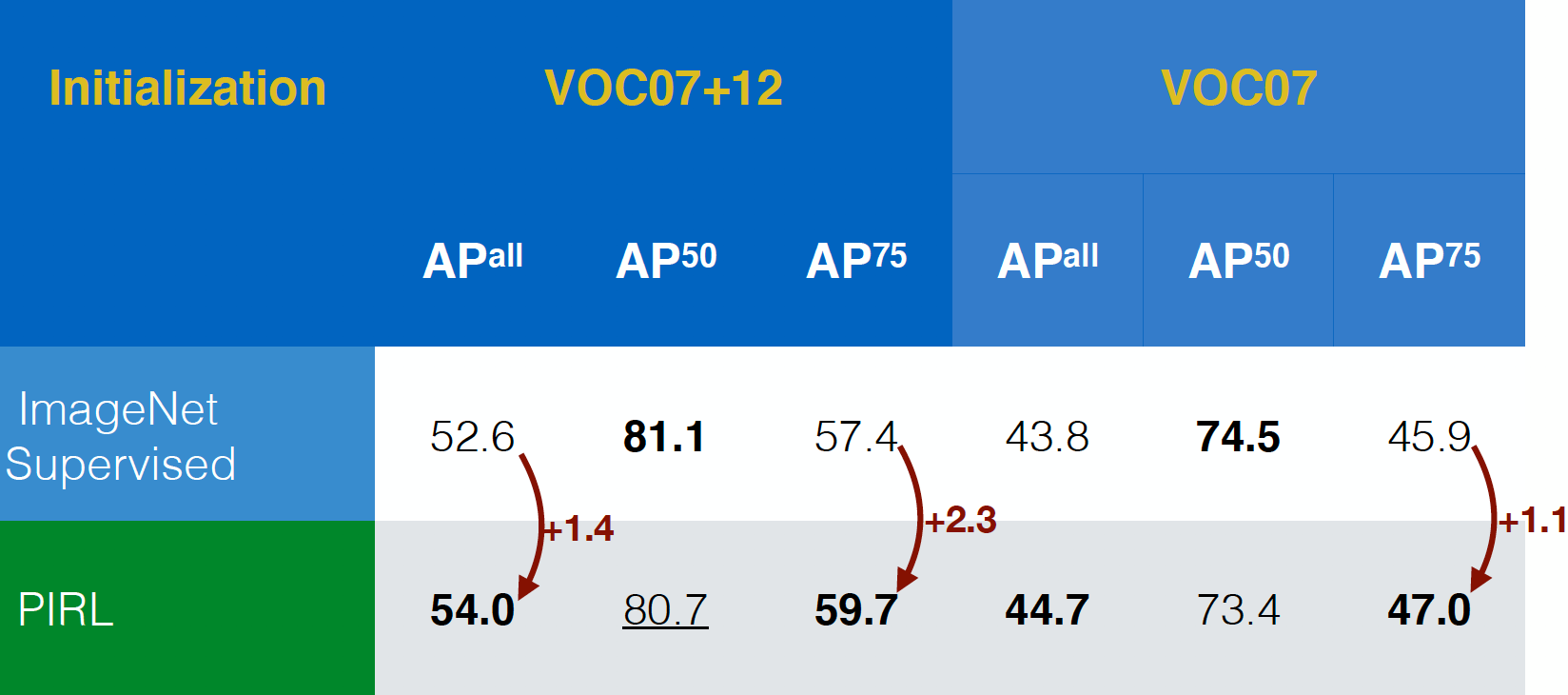
Figure 17 : Performances pour la tâche de détection d'objets sur deux jeux de données
Évaluation sur l’apprentissage semisupervisé
PIRL a ensuite été évalué sur une tâche d’apprentissage semisupervisée. Là encore, il a obtenu d’assez bons résultats. En fait, il a même été meilleur que la tâche de prétexte Jigsaw. La seule différence entre la première et la dernière rangée est que PIRL est une version invariante, alors que Jigsaw est une version covariante.
