그래프를 이용한 에너지 기반 방법
🎙️ Yann LeCun손실 비교하기
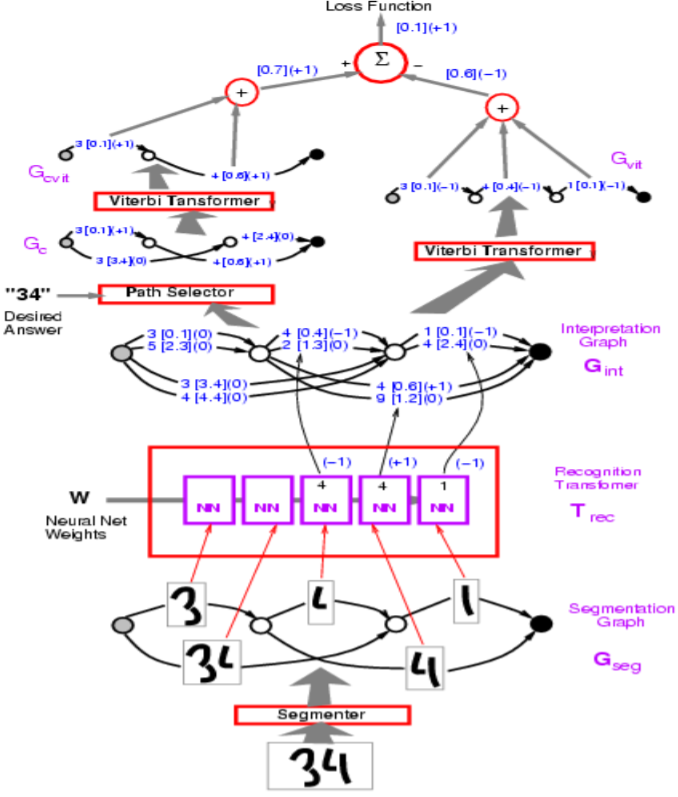
그림 1: 네트워크 구조
위 그림에서, 오답 경로는 -1의 값을 갖는다.
르쿤 교수는 위 그림의 그래프 트랜스포머 모델Graph Transformer Model의 예에서 사용된 퍼셉트론 손실로 시작한다. 목표는 오답의 에너지를 크게 만들고, 정답의 에너지를 작게 만드는 것이다.
구현 측면에서는, 그림 속의 호arcs를 벡터로 표시한다. 각각의 범주를 서로 다른 호를 통해 표현하기보다, 하나의 벡터가 범주와 각 범주에 대한 점수를 모두 포함한다.
질문: 위 모델에서 분할기segmentor는 어떻게 구현됩니까?
대답: 분할은 손으로 만들어진 휴리스틱이다. 이 모델은 수작업으로 만들어진 분할을 사용하지만 한 쪽 끝에서 다른 쪽 끝까지end-to-end 훈련시킬 수 있는 방법이 있다. 이 수작업 방식은 문자 인식을 위한 슬라이딩 윈도우sliding window 방식으로 대체되었다.
