디코딩 언어 모델
🎙️ Mike Lewis빔 서치
빔 서치는 텍스트를 생성하고, 언어 모델을 디코딩하는 또 다른 테크닉이다. 모든 스텝마다, 알고리즘은 $k$개의 가장 가능성있는 (최선의) 부분 번역들(가설들hypotheses)을 꾸준히 추척track한다. 각 가설의 스코어는 그의 로그 확률log probability과 같다.
알고리즘은 최고 스코어를 기록한 가설을 선택한다.
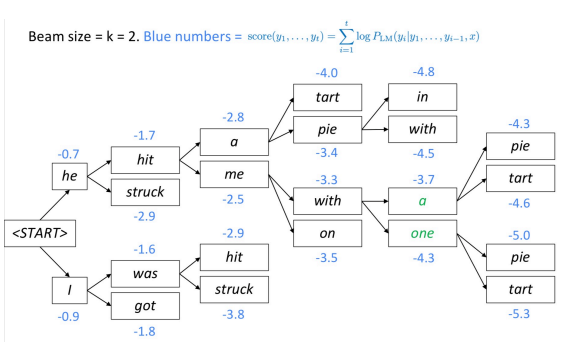
그림1: 빔 디코딩
빔 트리는 가지를 얼마나 깊게 뻗을 수 있을까?
빔 트리는 문장 토큰의 끝에 도달할때까지 이어진다. 문장의 마지막 토큰을 내놓으면, 가설도 종료된다.
어째서 매우 크기가 큰 빔 사이즈들은 (NMT에서) 자주 빈 번역 결과를 낼까?
트레이닝을 할 때, 알고리즘은 빔이 비싸기 때문에 자주 사용하지 않는다. 대신에 자동 회귀 분해auto-regressive factorization (이전의 올바른 결과물들을 받아, $n+1$ 첫번째 단어들을 예측한다.)를 사용한다. 트레이닝 중에는 모델의 실수가 드러나지 않기에, 빔에서 “무의미한 말”을 내놓을 가능성이 있는 것이다.
요약: 모든 $k$ 가설들이 마지막 토큰을 생산할 때까지 또는 최대 디코딩 한계 T에 도달할 때까지 빔 서치를 계속해라.
샘플링
어쩌면 가장 가능성이 높은 순서를 원하지 않을 수도 있다. 대신, 모델의 분포로부터 샘플링을 할 수 있다.
하지만, 모델의 분포로부터 샘플링을 하는 것은 이 방식 자체의 문제를 드러낸다. 한 번 “나쁜” 선택이 샘플링되었을 때, 모델은 트레이닝 동안 절대 마주친 적이 없는 상태에 있고, 연속적으로 “나쁜” 평가의 우도likelihood를 증가시킨다. 따라서 알고리즘은 끔찍한 피드백 루프에 갇힐 수 있다.
톱-K 샘플링
샘플링 기술 자체는 분포를 앞 뒤로 잘라서 최상의 $k$개를 뽑고, 다시 정규화를 하고 그 분포로부터 샘플링을 하는 것이다.
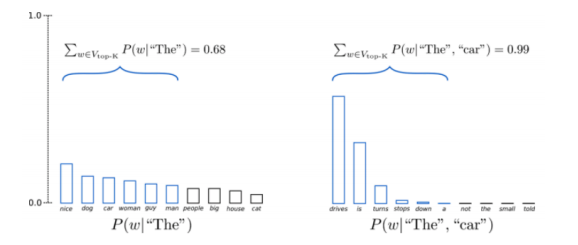
그림2: 톱-K 샘플링
질문 : 왜 톱-K 샘플링은 잘 되는 것일까?
이 테크닉이 잘 되는 이유는 본질적으로 꼬리를 잘라낸 분포의 머리 부분만 사용하기에, 뭔가 안 좋은 것이 샘플링 되려고 할 때, 즉, 좋은 언어의 매니폴드manifold에서 떨어지는 일을 막으려 노력하기 때문이다.
