Движущая сила задачи, линейная алгебра и визуализация
🎙️ Alfredo CanzianiРесурсы
Пожалуйста, подпишитесь на Твиттер @alfcnz Alfredo Canziani. Видео и книги с соответствующими подробностями по линейной алгебре и сингулярному разложению (SVD) можно найти при помощи поиска по твиттеру Alfredo, например, напечатайте linear algebra (from:alfcnz) в поле поиска.
Преобразования и мотивация
В качестве мотивирующего примера давайте рассмотрим классификацию изображений. Предположим, что мы делаем снимок на камеру с разрешением 1 мегапиксель. Это изображение будет размером около 1,000 пикселей по вертикали и 1,000 пикселей по горизонтали, и каждый пиксель будет также содержать три цветовых размерности для красного, зелёного и синего (RGB). Каждое изображение затем можно рассматривать как точку в 3 миллионо-мерном пространстве. При такой огромной размерности многие интересные изображения, которые мы могли бы захотеть классифицировать – такие как собака против кошки – будут в основном находиться в одной и той же области пространства.
Чтобы эффективно разделить эти изображения, мы рассматриваем способы преобразования данных для перемещения точек. Напомним, что в двумерном пространстве, линейные преобразования эквивалентны умножению на матрицу. Например, следующие линейные преобразования:
- Поворот (когда матрица ортонормальная).
- Масштабирование (когда матрица диагональная).
- Отражение (когда определитель матрицы отрицательный).
- Сдвиг.
Обратите внимание, что перемещение само по себе не является линейным, поскольку 0 не всегда будет отображаться в 0, но это афинное преобразование. Возвращаясь к нашему примеру с изображением, мы можем преобразовать точки данных, перемещая их таким образом, что точки будут кластеризованы вокруг 0 и, масштабируя диагональной матрицей таким образом, что мы “приблизим” эту область. Наконец, мы можем произвести классификацию, находя прямые в пространстве, которые разделяют различные точки по их соответствующим классам. Другими словами, идея состоит в применении линейных и нелинейных преобразований для отображения точек в пространстве таким образом, чтобы они стали линейно-разделимы. В следующих разделах будет больше конкретики относительно этой идеи.
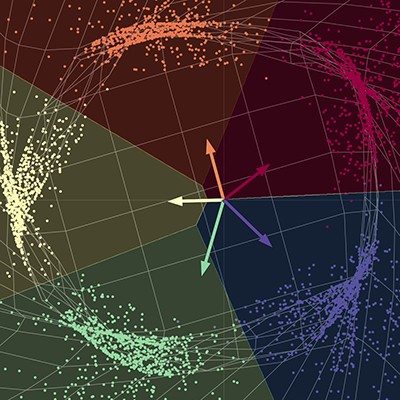
Визуализация данных - разделение точек по цветам при помощи сети
В нашей визуализации у нас есть пять ветвей спирали, каждая из которых соответствует своему цвету. Точки находятся на двумерной плоскости и могут быть представлены в виде кортежа: цвет представляет третье измерение, которое можно интерпретировать, как различные классы для каждой из точек. Затем мы используем сеть для разделения каждой точки по цветам.
 |
 |
| (a) Точки на входе сети | (b) Точки на выходе сети |
Сеть "растягивает" такнь пространства, чтобы разделить все точки на разные подпространства. При сходимости сеть разделяет каждый из цветов в различные подпространства конечного многообразия. Другими словами, каждый из цветов в этом новом пространстве будет линейно отделим, применяя регрессию один против всех. Вектора на графике могут быть представлены матрицей размера пять на два, эта матрица может быть умножена на каждую точку, чтобы получить оценки для каждого из пяти цветов. Каждая из точек затем может быть классифицирована по цвету при помощи их соответствующих оценок. Здесь размерность выхода равна пяти, по одной на каждый цвет, а размерность входа рвна двум, по одной для x и y координат каждой точки. Напомним, эта сеть в основном берёт ткань пространства и производит преобразование пространства, параметризованное сначала несколькими матрицами, а затем - нелинейностями.
