Глубокое обучение для обработки естественного языка
🎙️ Mike LewisОбзор
- Поразительный прогресс за несколько последних лет :
- Люди предпочитают машинный перевод человеческому для некоторых языков
- Серхчеловеческая производительность на многих выборках данных с ответами на вопросы
- Модели языка генерируют плавные параграфы (например Radford и др. 2019)
- Минимальные специальные техники, необходимые для задач, которые можно решить при помощи довольно общих моделей
Модели языка
- Модели языка присваивают тексту вероятность: $p(x_0, \cdots, x_n)$
- Много возможных предложений, значит мы не можем просто обучить классификатор
- Наиболее популярный метод заключается в факторизации распределения, используя цепное правило:
Нейронные модели языка
В основном мы вводим текст в нейронную сеть, нейронная сеть подбирает соответствующий вектор для всего контекста. Этот вектор представляет следующее слово и мы получаем некоторую большую матрицу характеристик слов. Эта матрица содержит по вектору для каждого слова, которое может выдать модель. Затем мы вычисляем сходство посредством скалярного произведения контекстного вектора и вектора для каждого слова. Мы получим вероятность предсказания следующего слова, затем обучим эту модель, максимизируя вероятность. Ключевой момент здесь: мы не работаем со словами напрямую, но имеем дело с сущностями, называемыми подсловами или символами.
\[p(x_0 \mid x_{0, \cdots, n-1}) = \text{softmax}(E f(x_{0, \cdots, n-1}))\]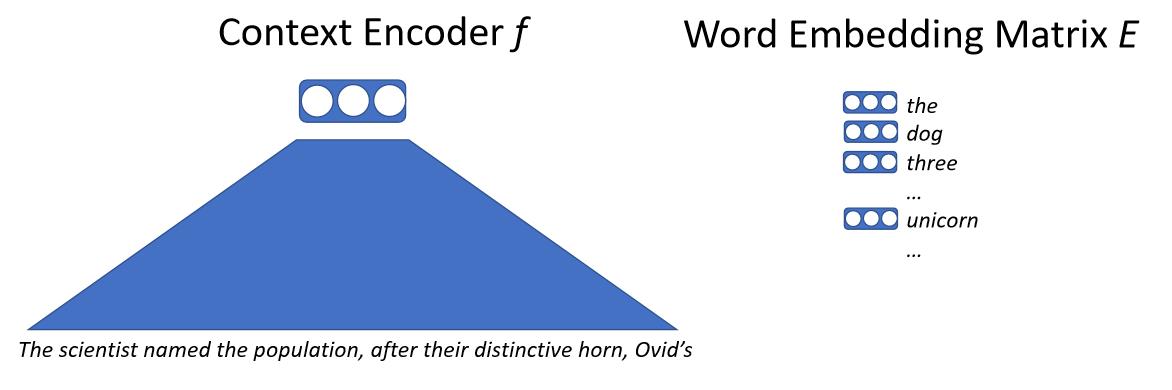
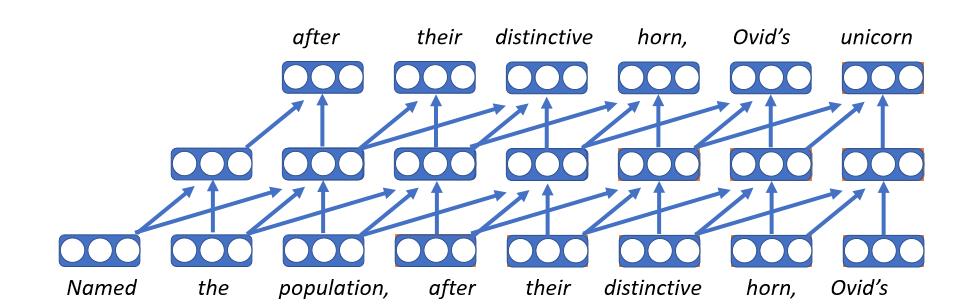
Свёрточные модели языка
- Первая нейронная модель языка
- Интерпретирует каждое слово как вектор, являясь таблицей поиска, по отношению к матрице характеристик, таким образом слово получит один и тот же вектор независимо от того, в каком контексте оно появляется
- Применяет одну и ту же сеть с прямой связью на каждом временном шаге
- К сожалению, история с фиксированной длиной означает, что она может быть обусловленна только ограниченным контекстом
- У этих моделей есть преимущество быстродействия
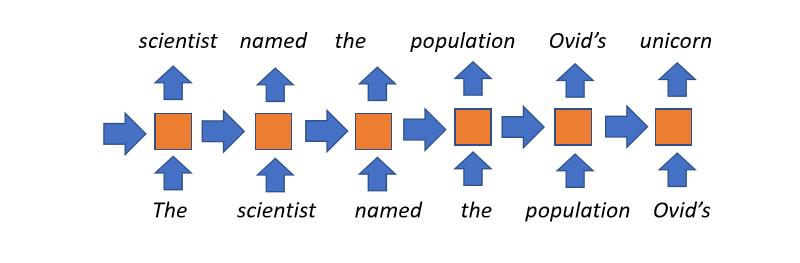
Рекуррентные модели языка
- Наиболее популярный подход вплоть до недавних лет
- Концептуально прямолинейны: на каждом временном шаге мы поддерживаем некоторое состояние (полученное из предыдущего временного шага), которое представляет то, что мы уже прочитали до сих пор. Это комбинируется с текущим прочитанным словом и используется в последующих состояниях. Затем мы повторяем этот процесс столько временных шагов, сколько нам необходимо.