텍스트 생성 평가하기
언어 모델을 평가하는 건 간단하게 갖고 있는 데이터의 로그 우도log likelihood만 요구한다. 하지만 텍스트를 평가하는 일은 어렵다. 보편적인 단어 오버랩 메트릭들word overlap metrics은 레퍼런스(BLEU, ROUGE etc.)와 함께 쓰이지만, 각자가 가진 문제도 있어서다.
시퀀스-투-시퀀스 모델
조건부 언어 모델Conditional Language Models
조건부 언어 모델들은 영어로부터 무작위한 샘플을 생성해내는데에는 유용하지가 못하다. 하지만 주어진 입력값에 대한 텍스트를 생성해내는데에는 유용하다.
예시들:
- 불어 문장이 주어졌을 때, 번역된 영어 문장 생성하기
- 문서가 주어졌을 때, 요약본 생성하기
- 대화가 주어졌을 때, 다음번 응답을 생성하기
- 질문이 주어졌을 때, 답변을 생성하기
시퀀스-투-시퀀스 모델
일반적으로 텍스트는 인코딩되서 입력된다. 이 임베딩 결과는 “생각하는 벡터”로 알려져 있다, 이는 단어별 토큰들을 생성해내기 위해 디코더로 전해진다.
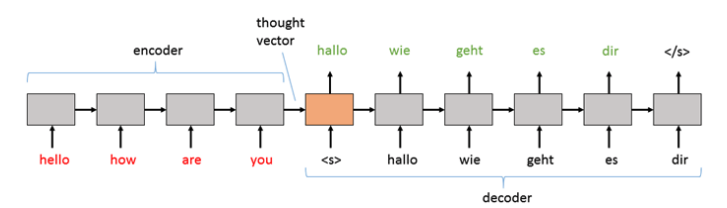
그림3: 생각하는 벡터
시퀀스-투-시퀀스 트랜스포머
시퀀스-투-시퀀스 변형 버전의 트랜스포머는 2개의 스택을 갖고 있다:
-
인코더 스택 - 셀프-어텐션은 마스크를 하지 않기에, 입력값의 모든 토큰은 입력값의 다른 모든 토큰들을 볼 수 있다.
-
디코더 스택 - 그 자신에 대한 어텐션을 쓰는 것과는 별개로, 전체 입력값들에 대한 어텐션을 또 사용한다.
그림4: 시퀀스-투-시퀀스 트랜스포머
결과값에 있는 모든 토큰은, 거기에 있는 모든 이전 토큰들과 또 입력값의 모든 단어들과도 직접적으로 연결되어 있다. 이 연결들이 모델을 매우 강력하게 또 표현력있게 만든다. 트랜스포머들은 이전의 순환 모델과 합성곱 모델을 넘어, 번역 점수에서 향상을 이루어냈다.
역-번역
이 모델들을 트레이닝할 때, 우리는 보통 많은 양의 라벨링된 텍스트에 의존한다. 데이터의 좋은 소스는 유럽 의회의 절차European Parliament proceedings이다 - 텍스트는 서로 다른 언어들로 수동으로 번역되어, 모델의 입력값과 출력값으로 사용할 수 있다.
이슈들
-
모든 언어들이 유럽 의회에 나타나는 것이 아니다, 이는 우리가 관심있어하는 모든 언어들의 번역 페어translation pair를 얻지 못할 수도 있다는 것이다. 굳이 데이터를 얻으려고 (노력)할 필요없이, 어떻게 트레이닝을 위한 언어 텍스트를 찾을 수 있을까?
-
트랜스포머같은 모델들은 더 많은 데이터가 있을 때 더 좋은 성능을 내는데, 우리는 어떻게 단일 언어 텍스트(댜른말로, 입력값이나 출력값이 없는 페어들)를 효율적으로 사용할 수 있을까?
우리가 독일어에서 영어로 번역하는 모델을 트레이닝시키고 싶다고 가정해보자. 역-번역back-translation의 아이디어는 영어에서 독일어로 가는 역 모델을 처음 트레이닝하는 점에 있다.
- 어떤 제한된 이중 언어-텍스트를 사용함으로써 우리는 2개의 다른 언어로 된 같은 문장을 얻을 수 있다.
- 한 번 영어-독일어 모델을 얻으면, 많은 단일 언어 단어들을 영어에서 독일어로 번역할 수 있다.
