활성화 함수 및 손실 함수 (part 1)
🎙️ Yann LeCun활성화 함수
오늘 강의에서는, 몇 가지 중요한 활성화 함수와 파이토치에서의 구현에 대해 복습할 것이다. 다양한 논문에서 어떤 특정 문제들에 대해서 여기서 다룰 활성화 함수들이 효과적이라고 동작한다고 주장했다.
ReLU - nn.ReLU()
\[\text{ReLU}(x) = (x)^{+} = \max(0,x)\]
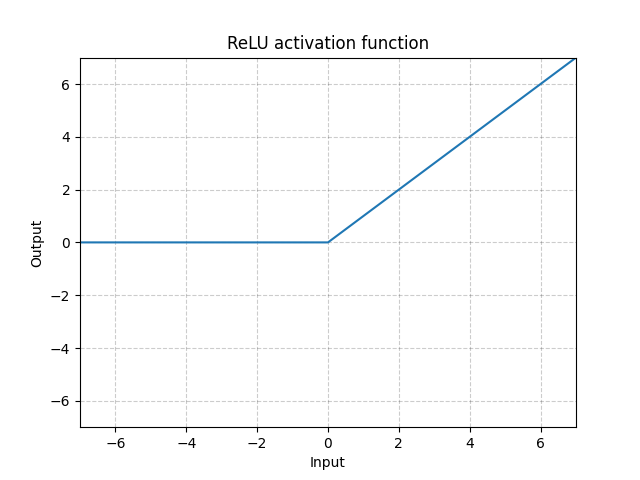
그림. 1: ReLU 함수
RReLU - nn.RReLU()
ReLU 함수에서 변형을 준 것이다. Random ReLU(RReLU)는 다음과 같이 정의한다.
\[\text{RReLU}(x) = \begin{cases} x, & \text{if $x \geq 0$}\\ ax, & \text{otherwise} \end{cases}\]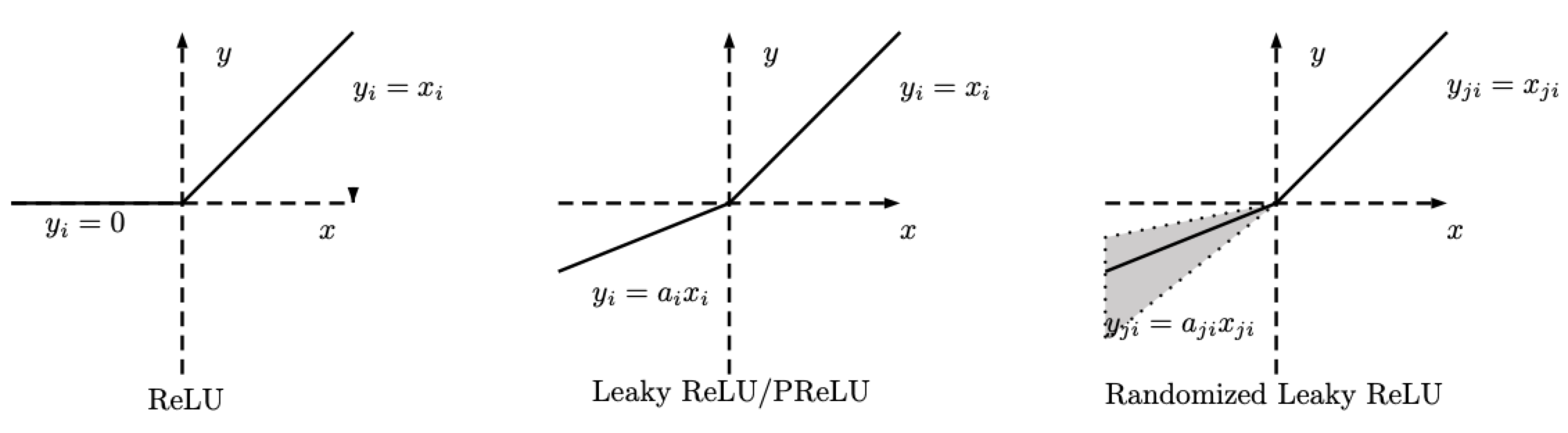
그림. 2: ReLU, Leaky ReLU/PReLU, RReLU
RReLU에서 주의해야 할 점은, $a$는 훈련 중에 주어진 범위 내에서 추출되는 확률 변수이며, 테스트할 때에는 고정 값이 된다. PReLU에서도 또한 $a$는 학습되지만, Leaky ReLU에서는 $a$는 고정 값이다.
LeakyReLU - nn.LeakyReLU()
\[\text{LeakyReLU}(x) = \begin{cases} x, & \text{if $x \geq 0$}\\ a_\text{negative slope}x, & \text{otherwise} \end{cases}\]
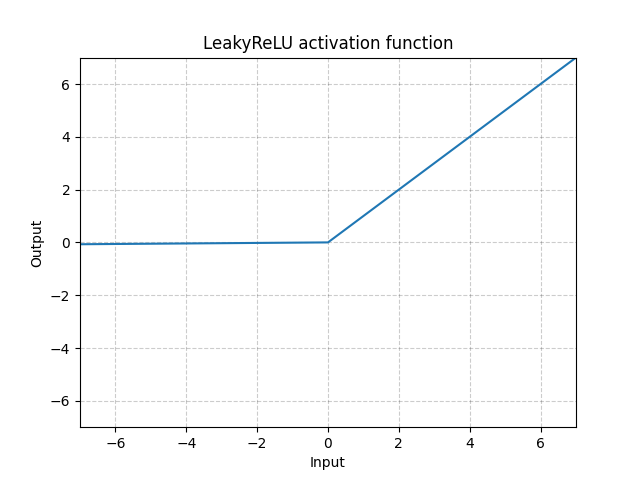
그림. 3: LeakyReLU
여기서 $a$는 고정된 매개 변수이다. 수식의 아래부분은 ReLU 뉴런이 비활성화 되는 것 즉, 어떤 입력에 대해서도 출력이 0이 되어 버리는 “Dying ReLU” 문제를 막아준다. 그러므로, 경사가 0이 된다. 음의 입력에 대해서 작은 값의 기울기Negative slope를 사용함으로써, 신경망이 역전파되어 잘 학습할 수 있도록 한다.
