NLP를 위한 딥러닝
🎙️ Mike Lewis오버뷰
- 최근 몇 년간 놀라운 진전이 있었다:
- 몇몇 언어들에서 사람들이 통역사보다 기계 번역기를 선호한다
- 많은 질문-답변 데이터셋에서 인간의 수준을 넘어선 성과가 있었다
- 언어 모델들이 유창하게 문단을 생성해낸다 (예시로. Radford et al. 2019)
- 상당히 일반적인 모델들로 이러한 진전들을 이루려면, 약간이라도 과제별로 전문가 기술들이 있어야 한다
언어 모델
- 언어 모델은 텍스트에 확률을 부여한다: $p(x_0, \cdots, x_n)$
- 가능한 문장의 종류가 많기 때문에, 분류기classifier 트레이닝만 하는 건 할 수 없다.
- 가장 널리 알려진 방법은 연쇄 법칙chain rule을 사용한 팩토라이즈 분포factorize distribution이다.
신경 언어 모델
기본적으로 텍스트를 신경망에 입력으로 넣으면, 신경망은 모든 맥락을 벡터로 바꾼다. 이 벡터는 다음 단어를 대표하며, 거대한 단어 임베딩 행렬을 얻게 된다. 단어 임베딩 행렬은 모델이 내놓을 가능성이 있는, 모든 개별 단어에 대응하는 벡터를 갖고 있다. 그 다음으로는 단어 벡터별로, 맥락 벡터와의 내적을 통해 유사도를 계산한다. 다음 단어를 예측하는 우도likelihood를 얻어내며, 최대 우도maximum likelihood를 사용해 모델을 트레이닝한다. 여기서 핵심이 되는 세부항목은 단어 자체와 직접적으로 씨름하는 것이 아니라, 서브-워드sub-words 또는 문자들이라 불리우는 것들과 씨름한다는 점이다.
\[p(x_0 \mid x_{0, \cdots, n-1}) = \text{softmax}(E f(x_{0, \cdots, n-1}))\]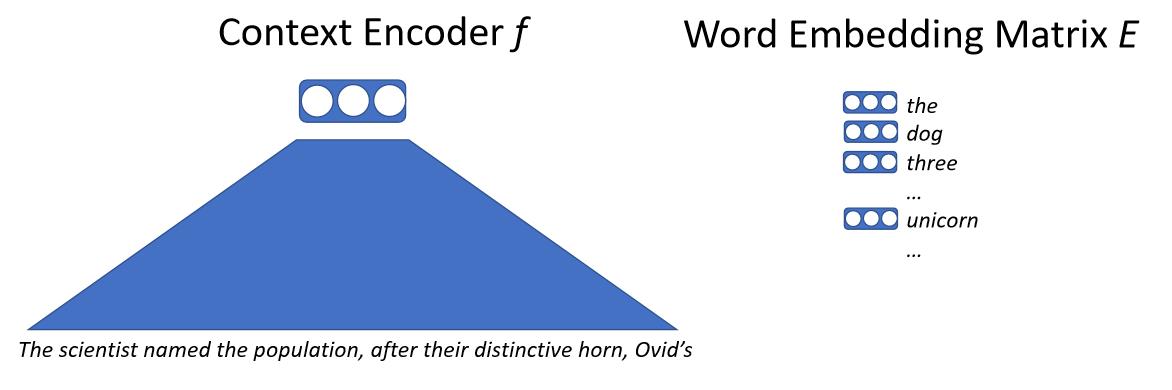
합성곱 언어 모델
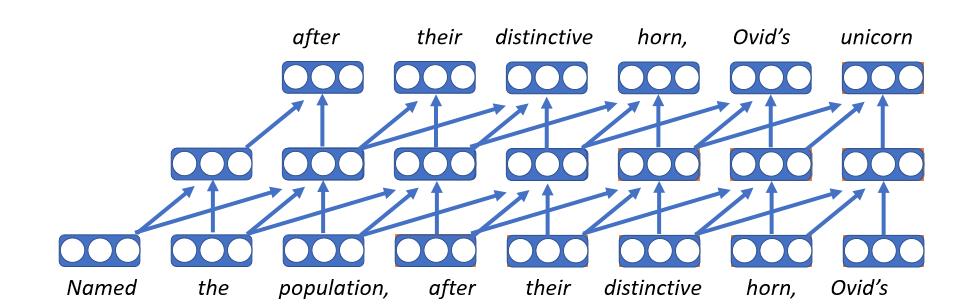
- 첫번째 신경 언어 모델
- 각 단어를 벡터로 임베딩한다는 건, 룩업 테이블lookup table에서 임베딩 행렬embedding matrix로 간다는 뜻이기에, 맥락과는 무관하게 항상 같은 단어 벡터를 갖는다.
