자기 지도 학습 - ClusterFit and PIRL
🎙️ Ishan Misra[“pretext” tasks에서 누락 된 것은 무엇인가? 일반화에 대한 희망] (https://www.youtube.com/watch?v=0KeR6i1_56g&t=3710s)
pretext task는 일반적으로 자기 감독되는 사전 훈련 단계로 구성되며 종종 분류 또는 감지인 Transfer Task가 있습니다. 사전 훈련 작업과 Transfer Task가 “정렬”되어 있기를 희망합니다. 즉, pretext task을 해결하는 것은 Transfer Task를 푸는데 큰 도움이 됩니다. 따라서 많은 연구가 pretext task을 설계하고 실제로 잘 구현하는 데 사용됩니다.
그러나 non-semantic task(pretext task)를 수행하는 것이 좋은 표현을 생성하는 이유는 매우 불분명합니다. 예를 들어, 직소 퍼즐과 같은 것을 풀면서 “Semantics”를 배우는 것을 기대할 수 있을까요? 또는 이미지에서 “해시 태그 예측”이 transfer tasks에서 분류기를 학습하는 데 도움이 될 것이라고 기대하는 이유는 무엇일까요? 따라서 문제가 남아 있습니다. Transfer Task와 잘 일치하는 좋은 사전 훈련 작업을 어떻게 설계할 것인가? 입니다.
이 문제를 평가하는 한 가지 방법은 각 레이어의 표현을 보는 것입니다 (그림 1 참조). 마지막 레이어의 표현이 transfer tasksㅇ허 잘 맞지 않으면 사전 훈련 작업이 해결하기에 적합한 작업이 아닐 수 있습니다.
그림 1: 각 Layer 별 Feature 표현
그림 2는 Jigsaw Pretraining을 사용하여 VOC07의 선형 분류기에 대한 각 레이어의 평균 정밀도Mean Average Precision를 나타냅니다. 마지막 레이어는 Jigsaw 문제에 매우 특수화 되어있음이 분명합니다.
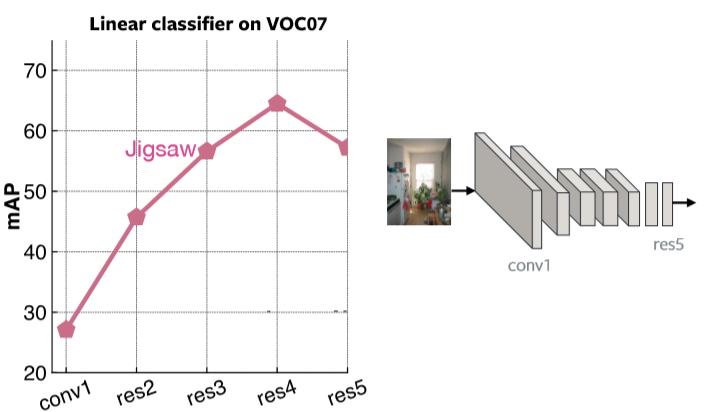
그림 2: 각 레이어별 Jigsaw Representation 성능
사전 학습 된 기능에서 우리가 원하는 것
-
이미지가 서로 관련되는 방식
- ClusterFit: 시각적 표현의 개선된 일반화 성능
-
“불변 요인”에 강건함robust - 불변성Invariance
-
예 : 물체의 정확한 위치, 조명, 정확한 색상
-
PIRL : Pre-text에 대해 Invariant Representations를 가지는 자기 지도 학습
-
위의 속성을 달성하는 두 가지 방법은 Clustering 및 Contrastive Learning 입니다. 그들은 지금까지 설계된 pretext tasks보다 훨씬 더 잘 수행하기 시작했습니다. 클러스터링에 속하는 한 가지 방법은 ClusterFit이고 불변성Invariance에 속하는 또 다른 방법은 PIRL입니다.
ClusterFit: 시각적 표현에 대한 일반화 성능 항샹
특징 공간의 클러스터링은 이미지가 서로 관련되어 있는지를 확인하는 방법입니다.
방법론
ClusterFit은 두 단계를 따릅니다. 하나는 클러스터 단계이고 다른 하나는 예측 단계입니다.
Cluster: 특징 클러스터링
사전 훈련 된 네트워크를 사용하여 일련의 이미지에서 여러 특징을 추출합니다. 네트워크는 모든 종류의 사전 훈련 된 네트워크(Classifcation-vgg, resnet 등등) 일 수 있습니다. 그런 다음 이러한 특징에 대해 K-평균 클러스터링이 수행되므로 각 이미지는 레이블이되는 클러스터에 속합니다.

그림 3: 클러스터 단계
Fit: 클러스터 레이블 예측
이 단계에서는, 네트워크를 처음부터 훈련하여 이미지의 pseudo 레이블을 예측합니다. 이러한 pseudo 레이블은 클러스터링의 첫 번째 단계에서 얻은 것입니다.
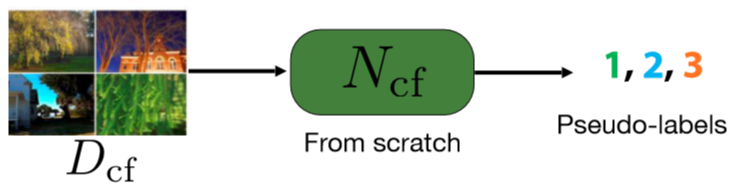
Fig. 4: Predict step
표준 사전 훈련 및 transfer task는 먼저 네트워크를 사전 훈련 한 다음 다운 스트림 작업에서 평가합니다. 그림 5의 첫 번째 행에 나와 있습니다. ClusterFit은 데이터 세트 $D_ {cf}$에서 사전 훈련을 수행하여 사전 훈련 된 네트워크 $N_{pre}$를 얻습니다. 사전 훈련 된 네트워크 $N_ {pre}$은 데이터 세트 $D_{cf}$에서 수행되어 클러스터를 생성합니다. 그런 다음이 데이터에서 새로운 네트워크 $N_ {cf}$를 처음부터 학습합니다. 마지막으로 모든 다운 스트림 작업에 $N_{cf}$를 사용합니다.
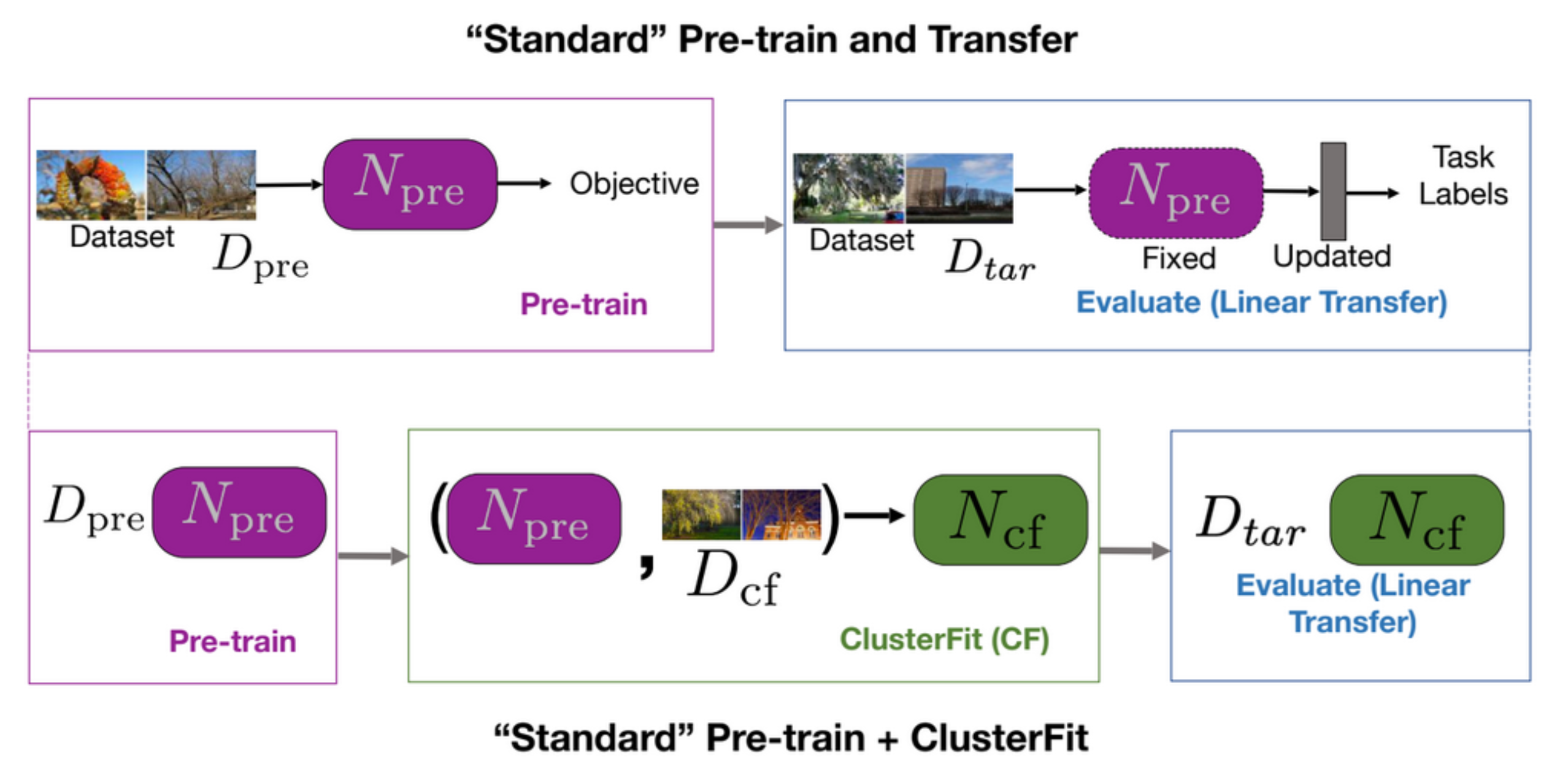
그림 5: 표준 사전학습 + transfer *vs.* 표준 사전학습 + ClusterFit
왜 ClusterFit이 작동하는가?
