손실 함수(cont.)와 에너지 기반 모델을 위한 손실 함수
🎙️ Yann LeCun이진 교차 엔트로피 손실Binary Cross Entropy - nn.BCELoss()
\[\ell(x,y) = L = \{l_1,...,l_N\}^T, \qquad l_n = -w_n[y_n\log x_n+(1-y_n)\log(1-x_n)]\]
이 손실은 오직 두 개의 클래스를 가지고 있어서 더 단순한 함수로 줄어들 수 있을 때를 위한 교차 엔트로피의 특별한 경우이다. 예를 들어, 이것은 오토 인코더 안에서 재구축 오류 측정을 위해 사용된다. 이 공식은 $x$와 $y$가 확률에 관한 것이며 오로지 0과 1 사이의 값이라고 가정한다.
Kullback-Leibler 발산 손실 - nn.KLDivLoss()
\[\ell(x,y) = L = \{l_1,...,l_N\}^T, \qquad l_n = y_n(\log y_n-x_n)\]
이것은 원-핫 분포(참고로 $y$는 카테고리이다.)가 목표값일 때에 대한 단순 손실 함수이다. $x$와 $y$가 확률이라는 것을 다시 가정한다. 소프트맥스 혹은 로그-소프트맥스와 합쳐지지 않아서 수치 안정성 문제를 가질 수 있다는 약점이 있다.
로짓을 동반한 이진 교차 엔트로피 손실 - nn.BCEWithLogitsLoss()
\[\ell(x,y) = L = \{l_1,...,l_N\}^T, \qquad l_n = -w_n[y_n\log \sigma(x_n)+(1-y_n)\log(1-\sigma(x_n))]\]
이번 이진 교차 엔트로피 버전은 비록 소프트맥스를 거쳐가지 않았더라도 점수를 취하므로 x는 0과 1 사이라고 가정하지 않는다. 그러면 그 범위 안에 있다는 것을 확실하기 위한 시그모이드를 통과하였더라도 지나가는 것이다. 이 경우처럼 결합될 때, 손실 함수는 수치상 더 안정적인 것처럼 보인다.
마진 순위 손실 - nn.MarginRankingLoss()
\[L(x,y) = \max(0, -y*(x_1-x_2)+\text{margin})\]
마진 손실은 손실의 중요한 카테고리이다. 만약 두 개의 입력값을 가지고 있다면, 이 손실 함수는 하나의 입력값이 최소한 다른 하나보다 더 커지길 원한다고 말할 것이다. 이런 경우 $y$는 $\in { -1, 1}$의 이진 변수이다. 두 개의 입력값이 두 카테고리의 점수라고 상상해보라. 최소한 약간의 마진으로 부정확한 카테고리 점수보다 정확한 카테고리 점수가 더 크길 원할 것이다. 힌지 손실처럼 만약 $y*(x_1-x_2)$가 마진보다 더 크다면, 비용은 0이다. 만약 더 작다면, 비용은 선형적으로 증가할 것이다. 이것을 분류에 쓰고자 했다면, $x_1$을 정답 점수로 만들고 $x_2$는 미니 배치에서 가장 높은 점수의 오답 점수로 만들었을 것이다. 만약 에너지 기반 모델에서 쓰인다면(추후 논의), 이 손실 함수는 정답을 $x_1$로 밀어내리고 오답은 $x_2$로 밀어올린다.
삼중 마진 손실 - nn.TripletMarginLoss()
\[L(a,p,n) = \max\{d(a_i,p_i)-d(a_i,n_i)+\text{margin}, 0\}\]
이 손실은 표본 사이의 상대적인 유사성을 측정하기 위하여 사용된다. 예를 들어, 두 이미지를 합성곱 신경망을 통해 같은 카테고리로 넣고 두 개의 벡터를 얻는다. 이 때, 두 벡터 사이의 거리가 가능한 작아지길 원한다. 만약 두 이미지를 합성곱 신경망을 통해 다른 카테고리로 넣는다면, 이 벡터 사이의 거리가 가능한 최대한 커지길 바라게 된다. 이 손실 함수는 첫번째 거리값을 0으로 보내려고 하고 두 번째 거리값을 약간의 이윤보다 더 크게 보내려고 한다. 그러나 중요한 사실은 좋은 쌍 사이의 거리는 나쁜 쌍 사이 거리보다 작다는 것이다.