LeakyReLU는 바닐라 ReLU를 쓴다면 경사를 역전파하는 것이 거의 불가능한 skinny network에서 필요하다. 즉, 모든 값이 0이 되어 훈련이 힘든 영역에서도 LeakyReLU를 사용하면 skinny network는 경사를 가질 수 있다.
PReLU - nn.PReLU()
\[\text{PReLU}(x) = \begin{cases} x, & \text{if $x \geq 0$}\\ ax, & \text{otherwise} \end{cases}\]
여기서 $a$는 학습 가능한 매개변수이다.
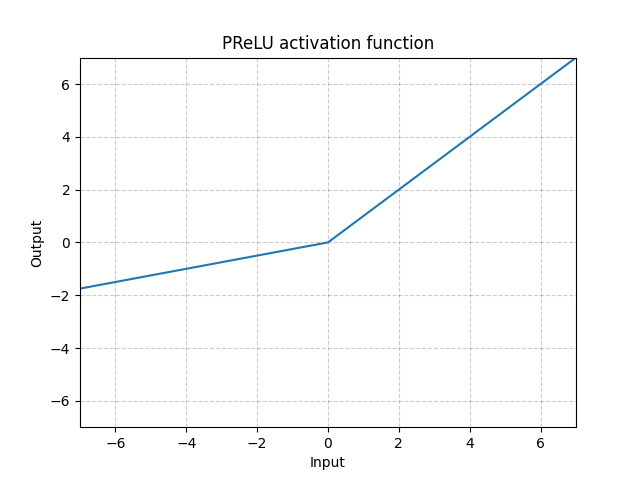
그림. 4: PReLU
위의 활성화 함수들(ReLU, LeakyReLU, PReLU)은 스케일 불변Scale-invariant하다.
Softplus - Softplus()
\[\text{Softplus}(x) = \frac{1}{\beta} * \log(1 + \exp(\beta * x))\]
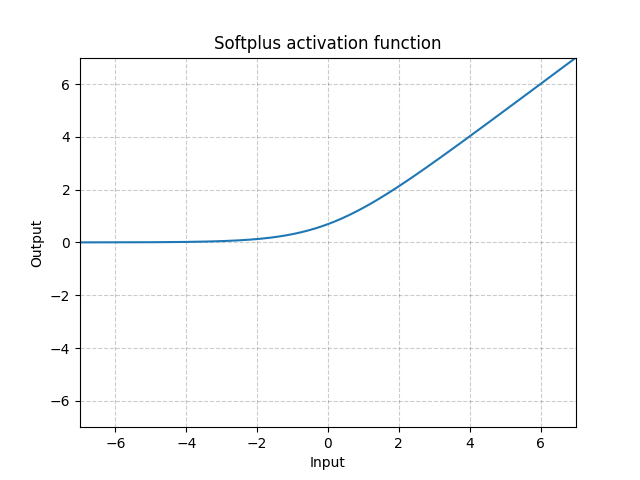
그림. 5: Softplus
Softplus는 ReLU 함수를 부드럽게 근사한 것(미분 가능)으로, 출력을 항상 양수로 제한하는 데에 사용할 수 있다. $\beta$가 커질수록 ReLU와 비슷해진다.
ELU - nn.ELU()
\[\text{ELU}(x) = \max(0, x) + \min(0, \alpha * (\exp(x) - 1)\]
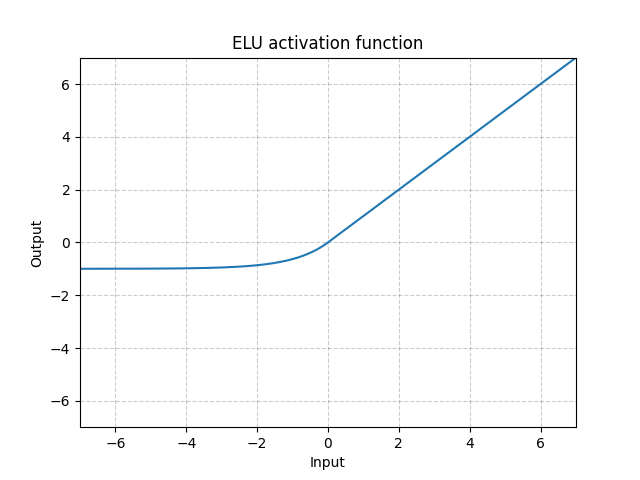
그림. 6: ELU
ReLU와는 달리, 0 이하로 내려가면 시스템의 평균 출력이 0이 될 수 있어, 모델이 더 빠르게 수렴할 것이다. CELU와 SELU는 ELU를 변형한 것으로, 단지 다른 방식으로 매개변수화한 것이다.