손실에 대한 개요
| Loss Equation | Formula | Margin |
|---|---|---|
| Energy Loss | $\text{E}(\text{W}, \text{Y}^i, \text{X}^i)$ | None |
| Perceptron | $\text{E}(\text{W}, \text{Y}^i, \text{X}^i)-\min\limits_{\text{Y}\in\mathcal{Y}}\text{E}(\text{W}, \text{Y}, \text{X}^i)$ | 0 |
| Hinge | $\max\big(0, m + \text{E}(\text{W}, \text{Y}^i,\text{X}^i)-\text{E}(\text{W}, \overline{\text{Y}}^i,\text{X}^i)\big)$ | $m$ |
| Log | $\log\bigg(1+\exp\big(\text{E}(\text{W}, \text{Y}^i,\text{X}^i)-\text{E}(\text{W}, \overline{\text{Y}}^i,\text{X}^i)\big)\bigg)$ | >0 |
| LVQ2 | $\min\bigg(M, \max\big(0, \text{E}(\text{W}, \text{Y}^i,\text{X}^i)-\text{E}(\text{W}, \overline{\text{Y}}^i,\text{X}^i)\big)\bigg)$ | 0 |
| MCE | $\bigg(1+\exp\Big(-\big(\text{E}(\text{W}, \text{Y}^i,\text{X}^i)-\text{E}(\text{W}, \overline{\text{Y}}^i,\text{X}^i)\big)\Big)\bigg)^{-1}$ | >0 |
| Square-Square | $\text{E}(\text{W}, \text{Y}^i,\text{X}^i)^2-\bigg(\max\big(0, m - \text{E}(\text{W}, \overline{\text{Y}}^i,\text{X}^i)\big)\bigg)^2$ | $m$ |
| Square-Exp | $\text{E}(\text{W}, \text{Y}^i,\text{X}^i)^2 + \beta\exp\big(-\text{E}(\text{W}, \overline{\text{Y}}^i,\text{X}^i)\big)$ | >0 |
| NNL/MMI | $\text{E}(\text{W}, \text{Y}^i,\text{X}^i) + \frac{1}{\beta}\log\int_{y\in\mathcal{Y}}\exp\big(-\beta\text{E}(\text{W}, y,\text{X}^i)\big)$ | >0 |
| MEE | $1-\frac{\exp\big(-\beta E(W,Y^i,X^i)\big)}{\int_{y\in\mathcal{Y}}\exp\big(-\beta E(W,y,X^i)\big)}$ | >0 |
위의 표에 있는 퍼셉트론 손실은 마진을 가지고 있지 않아서 손실이 무너질collapsing 위험이 있다.
- 힌지Hinge 손실은 오답의 정도가 가장 큰(가장 문제가 되는)offending 답과 정답을 가지고 그 둘 사이의 차이를 계산한다. 직관적으로 살펴보면, 마진 m을 사용하면 올바른 에너지가 가장 문제가 되는 에너지보다 최소 m 만큼 낮을 때에만 힌지의 손실이 0이 된다.
- MCE 손실은 음성 인식에서 사용되고, 시그모이드sigmoid와 유사하게 생겼다.
- NLL 손실은 정답의 에너지를 작게 만들고, 방징식 안의 로그 부분을 크게 만드는 것을 목표로 한다.
질문: 어떻게 힌지 손실이 NLL 손실보다 나을 수 있습니까?
대답: 힌지 손실이 NLL 손실보다 나은 이유는, NLL은 정답과 다른 답 사이의 차이를 무한대로 밀어붙이려 하는 반면, 힌지는 단지 어떤 값 (마진 m) 보다 그 차이를 크게 만들고자 하기 때문이다.
정의:
디코더는 각각의 소리 또는 이미지의 점수 또는 에너지를 나타내는 일련의 벡터를 입력하고 가능한한 최상의 출력을 선택한다.
질문: 디코더를 사용할 수 있는 문제의 예는 어떤 것들 입니까? 대답: 언어 모델링, 기계 번역, 그리고 시퀀스 태깅sequence tagging 등이 있습니다.
그래프 트랜스포머 네트워크에서의 순방향forward 알고리즘
그래프 구성
그래프 구성을 통해 두 개의 그래프를 결합 할 수 있다. 이 예에서 $trie$ (그래프)로 표현되는 언어 모델 어휘와 신경망으로 생성된 인식 그래프recognition graph를 확인할 수 있다.
