Декодирующие модели языка
🎙️ Mike LewisЛучевой поиск
Лучевой поиск - это ещё одна техника декодирования модели языка и генерации текста. На каждом шаге алгоритм отслеживает $k$ наиболее вероятных (наилучших) частичных переводов (гипотез). Оценка каждой гипотезы равна логарифму её вероятности.
Алгоритм выбирает гипотезы с лучшей оценкой.
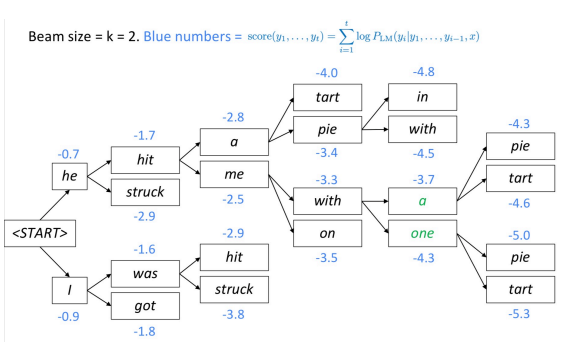
Рис. 1: Лучевое декодирование
Как глубоко разветвляется лучевое дерево ?
Лучевое дерево продолжается, пока не достигнет конца предложения. После вывода конца предложения, гипотеза завершена.
Почему (в нейронном машинном переводе) очень большие размерности луча часто приводят к пустому переводу?
В момент обучения алгоритм часто не использует луч, поскольку это очень дорого. Вместо этого используется авторегрессивная факторизация (по данному предыдущему корректному выходу, предсказывает $n+1$ первых слов). Модель не отображает собственные ошибки в процессе обучения, так что возможно появление “бессмыслицы” в луче.
Сводка: Продолжайте лучевой поиск, пока все $k$ гипотез порождают конечный токен или пока не достигнете максимального предела декодирования T.
Семплирование
Нам может быть не нужна наиболее вероятная последовательность. Вместо этого мы можем семплировать из распределения модели.
Однако выборка из распределения модели приносит свои проблемы. После “плохого” выбора, модель находится в состоянии, с которым никогда не сталкивалась в процессе обучения, возрастает вероятность продолжения “плохой” оценки. Алгоритм может затем застрять в ужасных циклах обратной связи.
Топ-K семлирование
Чистая техника семплирования, где вы усекаете распределение до $k$ наилучших и затем перенормализуете и выбираете из распределения.
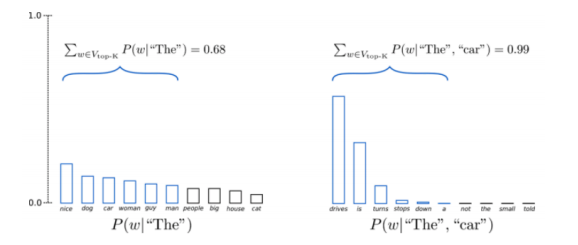
Рис. 2: Топ K семлирование
Вопрос: Почему Топ-K семплирование работает так хорошо?
Этот метод работает хорошо, поскольку он по сути пытается предотвратить выход за пределы многообразия хорошего языка, когда мы выбираем что-то плохое, используя только головную часть распределения и обрезая хвостовую часть.
Оценка генерации текста
Оценка модели языка требует просто вычислить логарифм вероятности выведенных данных. Однако, таким образом сложно оценить текст. Обычно используются метрики совпадения слов с упоминанем (BLEU, ROUGE etc.), но у них есть свои проблемы.
Sequence-To-Sequence модели
Обусловленные модели языка
Обусловленные модели языка не подходят для генерации случайых семплов на английском, но они полезны для генерации текста по заданному входу.
Примеры:
- По заданному предложению на французском сгенерируйте английский перевод
- По заданному документу сгенерируйте краткое изложение
- По заданному диалогу сгенерируйте следующий ответ
- По заданному вопросу сгенерируйте ответ
Sequence-To-Sequence модели
Обычно входной текст закодирован. Эта результирующая характеристика известна как “thought vector”, которая затем передаётся декодеру для генерации токенов слово за слово.
