Внимание и Трансформер
🎙️ Alfredo CanzianiВнимание
Введём концепцию внимания перед тем, как говорить об архитектуре Трансформеров. Есть два основных типа внимания: self attention против. перекрёстного внимания, среди этих категорий мы можем выделить жёсткое против. мягкого внимания.
Как мы увидим позже, трансформеры составлены из модулей внимания, которые являются отображениями множеств, скорее чем последовательностей, что значит мы не навязываем порядок нашим входам/выходам.
Self Attention (I)
Рассмотрим множество $t$ входов $\boldsymbol{x}$’s:
\[\lbrace\boldsymbol{x}_i\rbrace_{i=1}^t = \lbrace\boldsymbol{x}_1,\cdots,\boldsymbol{x}_t\rbrace\]гд каждый $\boldsymbol{x}_i$ есть $n$-мерный вектор. Поскольку в множестве есть $t$ элементов, каждый из которых принадлежит $\mathbb{R}^n$, мы можем представить множество как матрицу $\boldsymbol{X}\in\mathbb{R}^{n \times t}$.
При self-attention внутреннее представление $h$ является линейной комбинацией входов:
\[\boldsymbol{h} = \alpha_1 \boldsymbol{x}_1 + \alpha_2 \boldsymbol{x}_2 + \cdots + \alpha_t \boldsymbol{x}_t\]Используя матрицу представлений, описанную выше, мы можем записать внутренний слой, как произведение матриц:
\[\boldsymbol{h} = \boldsymbol{X} \boldsymbol{a}\]где $\boldsymbol{a} \in \mathbb{R}^t$ вектор-столбец с компонентами $\alpha_i$.
Отметим, что это отличается от внутреннего представления, которое мы видели до сих пор, где входы умножались на матрицу весов.
В зависимости от ограничений налагаемых на вектор $\vect{a}$, мы получаем жёсткое или мягкое внимание.
Жётское Внимание
При жёстком внимании, мы налагаем следующие ограничения на альфы: $\Vert\vect{a}\Vert_0 = 1$. Это значит $\vect{a}$ является унитарным вектором. Следовательно все, кроме одного, коэффициенты в линейной комбинации входов равняются нулю, и внутренние представления сокращаются до входа $\boldsymbol{x}_i$, соответствующего элементу $\alpha_i=1$.
Мягкое внимание
При мягком внимании, мы налагаем ограничение $\Vert\vect{a}\Vert_1 = 1$. Внутреннее представление является линейной комбинацией входов, где сумма коэффициентов равна единице.
Self Attention (II)
Откуда берутся $\alpha_i$?
Мы получаем вектор $\vect{a} \in \mathbb{R}^t$ следующим образом:
\[\vect{a} = \text{[soft](arg)max}_{\beta} (\boldsymbol{X}^{\top}\boldsymbol{x})\]Где $\beta$ представляет параметр обратной температуры $\text{soft(arg)max}(\cdot)$. $\boldsymbol{X}^{\top}\in\mathbb{R}^{t \times n}$ есть транспонированная матрица представлений множества $\lbrace\boldsymbol{x}_i \rbrace_{i=1}^t$, и $\boldsymbol{x}$ представляет собой набор $\boldsymbol{x}_i$ из множества. Заметим, что $j$-я строка $X^{\top}$ соответствует элементу $\boldsymbol{x}_j\in\mathbb{R}^n$, так что $j$-я строка $\boldsymbol{X}^{\top}\boldsymbol{x}$ является скалярным произведением $\boldsymbol{x}_j$ с каждым $\boldsymbol{x}_i$ из $\lbrace \boldsymbol{x}_i \rbrace_{i=1}^t$.
Компоненты вектора $\vect{a}$ также называются “оценки”, потому что скалярное произведение двух векторов говорит нам, как направлены или схожи два вектора. Следовательно элементы $\vect{a}$ предоставляют информацию о схожести всего множества с частным $\boldsymbol{x}_i$.