ClusterFit이 작동하는 이유는 클러스터링 단계에서 필수 정보만 캡처되고, 아티팩트가 폐기되어 두 번째 네트워크가 약간 더 일반화된 요소를 학습하기 때문입니다.
이 점을 이해하기 위해 매우 간단한 실험이 수행됩니다. ImageNet-1K에 레이블 노이즈를 추가하고, 이 데이터 세트를 기반으로 네트워크를 훈련시킵니다. 그런 다음 ImageNet-9K의 다운 스트림 작업에서이 네트워크의 기능 표현을 평가합니다. 그림 6에서 볼 수 있듯이 ImageNet-1K에 다른 양의 레이블 노이즈를 추가하고 ImageNet-9K에서 다양한 방법의 transfer 성능을 평가합니다.
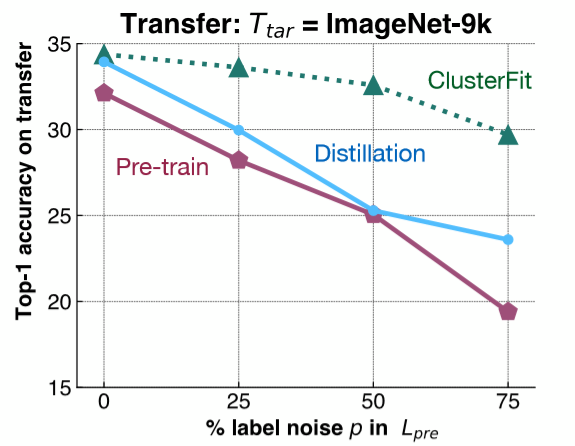
그림 6: 통제 실험
분홍색 선은 사전 훈련 된 네트워크의 성능을 나타내며 레이블 노이즈의 양이 증가함에 따라 감소합니다. 파란색 선은 초기 네트워크를 가져와 레이블을 생성하는 데 사용하는 model distillation를 나타냅니다. distillation는 일반적으로 사전 훈련 된 네트워크보다 성능이 좋습니다. 녹색 선인 ClusterFit은 이러한 방법 중 하나보다 지속적으로 낫습니다. 이 결과는 우리의 가설을 입증합니다.
- 질문 : 왜 비교를 위해 distillation 사용합니까?. distillation과 ClusterFit의 차이점은 무엇입니까?
model distillation에서 우리는 사전 훈련 된 네트워크를 가져 와서 네트워크가 더 부드러운 방식softer fashion으로 예측 한 레이블을 사용하여 이미지에 대한 레이블을 생성합니다. 예를 들어 모든 클래스에 대한 분포를 얻고, 이 분포를 사용하여 두 번째 네트워크를 훈련시킵니다. 더 부드러운 분포는 우리가 가지고있는 초기 클래스를 향상시키는 데 도움이됩니다. ClusterFit에서는 레이블 공간에 대해 신경 쓰지 않습니다.
성능
우리는 이 방법을 자기 지도 학습에 적용합니다. 여기서 Jigsaw는 ClusterFit에서 사전 훈련 된 네트워크 $N_{pre}$를 얻기 위해 적용됩니다. 그림 7에서 우리는 다른 데이터셋에 대한 transfer performance가 다른 자기 지도 방법에 비해 놀라운 성능 증가를 확인 할 수 있습니다.
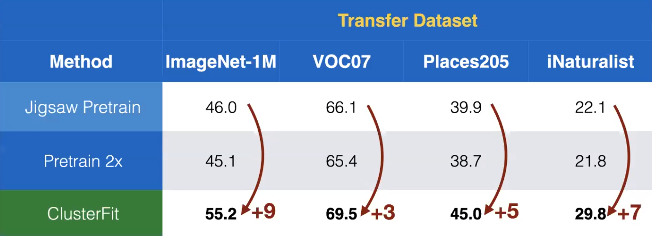
그림 7: 여러 데이터셋에 대한 Transfer 성능
ClusterFit은 사전 훈련 된 어떤 네트워크에서든지 작동합니다. 추가 데이터, 레이블 또는 아키텍처 변경없이 얻을 수 있는 이점이 있습니다. 이는 그림 8에서 볼 수 있습니다. 따라서 어떤 방식으로든 ClusterFit을 자기 지도 학습이 발생하는 fine-tuning 단계로 생각하여 표현의 성능을 향상시킬 수 있습니다.
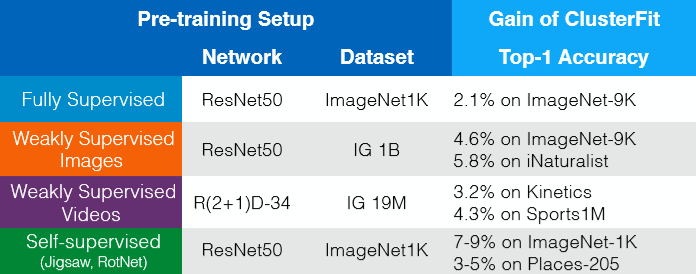
그림 8: 추가 데이터, 레이블 또는 아키텍처 변경없이 얻을 수 있는 이점
자기 지도 학습의 Pretext Invariant한 표현 (PIRL)
대조적 학습
대조적 학습은 기본적으로 결합하거나 관련이있는 포인트를 모아서 관련이없는 포인트를 밀어 낼 수있는 특징 공간을 학습하려는 일반적인 프레임 워크입니다.

그림 9: 관련되거나, 관련없는 이미지 그룹
이 경우 파란색 상자끼리 관계가 있고, 녹색끼리 관계가 있고, 보라색이 관계가 있다고 가정하겠습니다.
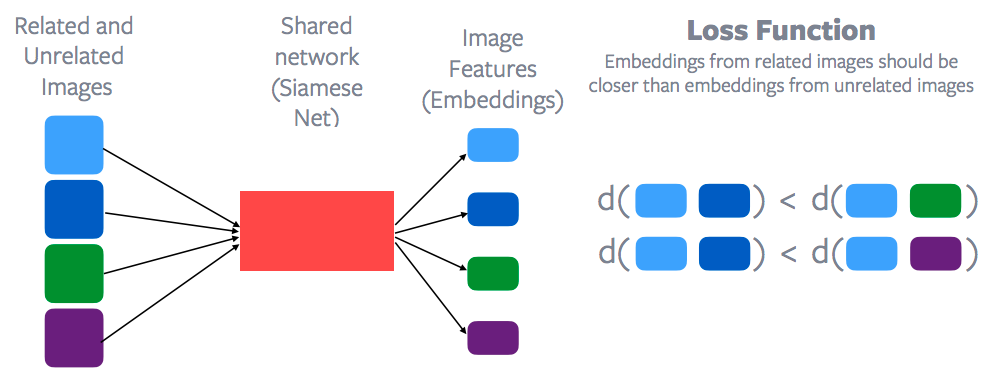
그림 10: 대조적 학습과 손실 함수
이러한 각 데이터 포인트에 대한 특징은 가중치를 공유하는 네트워크를 통해 추출되며, 각 데이터 포인트에 대한 이미지 특징을 얻기 위해 설계됩니다. 이 네트워크를 Siamese Network라고 합니다. 그런 다음 대비 손실 함수contrastive loss function를 적용하여 파란색 점과 녹색 점 사이의 거리를 멀게, 그리고 파란색 점끼리 사이의 거리를 가깝게 하려고 합니다. 또는 기본적으로 파란색 점끼리 거리는 파란색 점과 녹색 점 또는 파란색 점과 보라색 점 사이의 거리보다 작아야합니다. 따라서 관련 샘플의 임베딩 공간은 관련없는 샘플의 임베딩 공간보다 훨씬 가까워야 합니다. 이것이 바로 대조 학습에 대한 일반적인 설명입니다. 물론 Yann은 이 방법을 제안한 최초의 사람 중 한 명입니다. 그래서 대조적 학습은 이제 자기 지도 학습 아래서 부활하고 있습니다. 자기 지도 학습의 최신 방법들은 대부분은 실제로 대조적 학습을 기반으로합니다.
어떻게 관계있고 없는지를 정의하는가?