마지막으로, 이전 스텝에서 ‘역-번역’한 독일어를 사용해서 독일어에서 영어로 가는 모델을 트레이닝한다. 여기서 알아두어야 할 점은:
- 역 모델이 얼마냐 좋으냐와는 상관없다 - 엉망인 독일어 번역을 얻을수도 있지만, 결과적으로는 깨끗한 영어로 번역이 이루어진다.
- 영어/독일어 페어(이미 번역되어 있는)의 데이터를 넘어, 우리는 영어를 잘 이해하는 걸 배울 필요가 있다 - 많은 양의 영어 단일 언어 데이터를 사용해라
반복적인 역-번역
- 우리는 더 많은 이중 언어-텍스트 데이터를 생성하거나 더 좋은 성능에 도달하기 위해서 역-번역 절차를 반복할 수 있다 - 단일 언어 데이터를 사용해서 계속 트레이닝 해라.
- 많은 양의 병행 데이터를 쓸 수 없을 경우 큰 도움이 된다.
대량의 다중 언어 기계 번역
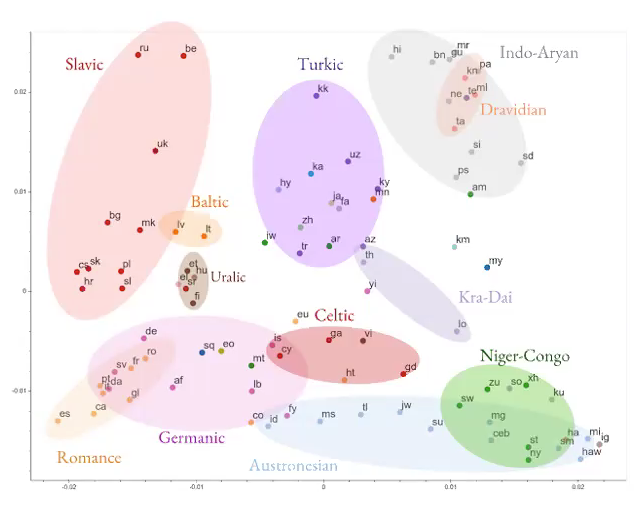
그림5: 다중 언어 기계 번역
- 하나의 언어에서 다른 언어로의 번역을 배우려고 노력하는 대신, 다양한 언어 번역을 배우도록 신경망을 구축하는데에 힘쓴다.
- 모델은 언어와는 독립되어 있는 일반적인 어떤 정보를 배운다.

그림6: 다중 언어 신경망 결과물
특히 쓸 수 있는 데이터가 많지 않은 언어를 번역하는 모델을 트레이닝 시키려고 할 때 끝내주는 결과를 낸다. (소스가 많지 않은 언어)
자연어 처리를 위한 비지도 학습
어떤 레이블labels도 없는 어마어마한 양의 텍스트가 있고, 적은 양의 지도 학습을 위한 데이터가 있다. 라벨링되지 않은 텍스트를 단순히 읽는 것만으로 우리는 언어에 대해서 얼마나 많은 것을 배울 수 있을까?
‘워드투벡터’
직관 - 텍스트에서 단어들이 근접해서 나타나면, 그들은 연결되어 있을 가능성이 높다, 그러므로 우리는 단순히 라벨링되지 않은 영어 텍스트를 읽는 것만으로 그들의 뜻을 배울 수 있기를 바란다.
- 목표는 단어들에 대한 벡터 공간 표현을 배우는 것이다.
사전학습 과제 - 몇몇 단어들을 마스크하고 (마스킹된) 공백을 채우기 위해 이웃하는 단어들을 사용해라.

그림7: 워드투벡터 마스킹 보이기
여기서, 한 예로, “horned”와 “silver-haired”의 아이디어는 다른 동물들에 비해, “unicorn”의 맥락에서 나올 가능성이 더 높다.
단어들을 선택하고, 선형 투영linear projection을 적용하자.