CELU - nn.CELU()
\[\text{CELU}(x) = \max(0, x) + \min(0, \alpha * (\exp(x/\alpha) - 1)\]
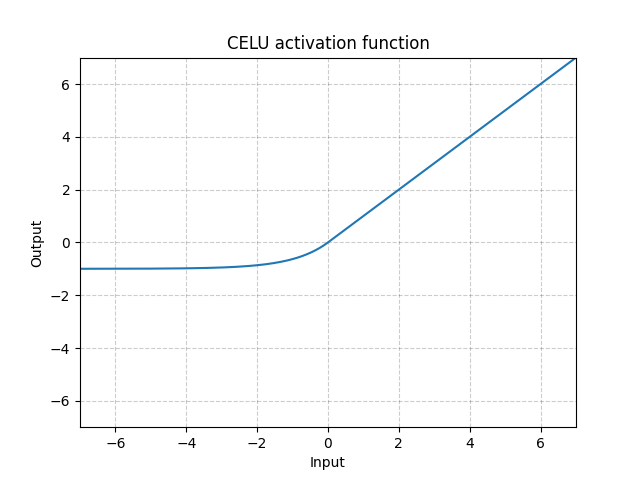
그림. 7: CELU
SELU - nn.SELU()
\[\text{SELU}(x) = \text{scale} * (\max(0, x) + \min(0, \alpha * (\exp(x) - 1))\]
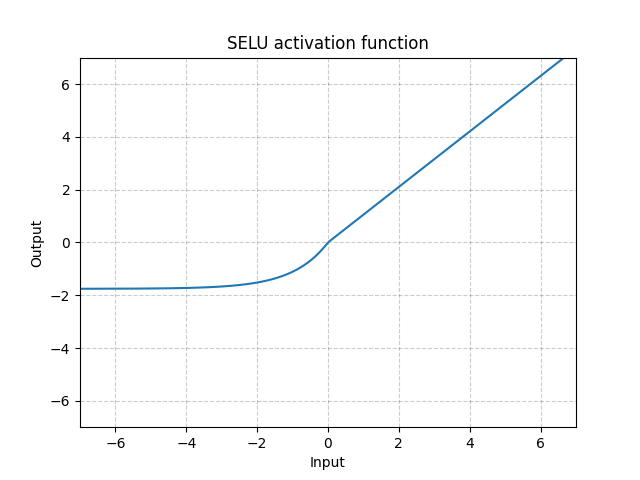
그림. 8: SELU
GELU - nn.GELU()
\[\text{GELU(x)} = x * \Phi(x)\]
여기서 $\Phi(x)$는 가우시안 분포의 누적확률분포함수(CDF)Cumulative Distribution Function이다.
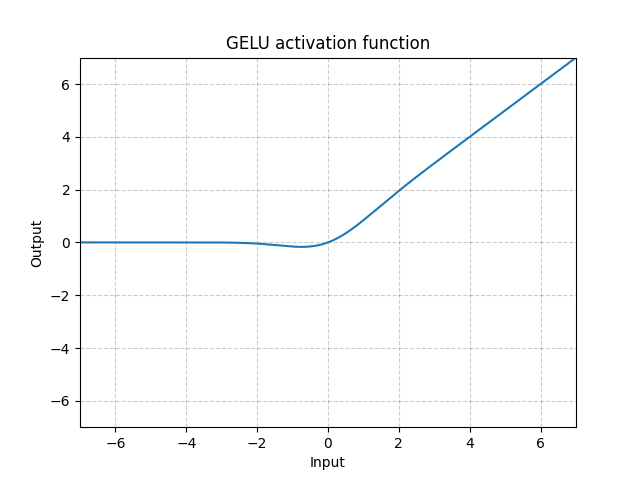
그림. 9: GELU
ReLU6 - nn.ReLU6()
\[\text{ReLU6}(x) = \min(\max(0,x),6)\]
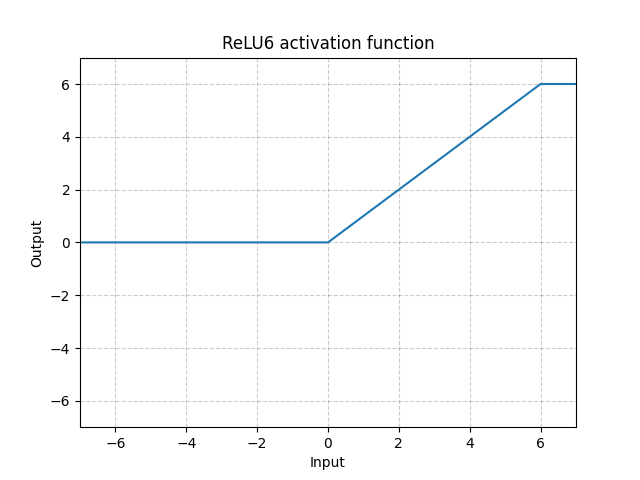
그림. 10: ReLU6
ReLU6는 6에서 포화상태가 되는Saturated ReLU이다. 그러나 6을 포화상태로 하는 데에는 특별한 이유가 없기 때문에, 아래 시그모이드Sigmoid 함수를 사용하는 것이 더 좋을 수 있다.