Квадратные скобки представляют represent необязательный аргумент. Заметим, что если используется $\arg\max(\cdot)$, мы получаем унитарный вектор альф, результирующий в жёсткое внимание. С другой стороны, $\text{soft(arg)max}(\cdot)$ приводит к мягкому вниманию. В каждом случае компоненты результирующего вектора $\vect{a}$ в сумме дают 1.
Генерируя $\vect{a}$ таким образом даёт их множество, по одному для каждого $\boldsymbol{x}_i$. Более того, каждый $\vect{a}_i \in \mathbb{R}^t$, так что мы можем образовать из альф матрицу $\boldsymbol{A}\in \mathbb{R}^{t \times t}$.
Поскольку каждое внутреннее состояние является линейной комбинацией входов $\boldsymbol{X}$ и вектора $\vect{a}$, мы получаем множество $t$ внутренних состояний, которые можем объединить в матрицу $\boldsymbol{H}\in \mathbb{R}^{n \times t}$.
\[\boldsymbol{H}=\boldsymbol{XA}\]Хранилище ключ-значение
Хранилище ключ-значение - парадигма разработанная для хранения (сохранения), извлечения (запроса) и управления ассоциативными массивами (словарями / хеш-таблицами).
Например, скажем нам нужно найти рецепт лазаньи. У нас есть книга рецептов и поисковое слово “лазанья” - это запрос. Этот запрос проверяется для каждого возможного из ключей вашей выборки данных - в этом случае это могут быть названия всех рецептов в книге. Мы проверяем как направлен запрос по отношению к каждому названию, чтобы найти максимальную оценку совпадения между запросом и всем соответствующими ключами. Если нашим выходом является функция argmax - мы получаем один рецепт с наивысшей оценкой. В другом случае, если мы используем функцию soft argmax, мы получим вероятностное распределение и можем получить рецепты в порядке от наиболее схожего содержимого до менее и менее релевантного, соответствующего запросу.
По сути, запрос есть вопрос. По заданному запросу, мы проверяем этот запрос по каждому ключу и получаем всё соответствующее содержимое.
Запросы, ключи и значения
\[\begin{aligned} \vect{q} &= \vect{W_q x} \\ \vect{k} &= \vect{W_k x} \\ \vect{v} &= \vect{W_v x} \end{aligned}\]Каждый из векторов $\vect{q}, \vect{k}, \vect{v}$ может быть представлен как поворот определённого входа $\vect{x}$. Где $\vect{q}$ есть просто $\vect{x}$ повёрнутый $\vect{W_q}$, $\vect{k}$ просто $\vect{x}$ повёрнутый посредством $\vect{W_k}$ и аналогично для $\vect{v}$. Заметим, что мы впервые вводим “обучаемые” параметры. Мы также не включаем каких-либо нелинейностей, поскольку внимание полностью опирается на направление.
Чтобы сравнить запрос с каждым из возможных ключей, $\vect{q}$ и $\vect{k}$ должны быть одинаковой размерности, т.е. $\vect{q}, \vect{k} \in \mathbb{R}^{d’}$.
Однако, $\vect{v}$ может быть любой размерности. Если мы продолжим нажпример с рецептом лазаньи - нам нужно, чтобы запрос имел такую же размерность, как у ключей, т.е. названий различных рецептов по которым мы будем искать. Размерность соответствующего полученного рецепта, $\vect{v}$, однако может быть сколь угодно большой. Таким образом мы имеем, что $\vect{v} \in \mathbb{R}^{d’’}$.