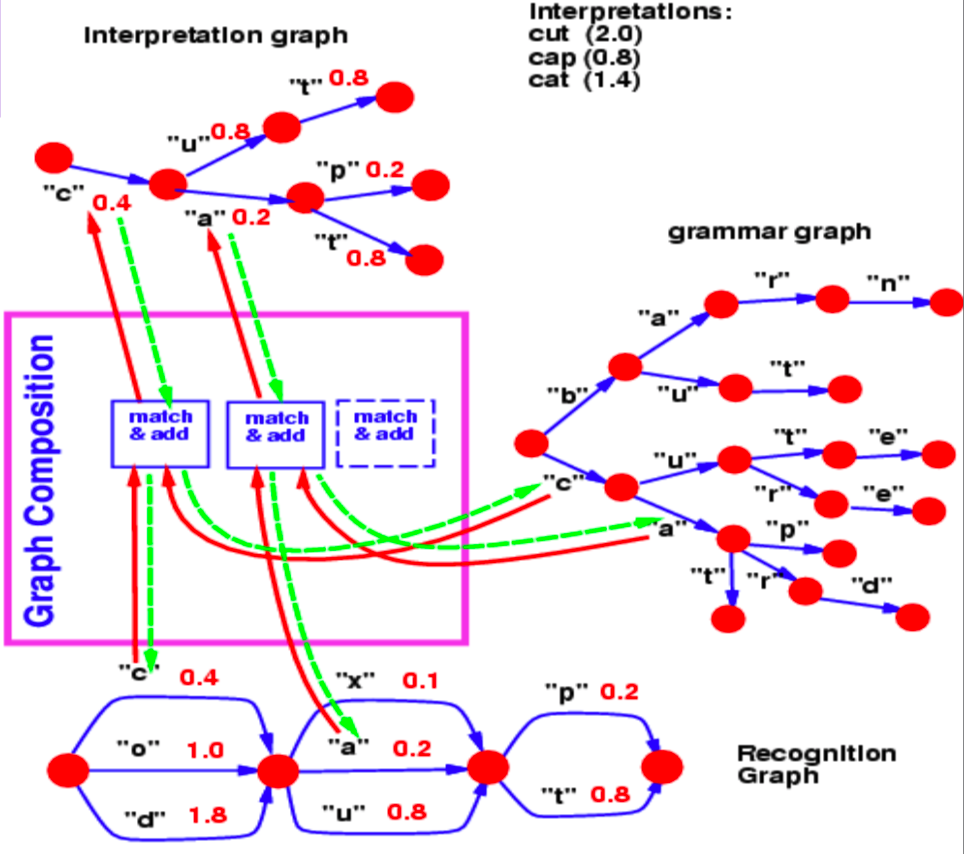
그림 2: 그래프 구성
인식 그래프는 각 문자가 특정 단계에 있을 가능성을 각기 다른 에너지 값(각 호와 연관되어 있음)으로 지정한다.
이제 이 예시에서 그래프 구성을 통해 우리가 대답하고자 하는 문제는 이 인식 그래프에서 우리의 어휘와 일치하는 최상의 경로가 무엇인가에 대한 것이다.
인식 그래프와 문법 사이의 1단계에서 2단계로의 일반적인 점프는 에너지 0.4와 연관된 문자 $c$ 이다. 따라서 해석 그래프interpretation graph는 $c$에 대응하는 1단계에서 2단계 사이의 호를 한 개 가진다. 마찬가지로, 인식 그래프에서 단계 2에서 단계 3 사이의 가능한 문자는 $x$, $u$ 그리고 $a$ 이다. 문법 그래프에서 $c$ 에서 뻗어나온 가지는 $u$ 와 $a$ 를 갖는다. 따라서 그래프 구성 작업은 호 $u$ 와 $a$ 를 해석 그래프에 표시할 호로 선택한다. 또한 인식 그래프에서 복사한 호를 에너지 값과 연결한다.
호와 관련된 값이 문법에도 포함되어 있다면, 그래프 구성은 에너지 값을 추가하거나 다른 연산자를 사용하여 그 값들을 결합했을 것이다.