Архитектура сети
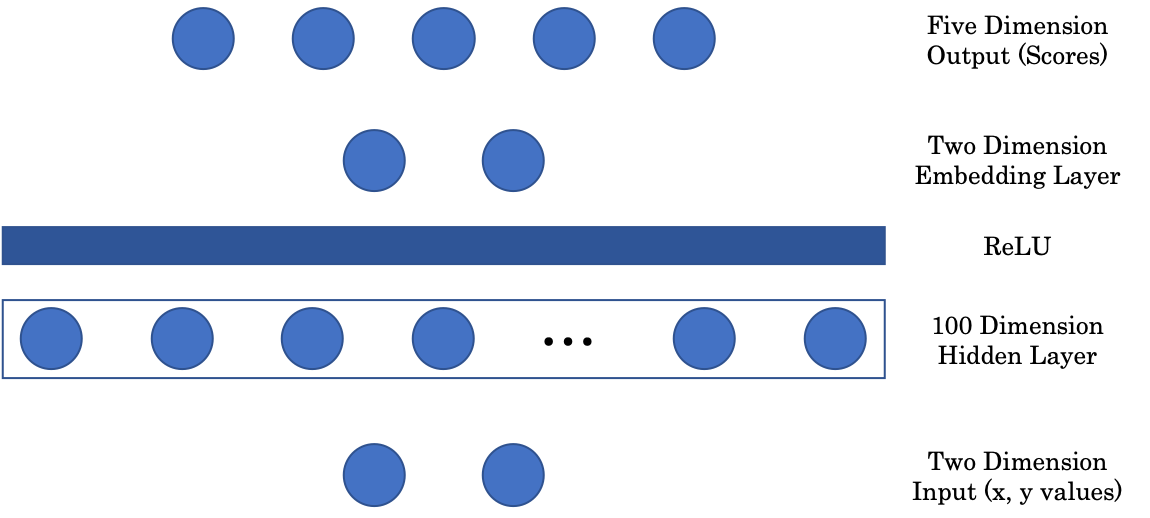
Рисунок 2: Архитектура сети
Первая матрица отображает двумерный вход в 100 мерный промежуточный скрытый слой. Затем у нас идёт нелинейный слой, ReLU или Rectified Linear Unit, который является просто положительной частью $(\cdot)^+$ функции. После, чтобы отобразить наше изображение графически, мы добавили встраиваемый слой, который отображает 100 мерный скрытый слой-вход в двумерный выход. Наконец, встраиваемый слой проецируется на последний, пятимерный слой сети, представляющий оценку для каждого цвета.
Произвольные проекции - Jupyter Notebook
Jupyter Notebook можно найти здесь. Чтобы запустить notebook, убедитесь, что Вы установили pDL среду, как указано в README.md.
PyTorch device
PyTorch может запускаться, как на CPU, так и на GPU компьютера. CPU полезен для последовательных задач, в то время как GPU полезна для параллельных задач. Перед выполнением на желаемом устройстве, мы сперва должны убедиться, что наши тензоры и модели переданы в память устройства. Это можно сделать при помощи следующих двух строк кода:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
X = torch.randn(n_points, 2).to(device)
Первая строка создаёт переменную с именем device, которой присваивается значение GPU, если есть хотя бы одна в доступе, в противном случае используется значение по умолчанию - CPU. Посредством следующей строки кода создаётся тензор и отправляется в память устройства вызовом .to(device).
Советы по Jupyter Notebook
Чтобы посмотреть документацию для функции в ячейке notebook, используйте Shift + Tab.
Визуализация линейных преобразований
Напомним, что линейное преобразование может быть представлено матрицей. Используя сингулярное разложение, мы можем разложить эту матрицу на три составляющие матрицы, каждая из которых представляет различные линейные преобразования.
\[W = U\begin{bmatrix}s_1 & 0 \\ 0 & s_2 \end{bmatrix} V^\top\]В уравнении (1) матрицы $U$ и $V^\top$ ортогональны и представляют преобразования поворота и отражения. Матрица посередине диагональная и представляет преобразование масштабирования.
