자기 지도 학습 - Pretext Tasks
🎙️ Ishan MisraSupervision의 성공적인 사례: 사전 학습
지난 10 년 동안 다양한 컴퓨터 비전 문제의 주요 성공 비결 중 하나는 이미지넷ImageNet 분류에 대해 지도 학습을 수행하여 시각적 표현을 학습하는 것이었습니다. 그리고 이러한 학습 된 표현 또는 학습 된 모델 가중치를 대량의 레이블이 지정된 데이터를 사용할 수 없는 다른 컴퓨터 비전 작업에 대한 초기화 값으로 사용하였습니다.
그러나 이미지넷ImageNet 규모의 데이터셋에 대한 주석annotation을 가져 오는 것은 엄청난 시간과 비용이 듭니다. 예시: 1,400 만 개의 이미지로 이미지넷ImageNet 라벨링하는 데 대략 22년이 걸렸습니다.
이 때문에 딥러닝 커뮤니티는 소셜 미디어 이미지에 대한 해시태그, GPS 위치, 또는 레이블이 데이터 샘플 자체인 속성을 가지는 자기 감독self-supervised 방식과 같은 대체 레이블 지정 프로세스를 찾기 시작했습니다.
그러나 대체 라벨링 프로세스를 찾기 전에, 중요한 질문이 발생합니다.
결국 레이블이 지정된 데이터를 얼마나 얻을 수 있는가?
- 물체 단위 카테고리Object-level category 및 바운딩 박스 주석bounding box annotations이있는 모든 이미지를 검색하면 대략 1백만 개의 이미지가 있습니다. -이제 바운딩 박스 좌표bounding box coordinates에 대한 제약이 완화되면 사용 가능한 이미지 수가 약 1,400 만 개로 늘어납니다 (대략). -하지만 인터넷상에서 볼 수있는 모든 이미지를 고려하면 사용 가능한 데이터 양이 5베 급증합니다. -그리고 이미지와는 별개의 데이터가 있습니다. 포착하거나 이해하기 위해서는 다른 감각적인 입력이 필요합니다.
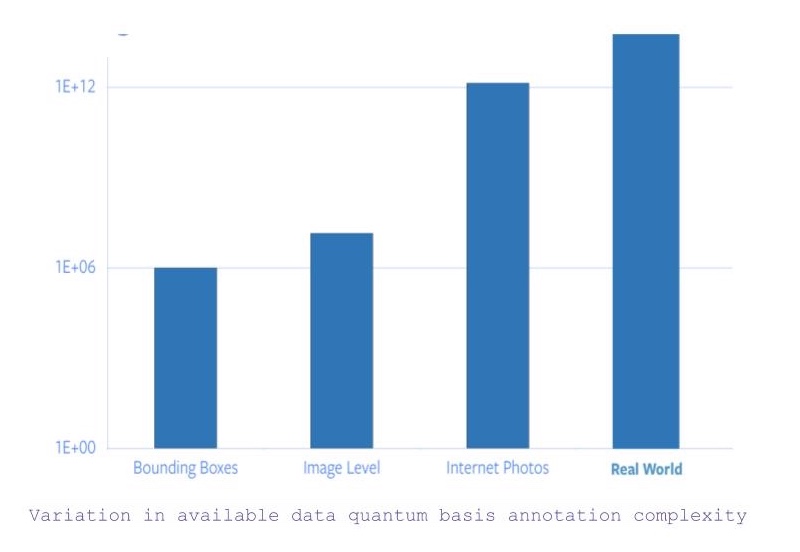
Figure 1: 사용 가능한 데이터에 대한 주석의 양자 기반 복잡성quantum basis complexity 변화
따라서 이미지넷ImageNet 특정 주석만으로는 22 년의 시간이 걸린다는 사실을 바탕으로, 라벨링을 모든 인터넷 사진 또는 그 이상으로 확장하는 것은 완전히 불가능합니다.