- 각 타임 스텝마다 같은 정방향feed forward 신경망을 적용한다.
- 슬프게도, 고정된 길이의 히스토리history는 오로지 (그 단어가) 속한 맥락에서만 영향을 받는다는 뜻이다.
- 이 모델들은 매우 빠를 수 있다는 장점이 있다.
순환 언어 모델
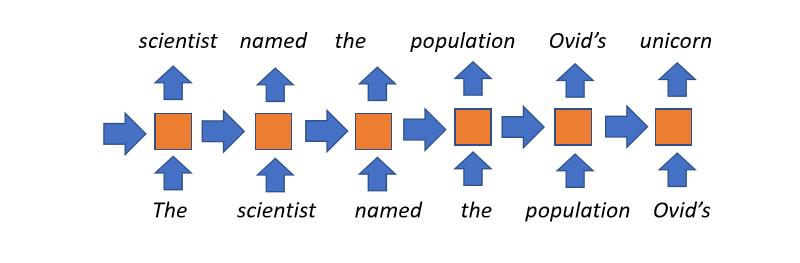
- 몇년 전 까지만 해도 꽤 인기있는 접근법이었다.
- 곧장 나아가는 컨셉: 각 타임 스텝마다 어떤 스테이트state를 유지한다. (이전의 타임 스텝에서 받아오며, 얼마만큼 읽어왔는지를 나타낸다.) 이는 현재 읽을 단어와 나중 스테이트에서 사용될 것의 조합이다. 이후 필요한 만큼, 여러번의 타임 스텝 동안 이 과정을 반복한다.
- 제한없는 맥락unbounded context 사용: 책의 타이틀은 책의 마지막 단어의 은닉 스테이트에 영향을 끼칠 수 있다
- 단점들:
- 문서를 읽은 전체 히스토리는, 타임 스텝마다 (모델의 병목지점bottleneck) 고정 길이의 벡터로 압축된다.
- 긴 맥락에서는 기울기가 사라지는vanish 경향이 있다.
- 타임 스텝에 걸친 병렬 처리가 불가능하기 때문에, 트레이닝 속도가 느리다
트랜스포머 언어 모델
- 가장 최근 NLP에서 사용되는 모델이다
- 혁명적인 패널티
- 세 가지 주요 단계들
- 입력 단계
- 다른 파라미터를 쓰는 $n$ 번의 트랜스포머 블록들 (인코딩 레이어)
- 출력 단계
- 트랜스포머 원 논문에 있는 6 트랜스포머 모듈 (인코딩 레이어) 예제이다.
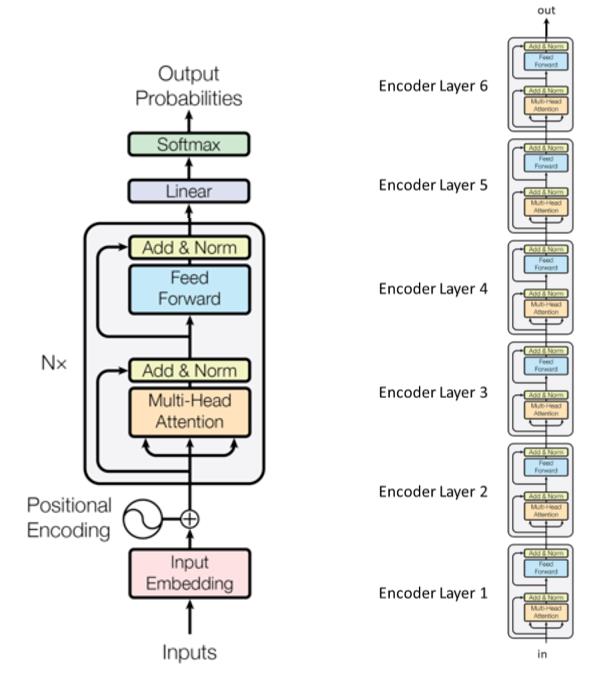
하위 레이어들은 “더하기&정규화”“Add&Norm”이라 이름붙여진 박스들로 연결되어 있다. “더하기” 파트의 의미는 잔차 커넥션residual connection으로, 기울기가 사라지는 현상을 멈추는데 도움이 된다. 여기서 말하는 정규화는 레이어 정규화이다.