무엇이 관련되고 관련이 없는지 정의하는 방법은 중요한 질문입니다. 지도 학습의 경우에는 모든 개 이미지가 관련 이미지이고 개가 아닌 이미지는 기본적으로 관련없는 이미지입니다. 그러나, 이 경우 자기 지도 학습의 경우 관련성과 무관성을 정의하는 방법은 명확하지 않습니다. pretext task와 다른 주요 차이점은 대조 학습은 실제로 한 번에 많은 데이터에 (관련성을 정의하는데 있어서)근거를 둡니다reasons. 손실 함수를 보면 항상 여러 이미지가 포함됩니다. 첫 번째 행에는 기본적으로 파란색 이미지와 녹색 이미지가 포함되고 두 번째 행에는 파란색 이미지와 보라색 이미지가 포함됩니다. 하지만 직소 같은 작업이나 회전 같은 작업의 경우, 항상 단일 이미지에 대해 독립적으로 근거를 둡니다reasons. 이것이 대조 학습의 또 다른 차이점입니다: 대조 학습은 한 번에 여러 데이터 포인트에 대해서 근거를 둡니다reasons.
앞서 논의한 것과 유사한 기술을 사용할 수 있습니다: 비디오 프레임 또는 데이터의 순차적 특성. 비디오에서 근처에 있는 프레임은 관련이 있으며, 예를 들어 다른 비디오의 프레임이나 시간이 더 먼 프레임은 관련이 없습니다. 그리고 그것은 이 분야에서 많은 자기 지도 학습 방법의 기초를 형성했습니다. 이 방법을 CPC라고하는데, 이는 신호의 순차적 인 특성에 의존하는 대조적 예측 코딩contrastive predictive coding이며 기본적으로 시간 공간에서 같이 가까이있는 샘플은 관련이 있고 더 멀리 떨어져있는 샘플은 관련이 없다고 합니다. 기본적으로 이를 많이 사용하는 작업은: 음성 도메인, 비디오, 텍스트 또는 특정 이미지입니다. 그리고 최근에 우리는 비디오애 오디오가 함께 작업되기 때문에, 기본적으로 비디오에 있는 해당 오디오는 관련 샘플이고 다른 비디오의 비디오와 오디오는 기본적으로 관련이없는 샘플이라고 말합니다.
개체 추적
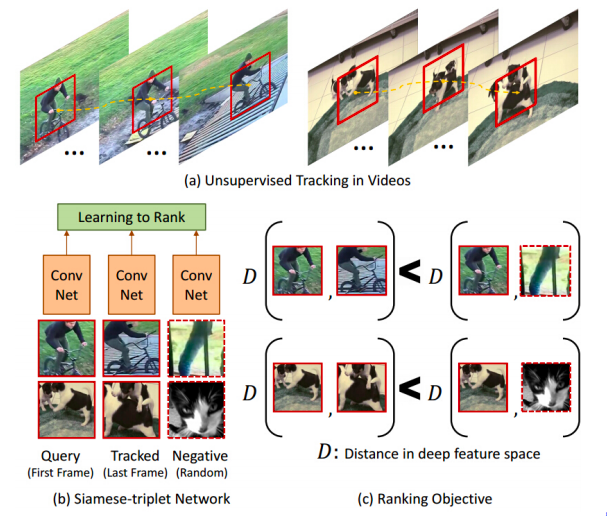
그림 11: 개체 추적
자기 지도 학습의 초기 작업 중 일부는 이 대조 학습 방법을 사용하며 관련 사례를 상당히 흥미롭게 정의했습니다. 비디오에서 추적 된 개체 추적기를 실행하면 움직이는 패치가 제공되며 추적기에 의해 추적 된 모든 패치가 원래 패치와 관련이 있다는 것입니다. 반면 다른 비디오의 패치는 관련 패치가 아닙니다. 따라서 기본적으로 관련있는 샘플과 관련없는 샘플을 모두 제공합니다. 그림 11(c)에는 이와 같은 거리 표기법이 있습니다. 이 네트워크가 배우려고하는 것은 기본적으로 동일한 비디오에서 나오는 패치는 관련이 있고 다른 비디오에서 나오는 패치는 관련이 없다는 것입니다. 어떤 방식으로든 물체의 다양한 포즈에 대해 자동으로 학습합니다. 강아지의 다른 자세, 사이클, 다른 각도에서 본 사이클을 각각 그룹화하려고합니다.
이미지의 가까운 패치 vs. 거리가 있는 패치
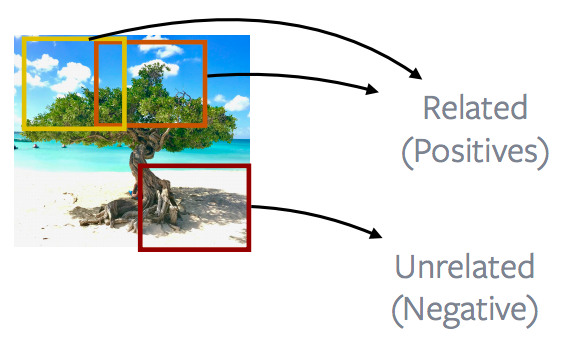
그림 12: 이미지의 가까운 패치 *vs.* 거리가 있는 패치
일반적으로 이미지에 대해 이야기하면, 가까운 이미지 패치와 먼 패치를 비교하는 데 많은 작업이 수행되므로 대부분의 CPC v1 및 CPC v2 방법은 이미지 속성을 실제로 활용하고 있습니다. 따라서 가까운 이미지 패치를 positive라고하고 더 멀리 떨어져있는 이미지 패치는 Negative로 번역되며, 목표는 이 positive 및 Negative 정의를 사용하여 대비 손실을 최소화하는 것입니다.
Patches of an image vs. patches of other images
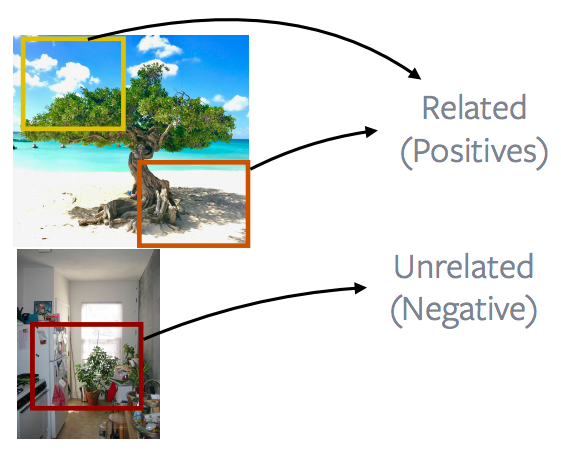
그림 13: 해당 이미지의 패치들 *vs.* 다른 이미지의 패치
이 작업에서 더 많이 쓰거나 성능이 좋은 방법은 이미지에서 가져온 패치(positive)를 보고 다른 이미지에서 가져온 패치(negative)와 대조하는 것입니다. 이것은 instance discrimination, MoCo, PIRL, SimCLR과 같은 많은 인기있는 방법의 기초를 형성합니다. 아이디어는 기본적으로 이미지 안에 무엇이 있는지를 보는 것입니다. 더 자세하게 말하자면, 이미지에서 완전히 임의의 패치를 추출하는 것입니다. 이러한 패치는 겹칠 수 있으며 실제로 서로 포함되거나, 완전히 분리 됩니다. 패치가 추출된 이후 일부 데이터는 augmentation를 적용 할 수 있습니다. 이 경우 색상을 변경하거나chattering 색상이 제거되는 등의 작업이 있습니다. 그리고 이 두 패치는 postive인 예로 정의됩니다. 다른 이미지에서 다른 패치가 추출됩니다. 그리고 이것 또한 임의의 패치이며 기본적으로 negative가됩니다. 그리고 이러한 방식을 활용하여 많은 negative 패치를 추출하고 기본적인 대조적 학습을 수행합니다. 따라서 학습 과정에서 두 개의 postive인 샘플이 추출되지만, negative 샘플은 더 많이 추출됩니다.