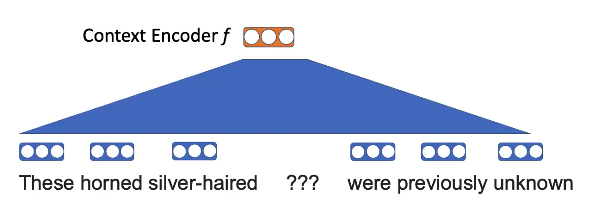
그림8: 워드투벡터 임베딩
알고자하는 것
\(p(\texttt{unicorn} \mid \texttt{These silver-haired ??? were previously unknown})\)
\[p(x_n \mid x_{-n}) = \text{softmax}(\text{E}f(x_{-n})))\]워드 임베딩은 어떤 구조를 갖고 있다.
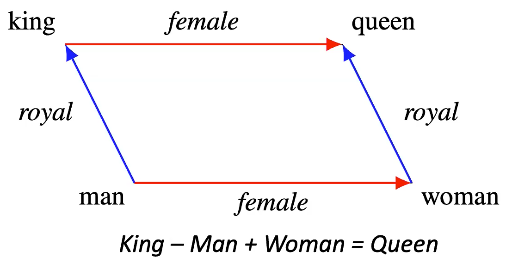
그림9: 임베딩 구조 예시
- 아이디어는 만약 트레이닝 이후에 “왕”에 대한 임베딩을 취하고, 거기에 “여성”이라는 임베딩을 더한다면, 우리는 “여왕”에 매우 가까운 임베딩을 얻을 수 있다는 것이다.
- 이는 벡터들 사이의 의미있는 어떤 차이를 보여준다.
질문: 단어의 표현은 맥락에 독립적인가 그렇지 못한가?
독립적이며 다른 단어들과 어떻게 연결되어 있는지에 대해서 알 수 없다.
질문: 이 모델이 어려움을 겪는 상황에 대한 예시가 있을까?
단어를 통역하는 일은 맥락에 크게 좌우된다. 그러므로 애매한 단어들에 대한 예시에서 - 단어는 여러가지 뜻을 가질 수 있으므로 - 임베딩 벡터들은 단어를 제대로 이해하기 위해 요구되는 맥락을 알 수 없으므로, 모델은 어려움을 겪을 것이다.
GPT
맥락을 더하기 위해, 조건부 언어 모델을 트레이닝할 수 있다. 이 언어 모델이 주어지면, 각 타임스텝마다 단어를 예측하고, 모델의 각 출력값을 다른 어떤 특징으로 대체한다.
- 사전 트레이닝 - 다음 단어 예측
- 파인 튜닝 - 세부 과제로 바뀐다. 예시들:
- 명사인지 형용사인지 예측
- 아마존 리뷰들로 구성된 어떤 텍스트를 주고, 리뷰에 대한 감성 점수를 예측한다
이 접근법은 좋은 건, 모델을 재사용할 수 있어서이다. 하나의 거대한 모델을 사전에 트레이닝하면, 다른 과제들을 위한 파인 튜닝이 가능하다.
ELMo
GPT는 왼쪽에 있는 맥락만을 고려했는데, 이후에 등장할 단어들에 대해서 의존하지 않는다는 의미다 - 이는 모델이 할 수 있는 일들을 꽤 제한했다.
여기 이 접근법은 두 개의 언어 모델들을 트레이닝하기 위한 것이다.
- 하나는 왼쪽에서 오른쪽으로 향한다.
- 하나는 오른쪽에서 왼쪽으로 향한다.
- 단어의 표현word representation을 얻기 위해, 두 모델의 결과물을 연결concatenate한다. 이제 우리는 우측으로부터의 맥락과 좌측으로부터의 맥락 모두에 의존한다.
이는 여전히 “얕은” 조합이고, 왼쪽과 오른쪽의 맥락 사이에서 좀 더 복잡한 어떤 상호 작용이 있었으면 좋겠다.
BERT
버트BERT는 이전에 한 공백-채우기 측면에서는, 워드투벡터와 비슷하다. 그러나 워드투벡터에서는 선형 투영을 했지만, 버트에는 더 많은 맥락을 볼 수 있는 거대한 트랜스포머가 있다. 트레이닝을 위해, 우리는 토큰 중 15%는 마스크 처리 할 것이고, 이 빈 부분들을 예측하려고 할 것이다.