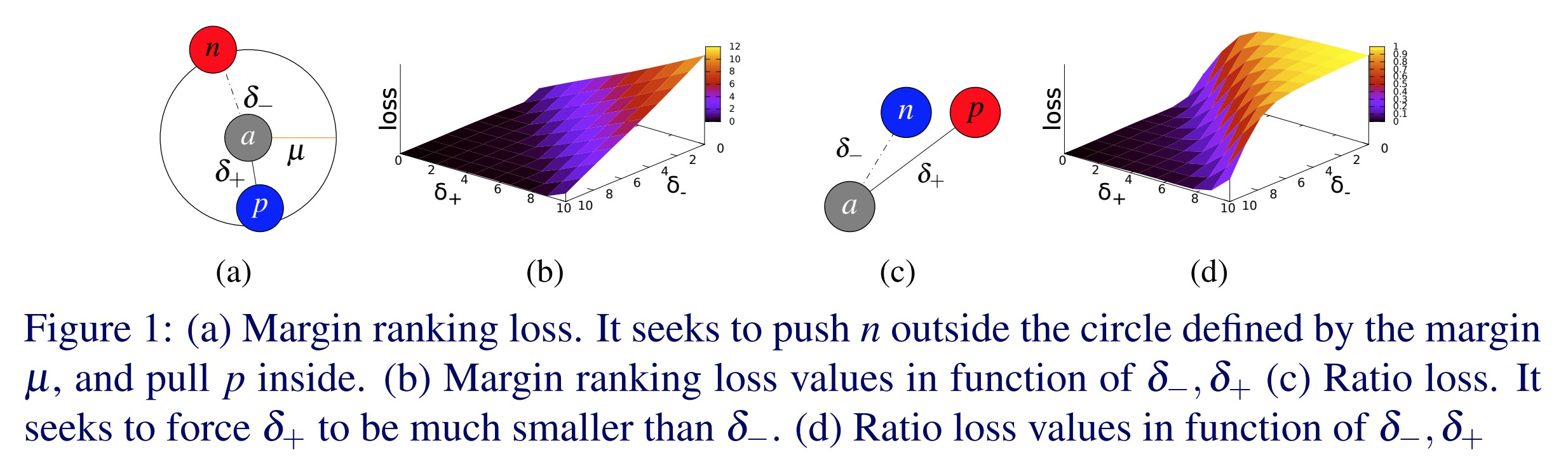
그림. 1: 삼중 마진 손실
이것은 원래 구글 이미지 검색 시스템을 학습시키고자 사용되었다. 당시에는 쿼리값을 구글에 삽입하고 그 쿼리값을 벡터에 넣어 인코드했을 것이다. 그런 다음 그 벡터와 이전에 인덱스되었던 이미지에서 오는 벡터 묶음과 비교했을 것이다. 구글은 그 다음 여러분의 벡터와 가장 가까웠던 이미지를 검색했을 것이다.
소프트 마진 손실 - nn.SoftMarginLoss()
\[L(x,y) = \sum_i\frac{\log(1+\exp(-y[i]*x[i]))}{x.\text{nelement()}}\]
위 수식은 입력 텐서 $x$와 (1 혹은 -1을 포함한) 목표 텐서 $y$ 사이의 2-클래스 분류 로지스틱 손실을 최적화하는 기준을 만든다.
이번 마진 손실의 소프트맥스 버전. 여러분은 소프트맥스를 통해 지나가길 바라는 양의 혹은 음의 묶음을 가지고 있다. 그러면 이 손실 함수는 그 어떤 것보다 더 작은 정답 $x[i]$에 대한 $\text{exp}(-y[i]*x[i])$를 만들려고 한다.
이 손실 함수는 $y[i]*x[i]$의 양의 값을 더 가까이 끌어당기고 음의 값을 멀리 밀어내지만 하드한 마진과 반대로, 연속적이고 기하급수적인 감소가 발생한다.