시그모이드Sigmoid - nn.Sigmoid()
\[\text{Sigmoid}(x) = \sigma(x) = \frac{1}{1 + \exp(-x)}\]
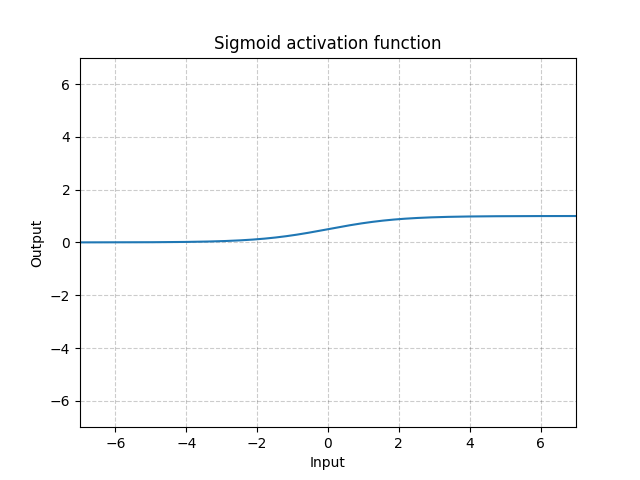
그림. 11: Sigmoid
여러 계층에 시그모이드를 쌓으면, 학습하는데 비효율적일 수 있고 초기화에 주의해야 한다. 이는 입력이 매우 크거나 작으면 시그모이드의 기울기가 0에 가까워지기 때문이다. 이 경우, 매개변수를 업데이트 하기 위해 역전파 되는 경사가 없게 되는데, 이를 경사포화문제Saturating gradient problem라고 한다. 그러므로, 심층 신경망에서는 ReLU와 같은 단일 Kink 함수A single kink function(미분 불가능한 점이 하나 존재하는 함수)가 선호된다.
Tanh - nn.Tanh()
\[\text{Tanh}(x) = \tanh(x) = \frac{\exp(x) - \exp(-x)}{\exp(x) + \exp(-x)}\]
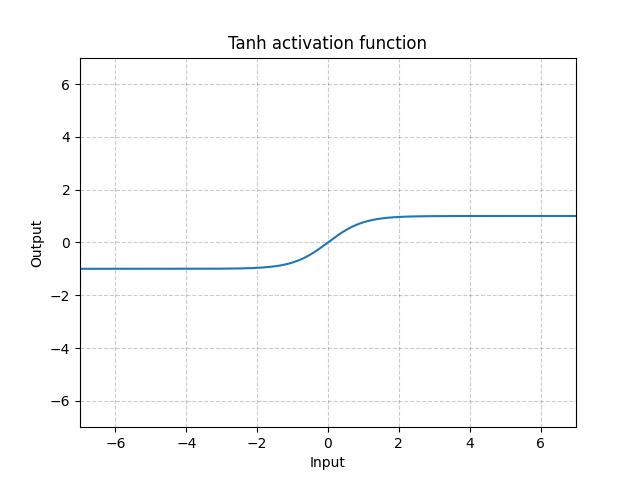
그림. 12: Tanh
Tanh는 -1에서 1까지의 범위에 집중되어 있다는 점을 제외하면 기본적으로 시그모이드와 동일하다. 함수 출력의 평균은 거의 0에 가까우므로, 모델이 빨리 수렴하게 된다. 일반적으로 각 입력 변수의 평균이 0에 가까울수록 수렴속도가 빠르다는 것에 유의해야 한다. 배치 정규화Batch Normalization가 그 예시이다.
Softsign - nn.Softsign()
\[\text{SoftSign}(x) = \frac{x}{1 + |x|}\]
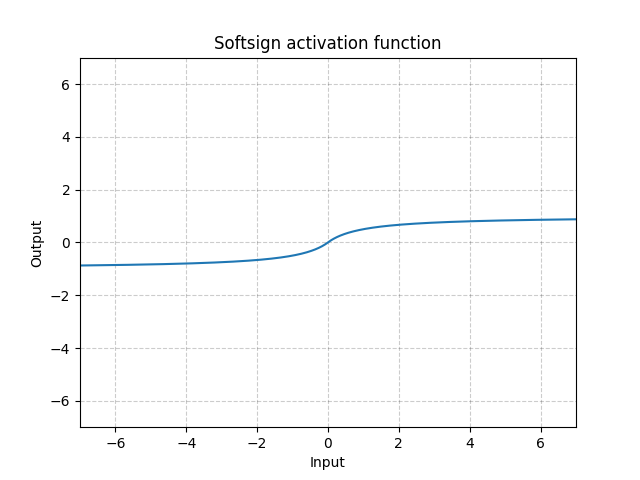
그림. 13: Softsign
시그모이드 함수와 비슷하지만, 점근선Asymptote에 천천히 도달하여 경사소실문제Gradient Vanishing Problem를 어느정도 완화해준다.
Hardtanh - nn.Hardtanh()
\[\text{HardTanh}(x) = \begin{cases} 1, & \text{if $x > 1$}\\ -1, & \text{if $x < -1$}\\ x, & \text{otherwise} \end{cases}\]
선형 영역[-1, 1]의 범위는 min_val 과 max_val를 이용하여 조정할 수 있다.