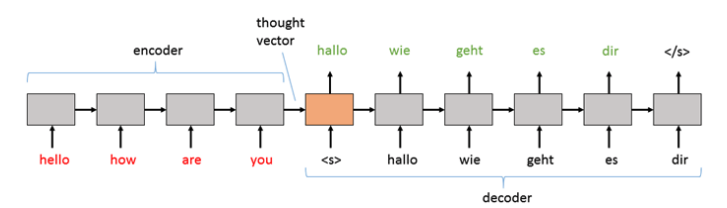
Рис. 3: Thought Vector
Sequence-To-Sequence трансформер
Sequence-to-sequence варианты трансформеров имеют 2 стека:
-
Стек кодировщик – Self-attention не маскируется, так что каждый входной токен может смотреть на любой другой токен входа
-
Стек декодировщик – Помимо использования внимания на себе, он также использует внимание по всему входу
Рис. 4: Sequence to Sequence трансформер
Каждый токен на выходе имеет прямую связь с каждым предыдущим выходным токеном, а также с каждым входным словом. Связи делают модели очень выразительными и мощными. Эти трансформеры улучшили оценку в машинном переводе по сравнению с предыдущими рекуррентными и свёрточными моделями.
Обратный перевод
При обучении этих моделей мы обычно полагаемся на большие объёмы размеченного текста. Хороший источник данных - это отчёты Европейского Парламента - текст вручную переведён на несколько языков, который мы можем затем использовать как входы и выходы модели.
Проблемы
- Не все языки представлены в Европейском Парламенте, означая, что мы не получим пары переводов по всем языкам, в которых мы можем заинтересоваться. Как мы находим текст для обучения на языке, для которого мы не можем получить данные?
- Поскольку модели как трансформеры намного более производительны при большем количестве данных, как мы используем монолингвистический текст эффективно, т.е. нет входных / выходных пар?
Предположим, мы хотим обучить модель для перевода с немецкого языка на английский. Идея обратного перевода заключается в том, что сперва обучаем обратную модель с английского на немецкий.
- Используя некоторый ограниченный парный текст, мы можем получать одинаковые предложения на двух различных языках
- Как только мы имеем модель перевода с английского языка на немецкий, переводим множество монолингвистических слов с английского на немецкий.
Наконец, обучаем модель перевода с немецкого языка на английский, используя немецкие слова, которые были ‘обратно переведены’ на предыдущем шаге. Отметим, что:
- Неважно, насколько хороша обратная модель - мы можем иметь зашумленные немецкие переводы, но в итоге чисто перевести на английский.
- Нам нужно обучить модель, чтобы понимать английский хорошо за пределами данных англиских/немецких пар (уже переведённых) - использовать большие объёмы монолингвистических данных на английском языке
Итеративный обратный перевод
- Мы можем итерировать процедуру обратного перевода, чтобы генерировать ещё больше двунаправленных текстовых данных и достичь лучшей производительности - просто продолжая обучаться на монолингвистических данных.
- Сильно помогает, когда немного параллельных данных
Массивный мультиязычный машинный перевод
Рис. 5: мультиязычный машинный перевод
- Вместо того, чтобы пытаться обучить модель переводить с одого языка на другой, попытаться создать нейронную сеть для обучения переводам на несколько языков.
- Модель изучает некоторую общую языко-независимую информацию.

Рис. 6: Результаты мультиязычной нейронной сети
Отличные результаты, особенно если мы хотим обучить модель переводить на язык, для которого у нас нет много доступных данных (низко ресурсный язык).
Обучение без учителя для естественной обработки языка
Есть большое количество текстовых данных без какой-либо разметки и немного размеченных данных. Как много мы можем изучить о языке, просто читая неразмеченный текст?
word2vec
Наитие - если слова появляются близко друг к другу в тексте, они вероятно связаны между собой, поэтому мы надеемся, что просто посмотрев на неразмеченный английский текст, мы можем обучиться, что они значат.
- Целью является изучить векторное пространство представлений слов (изучить характеристики)
Задача предобучения - замаскируем некоторые слова и используем соседние слова, чтобы заполнить пробелы.

Рис. 7: word2vec визуализация маскировки
Например, здесь, идея заключается в том, что “рогатый” и “седовласый” более вероятно появятся в контексте “единорога”, чем какого-то другого животного.