- Пользуется неограниченным контекстом: в принципе название книги повлияет на скрытое состояние последнего слова в книге.
- Недостатки:
- Вся история чтения документа сжимается в вектор фиксированной размерности на каждом временном шаге, что является узким местом этой модели
- Градиенты имеют тенденцию исчезать при длинном контексте
- Нет возможности параллелизации по временным шагам, отсюда медленное обучение.
Модель языка трансформер
- Новейшая модель, используемая в естественной обработке языка
- Революционный штраф
- Три основных этапа
- Входной этап
- $n$ блоков трансформеров (кодирующих слоёв) с различными параметрами
- Выходной этап
- Пример с 6 модулями трансформерами (кодирующими слоями) в статье первоисточнике о трансформерах:
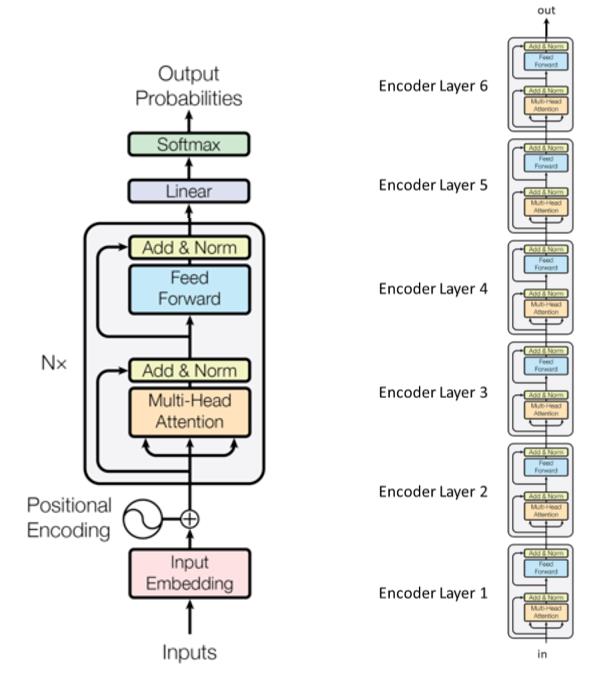
Подслои соединяются посредством элементов, отмеченных “Add&&Norm”. Часть “Add” означает остаточное соединение, которое помогает остановить исчезание градиента. Норма здесь обозначает нормализацию слоя.
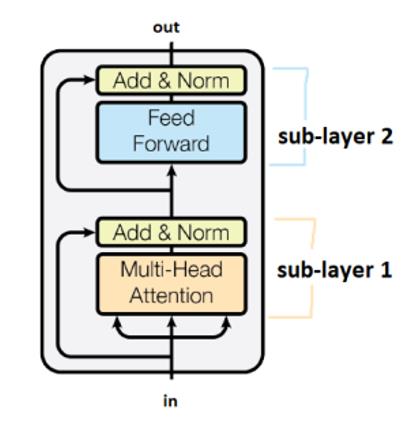
Следует отметить, что трансформеры делятся весами между временными шагами
Многоголовое внимание
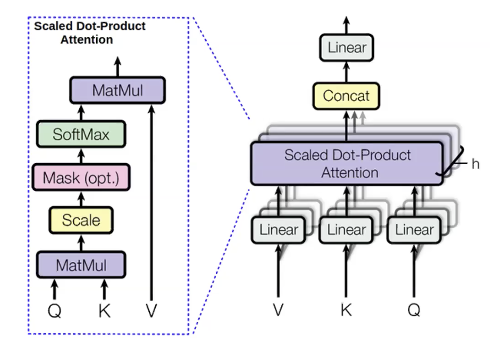
Для слов, которые мы пытаемся предсказать, мы вычисляем значения, называемые query(q). Все предыдущие слова, используемые для предсказания, мы называем keys(k). Запрос - это то, что говорит о контексте, например предыдущие прилагательные. Ключ - это что-то наподобие метки, содержащей информацию о текущем слове, такую как является ли оно прилагательным или нет. После вычисления q, мы можем получить распределение предыдущих слов ($p_i$):
\[p_i = \text{softmax}(q,k_i)\]Затем мы также вычисляем величины, называемые values(v) для предыдущих слов. Значения представляют содержимое слов.