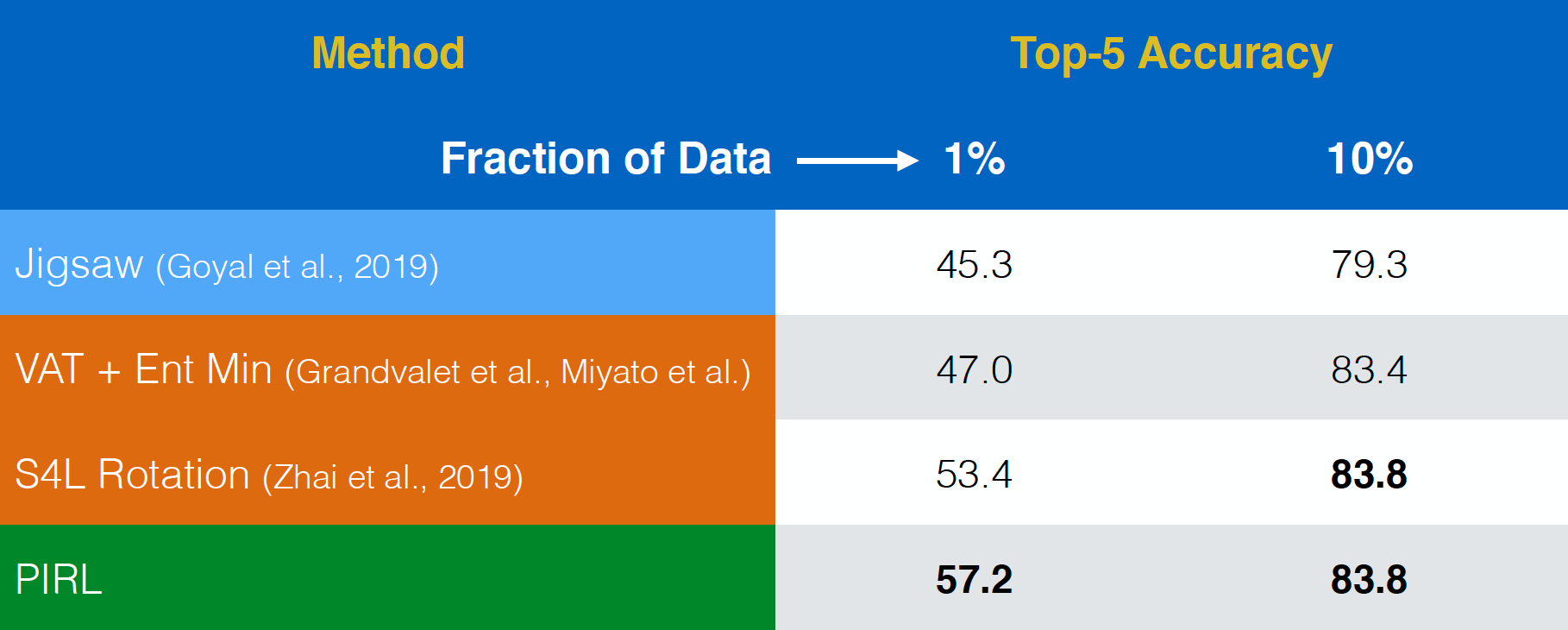
Figure 18 : Apprentissage semisupervisé sur ImageNet
Évaluation sur la classification linéaire
Sur l’évaluation sur de la classification, PIRL est au même niveau que CPCv2. Il a également bien fonctionné sur un certain nombre de paramètres et d’architectures différentes.
Depuis, la méthode SimCLR fait mieux avec une précision top-1 d’environ 69-70 contre environ 63 pour PIRL.