비슷한 방식으로 그래프 구성을 통해 신경망으로 표현되는 두 개의 지식 베이스knowledge bases를 결합할 수도 있다. 위에서 논의된 예시에서, 문법은 본질적으로 다음 문자를 예측해 내는 신경망으로 표현될 수 있다. 신경망의 소프트맥스 출력은 주어진 노드에서 다음 문자로의 전환transition 확률을 제공한다.
참고로, 이 예에서 표현된 언어 모델이 신경망인 경우, 전체 구조를 통해 역전파backpropagate를 할 수 있다. 이는 루프, if-조건문, 재귀 등을 포함한 프로그램을 통해 역전파 하는 차별화 가능한 프로그램의 예시가 된다.
90년대 중반의 수표 판독기
90 년대 중반의 수표 판독기가 가지는 전체 구조는 굉장히 복잡하지만, 우리가 주로 관심을 갖는 부분은 인식 그래프를 생성하는 문자 인식기에서 시작한다.
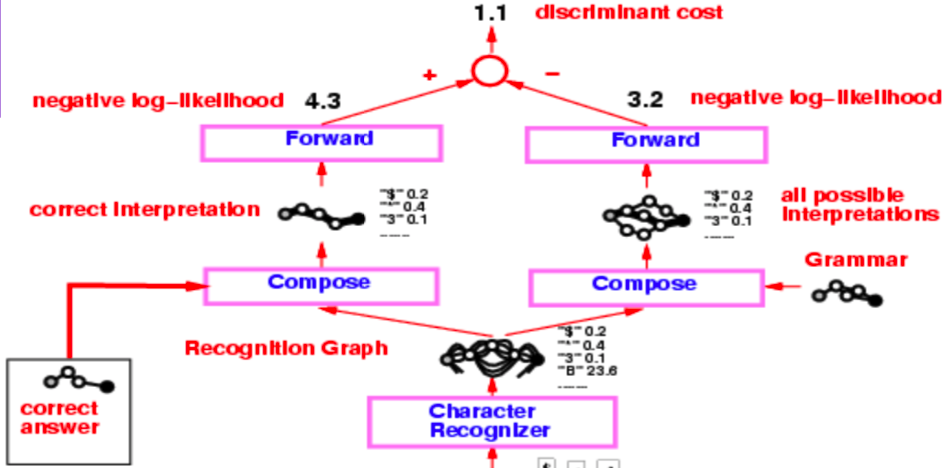
그림 3: 수표 판독기
이 인식 그래프는 두 개의 구별되는 구성 작업을 거치고, 하나는 정답 해석 (또는 실제 값 또는 데이터ground truth) 그리고 다른 하나는 모든 가능한 해석의 그래프를 만드는 문법을 사용한다.
전체 시스템은 음의 로그 우도 손실 함수Negative Log-Likelihood loss function를 통해 훈련된다. 음의 로그 우도는 해석 그래프의 각 경로가 가능한 해석이고, 그 경로를 따른 에너지의 합이 해당 해석의 에너지임을 나타낸다.
이제 Viterbi 알고리즘을 사용하는 대신, 순방향 알고리즘을 사용한다. 이어지는 하위 섹션에서는 이 두 접근 방식의 차이점에 대해 논의한다.
Viterbi 알고리즘
Viterbi 알고리즘은 동적 프로그래밍 알고리즘으로써 주어진 그래프에서 가장 가능성이 높은 경로 (혹은 최소의 에너지를 갖는 경로)를 찾는데 사용된다. 잠재 변수 z를 고려한 에너지를 최소화하고, 여기서 z는 그래프에서 우리가 취하는 경로를 나타낸다.
\[F (x, y) = \min_{z} \; E(x, y, z)\]순방향forward 알고리즘
반면에 순방향 알고리즘은 모든 경로에 대해 음수 에너지 값의 지수값을 구하고 그것을 총합한 것에 로그를 취한 값을 계산한다. 이 기나긴 표현은 간단하게 아래의 공식으로 표현될 수 있다.
\[F_{\beta} (x, y) = -\frac{1}{\beta} \; \log \; \sum_{z \, \in \, \text{paths}} \; \exp \, (- \beta \; E(x, y, z))\]이것은 해석 그래프에서 경로를 결정하는 잠재 변수 z에 대해 마지널라이징marginalising한다. 이 접근 방식은 특정한 노드에 대해 가능한 모든 경로에 대해 Log-Sum-Exponential을 취하여 계산한다. 이는 마치 소프트-미니멈soft-minimum 방식으로 가능한 모든 경로의 비용을 합하는 것과 같다.