Для простоты здесь мы сделаем предположение, что у всего размерность $d$, т.е.
\[d' = d'' = d\]Так что сейчас у нас есть множество $\vect{x}$-ов, множество запросов, множество ключей и множество значений. Мы можем объединить эти множества в матрицы, каждая с $t$ столбцами, поскольку мы объединяем $t$ векторов; каждый вектор длины $d$.
\[\{ \vect{x}_i \}_{i=1}^t \rightsquigarrow \{ \vect{q}_i \}_{i=1}^t, \, \{ \vect{k}_i \}_{i=1}^t, \, \, \{ \vect{v}_i \}_{i=1}^t \rightsquigarrow \vect{Q}, \vect{K}, \vect{V} \in \mathbb{R}^{d \times t}\]Мы сравниваем один запрос $\vect{q}$ с матрицей всех ключей $\vect{K}$:
\[\vect{a} = \text{[soft](arg)max}_{\beta} (\vect{K}^{\top} \vect{q}) \in \mathbb{R}^t\]Затем внутренний слой будет линейной комбинацией столбцов $\vect{V}$, взвешенной коэффициентами из $\vect{a}$:
\[\vect{h} = \vect{V} \vect{a} \in \mathbb{R}^d\]Поскольку у нас $t$ запросов, мы получим $t$ соответствующих $\vect{a}$ весов и следовательно матрицу $\vect{A}$ размерности $t \times t$.
\[\{ \vect{q}_i \}_{i=1}^t \rightsquigarrow \{ \vect{a}_i \}_{i=1}^t, \rightsquigarrow \vect{A} \in \mathbb{R}^{t \times t}\]Следовательно в матричной записи мы имеем:
\[\vect{H} = \vect{VA} \in \mathbb{R}^{d \times t}\]Отдельно мы обычно устанавливаем $\beta$ значение:
\[\beta = \frac{1}{\sqrt{d}}\]Это делается для того, чтобы поддерживать постоянную температуру на протяжении различных выборов размерности $d$, и поэтому мы делим на квадратный корень числа измерений $d$. (Подумайте какая длина вектора $\vect{1} \in \R^d$.)
Во время реализации мы можем ускорить вычисления объединяя все $\vect{W}$-ки в одну $\vect{W}$ и затем вычислить $\vect{q}, \vect{k}, \vect{v}$ за один проход:
\[\begin{bmatrix} \vect{q} \\ \vect{k} \\ \vect{v} \end{bmatrix} = \begin{bmatrix} \vect{W_q} \\ \vect{W_k} \\ \vect{W_v} \end{bmatrix} \vect{x} \in \mathbb{R}^{3d}\]Существует также концепция “голов”. Выше мы видели пример с одной головой, но у нас может быть много голов. Например, скажем у нас $h$ голов, значит у нас $h$ $\vect{q}$-ек, $h$ $\vect{k}$-ек и $h$ $\vect{v}$-ек и мы получаем вектор из $\mathbb{R}^{3hd}$:
\[\begin{bmatrix} \vect{q}^1 \\ \vect{q}^2 \\ \vdots \\ \vect{q}^h \\ \vect{k}^1 \\ \vect{k}^2 \\ \vdots \\ \vect{k}^h \\ \vect{v}^1 \\ \vect{v}^2 \\ \vdots \\ \vect{v}^h \end{bmatrix} = \begin{bmatrix} \vect{W_q}^1 \\ \vect{W_q}^2 \\ \vdots \\ \vect{W_q}^h \\ \vect{W_k}^1 \\ \vect{W_k}^2 \\ \vdots \\ \vect{W_k}^h \\ \vect{W_v}^1 \\ \vect{W_v}^2 \\ \vdots \\ \vect{W_v}^h \end{bmatrix} \vect{x} \in \R^{3hd}\]Однако, всё ещё можем преобразовать многоголовые значения, чтобы иметь изначальную размерность $\R^d$, используя $\vect{W_h} \in \mathbb{R}^{d \times hd}$. Это просто один из возможных способов реализации хранилища ключ-значение.
Трансформер
Расширяя наши знания о внимании в частности, мы теперь интерпретируем фундаментальные строительные блоки трансформера. В частности, мы возьмём прямой проход через базовый трансформер, и посмотрим, как внимание используется в стандартной парадигме кодировщик-декодировщик и сравним последовательные архитектуры с RNNs.
Архитектура Кодировщик-Декодировщик
Мы уже знакомы с этой терминологией. Наиболее заметно это было показано на примере автокодировщика, и необходимо понимание этого момента. Резюмируя, вход подаётся в кодировщик и декодировщик налагает некоторого рода ограничения на данные, стимулируя использовать только самую важную информацию. Эта информация сохранена в выходе кодирующего блока, и может быть использована в множестве не связанных задач.