희귀 개념의 문제 (롱테일 문제)
일반적으로, 인터넷 이미지에 대한 레이블 분포를 나타내는 플롯은 긴 꼬리처럼 보입니다. 즉, 많은 이미지가 존재하지 않는 엄청난 수의 레이블들이 존재하는데 반면, 대부분의 이미지들은 매우 적은 레이블로 표현됩니다. 따라서 꼬리 끝 부분의 카테고리에 대한 주석이 달린 샘플을 얻으려면 레이블이 지정 될 엄청난 양의 데이터가 필요합니다.
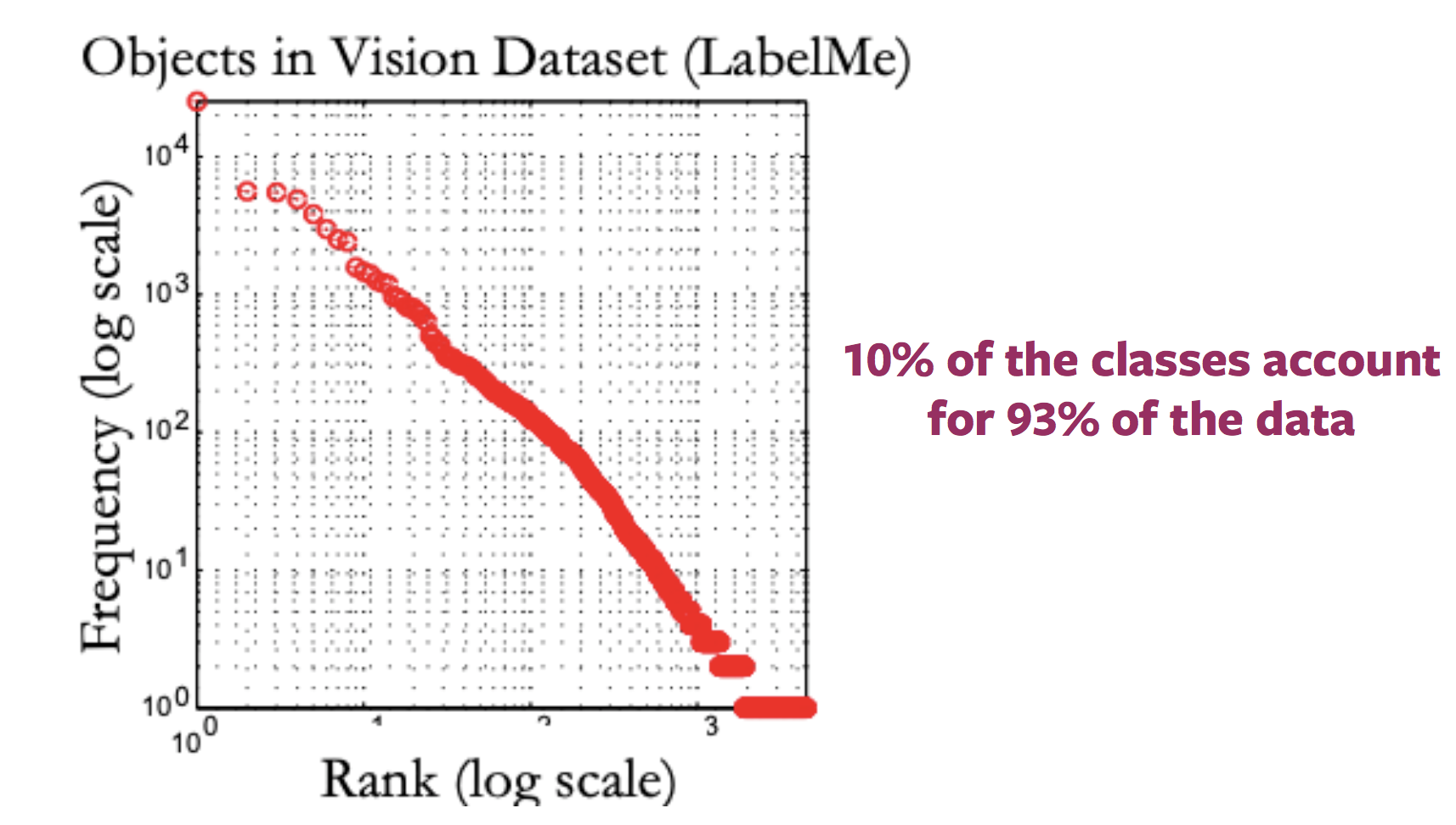
Figure 2: 라벨이 있는 사용 가능한 이미지 분포의 변화
다른 도메인의 문제
downstream 작업에 대한 ImageNet 사전 훈련pre-training 및 미세 조정fine-tuning방법은, 이미지가 의료 영상과 같이 완전히 다른 도메인에 속할 때 더욱 모호해집니다. 그리고 다른 도메인에 대한 사전 훈련pre-training을 위해 ImageNet 정도의 양을 가진 데이터 셋을 얻는 것은 불가능합니다.