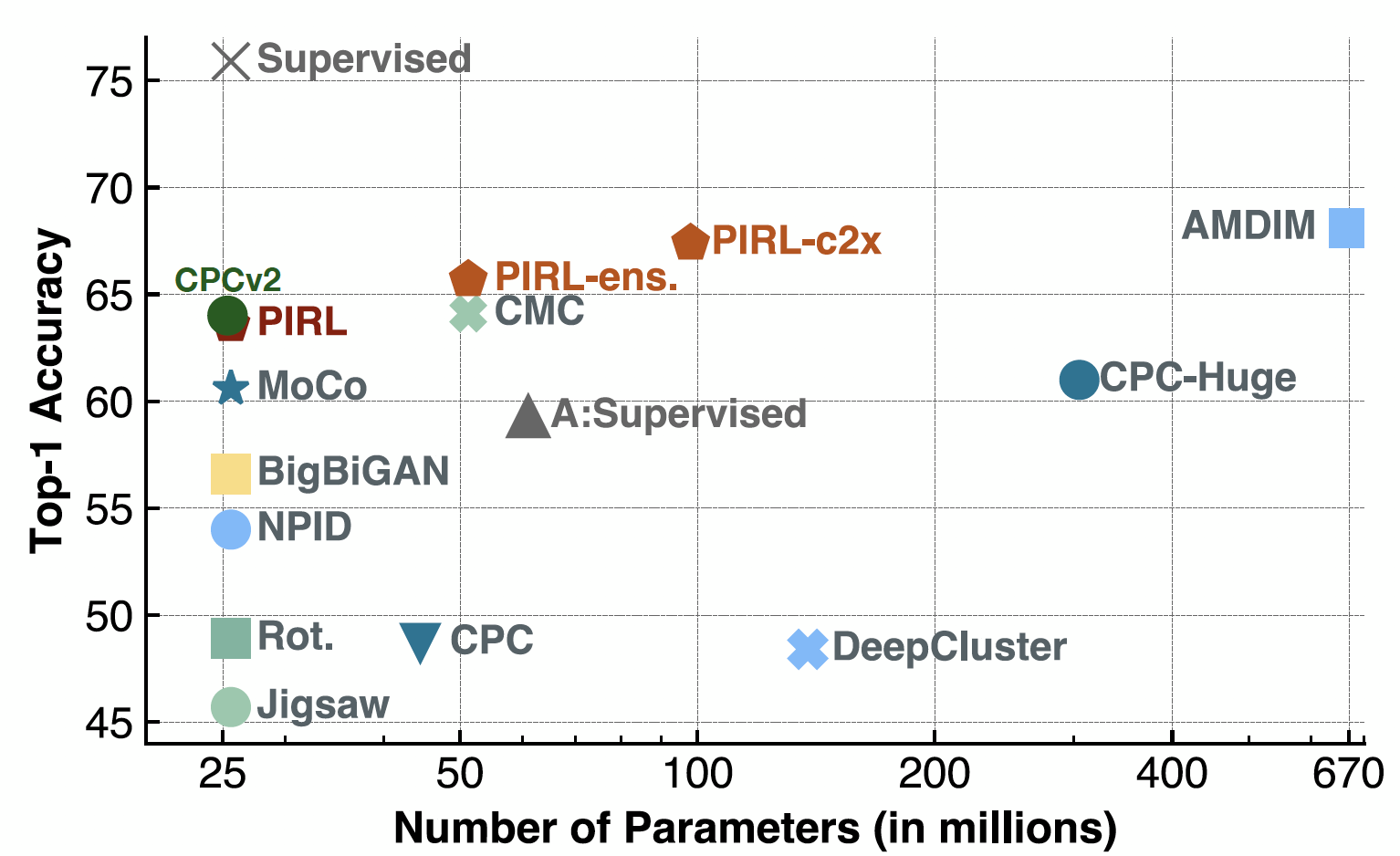
Figure 19 : Classification ImageNet avec modèles linéaires
Evaluation sur les images YFCC
PIRL a été évalué sur les images du jeu de données YFCC. Il a été plus performant que Jigsaw, même avec un jeu de données $100$ fois plus petit. Cela montre la puissance de la prise en compte de l’invariance pour la représentation dans les tâches de prétexte, plutôt que de simplement prédire les tâches de prétexte.