멀티-클래스 힌지 손실 - nn.MultiLabelMarginLoss()
\[L(x,y)=\sum_{ij}\frac{max(0,1-(x[y[j]]-x[i]))}{x.\text{size}(0)}\]
이 마진 기반 손실은 다른 입력값들에 대하여 목표값의 변수값을 갖도록 허용한다. 이 경우 높은 점수를 원하는 것에 대한 약간의 카테고리를 가지고 모든 카테고리에 걸친 힌지 손실을 더하게 된다. 에너지 기반 모델EBMs에 대하여 이 손실 함수는 원하는 카테고리로 밀어내리고 원하지 않는 카테고리를 끌어 올린다.
힌지 임베딩 손실 - nn.HingeEmbeddingLoss()
\[l_n =
\left\{
\begin{array}{lr}
x_n, &\quad y_n=1, \\
\max\{0,\Delta-x_n\}, &\quad y_n=-1 \\
\end{array}
\right.\]
두 입력값의 유사여부 측정에 의한 준지도학습을 위하여 쓰이는 힌지 임베딩 손실. 유사한 것들은 끌어당기고 그렇지 않은 것들은 밀어버린다. $y$ 변수는 점수쌍이 명확한 방향으로 가야하는지 여부를 나타낸다. 힌지 손실을 사용하면, $y$가 1이면 점수는 양의 값이고, 만약 $y$가 -1이라면 약간의 마진 $\Delta$이다.
코사인 임베딩 손실 - nn.CosineEmbeddingLoss()
\[l_n =
\left\{
\begin{array}{lr}
1-\cos(x_1,x_2), & \quad y=1, \\
\max(0,\cos(x_1,x_2)-\text{margin}), & \quad y=-1
\end{array}
\right.\]
이 손실은 코사인 거리를 사용한 두 입력값의 유사여부 측정을 위하여 쓰이며, 또한 전형적으로 비선형 임베딩 학습이나 준지도학습을 위하여 사용된다.
다른 관점에서, 1에서 두 벡터 사이의 코사인 각도를 뺀 값은 기본적으로 정규화된 유클리드 거리값이다.
이것의 이점은 두 벡터를 가지고 그 거리를 최대한 멀리 만들고 싶을 때마다 신경망이 벡터들을 매우 길게 만듦으로써 이것을 쉽게 얻을 수 있도록 한다는 것이다. 물론 이것이 최적의 방식은 아니다. 시스템이 벡터를 키우지 않도록 하고 싶지만 옳은 방향으로 벡터를 회전시킴으로써 그것을 정규화하고 그 정규화된 유클리드 거리를 계산하도록 한다.
긍정적인 경우, 이 손실은 벡터들을 가능한 나란히 만들고자 한다. 부정적 측면은 이 손실이 코사인 값을 특정 마진보다 더 작게 만들려고 한다는 것이다. 여기서 마진은 작은 양수일 것이다.
고차원 공간에서는 구의 적도에 가까운 많은 부분이 있다. 정규화 이후, 이제 모든 포인트는 그 구 위에서 정규화가 이루어진다. 여러분이 원하는 것은 의미상 여러분과 가까워지고자 하는 표본이다. 유사하지 않은 표본들은 직교일 것이다. 이 벡터들이 서로 반대가 되지 않기를 원하는데 왜냐하면 반대 극에 오직 한 지점만 있기 때문이다. 오히려 적도 위에 매우 큰 공간이 있고 따라서 마진을 작은 양의 값으로 만들어 이 모든 부분을 활용할 수 있다.
연결주의 시간 분류Connectionist Temporal Classification(CTC) 손실 - nn.CTCLoss()
연속적인 (구분되지 않은) 시계열과 목표 순서 사이의 손실을 계산한다.
연결주의 시간 분류CTC 손실은 목표에 대한 입력값의 정렬 가능성을 합쳐서 각 입력 노드에 대하여 미분할 수 있는 손실 값을 만들어낸다.
목표에 대한 입력값 정렬은 입력값 길이보다 작거나 같은 것처럼 목표 순서의 길이를 제한하는 “다대일many-to-one“인 것으로 가정한다.
출력값이 카테고리 점수에 대응하는 벡터 순서일 때 유용하다.