자기 지도 학습이란 무엇인가?
자기 지도 학습을 정의하는 두 가지 방법
- 기본 지도 학습 정의, 즉 네트워크는 사람의 입력없이 반 자동 방식으로 레이블을 얻는 지도 학습을 따릅니다.
- 예측 문제, 데이터의 일부가 숨겨져 있고 나머지는 표시됩니다. 따라서 목표는 숨겨진 데이터를 예측하거나 숨겨진 데이터의 일부 속성을 예측하는 것입니다.
자기 지도 학습은 지도 학습 및 비지도 학습과 어떻게 다른가요?
- 지도 학습 작업에는 사전 정의 된 (일반적으로 사람이 제공 한) 레이블이 있습니다.
- 비지도 학습에는 supervision, 레이블 또는 올바른 출력 없이 데이터 샘플만 있습니다.
- 자기 지도 학습은 주어진 데이터 샘플에 레이블을 동시 등장 양식co-occurring modality에서 가져오거나 데이터 샘플의 동시 등장 부분co-occurring part에서 가져오게 됩니다.
자연어 처리의 자기 지도 학습
Word2Vec
- 입력 문장이 주어지면, 해당 문장에서 누락 된 단어를 예측하는 작업이 포함되며, 누락 된 단어는 pretext task을 위해 특별히 생략됩니다.
- 따라서 레이블 집합은 어휘에서 가능한 모든 단어가 되며 올바른 레이블은 문장에서 생략 된 단어입니다.
- 따라서 단어 수준 표현을 학습하기 위해 일반적인 그라디언트 기반 방법을 사용하여 네트워크를 훈련시킬 수 있습니다.
자기 지도 학습이 필요한 이유?
- 자기 지도 학습은 데이터의 서로 다른 부분이 상호 작용하는 방식을 관찰하여 데이터 표현을 학습 할 수 있습니다.
- 따라서 엄청난 양의 주석 데이터가 필요하지 않습니다.
- 또한 단일 데이터 샘플과 연관 될 수 있는 여러 양식들modalities을 활용할 수 있습니다.
컴퓨터 비전의 자기 지도 학습
일반적으로, 자기 지도 학습을 사용하는 컴퓨터 비전 파이프 라인에는 pretext 작업과 실제 (downstream) 작업이라는 두 가지 작업이 포함됩니다.
- 실제 (downstream) 작업은 분류 또는 탐지 작업과 같이 주석이 달린 데이터 샘플이 충분하지 않을 수 있습니다.
- Pretext 작업은 downstream 작업에 학습 된 표현 또는 모델 가중치를 사용하기 위한 목적, 시각적 표현을 학습하기 위한 자기 지도 학습 과제입니다.
Pretext 작업 개발
- 컴퓨터 비전 문제에 대한 Pretext 작업은 이미지, 비디오 또는 비디오 및 사운드를 사용하여 개발할 수 있습니다.
- 각 Pretext 작업에는 일부는 표시되고 일부는 숨겨진 데이터가 있으며 작업은 숨겨진 데이터 또는 숨겨진 데이터의 일부 속성을 예측하는 것입니다.
[Pretext 작업 예 : 이미지 패치의 상대적 위치 예측] (https://www.youtube.com/watch?v=0KeR6i1_56g&t=759s)
- 입력 : 2 개의 이미지 패치, 하나는 앵커 이미지 패치이고 다른 하나는 쿼리 이미지 패치입니다.
- 2 개의 이미지 패치가 주어지면 네트워크는 앵커 이미지 패치에 대한 쿼리 이미지 패치의 상대적 위치를 예측해야합니다.