순방향 알고리즘은 Viterbi 알고리즘보다 구현하는데 드는 수고가 적다. 또한, 순방향 알고리즘 노드를 통해 그래프를 역전파 할 수 있다.
순방향 알고리즘의 작동은 다음 예시에서 정의된 해석interpretation 그래프 위에서 확인할 수 있다.
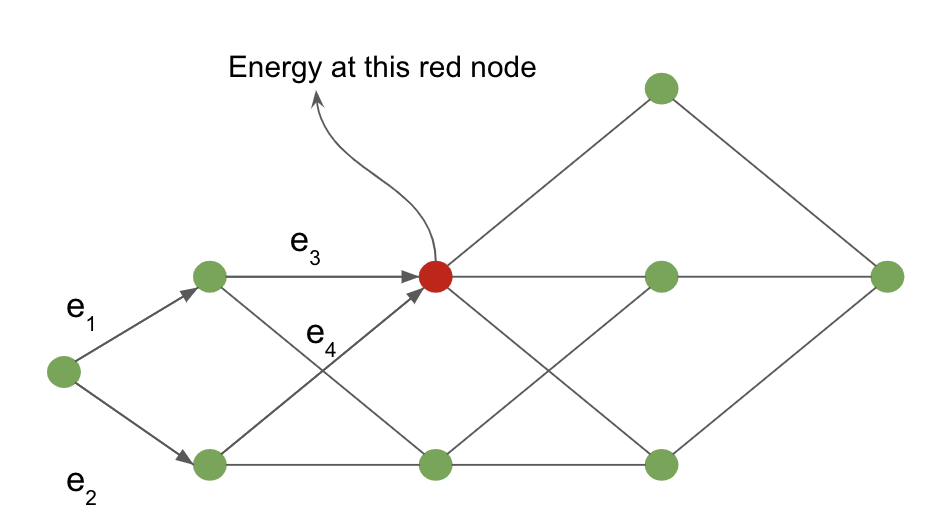
그림 4: 해석 그래프
입력 노드에서 빨간색으로 표시된 노드까지의 비용은 빨간 노드에 도달 할 수 있는 모든 경로에 대한 마지널라이징marginaliising를 통해 계산된다. 빨간 노드로 들어가는 화살표는 이 예시 안에서 가능한 경로들을 나타낸다.
빨간색 노드의 경우 이 노드에서의 에너지 값은 다음과 같다.
\[-\frac{1}{\beta} \; \log \; [ \, \exp \, (- \, \beta (e_1 \, + \, e_3)) \; + \; \exp \, (- \, \beta (e_2 \, + \, e_4)) \, ]\]순방향 알고리즘과 신경망 사이의 유사성
순방향 알고리즘은 기본 그래프가 체인 그래프chain graph인 경우 신념 전파belief-propagation 알고리즘의 특수한 케이스이다. 이 전체 알고리즘은 각 노드의 함수가 Log-Sum-Exponential와 덧셈 항인 피드포워드feed-forward 신경망으로 볼 수 있다.
해석 그래프의 각 노드에 대해 $\alpha$ 변수를 유지한다.
\[\alpha_{i} = - \; \log \; \biggl[ \sum_{k \, \in \, \text{parent} \, (i)} \; \exp \, (- \, \beta \; (\alpha_k \, + \, e_{ki})) \biggl]\]여기서 $e_{ki}$ 는 노드 $k$에서 노드 $i$로의 연결 에너지이다.