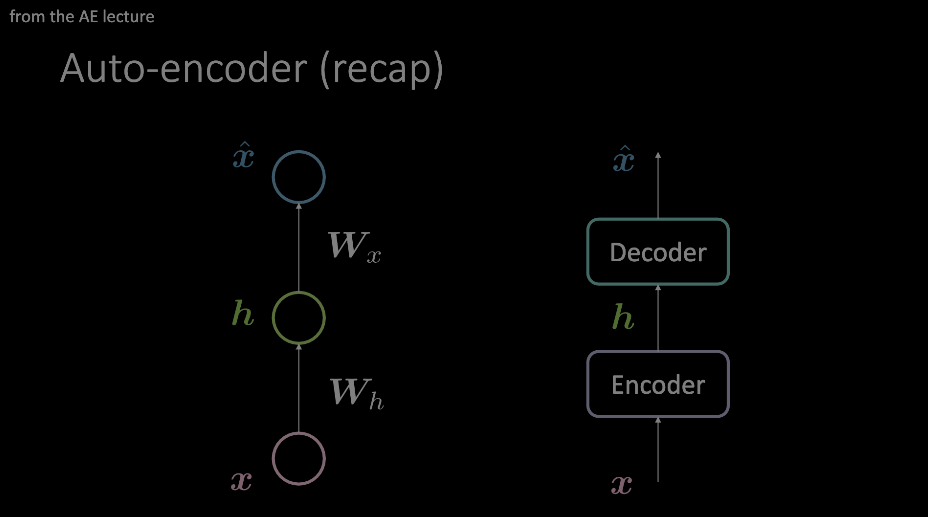
Рисунок 1: Два примера диаграм автокодировщика. Модель слева показывает, как автокодировщик может быть спроектирован с двумя аффинными преобразованиями + активациями, где изображение справа заменяет единственный "слой" на произвольный модуль операций.
Наше “внимание” изображено на схеме автокодировщика, как показано в модели справа, и сейчас заглянем внутрь в контексте трансформеров.
Модуль Кодировщик
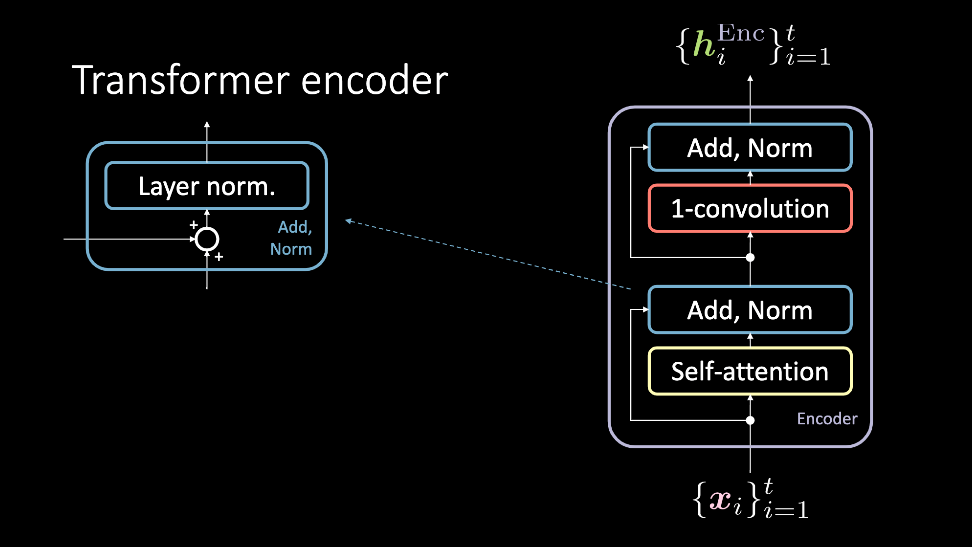
Рисунок 2: Кодировщик трансформера, которые принимает множество входов $\vect{x}$, и выводит множество внутренних представлений $\vect{h}^\text{Enc}$.