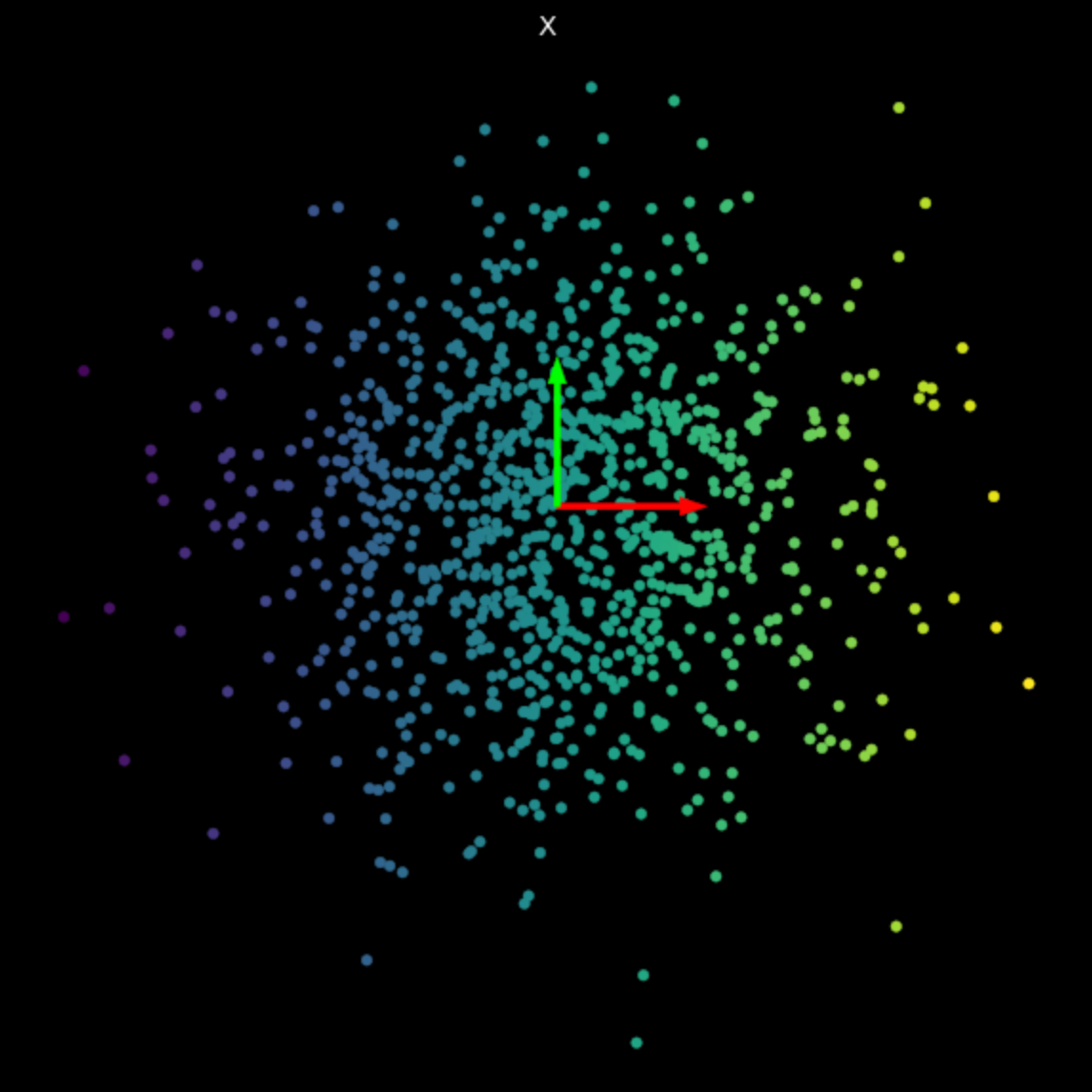
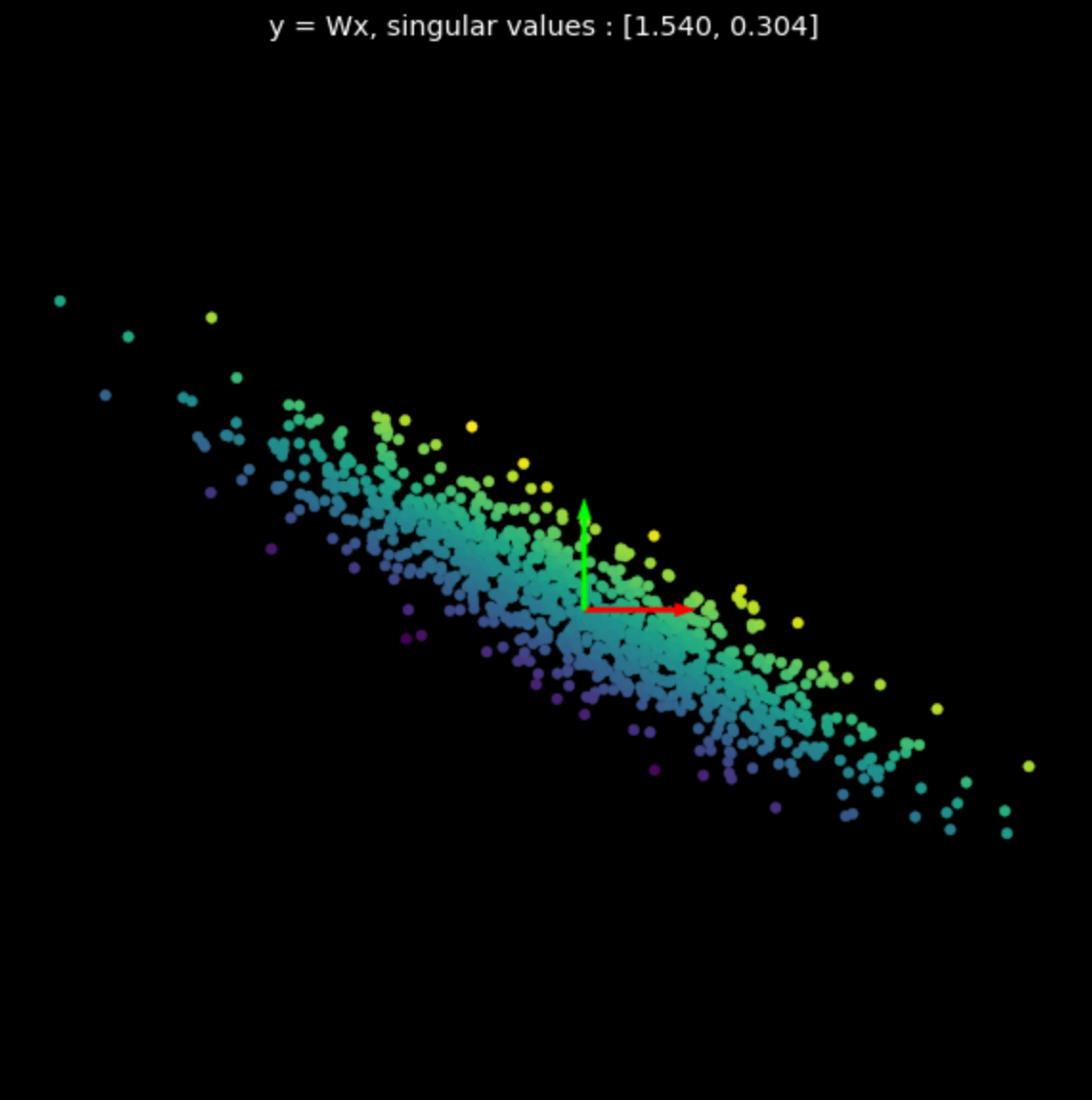
Мы визуализировали линейные преобразования нескольких произвольных матриц на Рис. 3. Обратите внимание на влияние сингулярных значений на результирующие преобразования.
Используемые матрицы были сгенерированны посредством Numpy, однако мы можем также использовать PyTorch nn.Linear класс со значением bias = False для создания линейных преобразований.