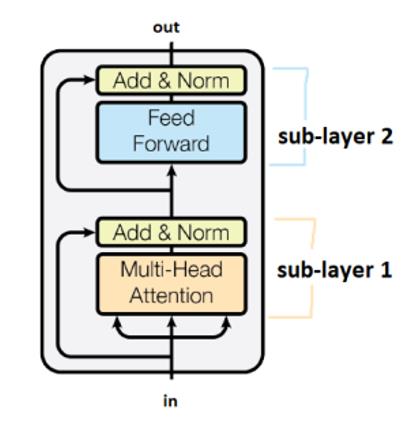
가중치가 타임 스텝을 교차하며 공유된다는 걸 기억해두자.
멀티-헤드 어텐션
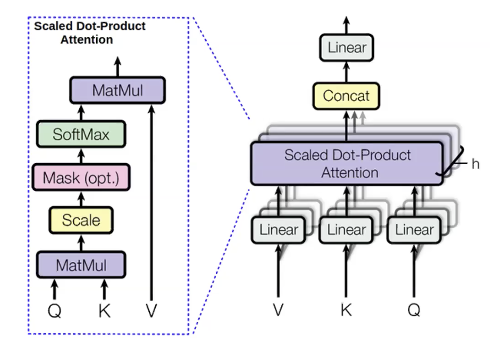
우리가 예측하려는 단어들, 우리가 계산하는 값들을 쿼리query(q)라고 부른다. 예측에 쓰인 모든 이전 단어는 키keys(k)라고 부른다. 쿼리는 맥락에 대한 어떤것(이전에 쓰인 형용사 같은)을 말해준다. 키는 현재 단어들에 대한 정보(예를 들어 그게 형용사인지 아닌지)를 담고 있는 레이블과 같다. 한 번 q가 계산되면, 이전 단어들의 분포 ($p_i$)를 얻을 수 있다:
\[p_i = \text{softmax}(q,k_i)\]그리고 우리는 이전 단어들을 위한, 밸류values(v)라고 불리우는 수량을 계산한다. 밸류는 단어의 내용을 대표한다.
밸류를 얻으면, 어텐션 분포를 최대화하여 은닉 스테이트를 계산한다:
\[h_i = \sum_{i}{p_i v_i}\]다른 쿼리, 밸류, 그리고 키들에 대해서 여러번 같은 것을 병행해서 계산한다. 이렇게 하는 이유는 서로 다른 것들을 사용해서 다음 단어를 예측하고 싶기 때문이다. 한 예로, 단어 “unicorns”를 이전의 세 단어 “These”,”horned” 그리고 “silver-white”를 써서 예측해보자. 사람은 “horned”,”silver-white”를 통해 “unicorn”임을 안다. 하지만 “These”는 복수의 “unicorns”임을 말한다. 따라서, 다음 단어가 무엇이 될지 알기 위해서는 우리는 이 세 단어를 모두 알아야만 할 것이다. 멀티-헤드 어텐션은 여러개의 이전 단어들을 보게하는 방법이다.
멀티-헤드 어텐션의 큰 장점 하나는 병렬화가 가능하다는 점이다. RNNs과 달리 멀티-헤드 어텐션 모듈들의 모든 헤드와 모든 타임 스텝은 한 번에 계산된다. 모든 타임 스텝을 계산할 때 문제점 하나는 이후 단어들까지 본다는 것인데, 우리는 이전 단어들만 보고자 한다.
한 가지 해결책은 셀프-어텐션 마스킹이다. 마스크는 0들을 하삼각lower triangle으로 하고, 음의 무한대를 상삼각upper triangle으로 가진 상삼각 행렬이다. 어텐션 모듈의 출력에 이 마스크를 추가해서 얻는 효과는 왼쪽 단어들 하나하나가 오른쪽에 있는 단어들보다 훨씬 큰 어텐션 스코어를 갖는다는 점이다. 덕분에 모델은 이전 단어들에만 집중할 수 있다. 마스크를 응용하는 일은 언어 모델에서 무척 중요한데, 수학적으로 올바르게 만들어주기 때문이다. 하지만 텍스트 인코더에서는 양방향 맥락bidirectional context이 도움될 수 있다.