Кодирующий модуль принимает множество входов, которые сразу подаются на блок self attention и проходят через него, достигая блока Add, Norm. В этот момент, они снова проходят через 1D-Свёртку и другой Add, Norm блок, и в результате выводятся как мнрожество внутренних представлений. Это множество внутренних представлений затем либо проходит через произвольное число кодирующих модулей (т.е. больше слоёв), либо через декодировщик. Теперь обсудим эти блоки более подробно.
Self-attention
Модель self-attention есть обычная модель внимания. Запросы, ключи и значения сгенерированы из того же самого последовательного входа. В задачах, которые пытаются моделировать последовательные данные, позиционные кодировщики добавляются перед этим входом. Вход этого блока есть взвешенные вниманием значения. Блок self-attention принимает множество входов, из $1, \cdots , t$, и выводит $1, \cdots, t$ взевешнных вниманием значений, которые проходят через остальную часть кодировщика.
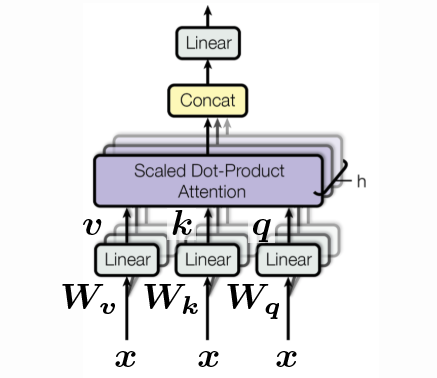
Рисунок 3: Блок self-attention. Последовательность входов изображена как множество в третьем измерении и сконкатенирована.
Сумма, Норма
Блок суммы нормы содержит два компонента. Первый - это блок суммы, который есть остаточное соеденение, и нормализация по слою.
1D-свёртка
Продолжая этот шаг, применяется 1D-свёртка (позиционная прямая сеть). Этот блок состоит из двух полносвязных слоёв. В зависимости от заданных значений, этот блок позволяет вам настраивать размеры выхода $\vect{h}^\text{Enc}$.
Модуль декодировщик
Декодировщик трансформера следует процедуре, похожей на кодировщик. Однако, тут есть дополнительный блок, который принимается во внимание. Дополнительно, входы этого модуля различны.

Рисунок 4: Более дружелюбное объяснение декодировщика.
Перекрёстное-внимание
Перекрёстное внимание следует настройке запросов, ключей и значений, используемой в блоках self-attention. Однако, входы немного более сложные. Вход в декодировщик - это точка данных $\vect{y}_i$, которая затем проходит через self attention и блоки суммы нормы, и наконец завершается блоком перекрёстного внимания. Это служит запоросом перекрёстного внимания, где пары ключей и значений есть выходы $\vect{h}^\text{Enc}$, где этот выход рассчитывается со всеми прошлыми входами $\vect{x}_1, \cdots, \vect{x}_{t}$.
Резюме
Множество от $\vect{x}_1$ до $\vect{x}_{t}$ проходит через кодировщик. Используя self-attention и несколько других блоков, получаем представление выхода $\lbrace\vect{h}^\text{Enc}\rbrace_{i=1}^t$, которое подаётся на декодировщик. После применения к нему self-attention, применяется перекрёстное внимание. В этом блоке запрос соответствует представлению символа в целевом языке $\vect{y}_i$, а ключ и значения из предложения на исходном языке (от $\vect{x}_1$ до $\vect{x}_{t}$). Интуитивно, перекрёстное внимание находит, какие значения во входной последовательности наиболее релевантны к построению $\vect{y}_t$, и затем заслуживают наивысшие коэффициенты внимания. Выход этого перекрёстного внимания затем проходит через ещё один блок 1D-свёртки, имеем $\vect{h}^\text{Dec}$. Для указанного целевого языка, отсюда легко увидеть, как начать обучение, сравнивая $\lbrace\vect{h}^\text{Dec}\rbrace_{i=1}^t$ с некоторыми целевыми данными.