 |
 |
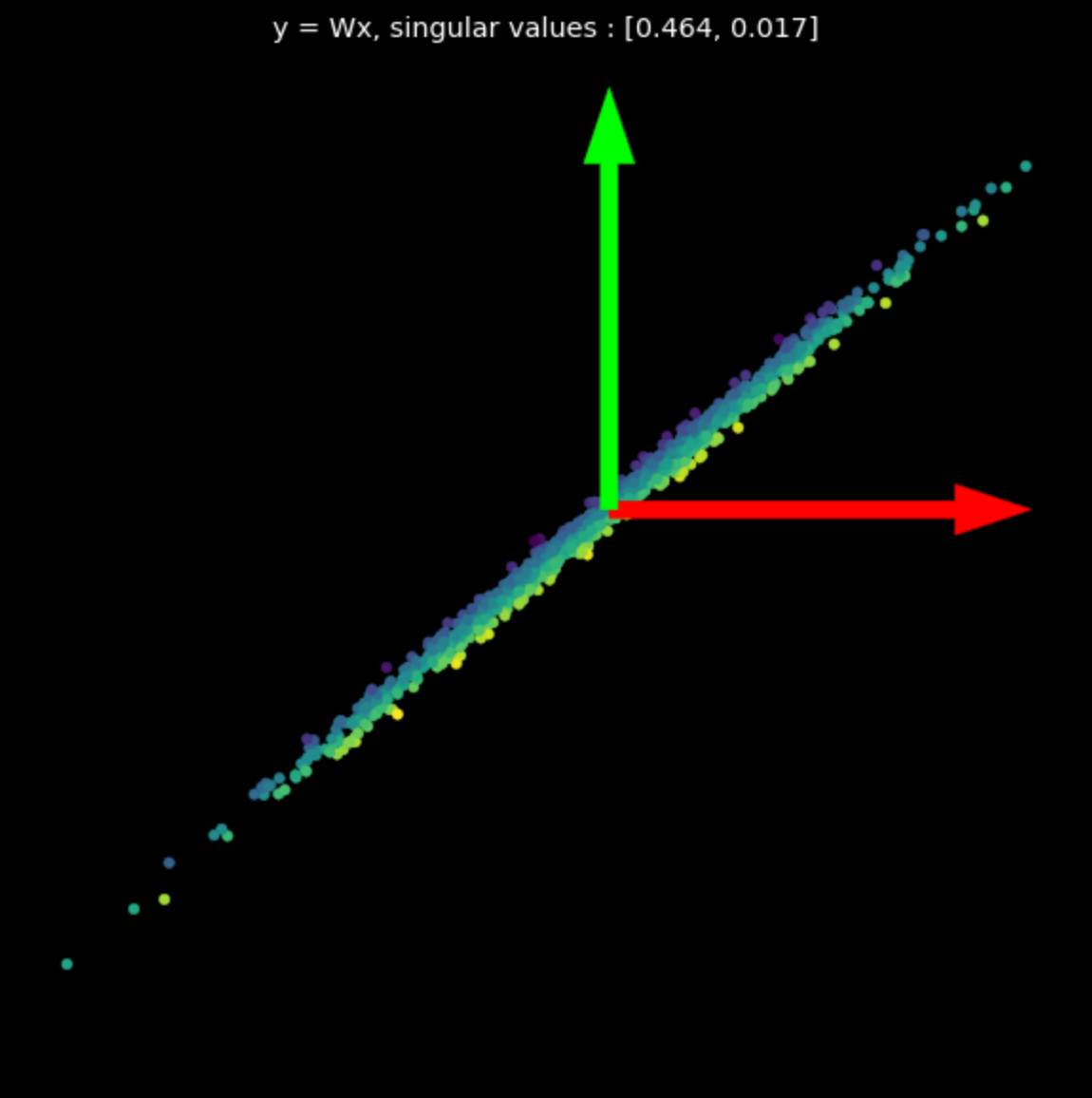 |
| (a) Первоначальные точки | (b) $s_1$ = 1.540, $s_2$ = 0.304 | (c) $s_1$ = 0.464, $s_2$ = 0.017 |
Нелинейные преобразования
После, мы визуализировали следующие преобразования:
\[f(\vx) = \tanh\bigg(\begin{bmatrix} s & 0 \\ 0 & s \end{bmatrix} \vx \bigg)\]Напомним, график $\tanh(\cdot)$ на Рис. 4.