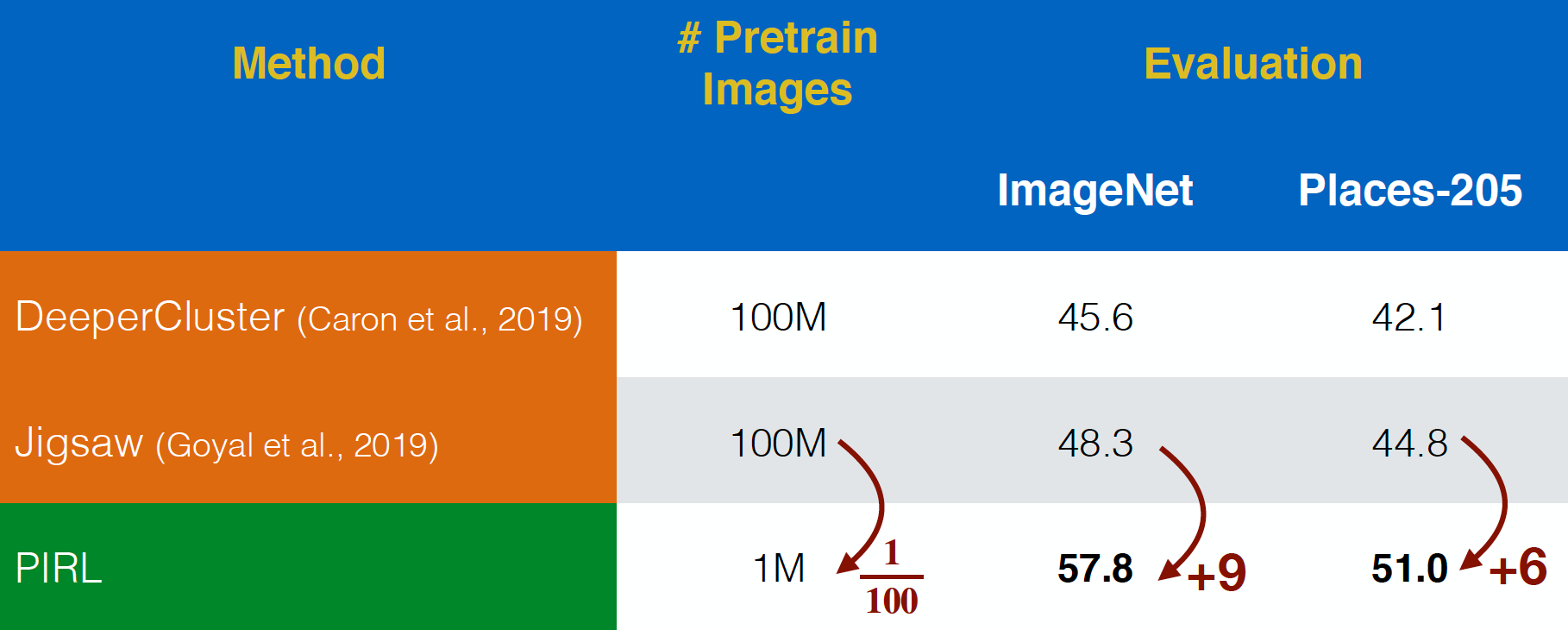
Figure 20 : Pré-entraînement sur les images non traitées de YFCC
Caractéristiques sémantiques
Maintenant, pour en revenir à la vérification des caractéristiques sémantiques, nous examinons la précision Top-1 pour PIRL et Jigsaw pour différentes couches de représentation, de conv1 à res5. Il est intéressant de noter que la précision augmente pour les différentes couches pour PIRL et Jigsaw, mais qu’elle diminue dans la 5e couche pour Jigsaw. En revanche, la précision continue à s’améliorer pour PIRL, c’est-à-dire de plus en plus sémantique.