그림. 2: 음성 인식을 위한 연결주의 시간 분류CTC 손실
응용 예제: 음성 인식 시스템
목표: 10ms마다 발음하는 단어 예측하기
각 단어는 소리 순서에 의해 표현된다.
사람마다 말하는 속도가 다르기 때문에, 다른 길이를 가진 소리가 같은 단어와 연결될 수도 있다.
- Find the best mapping from the input sequence to the output sequence. A good method for this is using dynamic programming to find the minimum cost path.
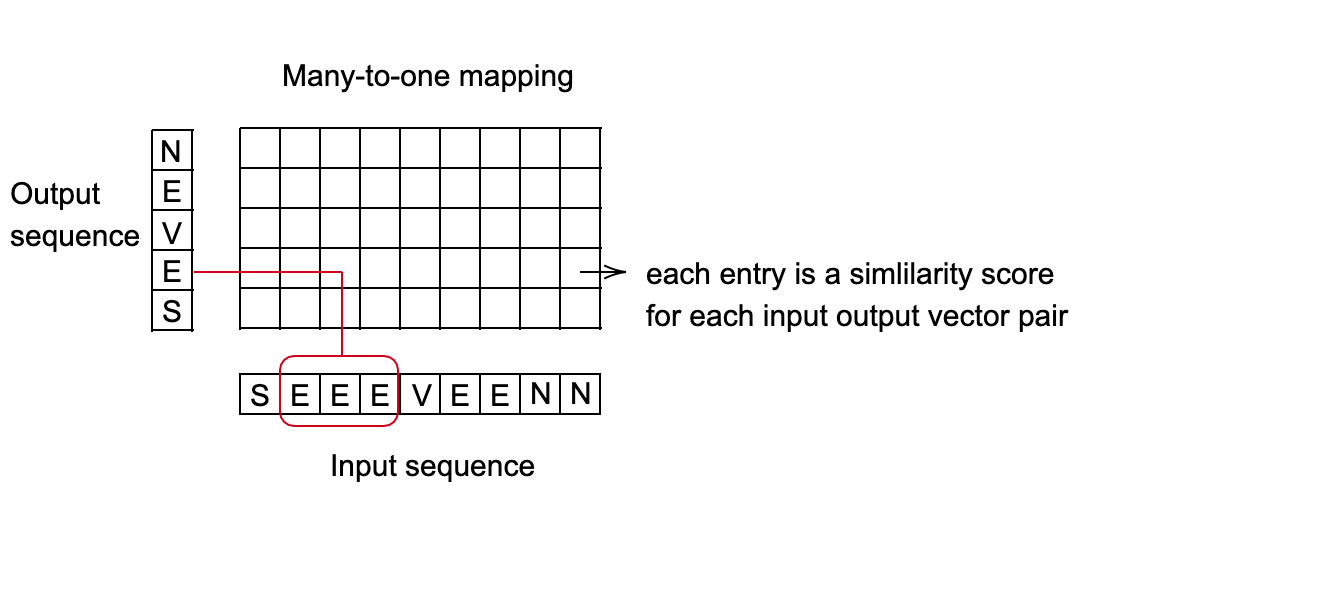
그림. 3: 다대일 연결 설정
에너지 기반 모델 (파트 4) - 손실 함수
아키텍처 그리고 손실 함수
에너지 함수 군: $\mathcal{E} = {E(W,Y, X) : W \in \mathcal{W}}$.
학습 세트: $S = {(X^i, Y^i): i = 1 \cdots P}$
손실 함수: $\mathcal{L} (E, S)$
함수는 또 다른 함수의 함수를 의미한다. 여기서는, 함수 $\mathcal{L} (E, S)$는 에너지 함수 $E$의 함수이다.
왜냐하면 $E$는 $W$에 의해 매개 변수가 되었기 때문에 우리는 이 함수를 $W$: $\mathcal{L} (W, S)$의 손실 함수로 바꿀 수 있다.
학습 세트에서 에너지 함수 질적 수치
순열에서의 불변과 표본의 반복
학습: $W^* = \min_{W\in \mathcal{W}} \mathcal{L}(W, S)$
손실 함수 형태:
- $L(Y^i, E(W, \mathcal{Y}, X^i))$는 표본당 손실이다.