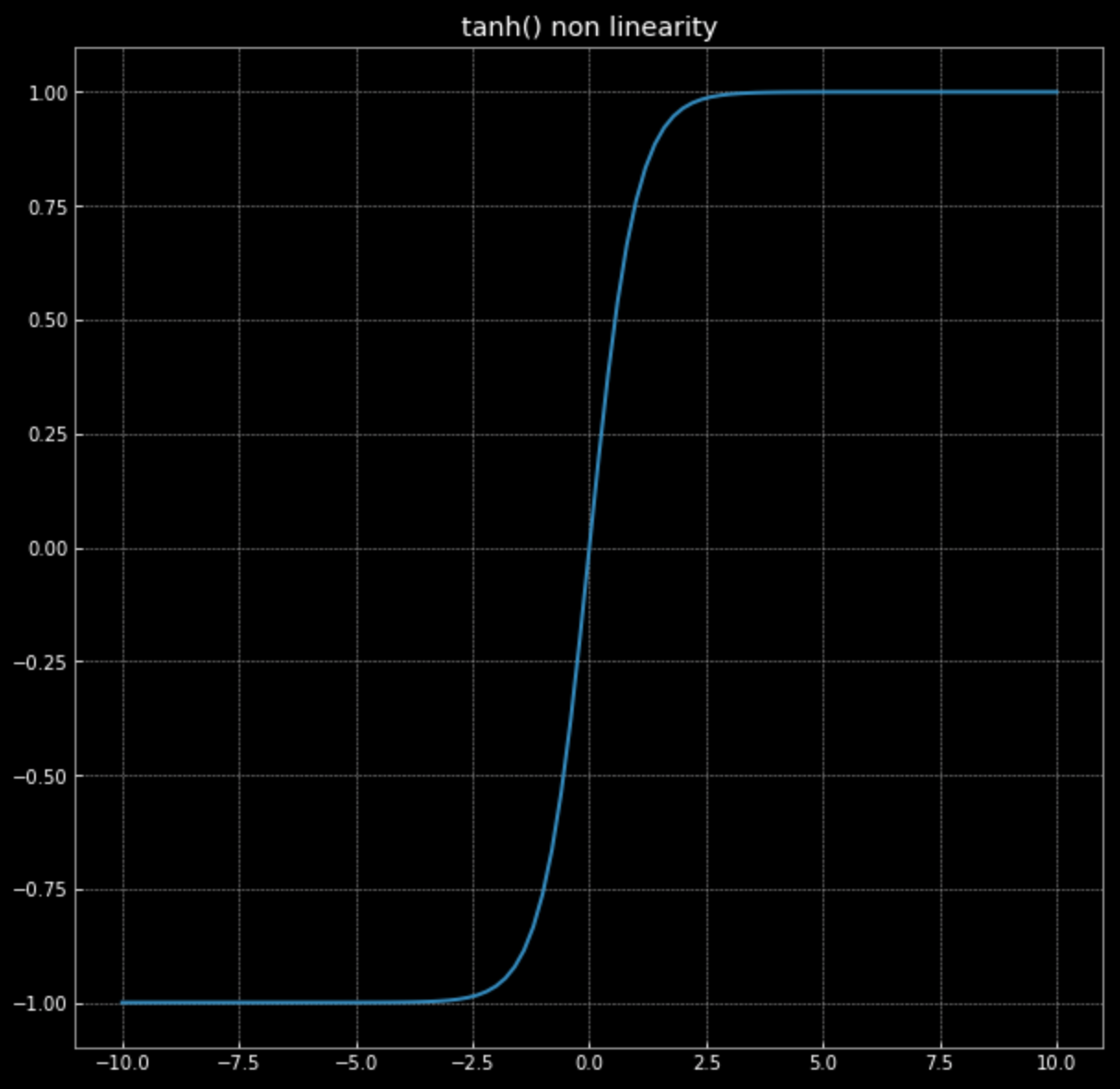
Рисунок 4: нелиненость вида гиперболический тангенс
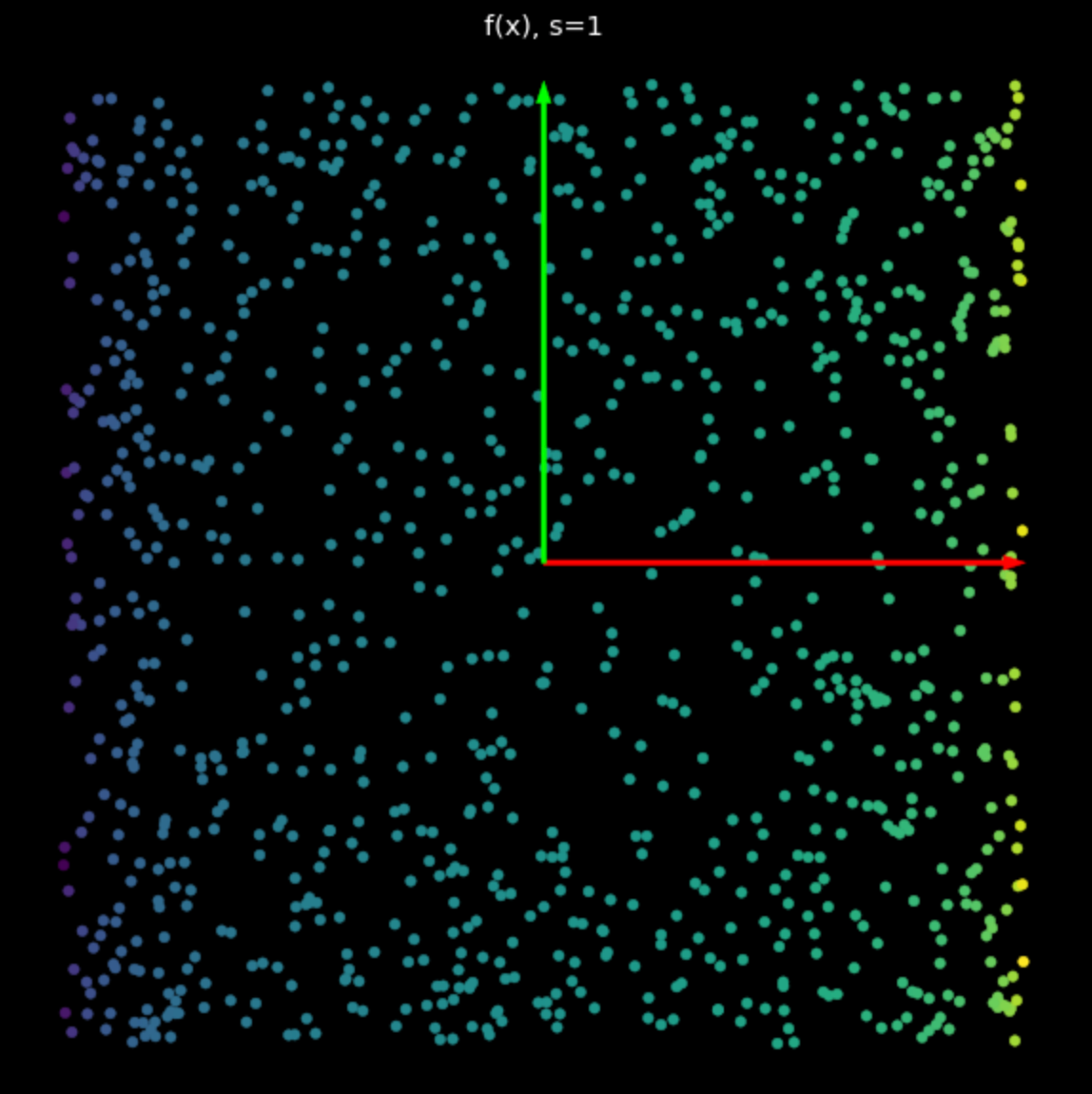
Эффект этой нелинейности заключается в ограничении точек между $-1$ и $+1$, образуя квадрат. Поскольку значение $s$ в уравнении (2) возрастает, всё больше и больше точек отодвигаются к рёбрам квадрата. Это показано на Рис. 5. Отодвигая больше точек к рёбрам, мы разбрасываем их дальше и затем можем попытаться их классифицировать.