Pretext Tasks의 기본 원칙
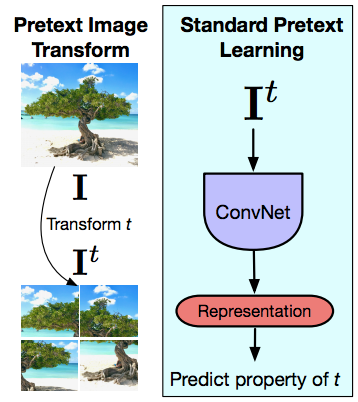
그림 14: Pretext 이미지 변환과 표준 Pretext 학습
이제 PIRL(Pretext Invariant Representations)로 이동하면서, pretext task의 주요 차이점이 무엇이며, 대조적 학습이 pretext task와 얼마나 다른지 이해하려고합니다. 다시 말하지만, pretext task은 항상 한 번에 하나의 이미지에 대하여 이루어 집니다. 따라서 아이디어는 이미지와 해당 이미지에 대한 대한 초기 변환prior transform(t) (이 경우 Jigsaw 변환)이 주어지면이 변환 된 이미지를 ConvNet에 입력으로 사용하고 적용한 변환의 속성을 예측하려고 시도하는 것입니다. 이때 회전 또는 색상과 관련된 변환을(예. 제거) 적용할 수 있습니다. 따라서 pretext task은 항상 단일 이미지에 대해 발생합니다. 두 번째 중요한 요소는, 수행하는 작업이 실제로 변환(t)의 일부 속성을 캡처해야한다는 것입니다. 따라서 적용되는 정확한 순열permutation 또는 적용되는 회전의 종류를 캡처해야합니다. 우리가 pretext task를 풀기위해서 노력하기 떄문에, 아키텍처의 마지막 레이어의 표현은 실제로 변환이 변경됨에 따라서 PIRL로 이동하게 됩니다. 그러나 불행히도 이것이 의미하는 것은 마지막 레이어 표현이 신호의 매우 낮은 수준의 속성low-level property을 캡처한다는 것입니다. 회전(t) 등을 캡처합니다. 실제 설계된 방향성이나 우리가 표현에 대해 기대하는 것은, 고양이가 똑바로 섰는지 또는 고양이가 말하든건 상관없이, 심지어 90도 정도 구부러져 있어도 고양이를 인식 할 수 있어야한다는 점입니다. 특정 pretext task을 해결할 때 이미지를 정 반대로 뒤집기도 합니다. 우리는 이 그림이 똑바로 세워져 있는지 아니면 이 그림이 기본적으로 옆으로 돌아가 있는지를 인식 할 수 있어야 합니다. 이러한 낮은 수준의 표현이 실제로 covariant 하기를 원하는 많은 예외가 있긴 합니다. 그 중 많은 부분이 3D의 예측 관련된 많은 작업과 관련이 있습니다. 예를들어 어떤 카메라 변환이 있는지 예측하고 싶은 경우: 동일한 물체에 대한 두 개의 뷰를 보고 있습니다. 그러나 많은 시맨틱 작업을 위한 특정 어플리케이션이 없는 경우 해당 입력을 사용하는 데 사용되는 변환(t)에 대해 불변invariant하고 싶을 것입니다.
불변성이 얼마나 중요한가?
불변성은 표현 학습의 word course였습니다. 예를들어, SIFT은 transferred invariant를 주입하는 handcrafted 표현이였습니다. 또한 AlexNets와 같은 지도 학습 네트워크는 데이터 증대에 대해서 invariant하게 학습됩니다. 이 네트워크가 입력에 적용된 변환이 정확히 무엇인지 예측하도록 요청하기보다는 이 나무 이미지의 크롭 또는 회전을 분류하기를 원합니다.
PIRL
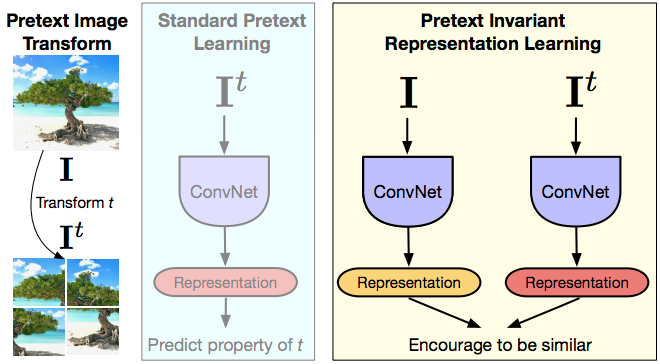
그림 15: PIRL
PIRL은 여기에 영감을 받습니다. 따라서 PIRL은 pretext 불변 표현 학습을 의미하며, 여기서 아이디어는 표현이 불변하거나 입력 변환(t)의 가능한 한 적은 정보를 캡처하기를 원한다는 것입니다. 따라서 이미지($I$)가 있고 이미지의 변형 된 버전($I^{t}$)이 있고 ConvNet을 통해 두 이미지를 모두 순전파하고 표현을 얻은 다음, 기본적으로 두 이미지의 표현이 유사하도록 만듭니다. 앞서 언급 한 표기법과 관련하여 이미지 $I$와 이미지의 pretext 변환 된 버전$I^t$ 은 관련있는(positive) 샘플이며 다른 이미지는 관련이 없는(negative) 샘플입니다. 따라서 이러한 방식으로이 네트워크를 구성 할 때 표현에는이 변환 $t$에 대한 정보가 거의 포함되지 않기를 바랍니다. 그리고 대조적 학습을 사용하고 있다고 가정해 봅시다. 따라서 대조적 학습은 기본적으로 원본 이미지 $I$에서 가져온 특징 벡터 $v_I$가 있고 변환 버전에서 오는 특징 벡터 $v_{I^t}$가 있습니다. 그리고 두 가지 표현이 모두 같기를 원합니다. 그리고 우리가 살펴본 논문은 pretext 변환 기술 두 가지를 언급합니다. 이것은 직소, 회전 방법입니다. 어떤 면에서 이것은 멀티 태스킹 학습과 비슷하지만 실제로 설계된 회전을 모두 예측하려고하는 것은 아닙니다. 당신은 직소 회전에 불변하려고 노력하고 있습니다.
많은 수의 Negatives 사용하기
과거 대조적 학습이 잘 작동하도록 만든 핵심은 많은 양의 negative 샘플을 성공적으로 사용한 것입니다. One of the good paper은 메모리 뱅크라는 개념을 도입 한 2018년 인스턴스 판별 논문입니다. 이것은 매우 강력함을 가지고,대부분의 최신 연구 방법이 메모리 뱅크에 대한 아이디어에 달려 있습니다. 메모리 뱅크는 컴퓨팅 요구 사항을 실제로 늘리지 않고도 많은 수의 negative 샘플을 얻을 수있는 좋은 방법입니다. 여러분이 하는 일은 이미지 당 특징 벡터를 메모리에 저장 한 다음 그 특징 벡터를 대조적 학습에 사용하는 것입니다.
어떻게 작동하는가?
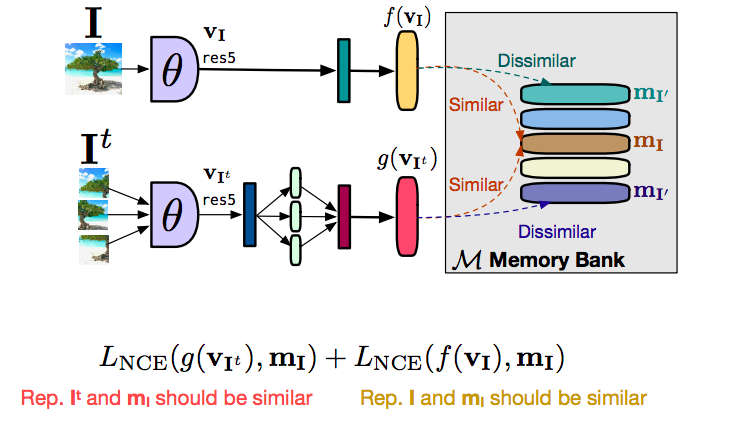
그림 16: Memory Bank의 작동방식
먼저 메모리 뱅크를 사용하지 않고 전체 PIRL 설정을 셋업하는 방법에 대해 이야기하겠습니다. 따라서 이미지 $I$가 있고 이미지 $I^t$가 있습니다.이 두 이미지를 모두 순전파하면 원본 이미지 $I$에서 특징 벡터 $f(v_I)$를 얻게됩니다. 변환한 버전을 봅시다. 이 경우 패치의 특징 벡터는 $g(v_{I^t})$가 됩니다. 우리가 원하는 것은 $f$와 $g$가 비슷한 것입니다. 그리고 다른 관련없는 이미지의 특징 벡터는 기본적으로 유사하지 않기를 원합니다. 우리가 많은 negative 이미지를 원할 경우, negative 이미지를 동시에 순전파하기를 원할 것입니다. 이는 실제로 매우 큰 배치 크기가 필요하다는 것을 의미합니다. 물론, 제한된 양의 GPU 메모리에서 큰 배치가 가능하지 않은 경우, 큰 배치는 좋은 해결책이 아닙니다. 이를 해결하는 방법은 메모리 뱅크라는 것을 사용하는 것입니다. 따라서 메모리 뱅크가 하는 일은 데이터 세트의 각 이미지에 대한 특징 벡터를 저장하고 대조적 학습을 수행합니다. 다른 negative image나 배치 내 다른 이미지의 특징백터를 사용하는 것이 아니기 때문에, 메모리에서 특징 펙터를 검색하는 방식입니다. 메모리에서 관련되지 않은 다른 이미지(negative)의 특징 벡터을 검색 할 수 있으며 이를 대체substitute하면서 대조적 학습을 수행 할 수 있습니다. 이미지 객체를 두 부분으로 나누기 만하면 변환 된 이미지 $g(v_I)$에서 특징 벡터를 가져 오는 contrasting term이 있는데, 이는 메모리에 있는 $m_I$ 표현과 유사합니다. 유사하게, $f(v_I)$ 특징 벡터를 메모리에있는 특징 표현과 가깝게 가져 오려는 두 번째 contrasting term가 있습니다. 본질적으로 $g$는 $m_I$에 가깝게 당겨지고 $f$는 $m_I$에 가깝게 당겨집니다. 전이성transitivity에 의해 $f$와 $g$가 서로 가깝게 당겨지고 있습니다. 그리고 이것을 분리 한 이유는 훈련이 안정되었고 이것을 하지 않고는 훈련을 할 수 없었기 때문입니다. 기본적으로 훈련은 실제로 수렴되지 않습니다. $f$와 $g$ 사이에 직접 대조적 학습을하는 대신 이것을 두 가지 형태로 분리함으로써 우리는 훈련을 안정화하고 실제로 작동시킬 수있었습니다.