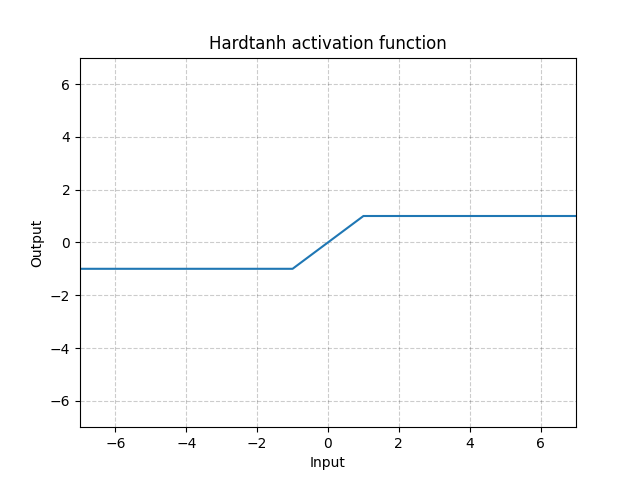
그림. 14: Hardtanh
Hardtanh는 놀랍게도 가중치가 작은 값 범위 내에 있을 때 놀랍게도 잘 작동한다.
Threshold - nn.Threshold()
\[y = \begin{cases} x, & \text{if $x > \text{threshold}$}\\ v, & \text{otherwise} \end{cases}\]
Threshold는 경사를 역전파할 수 없기 때문에 거의 사용되지 않는다. 60~70년대에 이진뉴런을 사용할 때, 역전파를 사용하지 못했던 이유이기도 하다.
Tanhshrink - nn.Tanhshrink()
\[\text{Tanhshrink}(x) = x - \tanh(x)\]
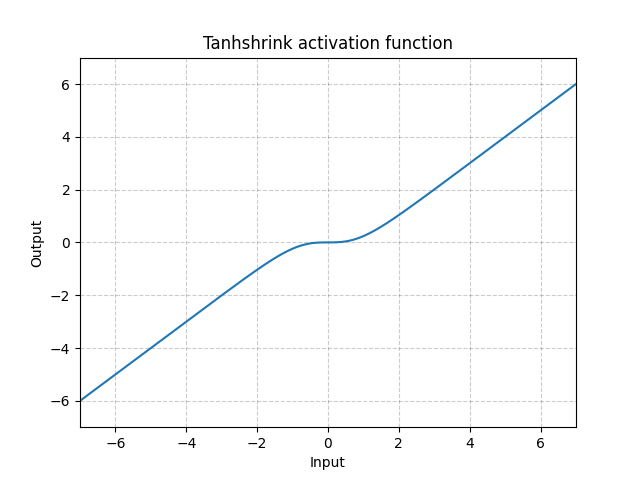
그림. 15: Tanhshrink
Thanshrink는 잠재변수 값을 계산하기 위한 희소 코딩Sparse coding 외에는 거의 사용되지 않는다.
Softshrink - nn.Softshrink()
\[\text{SoftShrinkage}(x) = \begin{cases} x - \lambda, & \text{if $x > \lambda$}\\ x + \lambda, & \text{if $x < -\lambda$}\\ 0, & \text{otherwise} \end{cases}\]
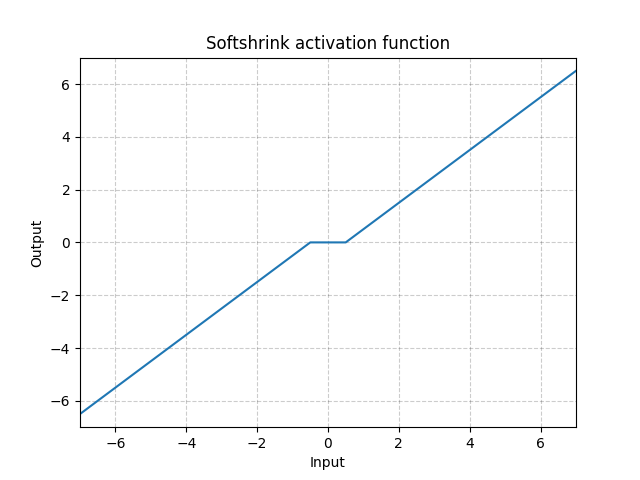
그림. 16: Softshrink
Softshrink는 기본적으로 변수를 0을 향해 상수로 수축시키고, 변수가 0에 가까워지면 출력은 0이 된다. $\ell_1$ 기준에 대한 경사라고 생각하면 된다. Softshrink를 Iterative Shrinkage-Thresholding Algorithm (ISTA)의 특정 단계에서 쓰이기도 하다. 그러나 일반적인 신경망에서 활성화로는 잘 사용되지 않는다.
Hardshrink - nn.Hardshrink()
\[\text{HardShrinkage}(x) = \begin{cases} x, & \text{if $x > \lambda$}\\ x, & \text{if $x < -\lambda$}\\ 0, & \text{otherwise} \end{cases}\]
그림. 17: Hardshrink
Hardshrink 또한 희소 코딩Sparse coding을 제외하고는 거의 사용되지 않는다.
LogSigmoid - nn.LogSigmoid()
\[\text{LogSigmoid}(x) = \log\left(\frac{1}{1 + \exp(-x)}\right)\]
그림. 18: LogSigmoid
LogSigmoid는 주로 활성화함수 보다는 손실함수에 사용된다.
Softmin - nn.Softmin()
\[\text{Softmin}(x_i) = \frac{\exp(-x_i)}{\sum_j \exp(-x_j)}\]
Softmin은 숫자를 확률분포로 변환한다.