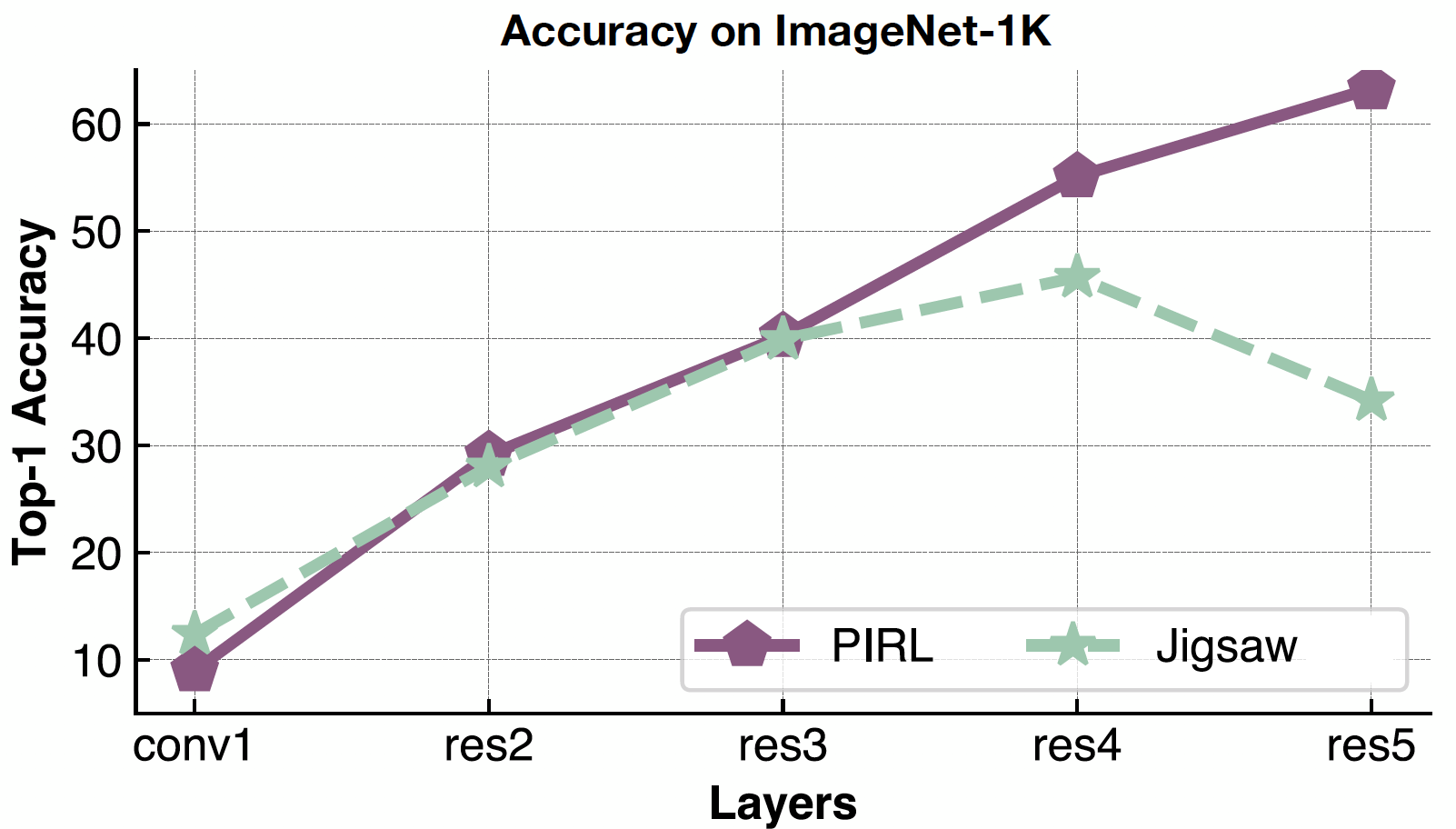
Figure 21 : Qualité des représentations de PIRL par couche
Passage à l’échelle
PIRL est très efficace pour gérer la complexité des problèmes car on ne prédit jamais le nombre de permutations, on les utilise simplement comme données d’entrée. Ainsi, PIRL peut facilement s’adapter aux $362 880$ permutations possibles dans les 9 patchs. Alors que dans Jigsaw, nous sommes limités par la taille de l’espace de sortie.