PIRL 사전 학습
평가하는 방법은 기본적으로 일반적인 사전 교육 평가 방법론 셋업을 사용하는 것입니다. transfer learning의 경우 레이블이 없는 이미지에 대해 사전 학습 할 수 있습니다. 방법은 Image net을 통해 이미지의 레이블을 버리고 비 지도 학습으로 학습된 것처럼 사용하는 것입니다.
평가
평가는 full fine-tuning (초기화 평가) 또는 선형 분류기 훈련 (특성 평가)으로 수행 할 수 있습니다. PIRL 견고성은 in-the-wild 이미지로 훈련시키고, 해당 훈련 데이터의 in-distribution 이미지를 사용하여 테스트되었습니다. 그래서 우리는 YFCC 데이터 세트인 Flickr에서 선택 된 무작위로 백만 개의 이미지를 사용합니다. 그런 다음 기본적으로 이 이미지에 대해 사전 훈련을 수행 한 다음 다른 데이터 세트에 이식을 수행했습니다.
물체 감지 평가
PIRL은 처음에 물체 감지 작업 (비전의 표준 작업)에 대해서 평가되었으며 VOC07+12 및 VOC07 데이터 세트 모두에서 ImageNet에 대해 지도학습 방법으로 사전 학습된 네트워크를 능가 할 수 있었습니다. 실제로 PIRL은 더 엄격한 평가 기준 인 $AP^{all}$에서도 성능이 뛰어 났으며 이는 긍정적인 신호입니다.
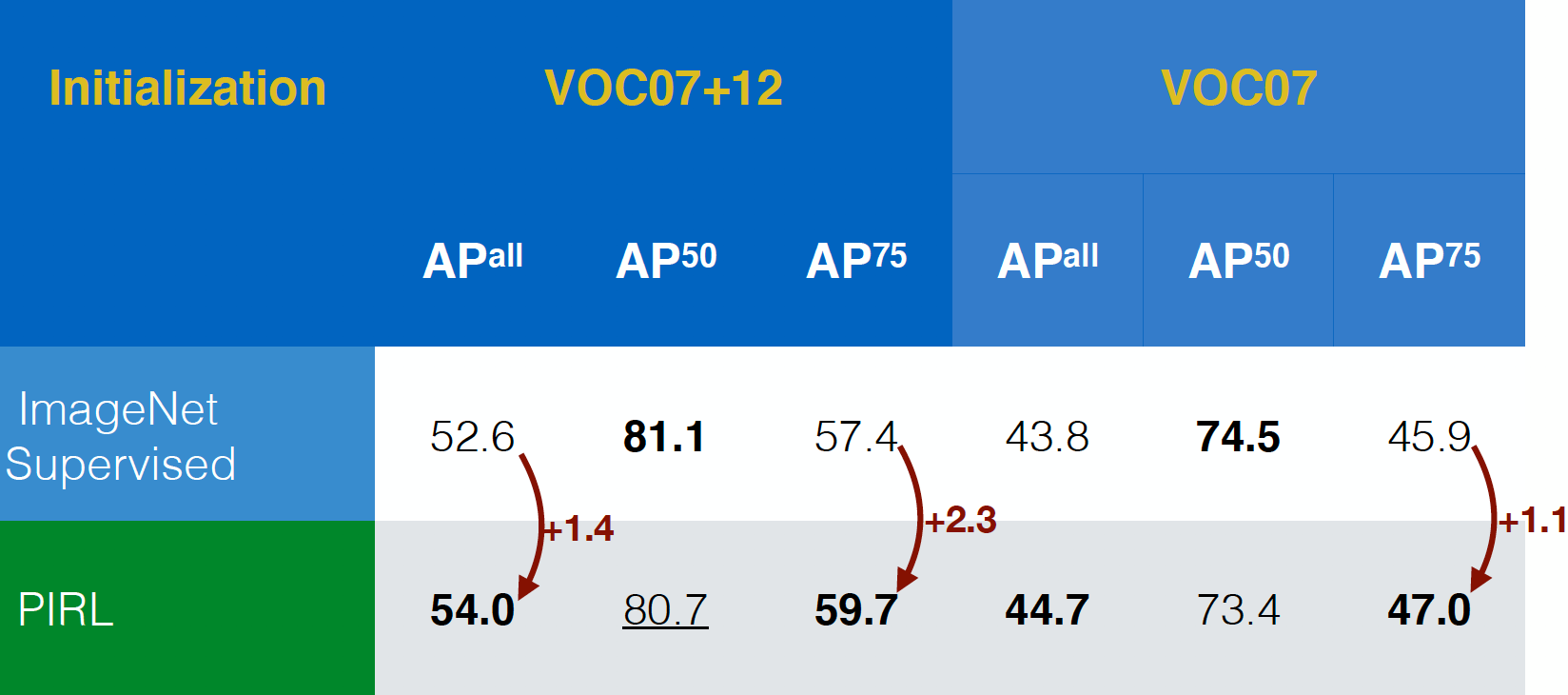
그림 17: 다양한 데이터 세트의 물체 감지 성능
준 지도 학습 평가
PIRL은 준지도 학습semi-supervised learning 과제에서 평가되었습니다. PIRL은 상당히 잘 수행되었습니다. 사실, PIRL은 Jigsaw의 사전 텍스트 작업보다 좋은 성능을 보입니다. 첫 번째 행과 마지막 행의 유일한 차이점은 PIRL은 불변 버전invariant version이고 Jigsaw는 공변 버전covariant version이라는 것입니다.
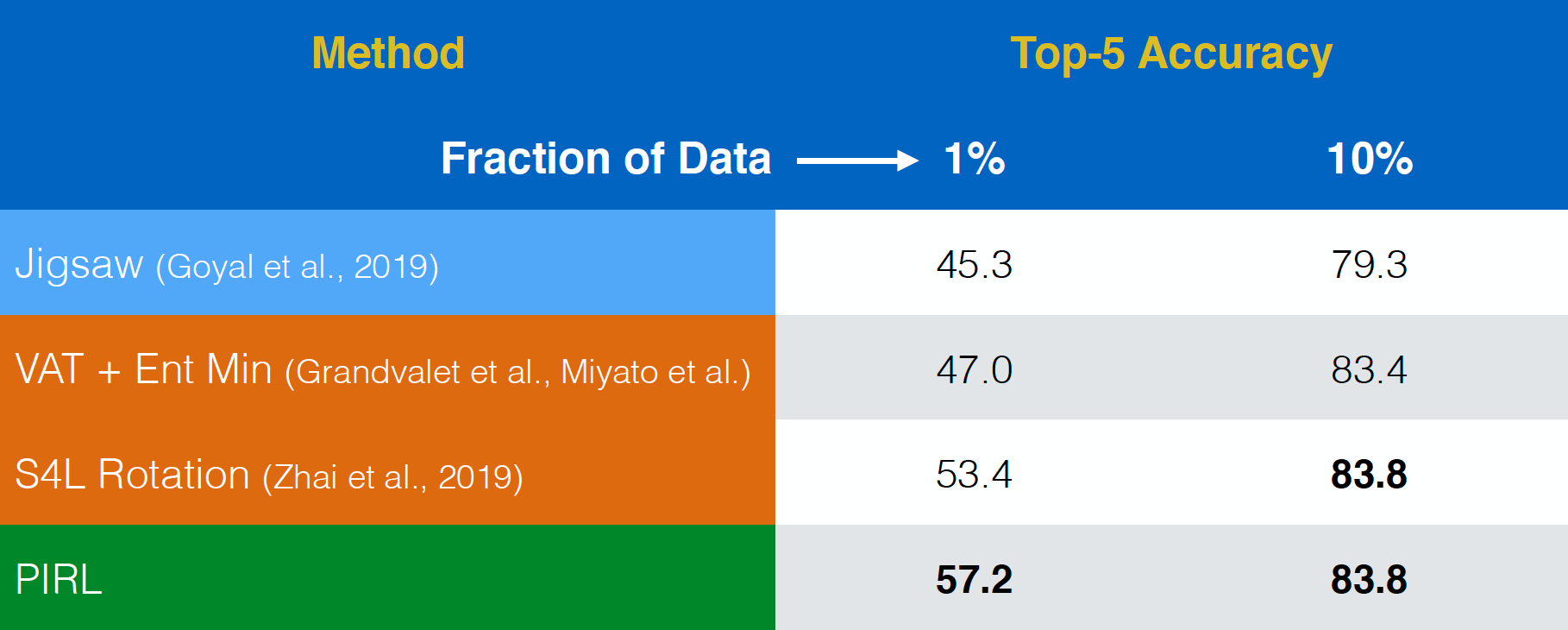
그림 18: ImageNet에서 준 지도 학습
선형 분류기를 통한 평가
이제 선형 분류기에서 평가할 때, PIRL은 실제로 CPCv2의 성능과 비슷했습니다. 또한 여러 매개 변수 설정과 여러 다른 아키텍처에서 잘 작동했습니다. 물론 SimCLR과 같은 방법으로 상당히 좋은 성능을 얻을 수 있습니다. 사실, SimCLR의 Top-1 정확도는 약 69-70이고 PIRL의 경우 약 63입니다.