Возьмём слова и применим линейную проекцию
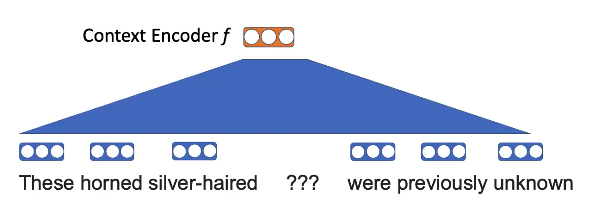
Рис. 8: word2vec характеристики
Хотим узнать
\[p(\texttt{единороги} \mid \texttt{Эти седовласые ??? были ранее неизвестны})\] \[p(x_n \mid x_{-n}) = \text{softmax}(\text{E}f(x_{-n})))\]Характеристики слов придерживаются некоторой структуры
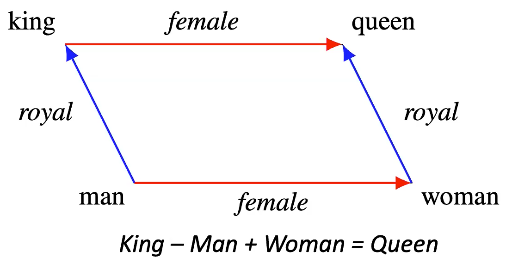
Рис. 9: Пример структуры характеристик
- Идея заключается в том, что если мы возьмём характеристический вектор для слова “король” после обучения и добавим характеристический вектор для слова “женский” мы получим характеристику, очень близкую к слову “королева”
- Показывает некоторые выразительные разности между векторами
Вопрос: Представления слов зависимы или независимы от контекста?
Независимы и не имеют представления, как они зависят от других слов
Вопрос: Какой может быть пример ситуации, затруднительный для данной модели?
Интерпретация слов сильно зависит от контекста. Поэтому на примерах двусмысленных слов - слов, которые могут иметь множество значений - модель будет затрудняться, поскольку характеристические вектора не будут захватывать контекст, необходимый для корректного понимания слова.
GPT
Чтобы добавить контекст, мы можем обучить обусловленную модель языка. Затем, по заданной модели языка, которая предсказывает слово на каждом временном шаге, заменяем каждый выход модели на некоторую другую характеристику.
- Предобучение - предсказываем следующее слово
- Тонкая настройка - заменяем на специфическую задачу. Например:
- Предсказываем где существительное, а где прилагательное
- По заданному некоторому тексту, содержащему обзор с Amazon, предсказать оценку настроения для обзора
Этот подход хорош, поскольку мы можем использовать модель повторно. Мы предобучаем одну большую модель и можем тонко настраивать её для других задач.
ELMo
GPT рассматривает только левосторонний контекст, что означает модель не может зависеть от каких-либо будущих слов - это ограничивает, что модель не может делать довольно много.
Подход заключается в обучении двух моделей языка
- Одну на тексте слева направо
- Одну на тексте справа налево
- Конкатенируем выходы двух моделей, чтобы получить представление слова. Теперь можно обусловливать на обоих: правостороннем и левостороннем контексте.
Это до сих пор “поверхностная” комбинация, и мы хотим некоторое более сложное взаимодействие между левым и правым контекстом.
BERT
BERT похож на word2vec в том смысле, что у нас также есть задача заполнения пробелов. Однако, в word2vec у нас есть линейные проекции в то время, как в BERT есть большой трансформер, которые может посмотреть больше контекста. Для обучения мы маскируем 15% токенов и пытаемся предсказать пробелы.
Можем увеличить масштаб BERT (RoBERTa):
- Упростим задачу предобучения BERT
- Увеличим размер батча
- Обучим на большом количестве GPUs
- Обучим на ещё большем количестве текста
Ещё больше улучшений поверх BERT производительности - в задаче ответов на вопросы сейчас производительность свехрчеловека.
Предобучение для обработки естественного языка
Давайте кратко рассмотрим различные подходы предобучения самостоятельного обучения, разработанные для естественной обработки языка.
-
XLNet:
Вместо того, чтобы предсказывать все замаскированные токены условно-независимо, XLNet предсказывает замаскированные токены авторегрессивно в случайном порядке
-
SpanBERT
Маскирует диапазон (последовательность слов) вместо токенов
-
ELECTRA:
Вместо маскировки слов, мы заменяем токены на похожие. Затем мы решаем задачу бинарной классификации, пытаясь предсказать, где были заменены токены.
-
ALBERT:
Облегченный Bert: Мы модифицируем BERT и облегчаем его уменьшая количество весов the weights в слоях. Это уменьшает количество параметров модели и сложные вычисления. Интересно, что авторам ALBERT не пришлось сильно жертвовать точностью.
-
XLM:
Мультиязычный BERT: Вместо подачи английского текста, мы подаём текст из множества языков. Как и ожидалось, она изучает межязыковые соединения лучше.
Ключевые выводы из различных моделей, упомянутых выше:
-
Много различных задач предобучения работают хорошо!