$\alpha_i$는 이 신경망에서 노드 $i$의 활성화activation을 형성하고 $e_{ki}$는 노드 $k$ 와 노드 $i$ 사이의 가중치이다. 이 공식은 로그 도메인에서 정규 신경망의 가중치 합 연산과 대수적으로algebraically 동일하다.
순방향 알고리즘을 적용한 동적 해석 그래프를 통해 역전파 할 수 있다(왜냐하면 예시에서 예시로 변경되기 때문since it changes from example to example이다). 해석 그래프의 에지를 정의하는 $e_{ki}$ 가중치를 고려한 그래프의 마지막 노드에서 계산된 $F(x, y)$의 그래디언트를 얻을 수 있다.
그림 5: 수표 판독기
수표 판독기의 예제로 돌아가서, 두 그래프 구성에 순방향 알고리즘을 적용하고, Log-Sum-Exponential 공식을 이용해서 마지막 노드의 에너지 값을 얻는다. 이 에너지 값들의 차이는 음의 로그 우도 손실이다.
정답과 인식 그래프 사이의 그래프 구성에 순방향 알고리즘을 적용해 얻은 값은 정답의 Log-Sum-Exponential 값이다. 반대로 인식 그래프와 문법 사이의 그래프 구성의 최종 노드에서의 Log-Sum-Exponential 값은 가능한 모든 유효한 해석에서 밀려난(마지널라이즈 된) 값이다.
역전파의 라그랑지안 공식화Lagrangian formulation of Backpropagation
입력 $x$ 및 목표 출력 $y$의 경우, 네트워크의 연속 단계가 $z_k$ 와 $z_{k+1} = f_k(z_k, w_k)$ 를 출력하도록 네트워크를 함수 $f_k$ 와 가중치 $w_k$의 모음으로 공식화 할 수 있다. 지도 학습 환경에서, 네트워크의 목표는 실제 값과 관련된 네트워크의 출력 비용인 $C(z_n, y)$를 최소화 하는 것이다. 이는 제약 조건 $z_{k+1} = f_k(z_k, w_k)$ 와 $z_0 = x$ 아래에서 $C(z_n, y)$ 를 최소화 하는 문제와 동일하다.
라그랑지안은 다음과 같이 쓸 수 있다. \(\mathcal{L}(x, y, \lambda_i, z_i, w_i) = C(z_n, y) + \sum\limits_{k=0}^{n-1} \lambda^T_{k+1}(z_{k+1} - f_k(z_k, w_k))\) $ \lambda $ 항은 라그랑지안 승수multiplier를 나타낸다(만약 미적분 3 을 접한지 오래됐다면, 다음을 참고할 수 있다. Paul’s online notes.
$\mathcal{L}$ 를 최소화 하려면, 각 인수에 대해 $\mathcal{L}$의 편미분 값을 0으로 두고 풀어야 한다.
- $\lambda$ 의 경우 간단하게 제약 조건을 복구한다: $\frac{\partial{\mathcal{L}}}{\partial \lambda_{k+1}} = 0 \rightarrow z_{k+1} = f_k(z_k, w_k)$.
- $z_k$ 의 경우, $\frac{\partial \mathcal{L}}{\partial z_k} = 0 \rightarrow \lambda^T_k - \lambda^T_{k+1} \frac{\partial f_k(z_k, w)}{\partial z_k} \rightarrow \lambda_k = \frac{\partial f_k(z_k, w_k)^T}{\partial z_k}\lambda_{k+1}$, 이는 표준적인 역전파 공식이다.
이 접근 방식은 최소화가 시스템의 에너지에 대한 것이고 $\lambda$ 항은 물리적 제약을 나타내는 고전 역학Classical Mechanics의 맥락에서 라그랑지Lagrange 그리고 해밀톤Hamilton으로부터 시작됐다. 예를 들어, 두 개의 공이 금속 막대에 부착된 덕에 서로 고정 된 거리를 유지하도록 강제하는 것과 같다.