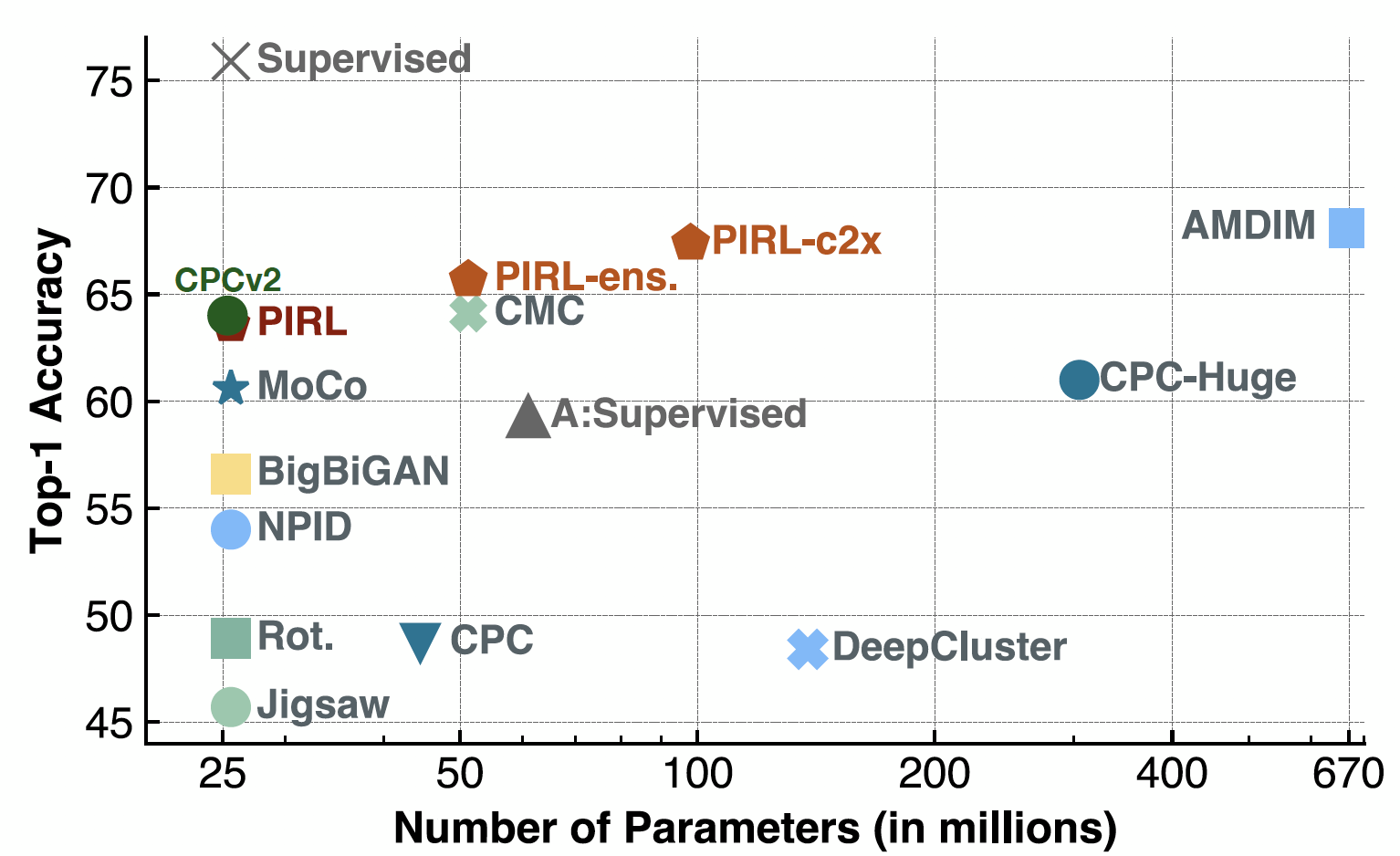
Fig. 19: 선형 모델을 사용한 ImageNet 분류
YFCC 이미지 평가
PIRL은 YFCC 데이터 세트의 “In-the-wild”Flickr 이미지에서 평가되었습니다. 데이터 세트가 $100$ 배 더 작아도 Jigsaw보다 더 나은 성능을 발휘할 수있었습니다. 이것은 pre-text 작업을 예측하는 것이 아니라 pre-text 작업의 표현에 대해 불변성invariance을 고려하는 힘을 보여줍니다.
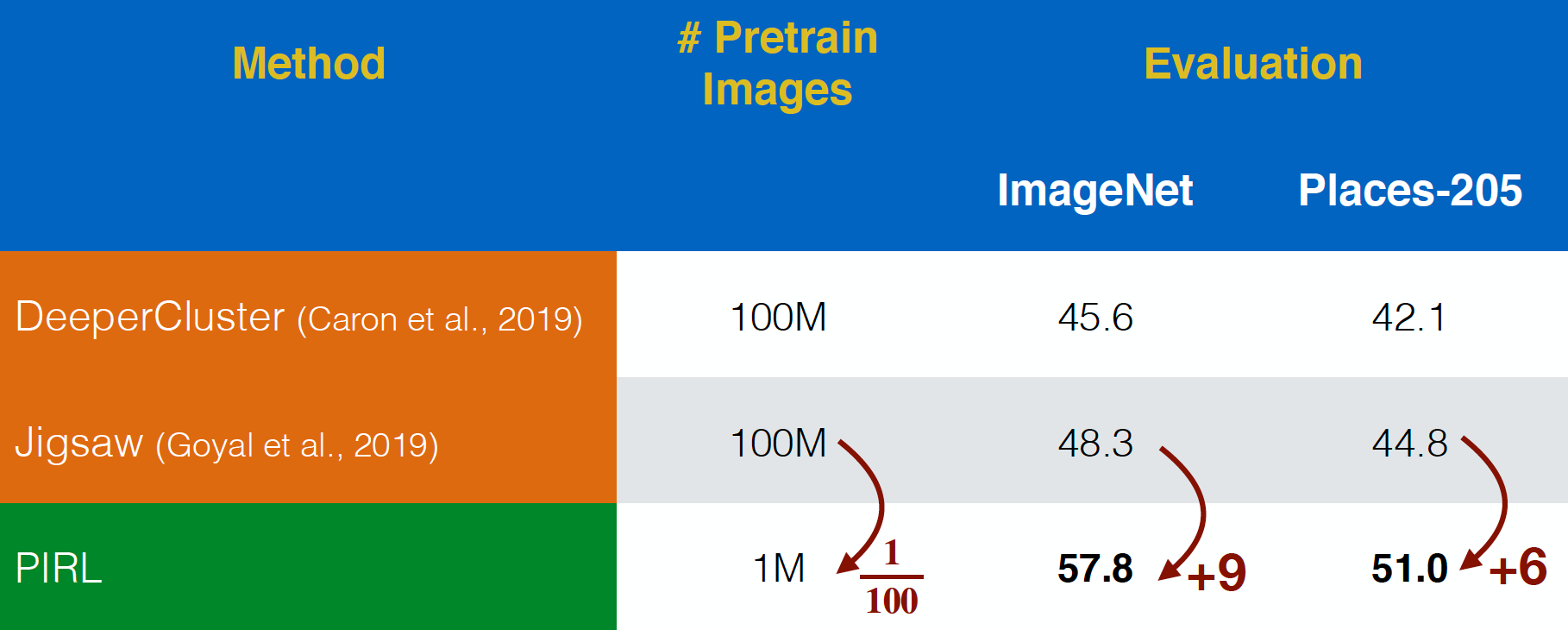
그림 20: 큐레이팅 되지 않은 YFCC images에 대한 사전 학습
의미론적 특징
이제 의미론적 특징을 확인하러 가봅시다. ‘conv1’에서 ‘res5’까지 다양한 표현 계층에 대한 PIRL 및 Jigsaw의 Top-1 정확도를 살펴 봅니다. PIRL과 Jigsaw 모두에 대해 서로 다른 레이어에 대해 정확도가 계속 증가하지만 Jigsaw의 5 번째 레이어에서 떨어집니다. 반면, 정확도는 PIRL에 대해 계속 개선되고 있습니다.