확장가능한 버트, 로베르타RoBERTa:
- 사전-트레이닝 목표의 간략한 버트
- 커진 배치 사이즈
- 많은 양의 GPUs에서 트레이닝
- 더 많은 텍스트를 트레이닝
최고의 버트 퍼포먼스 결과에서도 더 큰 향상을 보임 - 현재 질문-답변 과제 퍼포먼스에 있어서는 인간 수준을 넘어섰다.
자연어처리를 위한 사전학습
자연어처리에서 연구되어온 다른 자가 지도self-supervised 사전 학습 접근법을 빠르게 보자.
-
XLNet:
독립적인 조건의 모든 마스크된 토큰들을 예측하는 대신, XLNet은 무작위 순서로 자동-회귀적으로auto-regressively 마스크된 토큰들을 예측한다.
-
SpanBERT
토큰 대신에 확장된 마스크(이어진 단어들의 시퀀스)를 사용
-
일렉트라ELECTRA:
단어들을 마스킹하기보다, 토큰들을 비슷한 것으로 대체한다. 그리고 토큰들이 대체될 수 있는지 아닌지를 예측하려고 애쓰는, 이진 분류 문제를 푼다.
-
알버트ALBERT:
경량화된 버트: 우리는 레이어들을 교차하는 가중치들을 묶는 것으로, 버트를 수정하고 더 가볍게 만들었다. 이는 모델의 파라미터 관련한 계산들을 줄인다. 재미있게도, 알버트의 저자들은 정확도에 대해서 크게 타협할 필요가 없었다.
-
XLM:
다중 언어 버트: 영어 텍스트 대신, 여러 언어로부터 온 텍스트를 넣었다. 예측한대로, 교차적인 언어 연결을 더 낫게 학습했다.
키key는 위에서 언급된 서로 다른 모델로부터 가져온다
-
서로 다른 많은 사전학습 목표들이 잘 된다!
-
단어들끼리 양방향으로 깊은 상호 작용을 하게 하는 건 모델에게 굉장히 중요하다
-
스케일을 키운 사전 학습으로부터 많은 것을 얻는다. 아직 확실한 제약사항은 없다.
위에서 논의된 대부분의 모델들은 텍스트 분류 문제를 풀도록 설계되었다. 하지만, 텍스트 생성 문제를 풀기 위해서는, 시퀀스-투-시퀀스 모델처럼 결과값을 연속적으로 생성해야하기에, 약간의 다른 접근법이 사전 학습에 필요하다.
조건부 생성을 위한 사전 학습: 바트BART와 T5
바트: 노이즈 제거 텍스트에 의한 사전 학습 시퀀스-투-시퀀스 모델
바트에서는, 사전학습을 위해 문장을 갖고 무작위로 토큰들을 마스킹해서 망가뜨린다. 마스킹된 토큰들을 예측하는 대신 (버트의 목표처럼), 망가진 전체 시퀀스를 넣고 올바른 전체 시퀀스를 예측하도록 노력한다.
이 시퀀스-투-시퀀스 사전학습 접근법은 커럽션 스킴corruption schemes을 디자인하는 측면에서 유연함을 제공한다. 문장을 섞거나, 구절을 없애거나, 새로운 구절을 소개하는 등의 일들을 할 수 있다.
바트는 GLUE와 SQUAD 과제에서 로베르타RoBERTa를 상대할 수 있었다. 그러나, 그건 요약, 대화와 추상화된 QA 데이터셋에서 새로운 SOTA였다. 이 결과들은 텍스트 생성에서 (바트가) 버트/로베르타보다 더 나아지도록 하려는, 동기부여를 강화한다.
자연어처리에서의 몇 가지 열린 질문들
- 세계 지식world knowledge을 어떻게 융합할 수 있을까
- 어떻게 긴 문서들을 모델링할 수 있을까? (버트-기반 모델들은 보편적으로 512개의 토큰을 사용한다)
- 어떻게 멀티태스크 학습을 가장 잘 수행할 수 있을까?
- 적은 데이터로 파인 튜닝을 하는게 가능할까?
- 이 모델들이 정말로 언어를 이해하고 있는 것일까?