매번 $k$ 단계에서 비용 $C$ 를 최소화 해야 하는 상황에서 라그랑지안은 다음과 같이 표현된다. \(\mathcal{L} = \sum_k \left(C_k(z_k, y_k) + \lambda^T_{k+1}(z_{k+1} - f_k(z_k, w_k)) \right)\).
뉴럴 상미분방정식Neural Ordinary Differential Equation
역전파에 관한 이 공식을 사용해서 이제 새로운 모델인 뉴럴 상미분방정식Neural ODEs에 대해 이야기 할 수 있다. 이들은 기본적으로 $t$ 시점의 상태 $z$ 가 $ z_{t+\text{d}t} = z_t + f(z_t, W) dt $ 로 주어지는 순환신경망이고, 여기에서 $ W$ 는 일부 고정 매개 변수 집합을 나타낸다. 이는 또한 상미분방정식(편미분 없음)으로 표현될 수 있다: $\frac{\text{d}z}{\text{d}t} = f(z_t, W)$.
라그랑지안 공식을 사용해서 이러한 네트워크를 훈련시키는 것은 매우 간단하다. 목표 $y$가 있고, 시스템이 시점 $T$ 에서 $y$ 의 상태에 도달하기를 원한다면, 간단하게 비용 함수를 $z_T$ 와 $y$ 사이의 거리 함수로 설정한다. 이 네트워크의 또 다른 목표는 시스템의 안정적인 상태, 다른 말로 표현하자면, 특정 시점 이후 더 이상 변화가 일어나지 않는 상태를 찾는 것이다. 이것은 수학적으로 $\frac{\text{d}z}{\text{d}t} = f(y, W) = 0$ 와 같이 설정하는 것과 같다. 일반적으로 이 방정식에 대한 해답인 $y$ 를 찾는 것이 시간을 통한 역전파보다 훨씬 쉬운데, 왜냐하면 네트워크가 전체 시퀀스에 대한 그래디언트를 기억할 필요가 없고 $f$ 또는 $\lvert f \rvert^2$ 만 최소화 하면 되기 때문이다. 뉴럴 상미분방정식을 고정된 점에 도달시키기 위해 훈련하는 것에 관련해 더 자세한 장보는 (르쿤88) 을 참조하면 된다.
에너지 측면에서의 변이variational 추론
소개
기본 에너지 함수 $E(x,y,z)$ 의 경우, 변수 z 에 대해 마지널라이즈marginalize하여 $x$ 와 $y$, $L(x,y)$ 만으로 손실을 얻기 위해서는 다음을 계산해야만 한다.
\[L(x,y) = -\frac{1}{\beta}\int_z \exp(-\beta E(x,y,z))\]그 다음 $\frac{q(z)}{q(z)}$ 을 곱하면, 다음을 얻는다. \(L(x,y) = -\frac{1}{\beta}\int_z q(z) \frac{\exp({-\beta E(x,y,z)})}{q(z)}\)
$q(z)$ 가 $z$ 에 대한 확률 분포라고 가정하면, 재작성된 손실 함수 적분을 $\frac{\exp({-\beta E(x,y,z)})}{q(z)}$ 의 분포와 관련해 평균(기댓값)expected value으로 해석할 수 있다.
이 해석과, 옌센 부등식Jensen’s Inequality, 그리고 샘플링 기반 근사approximations을 이용해서 손실 함수를 간접적으로 최적화 한다.
옌센 부등식Jensen’s Inequality
옌센 부등식은 다음과 같은 기하학적 관찰이다. 만일 볼록 함수가 있으면, 해당 함수의 치역range 위 기댓값(평균)은 치역의 처음과 끝에서 측정한 함수값의 평균보다 작다. 기하학적으로 표현되는 이 내용은 매우 직관적이다.