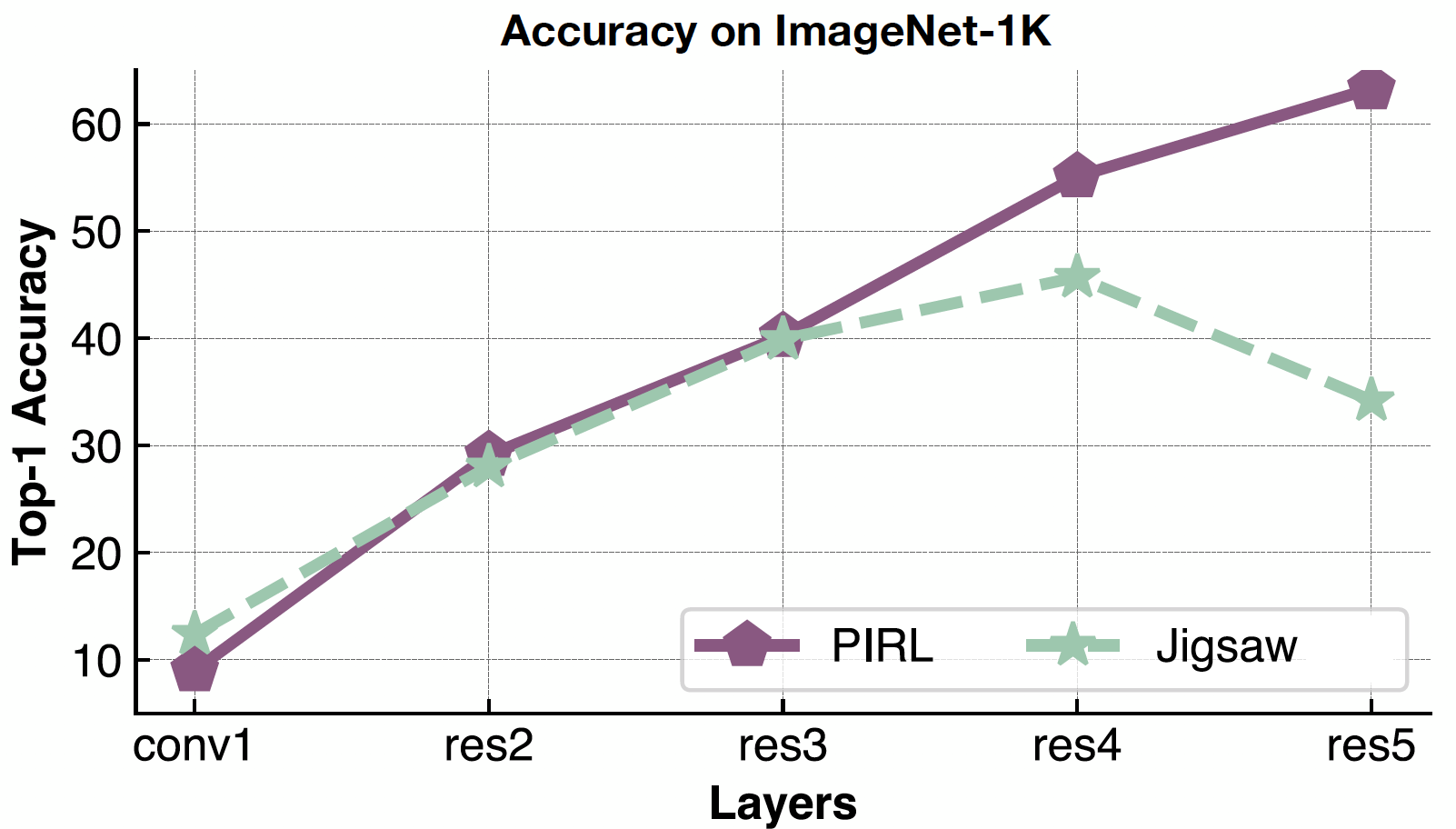
그림 21: 레이어 당 PIRL 표현 퀄리티 확인
확장성
PIRL은 순열의 수를 예측하지 않고 입력으로 사용하기 때문에 문제 복잡성을 처리하는 데 매우 유용합니다. 따라서 PIRL은 9개 패치에서 가능한 모든 순열 362,880 개로 쉽게 확장 할 수 있습니다. 반면에 Jigsaw에서는 예측하기 때문에 출력 공간의 크기에 제한을 받습니다.
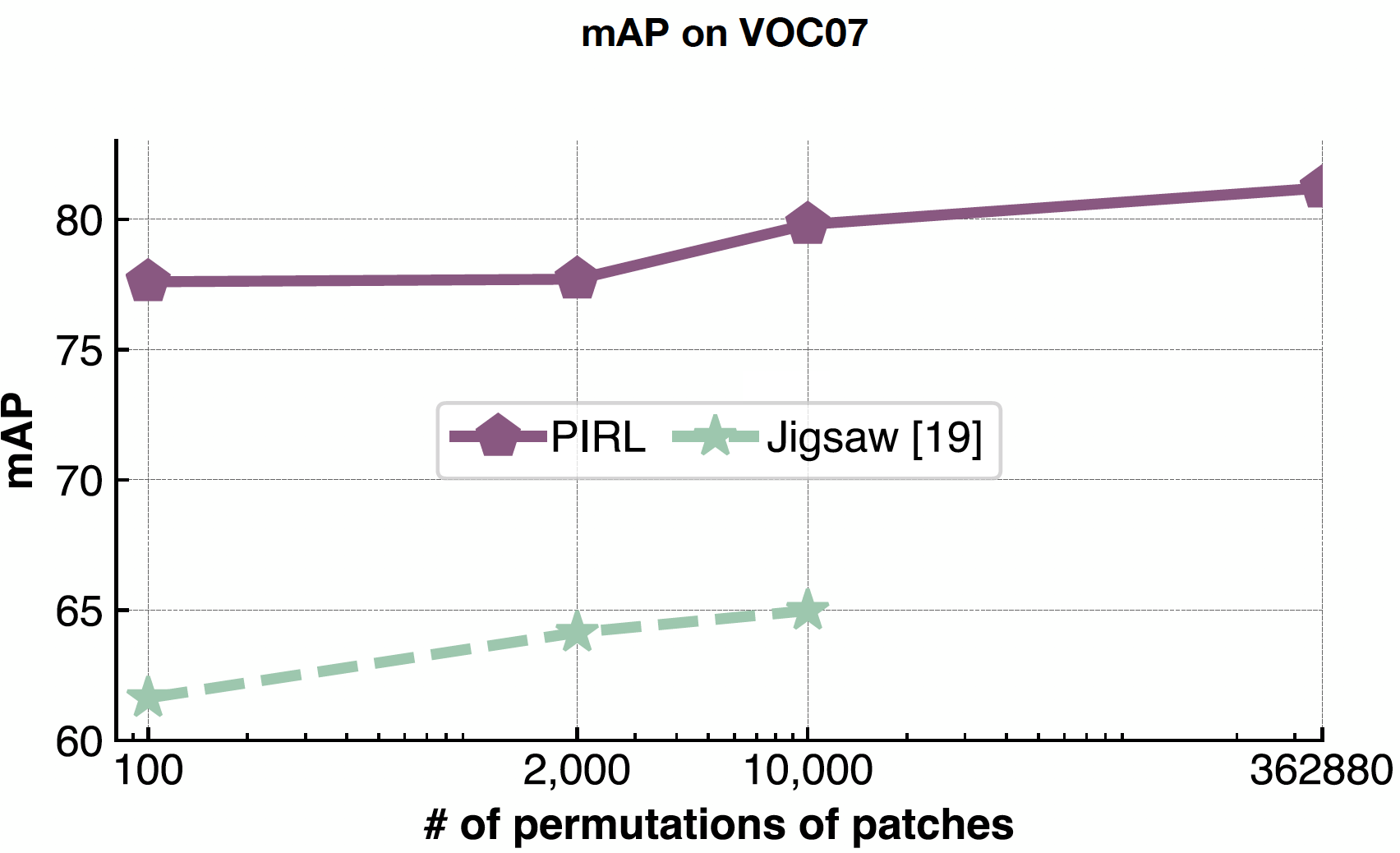
그림 22: 다양한 패치 순열 수의 영향
논문 “Misra & van der Maaten, 2019, PIRL“은 PIRL을 Jigsaw, Rotations 등과 같은 다른 pretext tasks으로 쉽게 확장 할 수있는 방법을 보여줍니다. 또한 Jigsaw + Rotation과 같은 작업의 조합으로 확장 할 수도 있습니다.