 |
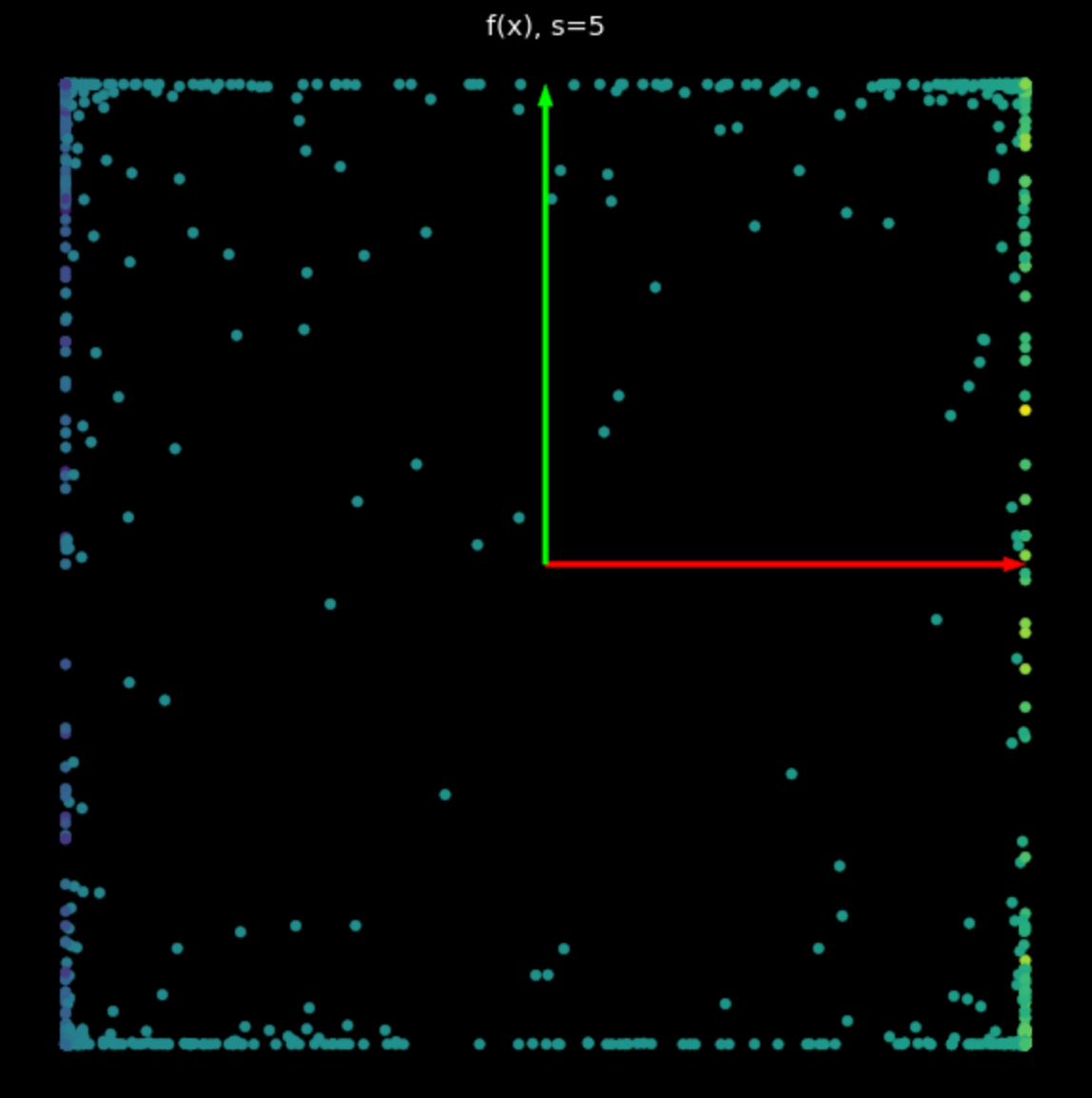 |
| (a) Нелинейность при $s=1$ | (b) Нелинейность при $s=5$ |
Произвольная нейронная сеть
Наконец, мы визуализируем преобразование, произведённое простой, необученной нейронной сетью. Сеть состоит из линейного слоя, который производит аффинное преобразование, с последующей нелинейностью вида гиперболический тангенс, и, наконец, ещё одного линейного слоя. Изучая преобразование на Рис. 6, мы видим, что оно отличается от линейных и нелинейных преобразований, виденных ранее. В дальнейшем мы увидим, как сделать эти преобразования, выполняемые нейронными сетями, полезными для нашей конечной цели классификации.
Рисунок 6: Преобразование посредством необученной нейронной сети
📝 Derek Yen, Tony Xu, Ben Stadnick, Prasanthi Gurumurthy
Evgeniy Pak
28 Jan 2020