Soft(arg)max - nn.Softmax()
\[\text{Softmax}(x_i) = \frac{\exp(x_i)}{\sum_j \exp(x_j)}\]
LogSoft(arg)max - nn.LogSoftmax()
\[\text{LogSoftmax}(x_i) = \log\left(\frac{\exp(x_i)}{\sum_j \exp(x_j)}\right)\]
LogSoft(arg)max 또한 활성화 함수에는 잘 안쓰이고 주로 손실함수에 사용된다.
Q&A 활성화 함수
nn.PReLU() 관련된 질문들
- 왜 모든 채널에 대해 같은 $a$ 값이 필요한가요?
각 채널들은 다른 $a$ 값을 가질 수 있다. $a$를 모든 유닛의 매개변수로 사용할 수 있다. 또한, 특징지도Feature map로 공유될 수 있다.
- $a$를 학습하나요? $a$를 학습함으로써 얻는 이점이 있나요?
$a$를 학습할 수도 있고 고정시킬 수도 있다. 고정시키는 이유는 음의 영역에서도 0이 아닌 경사를 갖는 비선형성을 보장하기 때문이다. $a$를 학습가능하도록 만듦으로써 시스템을 비선형성에서 선형 매핑 및
완전정류Full rectification로 변환할 수 있다. 이는 윤곽선Edge의 극성에 무관한 윤곽선 검출을 구현과 같은 응용에 사용될 수 있다.
- 얼마나 비선형성을 복잡하게 만들 수 있나요?
이론적으로,
스프링 매개변수<sup>Spring parameter</sup>와 체비셰프 다항식 등과 같이 전체 비선형 함수를 아주 복잡한 방법으로 매개변수화 시킬 수 있다. 매개변수화 시키는 것은 일종의 학습 방법이다.
- 시스템에서 유닛을 많이 가지고 있는 것보다 매개변수화 하는 것의 이점이 무엇인가요?
무엇을 하고 싶은지에 달려있다. 예를 들어, 저차원 공간에서 회귀 분석을 수행할 때에는, 매개변수화 하는 것이 도움이 될 수 있다. 그러나 이미지 인식과 같이 고차원 공간을 다루는 경우, “a” 비선형성이 필요할 것이고 단조 비선형성Monotonic nonlinearity이 더 효과적일 것이다. 간단히 말해, 어떠한 함수도 매개변수화할 수 있지만, 큰 이점을 가져오지는 않을 수 있다.
Kink에 관련된 질문들
- 단일 Kink vs 이중 Kink
이중 kink가 기본 스케일이다. 이말인 즉슨, 입력 층에 2가 곱해지면(또는 신호의 진폭에 2를 곱하면), 출력은 완전히 달라질 것이다. 이 신호는 비선형에 더욱 가까워질 것이고, 완전히 다른 특성을 갖는 출력을 얻을 것이다. 반면에 단일 kink 함수라면, 입력에 2를 곱해도 출력 또한 2를 곱한 값이 될 것이다.
- 꺾인 비선형 활성화와 부드러운 비선형 활성화의 차이점, 언제 어떤 것이 왜 선호되나요?
이는 Scale equivariance와 관련된 문제이다. Kink가 hard하면, 입력에 2를 곱했을 때 출력에도 2가 곱해진다. 부드러운 활성화의 경우로 예를 들자면, 입력에 100을 곱한다면 출력은 hard kink처럼 보이게 된다. 이는 부드러운 부분이 100만큼 줄어들기 떄문이다. 반대로 입력을 100으로 나누면, kink는 아주 매끄러운 볼록함수Convex function가 된다. 따라서 입력의 스케일을 변경하여 활성화 유닛의 특성을 꿔야 한다.
하지만 이 방법은 종종 문제가 될 때가 있다. 예를 들어, 다층 신경망을 학습시킬 때 연달아 있는 두 개의 층의 경우가 그렇다. 한 층의 가중치들이 다른 층의 가중치들에 얼마나 크게 상관이 있는지를 제어할 수 없다. 스케일에 영향이 있는 비선형은 특성을 완전히 바꿔 버리기 때문에, 신경망의 첫 번째 층에서 어떤 크기의 가중치 행렬을 사용할 지 정할 수 없다.
이 문제를 해결할 수 있는 방법 중 하나는 배치 정규화Batch normalization와 같이 각 층의 가중치를에 hard scale을 설정해서 정규화 할 수 있다. 따라서 한 유닛으로 들어가는 분산이 항상 상수가 된다. 스케일을 고정하게 되면, 시스템은 이중 kink 함수 시스템에서 비선형성의 어떤 부분을 사용할지 선택할 수 있는 방법이 없다. ‘고정된’ 부분이 너무 선형에 가까워지면 문제가 된다. 예를 들어, 시그모이드는 0 부근에서 거의 선형이 되어서 (0에 가까운) 배치 정규화된 출력은 ‘비선형성’을 활성화 시킬 수 없다. 심층 신경망이 왜 단일 kink 함수에서 잘 작동하는지에 대한 이유는 명확하지는 않다. 아마도 scale equivariance 특성 때문인 것 같다.
Soft(arg)max 함수에서의 온도계수Temperature coefficient
- 언제 온도계수를 사용하고, 왜 사용하나요?