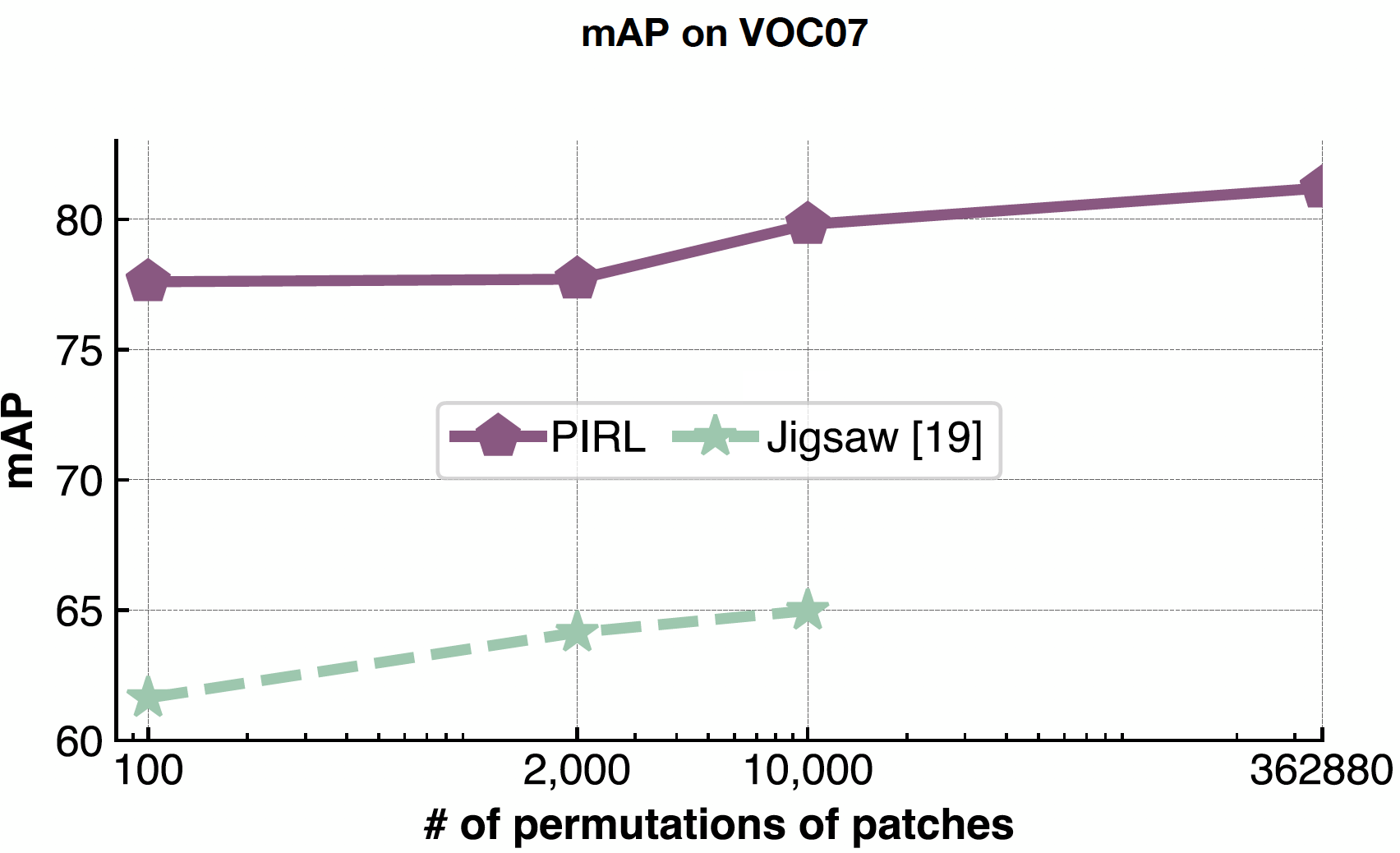
Figure 22 : Effet de la variation du nombre de permutations de patchs
Le papier de PIRL montre également comment il peut être facilement étendu à d’autres tâches de prétexte comme Jigsaw, les rotations, etc. En outre, il peut même être étendu à des combinaisons de ces tâches comme Jigsaw+Rotation.