Как только мы получили значения, вычисляем скрытые состояния, максимизируя распределение внимания:
\[h_i = \sum_{i}{p_i v_i}\]Мы вычисляем ту же самую вещь с различными запросами, значениями и ключами множество раз параллельно. Причина в том, что мы хотим предсказать следующее слово, используя различные вещи. Например, когда мы предсказываем слово “единороги”, используя три предыдущих слова “Эти” “рогатые” и “серебристо-белые”. Мы знаем, что это единорог по словам “рогатый” и “серебристо-белый”. Однако, мы можем узнать о множественном числе “единороги” по “Эти”. Поэтому мы, вероятно, захотим использовать все три слова,чтобы знать, каким должно быть следующее. Многоголовое внимание - это способ позволить каждому слову посмотреть на несколько предыдущих.
Одним из больших преимуществ многоголового внимания является его хорошая параллелизуемость. В отличие от RNNs, оно вычисляет все головы модулей многоголового внимания и все временные шаги за раз. Одна из проблем одновременного вычисления всех временных шагов заключается в том, что также возможно смотреть на будущие слова, в то время как мы хотим учитывать только предыдущие. Одно из решений этой проблемы - это так называемая self-attention маскировка. Маска - это верхнетреугольная матрица, имеющая нули в нижнем треугольнике и минус бесконечность в верхнем. Эффект добавления этой маски к выходу модуля внимания состоит в том, что каждое слово слева имеет гораздо более высокую оценку внимания, чем слова справа, поэтому модель на практике фокусируется только на предыдущих словах. Применение маски имеет решающее значение в модели языка, поскольку оно делает её математически правильной, однако в кодировщиках текста двунаправленный контекст может быть полезным.
Одна деталь, заставляющяя модель языка трансформер работать, - добавление позиционных характеристик ко входу. В языке некоторые свойства такие, как порядок важны для интерпретации. Используемая здесь техника заключается в обучении отдельных характеристик на различных временных шагах и добавлении их ко входу, так что теперь вход является суммой вектора слова и позиционного вектора. Это придаёт порядок информации.
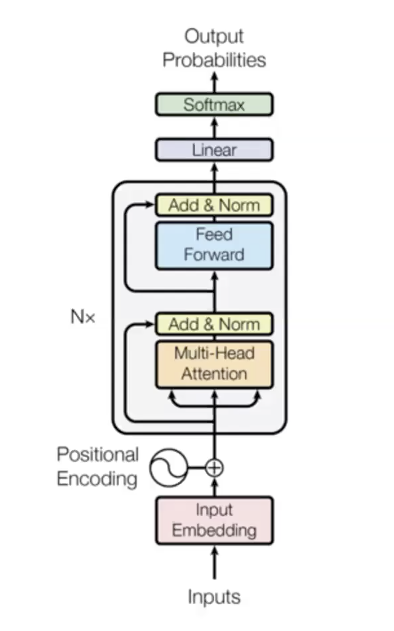
Почему модель так хороша:
- Она даёт прямые соединения между каждой парой слов. Каждое слово может быть напрямую получить доступ к скрытому состоянию предыдущих слов, смягчая исчезание градиентов. Она довольно легко обучает очень дорогие функции.
- Все временные шаги вычисляются параллельно
- Self-attention квадратично (все временные шаги могут следить за всеми другими), ограничивая максимальную длину последовательности
Некоторые прёмы (особенно для многоголового внимания и позиционного кодирования) и декодирующие модели языка
Приём 1: Широкое применение нормализации слоёв действительно полезно для стабилизации обучения
- Действительно важно для трансформеров
Приём 2: Разогрев (Warm-up) + график обучения обратный квадратный корень
- Используйте график скорости обучения: чтобы трансформеры работали хорошо, вы должны сделать скорость обучения линейно-уменьшающейся от нуля до тысячных шагов.