어느 정도까지는, 온도는 입력 가중치에
redundant하다. 가중합이 Softmax로 들어가면, $\beta$ 매개변수는 가중치의 크기와redundant하다. 온도는 출력분포의hard한 정도를 제어한다. $\beta$가 아주 클 때는 출력이 1이나 0에 아주 가깝게 된다. $\beta$가 아주 작으면soft해진다. $\beta$가 0에 가깝게 한정되면 평균에 수렴한다. $\beta$가 무한대로 발산하게 되면, argmax와 같은 특성을 가져 더이상soft한 버전이 아니게 된다. 그러므로 softmax에 넣어주기 전에 정규화Normalization를 거치면 매개변수 조정을 통해hardness를 조절할 수 있다. 보통 작은 $\beta$에서 시작하면, 경사하강법이 적절하게 동작하도록 할 수 있고, 어텐션 메커니즘Attention mechanism과 같은harder decision을 원한다면 $\beta$를 증가시키면 된다. 따라서, 결정을sharpen하게 할 수 있다. 이러한 방법을 담금질Annealing이라고 한다. Self-attention mechanism과 같은 experts의 mixture에 유용하게 사용할 수 있다.
손실함수 Loss functions
파이토치에는 다양한 손실함수가 구현되어 있다. 그 중 일부를 여기서 다루어 볼 것이다.
nn.MSELoss()
이 함수는 입력 $x$와 타겟Target $y$의 원소들 사이에 평균제곱오차Mean Squared Error (MSE, Squared L2 Norm)를 계산한다.
만약 $n$ 샘플의 미니배치Minibatch를 사용한다면, 이 배치에서 각 샘플당 하나씩 $n$개의 loss를 가지게 된다. loss를 벡터로 가지거나 이를 줄이는 것을 손실함수라고 한다.
만약 줄어들지 않은 상태 즉, reduction='none'로 설정되어 있다면, loss는 다음과 같다.
여기서 $N$은 배치의 크기이고, $x$와 $y$는 각각 총 n개 원소를 가진 임의의 모형Shape을 가진 텐서Tensor이다.
Reduction 옵션은 아래와 같다. 기본값이 reduction='mean'인 것에 주의해야 한다.
모든 원소에 대해 Sum 연산을 하고, $n$ 으로 나눈다.
nn.L1Loss()
L1 loss는 입력 $x$와 타겟Target $y$의 원소들(또는 실제 출력과 원하는 출력) 사이에 평균절대오차 mean absolute error (MAE)를 계산한다.
만약 줄어들지 않은 상태 즉, reduction='none'로 설정되어 있다면, loss는 다음과 같다.
여기서 $N$은 배치의 크기이고, $x$와 $y$는 각각 총 n개 원소를 가진 임의의 모형Shape을 가진 텐서Tensor이다.
nn.MSELoss() 에서와 비슷하게 'mean' and 'sum'에 reduction 옵션이 있다.
사용 사례: L1 loss는 L2 loss에 비하여 이상치와 잡음 Outliers and Noise에 상대적으로 견고Robust하다. L2는 이상치와 잡음이 있는 점들에 대해 제곱을 하여, 비용함수가 이상치에 대해 아주 민감하게 된다.
문제점: L1 loss는 0의 값을 갖는 바닥 지점Bottom에서 미분이 불가능하기 때문에 경사를 다룰 때 주의를 기울여야 한다. (Softshrink라고 불린다.) 여기서 영감을 받은 것이 앞으로 나올 SmoothL1Loss이다.
nn.SmoothL1Loss()
이 함수는 요소별Element-wise 절대오차가 1 아래로 떨어질 때 L2 loss를 이용하고 나머지는 L1 loss를 사용한다.
\[\text{loss}(x, y) = \frac{1}{n} \sum_i z_i\]여기서 $z_i$는 다음과 같이 주어진다.
\[z_i = \begin{cases}0.5(x_i-y_i)^2, \quad &\text{if } |x_i - y_i| < 1\\ |x_i - y_i| - 0.5, \quad &\text{otherwise} \end{cases}\]이 또한 reduction 옵션이 있다.
SmoothL1Loss는 Ross Girshick의 Fast R-CNN에 의해서 알려졌다. Smooth L1 Loss는 Huber Loss라고도 불리며, 목적함수로 사용될 때에는 Elastic Network 라고 불린다.
사용 사례: MSELoss 보다는 이상치에 대해 덜 민감하고, 0인 지점에서 부드럽다. 이 함수는 주로 컴퓨터 비전 분야에서 이상치로부터 보호하기 위해 주로 쓰인다.
문제점: 이 함수는 위 함수에서 보이는 처럼 $0.5$의 스케일을 가지고 있다.
컴퓨터 비전에서의 L1 vs. L2
예측하는 과정에서, 다음과 같이 다양한 $y$를 가질 수 있다.
- MSE(L2 Loss)를 사용한다면, 모든 $y$에 대해서 평균이 나온다. 컴퓨터 비전에서는 blurry 이미지를 얻게 된다는 뜻이다.
- L1 loss를 사용한다면, L1 거리를 최소화 하는 $y$ 값은 중간값Medium이다. Blurry하진 않지만, 다차원에서는 중간값을 정의하기 힘들다.
L1을 사용하면 더 날카로운 이미지를 예측해낸다.
nn.NLLLoss()
음의 로그우도Negative Log Likelihood loss는 C개의 클래스를 가진 분류 문제를 학습시킬 때 사용된다.
수학적으로 NLLLoss 의 입력은 (로그) 우도여야 하지만, 파이토치는 이를 강제하지는 않는다는 점에 유의해야 한다. 따라서 원하는 성분을 가능한 한 크게 만드는 효과가 있다.