- $Y^i$가 원하는 답이며, 카테고리 혹은 전체 이미지 등이 될 수 있다.
- $E(W, \mathcal{Y}, X^i)$는 $Y$가 변하면서 주어진 $X_i$에 대한 에너지 표면이다.
- $R(W)$는 정규화도구이다.
좋은 손실 함수 설계
정답 에너지에서 밀어내릴 것.
특히 정답보다 작은 경우, 오답 에너지에서 밀어 올릴 것.
손실 함수 예제
에너지 손실
\[L_{energy} (Y^i, E(W, \mathcal{Y}, X^i)) = E(W, Y^i, X^i)\]이 손실함수는 단순히 정답 에너지에서 밀어 내린다. 만약 신경망이 정상적으로 설계되지 않는다면, 정답 에너지를 작게 만들려고 하면서도 다른 곳의 에너지를 밀어 올리지 않는 것으로써 대부분의 평평한 에너지로 끝날 수 있다. 따라서, 시스템이 무너질 수도 있다는 것이다.
음의 로그 우도 손실
\[L_{nll}(W, S) = \frac{1}{P} \sum_{i=1}^P (E(W, Y^i, X^i) + \frac{1}{\beta} \log \int_{y \in \mathcal{Y}} e^{\beta E(W, y, X^i)})\]이 손실 함수는 확률에 비례하여 모든 답의 에너지에서 밀어올리는 동안 정답 에너지를 밀어 내린다. 이것은 $\beta \rightarrow \infty$일 때, 퍼셉트론 손실로 줄어든다. 오랫동안 많은 커뮤니티에서 구조적인 출력값을 동반한 판별 학습을 위하여 사용되어 왔다.
확률적 모델은
에너지가 Y(예측 변수)에 통합될 수 있는
손실 함수가 음의 로그 우도인 곳에 있는 에너지 기반 모델EBM이다.
퍼셉트론 손실
\[L_{perceptron}(Y^i,E(W,\mathcal Y, X^*))=E(W,Y^i,X^i)-\min_{Y\in \mathcal Y} E(W,Y,X^i)\]60년도 더 된 퍼셉트론 손실과 매우 비슷하고, 항상 양의 값을 갖는데 $Y^i$이 최소값을 넘겨 받아서 $E(W,Y^i,X^i)-\min_{Y\in\mathcal Y} E(W,Y,X^i)\geq E(W,Y^i,X^i)-E(W,Y^i,X^i)=0$이기 때문이다. 동일한 계산 결과는 오직 $Y^i$가 정답일 때만 정확히 0을 부여한다는 것을 보여준다.
이 손실은 정답 에너지를 작게 만들고, 동시에 모든 다른 정답을 가능한 크게 만든다. 하지만 이 손실은 함수가 모든 오답 $Y^i$에 동일한 값을 주는 것을 방지하지 않아서, 이러한 측면에서 비선형 시스템에 대하여 나쁜 손실 함수이다. 이 손실을 개선하고자, 우리는 가장 문제가 되는 오답을 정의하기로 한다.
일반화된 마진 손실
가장 문제 되는 오답 : 이산 사건 $Y$를 이산 변수라 가정하자. 그러면 학습 표본 $(X^i,Y^i)$에 대하여 가장 문제 되는 오답 $\bar Y^i$은 모든 가능성 있는 오답 중 가장 낮은 에너지를 갖는 답이다.
\[\bar Y^i=\text{argmin}_{y\in \mathcal Y\text{ and }Y\neq Y^i} E(W, Y,X^i)\]가장 문제되는 오답: 연속 사건 $Y$를 연속 변수라 하자. 그러면 학습 표본 $(X^i,Y^i)$에 대하여, 가장 문제되는 오답 $\bar Y^i$는 정답으로부터 최소한 $\epsilon$ 만큼 떨어진 모든 답들 중 가장 낮은 에너지를 갖는 답이다.