Мировые модели языка
Есть несколько важных фактов, которые мы опустили выше, чтобы объяснить наиболее важных модулей трансформера, но нам нужно обсудить их сейчас, чтобы понимать, как трансформеры могут достичь state-of-the-art результатов в задачах языка.
Позиционное кодирование
Механизмы внимания позволяют нам параллелизовать операции и сильно ускорить время обучения модели, но теряется последовательность информации. Функция позционного кодирования позволяет нам захватить этот контекст.
Сематические представления
На протяжении обучения трансформера, генерируется множество внутренних представлений. Чтобы создать пространство характеристик, подобное тому, которое использовалось в примере модели мирового языка на PyTorch, выход перекрёстного внимания предоставит семантическое представление слова $x_i$, после чего можно проводить дальнейшие эксперименты на этой выборке данных.
Резюме кода
Сейчас мы увидим блоки трансформера, обсуждённые выше в намного более понятном формате, давайте кодить!
Первый модуль, который мы рассмотрим - блок много-голового внимания. В зависимости от запроса, ключа и значений поданных на вход этого блока, он может быть использован, либо для self-attention, либо для перекрёстного внимания.
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, p, d_input=None):
super().__init__()
self.num_heads = num_heads
self.d_model = d_model
if d_input is None:
d_xq = d_xk = d_xv = d_model
else:
d_xq, d_xk, d_xv = d_input
# Embedding dimension of model is a multiple of number of heads
assert d_model % self.num_heads == 0
self.d_k = d_model // self.num_heads
# These are still of dimension d_model. To split into number of heads
self.W_q = nn.Linear(d_xq, d_model, bias=False)
self.W_k = nn.Linear(d_xk, d_model, bias=False)
self.W_v = nn.Linear(d_xv, d_model, bias=False)
# Outputs of all sub-layers need to be of dimension d_model
self.W_h = nn.Linear(d_model, d_model)
Инициализация класса многоголового внимания. Если подан d_input, он становится перекрёстным вниманием. В ином случае - self-attention. Настройка запроса, ключа, значения строится как линейное преобразование входа d_model.
def scaled_dot_product_attention(self, Q, K, V):
batch_size = Q.size(0)
k_length = K.size(-2)
# Scaling by d_k so that the soft(arg)max doesnt saturate
Q = Q / np.sqrt(self.d_k) # (bs, n_heads, q_length, dim_per_head)
scores = torch.matmul(Q, K.transpose(2,3)) # (bs, n_heads, q_length, k_length)
A = nn_Softargmax(dim=-1)(scores) # (bs, n_heads, q_length, k_length)
# Get the weighted average of the values
H = torch.matmul(A, V) # (bs, n_heads, q_length, dim_per_head)
return H, A
Возвращает внутренний слой, соответствующий кодам значений после масштабирования вектором внимания. Для целей учёта (какие значения в последовательности были замаскированы вниманием?) A также возвращается.
def split_heads(self, x, batch_size):
return x.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
Разделим последнюю размерность на (heads × depth). Возвращает результат после транспонирования в форме (batch_size × num_heads × seq_length × d_k)
def group_heads(self, x, batch_size):
return x.transpose(1, 2).contiguous().
view(batch_size, -1, self.num_heads * self.d_k)
Комбинирует головы внимания вместе, чтобы получить правильную форму, совместимую с размером батча и длиной последовательности.
def forward(self, X_q, X_k, X_v):
batch_size, seq_length, dim = X_q.size()
# After transforming, split into num_heads
Q = self.split_heads(self.W_q(X_q), batch_size)
K = self.split_heads(self.W_k(X_k), batch_size)
V = self.split_heads(self.W_v(X_v), batch_size)
# Calculate the attention weights for each of the heads
H_cat, A = self.scaled_dot_product_attention(Q, K, V)
# Put all the heads back together by concat
H_cat = self.group_heads(H_cat, batch_size) # (bs, q_length, dim)
# Final linear layer
H = self.W_h(H_cat) # (bs, q_length, dim)
return H, A
Прямой проход многоголового внимания.