트랜스포머 언어 모델을 만들때의 디테일 한 가지는, 입력에 포지셔널 임베딩positional embedding을 추가하는 것이다. 언어를 해석 하려고 할 때 몇몇 특성들은 순서가 중요할 수 있다. 여기에 쓰인 테크닉은 분리된 임베딩을 다른 타임 스텝에서 학습시키고, 이들을 입력에 추가한다, 그래서 현 입력값은 워드 벡터들의 총합이고, 포지셔널 벡터이다. 이는 순서 정보를 제공한다.
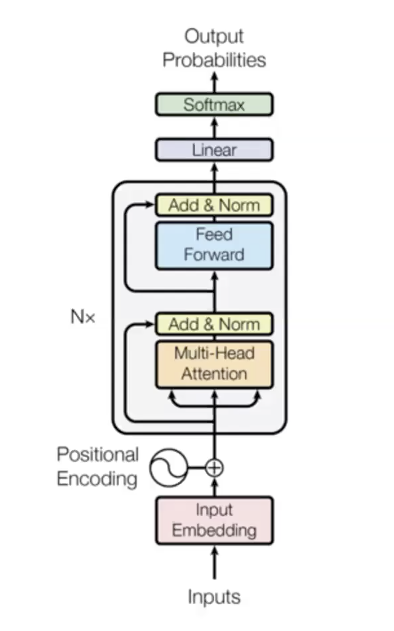
왜 이 모델이 좋은가:
- 각 단어 페어들간의 직접적인 연결을 해준다. 각 단어는 이전 단어들의 은닉 스테이트에 직접적으로 접근할 수 있고, 기울기가 사라지는 vanishing gradients 현상을 줄인다. (이 모델은) 매우 비싼 함수를 매우 쉽게 배운다.
- 모든 타임 스텝들은 병렬로 계산된다.
- 셀프 어텐션은 이차식quadratic이고 (모든 타임 스텝들은 모든 다른것들에도 참여할 수 있다), 최대 연속된 배열의 길이를 제한한다.
몇가지 트릭들(특히 멀티-헤드 어텐션과 포지셔널 인코딩을 위한)과 디코딩 언어 모델
트릭 1: 트레이닝을 안정화시키기 위해 레이어 정규화를 확장해서 사용하는 건 정말 큰 도움이 된다
- 트랜스포머에겐 정말 중요하다
트릭 2: 웜업 + 역-제곱근Inverse-square root 트레이닝 스케쥴
- 학습률 스케쥴을 사용해라: 트랜스포머가 잘 동작하게 만들기 위해서, 0에서 수천번째 스텝들까지 선형으로 감소하는 학습률learning rate decay을 사용하자
트릭 3: 초기화는 신중하게
- 기계 번역같은 과제들에 정말 도움이 된다
트릭 4: 레이블 스무딩
- 기계 번역같은 과제에 정말 도움이 된다
아래는 위에서 언급한 어떤 방법들의 결과들이다. 이 테스트들에서, 오른쪽의 메트릭metric은 ‘ppl’ (perplexity, 혼잡도)이라고 부른다. (ppl은 낮을수록 좋다)
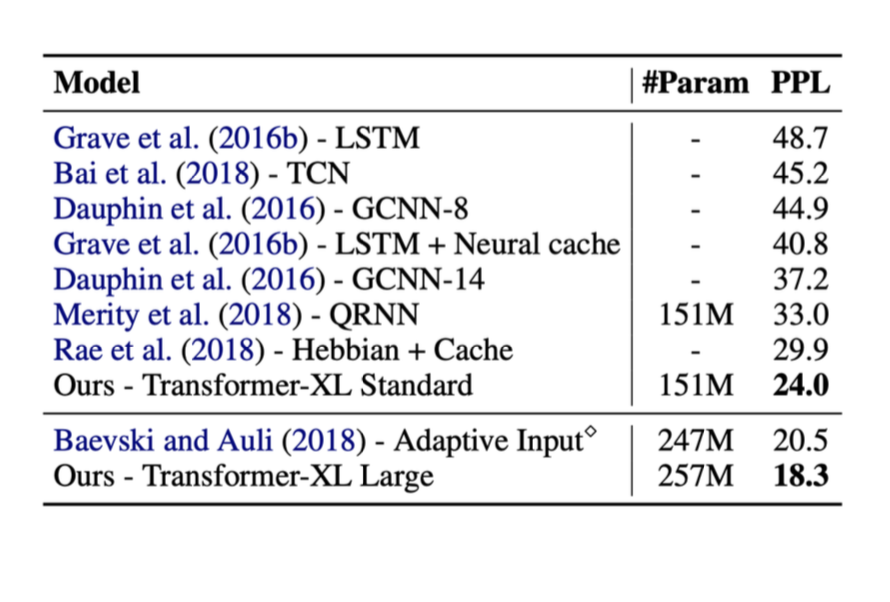
트랜스포머가 소개되었을 때, 퍼포먼스가 크게 향상된 것을 볼 수 있다.