감소되지 않은 loss 즉, :attr:reduction 이 'none'으로 설정 되어 있으면, 다음과 같이 정의될 수 있다.
여기서 $N$은 배치 크기이다.
reduction이 'none' (기본 설정은 'mean')이 아니라면, 다음과 같다.
이 손실함수는 각 클래스에 가중치를 할당하는 선택적 인자인 weight을 가지고 있다. 이는 1D 텐서를 사용하여 전달할 수 있으며, 불균형한 훈련 세트를 다룰 때 유용하다.
가중치와 불균형한 클래스들에 대해서:
가중치 벡터는 각 범주 또는 클래스의 빈도가 다를 때 유용하다. 예를 들어, 일반 독감의 빈도는 폐암보다 훨씬 높다. 간단하게 적은 샘플을 가진 범주에 가중치를 늘려줄 수 있다.
그러나, 가중치를 주는 대신에 확률적 경사Stochastic Gradients를 더 잘 활용할 수 있도록, 훈련 빈도를 균등하게 하는 것이 더 좋다.
훈련 과정에서 각 클래스들을 균등하게 해주기 위해서, 다른 버퍼에 각 클래스의 샘플들을 넣어준다. 그리고 나서, 각 버퍼로부터 같은 수의 샘플을 추출하여 각 미니배치를 생성해준다. 작은 버퍼에서 사용할 샘플이 부족하면, 큰 클래스의 모든 샘플이 사용될 때까지 다시 처음부터 작은 버퍼를 반복한다. 이 방법은 순환 버퍼를 통해 모든 범주에 대해서 같은 빈도를 갖게 하는 방법이다. 빈도수를 균등하게 해주려고 주된 클래스의 모든 샘플을 사용하지 않는 것과 같은 쉬운 방법을 택해선 절대 안된다. 데이터를 남기지 말아야 한다.
위 방법의 명백한 문제점은 신경망 모델은 실제 샘플들의 상대적 빈도수를 모른다는 것이다. 이러한 문제를 풀기 위해서, 마지막에 실제 클래스 빈도로 약간의 epoch을 돌려 시스템을 미세조정Fine-tune한다. 그러면, 더 빈번한 것을 택하기 위해 시스템은 출력층의 편향Biases에 맞춘다.
이 방법에 대한 직관을 얻기 위해, 의과 대학의 예시로 돌아가 보자. 학생들은 자주 접하는 질병에 투자하는 시간 만큼 희귀 질병에 많은 시간을 할애한다. (혹은 희귀 질병이 보통 더 복잡하기 때문에 더 많은 시간을 투자한다.) 학생들은 모든 질병의 특징에 적응하기 위해 공부를 하고나서, 어떤 질병이 희귀한지 수정한다.
nn.CrossEntropyLoss()
이 함수는 nn.LogSoftmax와 nn.NLLLoss가 하나의 클래스로 구성되어 있다. 이 둘의 조합은 정확한 크래스에 대해서 더 큰 점수를 부여한다.
여기서 두 함수를 합친 이유는 경사를 연산함에 있어서 수치적 안정성을 위한 것이다. 소프트맥스를 거친 값이 1이나 0에 가까우면, 그 값에 로그를 취한 것은 0이나 $-\infty$에 가까워 질 수 있다. 0에 가까운 로그 값의 기울기는 $\infty$에 가까워지며, 역전파의 중간단계에서 수치적 문제를 발생시킨다. 두 함수가 합쳐지면, 경사는 포화되어 적당한 숫자를 얻게 된다.
각 클래스에 대한 입력 값은 정규화 되지 않은 점수일 것이다. 그 Loss는 다음과 같이 표현될 수 있다.
\[\text{loss}(x, c) = -\log\left(\frac{\exp(x[c])}{\sum_j \exp(x[j])}\right) = -x[c] + \log\left(\sum_j \exp(x[j])\right)\]또는 weight 인자가 구체화 된 경우에는 다음과 같다.
이 loss들은 각 미니배치에 대한 관찰을 통해 평균을 낸다.
크로스 엔트로피Cross Entropy Loss에 대한 물리적 해석은 두 분포 사이의 차이Divergence를 측정하는 쿨백-라이블러 발산KL divergence (Kullback–Leibler divergence )와 연관이 있다.
수학적으로는, 다음과 같다.
\[H(p,q) = H(p) + \mathcal{D}_{KL} (p \mid\mid q)\] \[H(p,q) = - \sum_i p(x_i) \log (q(x_i))\]이는 (두 분포 사이의) 크로스 엔트로피이다.
\(H(p) = - \sum_i p(x_i) \log (p(x_i))\) 는 엔트로피이고,
\(\mathcal{D}_{KL} (p \mid\mid q) = \sum_i p(x_i) \log \frac{p(x_i)}{q(x_i)}\)는 KL divergence이다.
nn.AdaptiveLogSoftmaxWithLoss()
이는 아주 많은(ex, 백만개) 클래스에 대한 소프트맥스의 Efficient softmax approximation이다. 이는 연산 속도를 향상시키기 위해서 몇가지 트릭을 이용해 구현한다.
자세한 방법은 Edouard Grave, Armand Joulin, Moustapha Cissé, David Grangier, Hervé Jégou의 Efficient softmax approximation for GPUs에 기술되어 있다.
📝 Haochen Wang, Eunkyung An, Ying Jin, Ningyuan Huang
Jinwoo Oh
13 April 2020