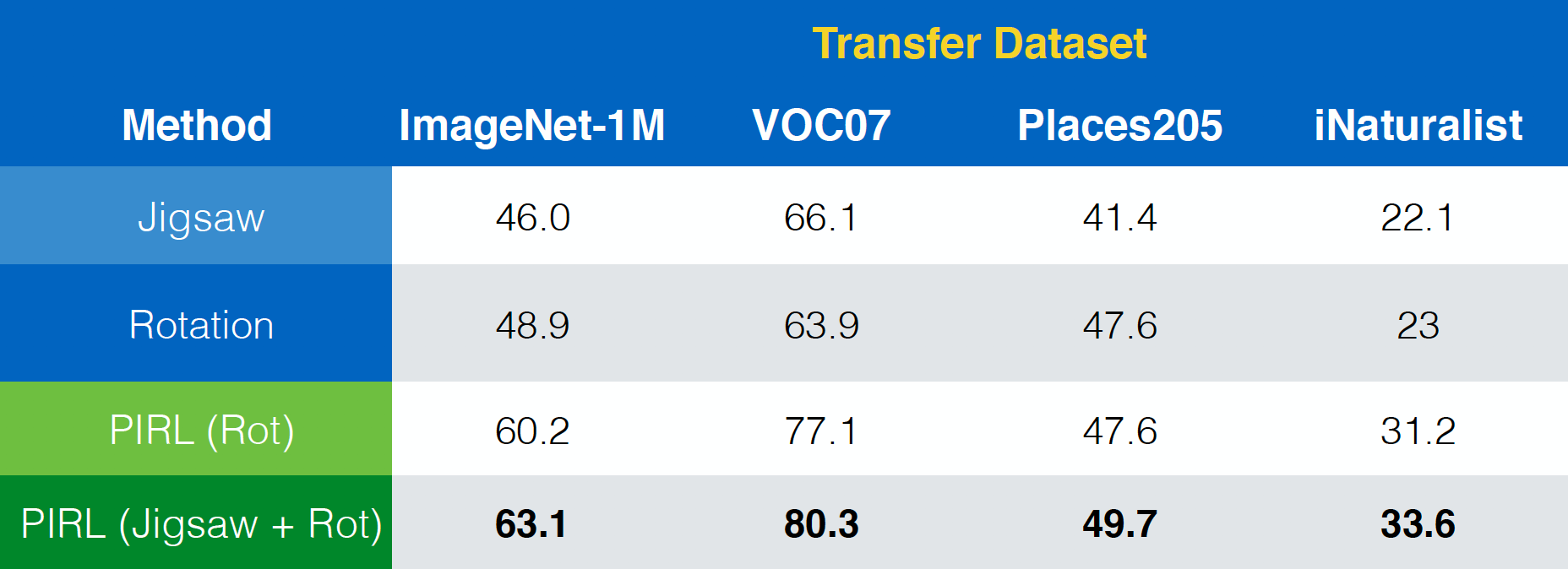
그림 23: 서로 다른 pretext tasks(조합)과 함께 PIRL 사용
불변성 vs. 성능
불변성Invariance의 관점에서 일반적으로 PIRL의 불변이 클러스터링의 불변보다 크다고 주장 할 수 있으며, 또한 pretext tasks보다 불변성이 더 큽니다. 마찬가지로 PIRL의 성능은 클러스터링보다 높으며, 이는 pretext tasks보다 성능이 높습니다. 이것은 방법론에 더 많은 불변성을 취하는 것이 성능을 향상시킬 수 있음을 의미합니다.
단점
- 어떤 데이터 변환이 중요한지 명확하지 않습니다. Jigsaw가 작동하지만 작동하는 이유는 명확하지 않습니다.
- 모델 크기 및 데이터 크기의 포화Saturation
- 어떤 불변성이 중요할까요? (일반적으로 특정 지도 학습 작업에 대해 어떤 불변성이 작동하는지 생각할 수 있습니다.)
그래서 일반적으로 우리는 점점 더 많은 정보를 예측하고 가능한 한 불변성을 유지하려고 노력해야합니다.
의심스러운 몇 가지 중요한 질문
대조적 학습 및 배치 정규화
- 대조적 네트워크가 배치 정규화 레이어를 사용하는 경우 (정보가 한 샘플에서 다른 샘플로 전달되므로) 네트워크는 네거티브와 긍정을 분리하는 아주 간단한 방식으로 학습하지 않습니까?
Ans : PIRL에서는 배치 정규화를 사용했을 때 이러한 현상이 관찰되지 않았습니다.
- 대조적 네트워크에 대해 배치 정규화를 사용하는 것이 괜찮습니까?
Ans : 일반적으로 괜찮습니다. SimCLR에서는 일반적인 배치 정규화의 변형을 사용하여 큰 배치 크기를 에뮬레이션emulate합니다. 따라서 약간의 조정이있는 배치 정규화를 사용하여 학습을 더 쉽게 만들 수 있습니다.
- 배치 정규화가 PIRL 논문에서 작동하는 이유는 메모리 뱅크로 구현 되었기 때문입니까? - 즉, 모든 표현이 동시에 사용되지 않기 때문입니까? (예를 들어, 배치 정규화는 MoCo 논문에서 특별히 사용되지 않기 때문에)
Ans : 예. PIRL에서 동일한 배치에는 모든 표현이 없으며 배치 정규화가 작동하는 이유가 여기 있습니다. 배치 내에서 표현이 모두 상관 관계가있는 다른 작업에는 해당되지 않을 수 있습니다
- 메모리 뱅크 외에 n-pair 손실과 같은 다른 제안이 있습니까? AlexNet 또는 배치 정규화를 사용하지 않는 다른 네트워크를 사용해야하나요? 아니면 배치 정규화 레이어를 해제하는 방법이 있습니까? (이것은 비디오 학습 작업입니다).
Ans : 일반적으로 프레임은 동영상에서 상관 관계가 있으며 상관 관계가 있을 때 배치 정규화 성능이 저하됩니다. 또한, AlexNet의 가장 간단한 구현조차도 실제로 배치 정규화을 사용합니다. 왜냐하면 배치 정규화으로 훈련하면 훨씬 더 안정적이기 때문입니다. 더 높은 학습률을 사용할 수도 있고 다른 다운 스트림 작업에도 사용할 수 있습니다. 비디오 학습 작업에 대해서는 배치 크기에 의존하지 않는 그룹 정규화와 같은 배치 정규화의 변형을 사용할 수 있습니다
PIRL의 손실 함수
- PIRL에서 왜 NCE(Noise Contrastive Estimator)가 손실을 최소화하는 데 사용됩니까? 데이터 분포의 negative probability를 쓸수 있지 않습니까? $h(v_{I}, v_{I^{t}})$?
Ans : 실제로 둘 다 사용할 수 있습니다. NCE를 사용하는 이유는 메모리 뱅크 논문의 셋업과 더 관련이 있습니다. $k+1$ 네거티브를 사용하면 $k+1$ 이진 문제를 푸는 것과 같습니다. 이를 수행하는 또 다른 방법은 소프트 맥스를 사용하는 것입니다. 소프트 맥스를 적용하는 경우 음의 로그 가능도negative log-likelihood를 최소화합니다
자기 지도 학습 프로젝트 팁
간단한 자기 감독 모델이 작동하도록하려면 어떻게 해야합니까? 구현을 어떻게 시작합니까?
Ans : 초기 단계에 유용한 특정 종류의 기술이 있습니다. 예를 들어, pretext task을 볼 수 있습니다. 회전은 구현하기 매우 쉬운 작업입니다. 움직이는 조각의 수는 일반적으로 좋은 지표입니다. 기존 방법을 구현할 계획이라면 저자가 언급 한 세부 사항 예 : 사용 된 정확한 학습률, 배치 정규화가 사용 된 방식 등)을 자세히 살펴 봐야 할 수 있습니다. 이런 실험 디테일이 많을 수록 구현이 더 어렵습니다. 다음으로 고려해야 할 매우 중요한 사항은 데이터 증대data augmentation입니다. 무언가 작동하는 것을 구현했다면, 그 다음은 있으면 더 많은 데이터 증대data augmentation를 추가하십시오.
생성 모델
생성 모델을 대조적 네트워크와 결합 할 생각이 있나요?
Ans : 일반적으로 좋은 생각입니다. 그러나 모델을 훈련하는 것이 까다롭고 사소하지 않기 때문에 부분적으로 구현되지 않았습니다. 통합 접근 방식은 구현하기가 더 어렵지만 미래로 가는 길일 수도 있습니다.
Distillation
더 부드러운 분포에 의해 더 다양한 타겟이 제공 될 때 모델의 불확실성이 증가하지 않을까요? 또한 Distillation라고 하는 이유는 무엇입니까?
Ans : 하나의 one-hot 레이블로 학습하는 경우 모델이 레이블에 과도하게 집중overconfident하는 경향이 있습니다. 이를 위해 레이블 스무딩과 같은 트릭이 일부 방법에서 사용됩니다. 레이블 스무딩은 one-hot vector를 예측하려는 단순한 distillation 버전입니다. 이제 전체 one-hot를 예측하는 대신 확률 질량probability mass를 예측합니다. 이는 1과 0을 예측하는 대신 $0.97$를 예측 한 다음 $0.01$을 더합니다. 나머지 벡터에도 $0.01$ 균일하게 더해 줍니다. distillation는 더 많은 정보를 가지고 하는 방법일 뿐입니다. 관련없는 작업의 확률을 무작위로 높이는 대신, 레이블 스무딩을 더 잘 수행 할 수 있는 사전 훈련 된 네트워크가 있습니다. 일반적으로 더 부드러운 분포는 사전 훈련 방법에서 매우 유용합니다. 모델은 지나치게 확신하는 경향이 있으므로 부드러운 분포를 통해 학습시키는 것이 더 쉽습니다. 그들은 또한 더 빨리 수렴합니다. distillation은 이러한 이점이 있습니다.
📝 Zhonghui Hu, Yuqing Wang, Alfred Ajay Aureate Rajakumar, Param Shah
SeungHeon
6 Apr 2020