Приём 3: Тщательная инициализация
- Действительно полезна для таких задач, как машинный перевод
Приём 4: Сглаживание меток
- Действительно полезно для таких задач, как машинный перевод
Ниже приведены результаты некоторых методов, упомянутых выше. В этих тестах, метрикой справа, называемой ppl была перплексия (чем меньше ppl, тем лучше)
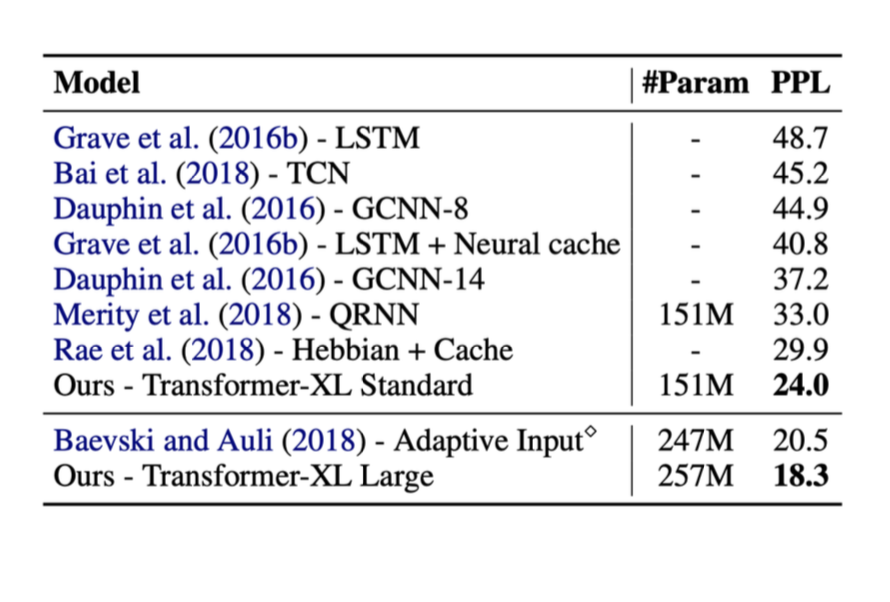
Вы могли видеть, что с появлением трансформеров, производительность значительно улучшилась.
Некоторые важные факты о моделях языка трансформерах
- Минимальный индуктивный сдвиг.
- Все слова напрямую связаны, что смягчает исчезание градиентов.
- Все временные шаги вычисляются параллельно.
Self-attention квадратично (все временные шаги могут следить за всеми другими), ограничивая максимальную длину последовательности.
- Поскольку self-attention квадратично, его стоимость растёт линейно на практике, что может вызывать проблемы.

Трансформеры очень хорошо масштабируются
- Неограниченные обучающие данные, даже больше, чем вам нужно
- GPT 2 использовала 2 миллиарда параметров в 2019
- Последние модели используют до 17Млрд параметров в 2020
Декодирующие модели языка
Мы можем сейчас обучить вероятностное распределение по тексту - теперь, по сути, мы можем получить экспоненциально много различных выходов, поэтому мы не можем вычислить максимум. Какой бы выбор вы ни сделали для первого слова, оно может повлиять на все остальные решения. Таким образом, учитывая это, жадное декодирование было представлено следующим образом.
Жадное декодирование не работает
Мы берём наиболее вероятное слово на каждом временном шаге. Однако, нет никаких гарантий, что такой подход даст наиболее вероятную последовательность, потому что если вы сделали этот шаг в какой-то момент, у вас нет пути отслеживания предыдущих шагов, чтобы отменить предыдущие решения.
Полный перебор также невозможен
Он требует вычисления всех возможных последовательностей и поскольку сложность порядка $O(V^T)$, это будет очень дорого
Вопросы и ответы для понимания
- В чём преимущество многоголового внимания по сравнению с моделью одноголового внимания?
- Чтобы предсказать следующее слово, вам нужно наблюдать несколько различных вещей, другими словами внимание можно сосредоточить на нескольких предыдущих словах, пытаясь понять контекст, необходимый для предсказания следующего слова
- Как трансформеры решают информационно узкие места CNNs и RNNs ?
- Модели внимания позволяют установить прямую связь между всеми словами, позволяя каждому слову быть обусловленным всеми предыдущими, эффективно устраняя это узкое место.
- Чем трансформеры отличаются от RNN в смысле использования параллелизации GPU?
- Модули многоглового внимания в трансформерах хорошо параллелизуемы, тогда как RNNs - нет, и поэтому рекуррентные сети не могут использовать преимущество GPU технологий. По факту трансформеры вычисляют все временные шаги за раз в один прямой проход.
📝 Jiayu Qiu, Yuhong Zhu, Lyuang Fu, Ian Leefmans
Evgeniy Pak
20 Apr 2020