-
Глубина модели критична, двунаправленные взаимодействия между словами
-
Большой выигрыш от увеличения масштабов предобучения, до сих пор без чётких ограничений.
Большинство моделей, обсуждённых выше разработаны для решения задачи классификации текста. Однако, для решения задачи генерации текста, где мы генерируем выход последовательно, очень похоже на seq2seq модель, нам нужен немного другой подход для предобучения.
Предобучение для обусловленной генерации: BART и T5
BART: предобучение seq2seq модели посредством очищения текста от шумов
В BART для предобучения мы берём последовательность и искажаем её, маскируя токены случайным образом. Вместо предсказания замаскированных токенов (как в задаче BERT), мы подаём целую искажённую последовательность и пытаемся предсказать искажённую последовательность целиком.
Этот seq2seq подход предобучения даёт нам гибкость в дизайне наших искажённых схем. Мы можем перемешивать предложения, удалять фразы, вставлять новые фразы и т. д.
BART сопоставим с RoBERTa на задачах SQUAD и GLUE. Однако, он был новым SOTA на обобщениях, диалогах и абстрактных вопросах/ответах выборках данных. Эти результаты усиливают нашу мотивацию для BART, быть лучше в задачах генерации текста, чем BERT/RoBERTa.
Некоторые открытые вопросы в естественной обработке языка NLP
- Как нам интегрировать мировые знания
- Как нам моделировать длинные документы? (модели на основе BERT обычно используют 512 токенов)
- Как нам лучше всего выполнять многозадачное обучение?
- Можем ли мы выполнять тонкую настройку с меньшим количеством данных?
- Эти модели на самом деле понимают язык?
Резюме
- Обучение моделей на большом количестве данных лучше, чем явное моделирование лингвистической структуры
С точки зрения дисперсии смещения, трансформеры малосмещённые (очень выразительные) модели. Подавая этим моделям большое количество текста лучше явного моделирования лингвистических структур (сильно смещённых). Архитектуры должны сжимать последовательность дл прохождения через узкие места
-
Модели могут изучить много о языке, предсказывая слова в неразмеченном тексте. Это оказывается отличной задачей обучения без учителя. Тонкая настройка для специфических задач после проста.
-
Двунаправленность контекста критична
Дополнительные идеи из вопросов после лекции:
Какими способами можно измерить ‘понимание языка’? КАк мы можем узнать, что эти модели действительно понимают язык?
“Трофей не поместился в чемодан, поскольку он был очень большим”: Разрешить ссылку ‘оно’ в этом предложении сложно для машин. Люди хороши в этой задаче. Есть выборка данных, состоящая из подобных сложных примеров и люди достигают 95% точности на этой выборке. Компьютерные программы были способны достичь лишь около 60% до революции, совершённой трансформерами. Современные модели транфсормеры способны достигать больше 90% на этой выборке данных. Это повзоляет предположить, что эти модели не просто запоминают / эксплуатируют данные, но изучают концепции и объекты посредством статистических шаблонов в данных.
Более того, BERT и RoBERTa достигают сверхчеловеческой производительности на SQUAD и Glue. Текстовые сводки, сгенерированные BART,смотрятся очень реалистично для людей (высокие оценки BLEU). Эти факты свидетельства того, что модели понимают язык в каком-то плане.
Приземлённый язык
Интересно, что лектор (Майк Льюис, Учёный исследователь, FAIR) работает над концепцией, называемой ‘Grounded Language’. Цель этой области исследований создать разоговорных агентов, которые будут способны болтать или вести переговоры. Болтовня и переговоры абстрактные задачи с нечёткими целями по сравнению с классификацией текста или резюмирование текста.
Можем ли мы оценить, когда модель уже обладает мировыми знаниями?
‘Мировые знания’ это абстрактная концепция. Мы можем тестировать модели на очень базовом уровне на их мировые знания, спрашивая их простые вопросы о концепциях, которые нам интересны. Модели как BERT, RoBERTa и T5 имеют миллиарды параметров. Учитывая, что эти модели обучаются на большом своде информационного текста, как Википедия, они запомнили бы факты, используя их параметры и смогли бы ответить на наши вопросы. Более того, мы можем также подумать о проведении того же самого теста знаний до и после тонкой настройки модели для какой-либо задачи. Это даст нам представление о том, как много информации “забыла” модель.
📝 Trevor Mitchell, Andrii Dobroshynskyi, Shreyas Chandrakaladharan, Ben Wolfson
Evgeniy Pak
20 Apr 2020