그림 6: 옌센 부등식 (출처 [위키피디아](https://en.wikipedia.org/wiki/Jensen%27s_inequality))
마찬가지로, $F$ 가 볼록하면, 고정된 확률 분포 $q$에 대해 옌센 부등식으로부터 $z$ 범위에 대해 다음과 같이 추론할 수 있다.
\[F\Bigg(\int_z q(z)h(z)\Bigg) \leq \int_z q(z)F(h(z)) \tag{1}\]이제 $\frac{q(z)}{q(z)}$ 을 곱하여 마지널라이즈marginalized 된 $L(x,y)$ 는 다음과 같다. \(L(x,y) = -\frac{1}{\beta}\int_z q(z) \frac{\exp({-\beta E(x,y,z)})}{q(z)}\)
만약 $h(z) = -\frac{1}{\beta} \frac{\exp({-\beta E(x,y,z)})}{q(z)}$ 을 만들면, 옌센 부등식 $(1)$ 로부터 다음을 알게 된다.
\[F\Bigg(\int_z q(z)\frac{\exp({-\beta E(x,y,z)})}{q(z)}\Bigg) \leq \int_z q(z)F\Bigg(\frac{\exp({-\beta E(x,y,z)})}{q(z)}\Bigg)\]이제 명확하게 볼록 함수인 $F(x) = -\log(x)$ 를 가지고 이 작업을 계속해 보자.
\[-\log\Bigg(-\frac{1}{\beta}\int_z q(z)\frac{\exp({-\beta E(x,y,z)})}{q(z)}\Bigg) \leq \int_z q(z) * \frac{-1}{\beta}\log\Bigg(\frac{\exp({-\beta E(x,y,z)})}{q(z)}\Bigg)\] \[\leq \int_z q(z)[E(x,y,z) + \frac{1}{\beta}\log(q(z))]\] \[\leq \int_z q(z)E(x,y,z) + \frac{1}{\beta}\int_z q(z)\log(q(z))\]자, 이제 우리가 이해하는 두 항으로 구성된 손실 함수 $L(x,y)$ 의 상한을 알게됐다. 첫 번째 항 $\int_z q(z)E(x,y,z)$ 은 평균 에너지이다. 그리고 두 번째 항 $\frac{1}{\beta}\int_z\log(q(z))$ 은 어떤 요인 ($-\frac{1}{\beta}$) 곱하기 분포 $q$ 의 엔트로피 이다.
그래서 요점이 무엇인가?
이제 복잡한 적분 대신에 우리가 선택한 대리 분포surrogate distribution ($q(z)$) 에서 샘플링하여 이 값들을 근사하는 방식으로 상한을 공식화 했다.
상한 함수의 첫 번째 항 값을 구하기 위해서 해당 분포에서 샘플링하고 샘플링된 $z$ 를 적용해서 얻은 $L$ 의 평균을 계산한다.
두 번째 항 (엔트로피 인자factor)는 분포 모임distribution family의 속성일 뿐이고, 마찬가지로 $q$ 에서의 랜덤 샘플링을 근사할 수 있다.
마지막으로, 위의 $L$을 제한하는 이 함수를 최소화 함으로써 매개 변수 (예를 들어, 네트워크 $W$ 의 가중치)를 고려한 $L$ 를 최소화 할 수 있다. 이 최소화는 다음의 두 변수를 업데이트함으로써 수행할 수 있다: (1) $q$ 의 엔트로피, 그리고 (2) 모델 매개변수 $W$.
요약
이것이 변이 추론의 “에너지 관점”이다. Log-Sum-Exponential 을 계산해야 할 경우 함수의 평균에 엔트로피 항을 더한 값으로 대체하면 된다. 그 다음 이 상한을 최소화하고, 이렇게 함으로써 우리가 실제로 중요시하는 함수를 최소화 한다.
📝 Yada Pruksachatkun, Ananya Harsh Jha, Joseph Morag, Dan Jefferys-White, and Brian Kelly
Yujin
4 May 2020