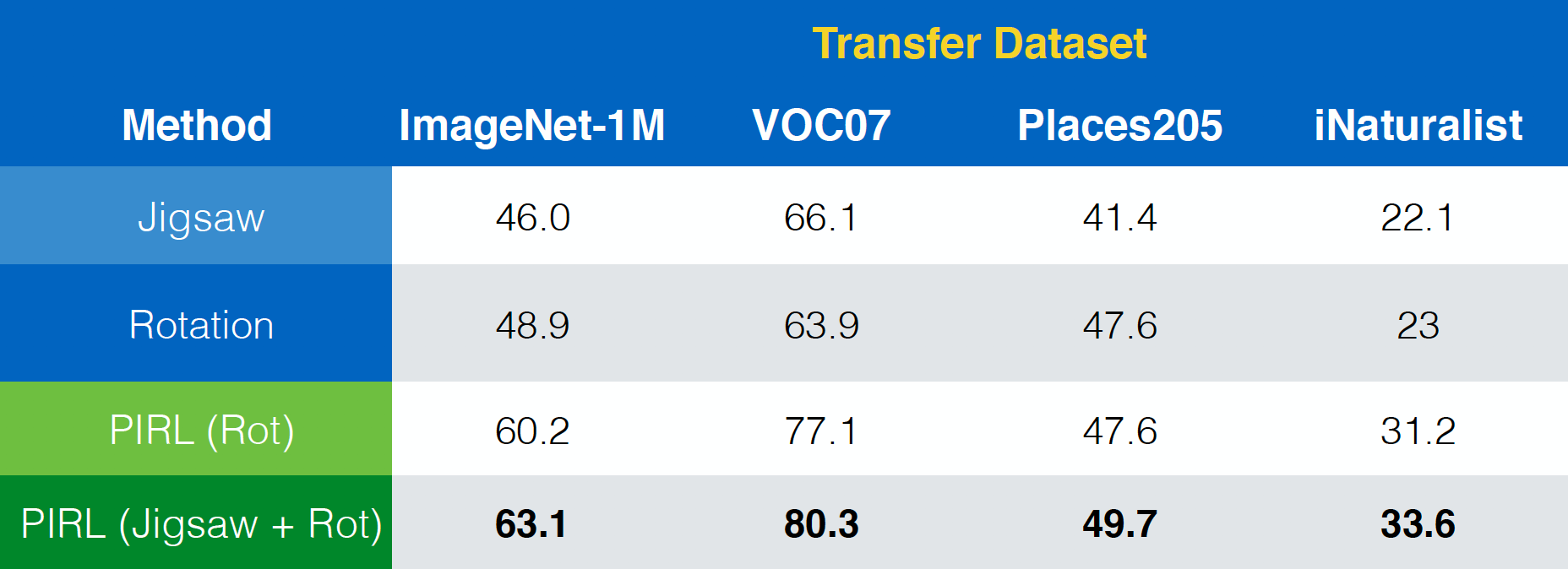
Figure 23 : Utilisation de PIRL avec (combinaisons de) différentes tâches de prétexte
Invariance vs performance
En termes de propriété d’invariance, on pourrait, en général, affirmer que l’invariance de PIRL est plus que celle du Clustering, qui à son tour a plus d’invariance que celle des tâches de prétexte. De même, la performance est plus élevée pour PIRL que pour le Clustering, qui à son tour a une performance plus élevée que les tâches de prétexte. Cela suggère que le fait d’ajouter de l’invariance dans une méthode pourrait améliorer les performances.
Lacunes
- Il n’est pas très clair de savoir quel ensemble de données transforme la matière. Bien que Jigsaw fonctionne, on ne sait pas très bien pourquoi.
- Saturation avec la taille du modèle et la taille des données.
- Quelles sont les invariances importantes ? On pourrait penser à celles qui fonctionnent pour une tâche supervisée particulière en général comme un travail futur.
Donc, en général, nous devrions essayer de prévoir de plus en plus d’informations et essayer d’être aussi invariants que possible.
Questions des étudiants sur plusieurs sujets
L’apprentissage contrastif et la batch normalisation
Le réseau n’apprendrait-il pas une façon très triviale de séparer les négatifs des positifs si le réseau utilise la couche de batch normalisation (car l’information passerait alors d’un échantillon à l’autre) ?
Dans PIRL, aucun phénomène de ce type n’a été observé, donc seule la batch normalisation habituelle a été utilisée.
Est-il donc acceptable d’utiliser une normalisation par batch pour des réseaux contrastifs ?
En général, oui. Dans SimCLR, une variante de la normalisation par batch est utilisée pour émuler une grande taille de batch. Ainsi, la normalisation par batch avec peut-être quelques modifications pourrait être utilisée pour faciliter l’entraînement.
La normalisation par batch fonctionne-t-elle dans le papier PIRL uniquement parce qu’elle est mise en œuvre en tant que banque de mémoire ? Etant donné que toutes les représentations ne sont pas prises en même temps
Oui. Dans PIRL, le même batch n’a pas toutes les représentations et est peut-être la raison de pourquoi la normalisation par batch fonctionne ici. Cela pourrait ne pas être le cas pour d’autres tâches où les représentations sont toutes corrélées dans le batch.