\[\bar Y^i=\text{argmin}_{Y\in \mathcal Y\text{ and }\|Y-Y^i\|>\epsilon} E(W,Y,X^i)\]이산 사건의 경우, 가장 문제가 되는 오답은 정답이 아닌 가장 작은 에너지를 갖는 것이다. 연속 사건에서는 극단적으로 $Y^i$와 가까운 $Y$에 대한 에너지가 $E(W,Y^i,X^i)$와 가까울 것이다. 게다가, $Y^i$와 같지 않은 $Y$를 초과하여 측정된 $\text{argmin}$은 0일 것이다. 결과적으로, 우리는 거리 $\epsilon$을 선택하고 오직 $Y_i$에서 $Y$의 $\epsilon$ 이상에 해당하는 부분만 “오답”으로 간주해야 한다. 이것은 최적화가 오직 $Y_i$에서 $Y$의 $\epsilon$ 이상인 부분에 대해서 이루어지는 이유이다.
만약 에너지 함수가 가장 문제되는 오답이 약간의 마진에 의한 정답 에너지보다 높다는 것을 보장할 수 있다면, 이 에너지 함수는 잘 작동할 것이다.
일반화된 마진 손실 함수 예제
힌지 손실
\[L_{\text{hinge}}(W,Y^i,X^i)=( m + E(W,Y^i,X^i) - E(W,\bar Y^i,X^i) )^+\]$\bar Y^i$가 가장 문제되는 오답인 부분이다. 이 손실은 정답과 가장 문제되는 오답 사이의 차이가 최소한 $m$이 되도록 한다.

그림. 4: 힌지 손실
Q: $m$을 어떻게 선택하는지?
A: 임의적이지만 마지막 층위의 가중치에 영향을 미친다.
로그 손실
\[L_{\log}(W,Y^i,X^i)=\log(1+e^{E(W,Y^i,X^i)-E(W,\bar Y^i,X^i)})\]이것은 “소프트” 힌지 손실로 여겨질 수 있다. 정답과 힌지를 가진 가장 문제되는 오답의 차이를 구성하는 대신, 이제 소프트 힌지로 이루어진다. 이 손실은 “무한한 마진”을 강화하려고 하지만, 기하급수적인 경사 소멸 때문에 일어나지 않는다.

그림. 5: 로그 손실
제곱-제곱 손실
\[L_{sq-sq}(W,Y^i,X^i)=E(W,Y^i,X^i)^2+(\max(0,m-E(W,\bar Y^i,X^i)))^2\]이 손실은 에너지 제곱과 제곱 힌지를 결합한다. 이 결합은 에너지를 최소화하려 하지만 가장 문제되는 오답에서의 최소 마진 $m$을 강화하려 한다. 이것은 샴 신경망에서 쓰이는 손실과 매우 비슷하다.