트랜스포머 언어 모델의 몇가지 중요한 사실들
- 최소한의 귀납편향inductive bias
- 모든 단어들은 직접적으로 연결되어 있다. (기울기 사라짐 현상을 완화할 수 있다)
- 모든 타임 스텝들은 병렬적으로 계산된다.
셀프 어텐션은 이차식quadratic이고 (모든 타임 스텝은 모든 다른것에도 참여할 수 있다), 최대 시퀀스 길이를 제한한다.
- 셀프 어텐션이 이차식인 것처럼, 실제로 그 비용도 선형적으로 증가한다. 이는 문제가 될 수 있다.

트랜스포머는 크기를 수월하게 키울 수 있다
- 트레이닝 데이터가 무제한일때, 필요한 것 이상으로 더 나아갈 수 있다
- GPT 2는 2019년에 20억개의 파라미터를 사용했다.
- 2020년 최근 모델들은 최대 170억개의 파라미터들을 사용한다.
디코딩 언어 모델
이제 텍스트에 대한 확률 분포를 트레이닝 할 수 있다 - 이제 지수적으로, 가능성 있는 여러 출력값들을 얻을 수 있기에, 최대값을 계산할 필요가 없다. 첫번째 단어로 어떤 것을 선택하든, (그 선택은) 다른 결정들에 영향을 끼칠 수 있다. 그러므로, 첫번째 단어가 주어졌다 가정하며, 이어지는 내용에 탐욕 디코딩greedy decoding을 소개한다.
탐욕 디코딩Greedy Decoding은 동작하지 않는다
각 타임 스텝마다 가장 그럴듯한 단어를 취한다. 하지만, 이 방식이 가장 그럴듯한 시퀀스를 주리라는 보장은 없다. 왜냐면 어느 시점의 스텝을 만든다 해도, 이전 세션들을 탐색해서 되돌릴 수 있는 방법이 없기 때문이다.
완전 탐색Exhaustive search 역시 가능하지 않다
모든 가능한 시퀀스들을 계산해야 하는데, $O(V^T)$의 복잡도를 가지므로 너무 비싸다.
질문과 답변들 종합
-
싱글-헤드 어텐션 모델과 상반된, 멀티-헤드 어텐션의 이점은 뭔가요?
- 다음 단어를 예측하기 위해서, 당신은 여러 분리된 것들을 탐색해야 합니다. 다른 말로 어텐션은 여러 이전 단어들에 배치되어, 다음 단어를 예측하기 위해 필요한 맥락을 이해하려고 노력합니다.
-
어떻게 트랜스포머가 CNNs과 RNNs의 정보의 병목현상informational bottlenecks을 해결하나요?
- 어텐션 모델은 각 단어마다 의존할 수 있는 모든 이전 단어들을 허용하기에, 모든 단어들간 직접적 연결이 가능합니다. 효과적으로 병목현상을 사라지죠.
-
어떻게 트랜스포머가, GPU 병렬처리를 활용하는 측면에서, RNNs와 다른가요?
- 트랜스포머에 있는 멀티-헤드 어텐션 모듈은 병렬성이 높습니다. RNNs은 할 수 없고, GPU 테크놀로지의 혜택도 받을 수 없죠. 사실 트랜스포머는 한 번의 정방향 전파forward 과정에서 모든 타임 스텝을 계산합니다.
📝 Jiayu Qiu, Yuhong Zhu, Lyuang Fu, Ian Leefmans
Jieun
20 Apr 2020