Outre la banque de mémoire, existe-t-il d’autres suggestions sur la manière de procéder en cas de perte n-paires ? Devrions-nous utiliser AlexNet qui n’utilise pas la noramlisation par batch ou existe-t-il un moyen de désactiver la couche de normalisation par batch ? Notamment dans le cadre d’une tâche d’apprentissage vidéo
Généralement, les images sont corrélées dans les vidéos et la performance de la normalisation par batch se dégrade lorsqu’il y a des corrélations. De plus, même la plus simple des implémentations d’AlexNet utilise en fait la normalisation par batch. En effet, il est beaucoup plus stable lorsqu’il est entraîné avec. Vous pourriez même utiliser un taux d’apprentissage plus élevé et vous pourriez également l’utiliser pour d’autres tâches en aval. Vous pouvez utiliser une variante de la normalisation par batch, par exemple la normalisation par groupe pour les tâches d’apprentissage vidéo, car elle ne dépend pas de la taille du batch.
Fonctions de perte dans PIRL
Dans PIRL, pourquoi utilise-t-on le NCE (Noise Contrastive Estimator) pour minimiser les pertes et pas seulement la probabilité négative de la distribution des données : $h(v_{I},v_{I^{t}})$ ?
En fait, les deux pourraient être utilisés. La raison de l’utilisation du NCE a plus à voir avec la façon dont le papier de la banque de données a été mis en place. Ainsi, avec $k+1$ négatifs, cela équivaut à résoudre $k+1$ problème binaire. Une autre façon de procéder est d’utiliser une fonction softmax et minimiser la log-vraisemblance négative.
Conseils relatifs aux projets d’apprentissage autosupervisés
Comment faire fonctionner un modèle simple et autosupervisé ? Comment en amorcer la mise en œuvre ?
Il existe une certaine classe de techniques qui sont utiles pour les étapes initiales. Par exemple, vous pouvez examiner les tâches de prétexte. La rotation est une tâche très facile à mettre en œuvre. Le nombre de pièces en mouvement est en général un bon indicateur. Si vous envisagez de mettre en œuvre une méthode existante, vous devrez peut-être examiner de plus près les détails mentionnés par les auteurs, comme le taux d’apprentissage exact utilisé, la manière dont les normes de lot ont été utilisées, etc. Plus ces éléments sont nombreux, plus la mise en œuvre est difficile. Le prochain point très important à prendre en compte est l’augmentation des données. Si quelque chose fonctionne, il faut y ajouter une augmentation des données.
Modèles génératifs
Avez-vous pensé à combiner des modèles génératifs avec des réseaux contrastifs ?
Généralement, c’est une bonne idée. Mais, elle n’a pas été mise en œuvre en partie parce qu’il est délicat et non trivial d’entraîner de tels modèles. Les approches intégratives sont plus difficiles à implémenter mais c’est peut-être la voie à suivre à l’avenir.
Distillation
L’incertitude du modèle n’augmenterait-elle pas lorsque des cibles plus riches sont données par des distributions plus douces ? Aussi, pourquoi l’appelle-t-on distillation ?
Si vous entraînez sur un seul label, vos modèles ont tendance à être trop confiants. Des astuces comme le lissage des labels sont utilisées dans certaines méthodes. Le lissage de label est une simple version de la distillation où vous essayez de prédire un vecteur one-hot. Maintenant, plutôt que d’essayer de prédire le vecteur one-hot entier, vous en retirez une certaine masse de probabilité, où au lieu de prédire un $1$ et un tas de $0$, vous prédisez par exemple $0,97$ et vous ajoutez ensuite $0,01$, $0,01$ et $0,01$ au vecteur restant (uniformément). La distillation est simplement une façon plus éclairée de procéder. Au lieu d’augmenter de manière aléatoire la probabilité d’une tâche sans rapport, vous disposez d’un réseau pré-entraîné pour le faire. En général, les distributions plus douces sont très utiles dans les méthodes d’entraînement préalable. Les modèles ont tendance à être trop confiants et les distributions plus douces sont plus faciles à entraîner. Elles convergent aussi plus rapidement. Ces avantages sont présents dans la distillation.
📝 Zhonghui Hu, Yuqing Wang, Alfred Ajay Aureate Rajakumar, Param Shah
Loïck Bourdois
6 Apr 2020