다른 손실들
다발들이 있다. 여기서는 좋고 나쁜 손실 함수에 대한 내용을 요약 정리하였다.
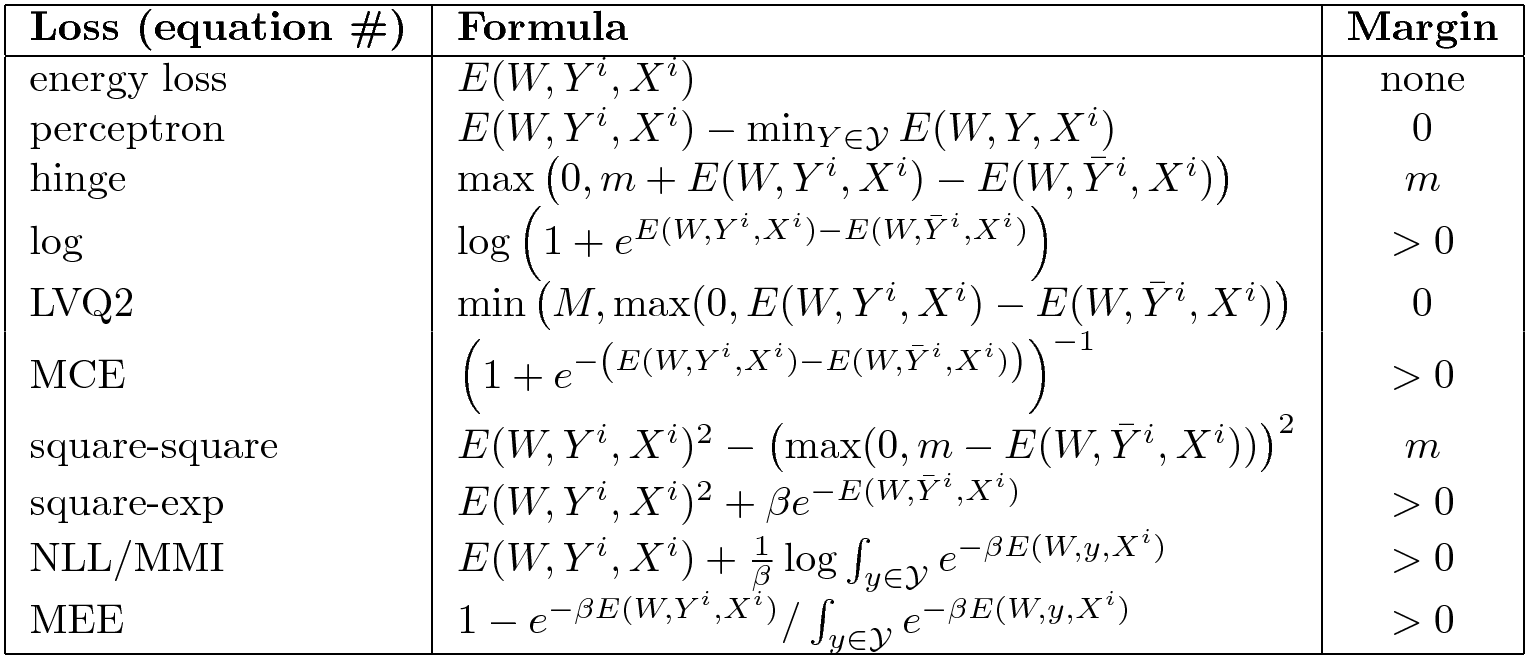
그림. 6: 에너지 기반 모델EBM 손실 함수의 선택
오른쪽 열은 에너지 함수가 마진을 강화할 것인지 여부를 가리킨다. 평범한 오래된 에너지는 아무데서나 밀어올리지 않으므로 마진을 갖지 않는다. 에너지 손실은 모든 문제에 대한 해결책이 되는 것은 아니다. 만약 에너지를 선형적인 매개변수로 만든다면 퍼셉트론 손실을 적용할 수 있지만 일반으로 그렇지 않다. 어떤 것은 힌지 손실과 같은 유한한 마진을 가지고, 또 어떤 것은 소프트 힌지와 같은 무한한 마진을 갖는다.
Q: 가장 문제되는 오답과 연속 사건에서 $\bar Y_i$를 어떻게 찾는지?
A: $Y^i$에서 충분히 멀리 떨어진 한 지점에서 밀어 올리고 싶을텐데, 아주 가까워서 매개변수가 많이 움직이지 않는다면 신경망에 의해 정의된 함수가 “빽빽한” 함수이기 때문이다. 그러나 일반적으로, 이것은 어려우며 대조 표본 선택 방법이 해결하려고 하는 문제이다. 그것을 하기 위한 옳은 수행 방법은 없다.
힌지 유형 대조 손실에 대한 약간 더 일반적인 형태는
\[L(W,X^i,Y^i)=\sum_y H(E(W, Y^i,X^i)-E(W,y,X^i)+C(Y^i,y))\]우리는 $Y$가 이산이지만, 만약 연속이라면 그 합은 적분으로 바뀔 것이라 가정한다. 여기서 $E(W, Y^i,X^i)-E(W,y,X^i)$는 정답과 어떤 다른 답에서 측정된 $E$의 차이이다. $C(Y^i,y)$는 마진이며 일반적으로 $Y^i$와 $y$ 사이의 거리값을 나타낸다. 동기는 우리가 잘못된 표본 $y$에서 밀어올리고 싶은 합이 $y$와 옳은 표본 $Y_i$ 사이 거리에 따라 달라져야 한다는 것이다. 이것은 최적화하는데 더 어려운 손실이 될 수 있는 것이다.
📝 Charles Brillo-Sonnino, Shizhan Gong, Natalie Frank, Yunan Hu
ChoongHee
13 April 2020