Заданные входы разделяет на q, k и v, после чего эти значения проходят через масштабированное скалярное произведение механизма внимания, конкатенируются и проходят через конечный линейный слой. Последний выход блока внимания есть полученное внимание, и внутреннее предстваление, которое проходит через остальные блоки.
Следующий блок, демонстрируемый в трансформере/кодировщике, является Суммой,Нормой, которые являются функциями, уже встроенными в PyTorch. Таким образом, это чрезвычайно простая реализация, и для неё не нужен отдельный класс. Затем идёт 1-D свёрточный блок. Пожалуйста обратитесь к предыдущим разделами для более подробной информации.
Теперь, когда все наши основные классы построены (или встроены для нас), мы перейдём к модулю кодировщику.
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, conv_hidden_dim, p=0.1):
self.mha = MultiHeadAttention(d_model, num_heads, p)
self.layernorm1 = nn.LayerNorm(normalized_shape=d_model, eps=1e-6)
self.layernorm2 = nn.LayerNorm(normalized_shape=d_model, eps=1e-6)
def forward(self, x):
attn_output, _ = self.mha(x, x, x)
out1 = self.layernorm1(x + attn_output)
cnn_output = self.cnn(out1)
out2 = self.layernorm2(out1 + cnn_output)
return out2
В самых мощных трансформерах произвольно большое количество этих кодировщиков соединены друг с другом.
Вспомните, что self attention само по себе не имеет каких-либо циклов или свёрток, но это то, что позволяет выполнять его так быстро. Чтобы сделать его чувствительным к положению, мы обеспечиваем позиционные кодировки. Они вычисляются следующим образом:
\[\begin{aligned} E(p, 2i) &= \sin(p / 10000^{2i / d}) \\ E(p, 2i+1) &= \cos(p / 10000^{2i / d}) \end{aligned}\]Чтобы не занимать слишком много места на мелких деталях, мы отсылаем вас к https://github.com/Atcold/pytorch-Deep-Learning/blob/master/15-transformer.ipynb для полного кода, использованного здесь.
Весь кодировщик, с N последовательными слоями кодировщиками, а также позиционные характеристики, написаны следующим образом:
class Encoder(nn.Module):
def __init__(self, num_layers, d_model, num_heads, ff_hidden_dim,
input_vocab_size, maximum_position_encoding, p=0.1):
self.embedding = Embeddings(d_model, input_vocab_size,
maximum_position_encoding, p)
self.enc_layers = nn.ModuleList()
for _ in range(num_layers):
self.enc_layers.append(EncoderLayer(d_model, num_heads,
ff_hidden_dim, p))
def forward(self, x):
x = self.embedding(x) # Transform to (batch_size, input_seq_length, d_model)
for i in range(self.num_layers):
x = self.enc_layers[i](x)
return x # (batch_size, input_seq_len, d_model)
Пример использования
Есть множество задач, где вы можете использовать только Кодировщик. В прилагаемой рабочей тетради, мы увидим, как кодировщик может быть использован для анализа настроений.
Используя выборку данных обзоров imdb, мы можем выводить из кодировщика скрытое представление последовательности текста, и обучить этот процесс кодирования с двоичной перекрёстной энтропией, соответствующей положительному или негативному обзору фильма.
Опять мы опускаем азы, и направляем вас к рабочей тетради, но здесь есть наиболее важные компоненты архитектуры, используемые в трансформере:
class TransformerClassifier(nn.Module):
def forward(self, x):
x = Encoder()(x)
x = nn.Linear(d_model, num_answers)(x)
return torch.max(x, dim=1)
model = TransformerClassifier(num_layers=1, d_model=32, num_heads=2,
conv_hidden_dim=128, input_vocab_size=50002, num_answers=2)
Где эта модель обучается типичным образом.
📝 Francesca Guiso, Annika Brundyn, Noah Kasmanoff, and Luke Martin
Evgeniy Pak
21 Apr 2020