요약
- 모델을 많은 데이터로 트레이닝하는 것이, 명백한 언어학적 구조의 모델링을 이긴다.
편향과 분산 관점에서, 트랜스포머는 편향이 낮은 (표현력이 좋은) 모델들이다. 많은 양의 텍스트를 이 모델들에 집어넣는 것이 명백한 언어학적 구조의 모델 (편향이 높음)보다 낫다. 아키텍쳐는 병목지점을 통과하며 압축되는 시퀀스들이어야 한다.
-
모델은 라벨링되지 않은 텍스트에서 단어들을 추측하는 것으로 언어에 대해 많은 것을 배울 수 있다. 이는 훌륭한 비지도 학습 목표로 밝혀진 바 있다. 세부적인 과제들에 대한 파인 튜닝은 더 쉬워진다.
-
양방향 맥락이 결정적이다.
강의 후의 질문들로부터 얻을 수 있는 추가적인 인사이트:
‘언어를 이해한다’는 것을 정량화 할 수 있는 방법들은 무엇인가? 어떻게 이 모델들이 정말로 언어를 이해했는지를 알 수 있을까?
“트로피는 너무 크기 때문에, 여행가방에는 맞지 않다.”“The trophy did not fit into the suitcase because it was too big”: 기계들이 이 문장에서 ‘그것’it이 뭘 가리키는지를 알아내기란 어렵다. 인간들은 이 과제를 잘 해낸다. 이런 어려운 예시들로 구성된 데이터셋에서 인간은 95%의 성능을 달성했다. 컴퓨터 프로그램은 트랜스포머가 혁신을 가져다주기 전까지, 고작 60% 언저리 성능만을 달성했을 뿐이다. 최근의 트랜스포머 모델들은 저 데이터셋에서 90% 이상을 달성할 수 있다. 이는 이 모델들이 데이터를 단순히 암기/활용만 하는 것이 아니라, 데이터 내부의 통계학적인 패턴을 따라 개념과 목표들을 학습하고 있음을 시사한다.
더군다나, 버트와 로베르타는 SQUAD와 Glue에서 인간을 뛰어넘는 성능을 달성했다. 바트로 생성한 요약본들은 사람들에게도 진짜(사람이 쓴 것)처럼 보인다. (높은 BLEU 점수) 이러한 사실들은 모델이 어떤 방식으로든 언어를 이해하고 있음을 나타내는 증거라고 볼 수 있다.
기초 언어
흥미롭게도, 강의자 (Mike Lewis, Research Scientist, FAIR)는 ‘기초 언어’라고 불리우는 개념을 연구하고 있다. 이 연구 분야의 목적은 칫-챗chit-chat이나 협상 가능한, 대화가 가능한 에이전트를 만드는 것이다. 칫채팅chit-chatting 그리고 협상은 텍스트 분류나 텍스트 요약과 비교해서 (상대적으로) 불확실한 목표들과 함께해야 하는 추상 과제들이다.
모델이 이미 세계 지식을 갖고 있는지 아닌지 측정할 수 있을까?
‘세계 지식’은 추상적 개념이다. 우리가 관심있는 개념들에 대해 간단한 질문들을 모델에 하는 식으로, 매우 기본적인 수준에서만 그들의 세계 지식을 테스트할 수 있다. 버트나 로베르타, T5같은 모델들은 수십억개의 파라미터를 갖고 있다. 이런 모델들을 위키피디아같은 비격식적인 텍스트들의 거대한 언어 자료로 트레이닝하는 걸 생각해보면, 파라미터들을 사실을 암기하는데에 사용하고는 우리가 하는 질문들에 대해 답변 할 수 있을 것이다. 추가로, 모델을 어떤 과제를 위한 파인튜닝하기 전후로, 동일한 지식 테스트를 (모델들에) 수행하는 것도 생각해볼 수 있다. 이는 얼마나 많은 정보들을 모델이 ‘망각’해야하는지에 대한 느낌을 알려준다.
📝 Trevor Mitchell, Andrii Dobroshynskyi, Shreyas Chandrakaladharan, Ben Wolfson
Jieun
20 Apr 2020