- 따라서 이 문제는 앵커가 주어 졌을 때 쿼리 이미지에 대해 8 개의 가능한 위치가 있으므로 8-way 분류 문제로 모델링 할 수 있습니다.
- 또한 앵커에 대한 쿼리 패치의 상대적 위치를 입력하여, 이 작업에 대한 라벨을 자동으로 생성 할 수 있습니다.
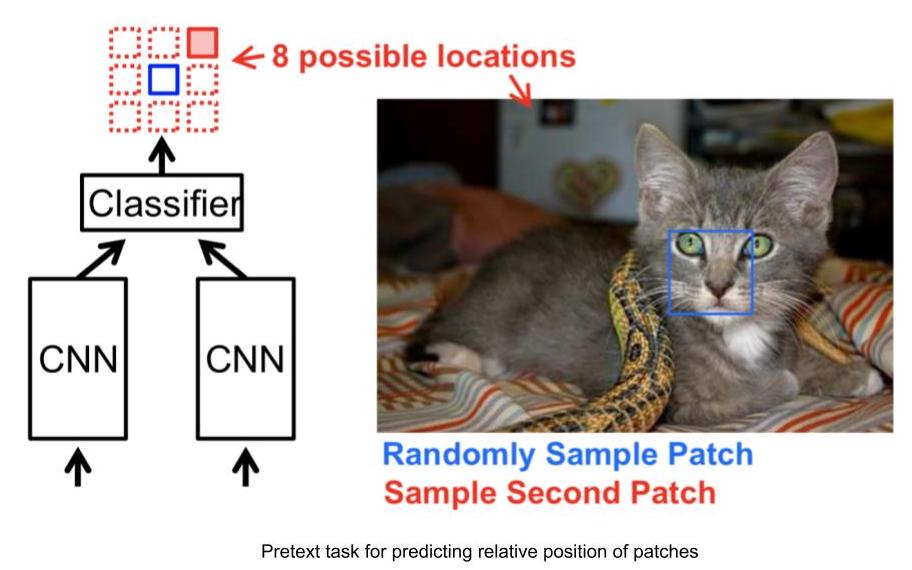
Figure 3: 상대 위치 작업
상대 위치 예측 작업으로 학습한 시각적 표현
네트워크에서 제공하는 주어진 이미지 패치 기반 특징 표현에 대해, 가장 가까운 이웃nearest neighbours을 확인을 통해 학습 된 시각적 표현의 효율성을 평가할 수 있습니다. 주어진 이미지 패치의 가장 가까운 이웃을 계산하려면,
- 데이터 세트의 모든 이미지에 대한 CNN 특징 백터CNN features를 계산합니다. 이는 검색의 샘플 풀의 역할을 합니다.
- 필요한 이미지 패치에 대한 CNN 특징 백터를 계산합니다.
- 사용 가능한 이미지의 특징 벡터 풀에서 필요한 이미지의 특징 벡터에 대한 가장 가까운 이웃을 식별합니다.
상대 위치 작업은 입력 이미지 패치와 매우 유사한 이미지 패치를 찾아 내면서, 물체 색상과 같은 요소에 대한 불변성을 유지합니다. 따라서 상대적 위치 작업은 시각적 표현을 학습 할 수 있으며, 비슷한 시각적 모양을 가진 이미지 패치에 대한 표현도 표현 공간에서 더 가깝습니다.

Figure 4: 상대 위치 : 가장 가까운 이웃
이미지 회전 예측
- 회전 예측은 단순하고 간단한 아키텍처를 가지고 있으며 최소한의 샘플링이 필요한 가장 인기있는 Pretext 작업 중 하나입니다.
- 이미지에 0, 90, 180, 270 도의 회전을 적용하고 이러한 회전 된 이미지를 네트워크로 전송하여 이미지에 적용된 회전의 종류를 예측하고 네트워크는 단순히 4 방향 분류를 수행하여 회전을 예측합니다.
- 회전 예측은 Semantic sense가 없습니다. 우리는 이 Pretext 작업을 프록시로 사용하여 downstream 작업에서 사용할 일부 기능과 표현을 학습합니다.
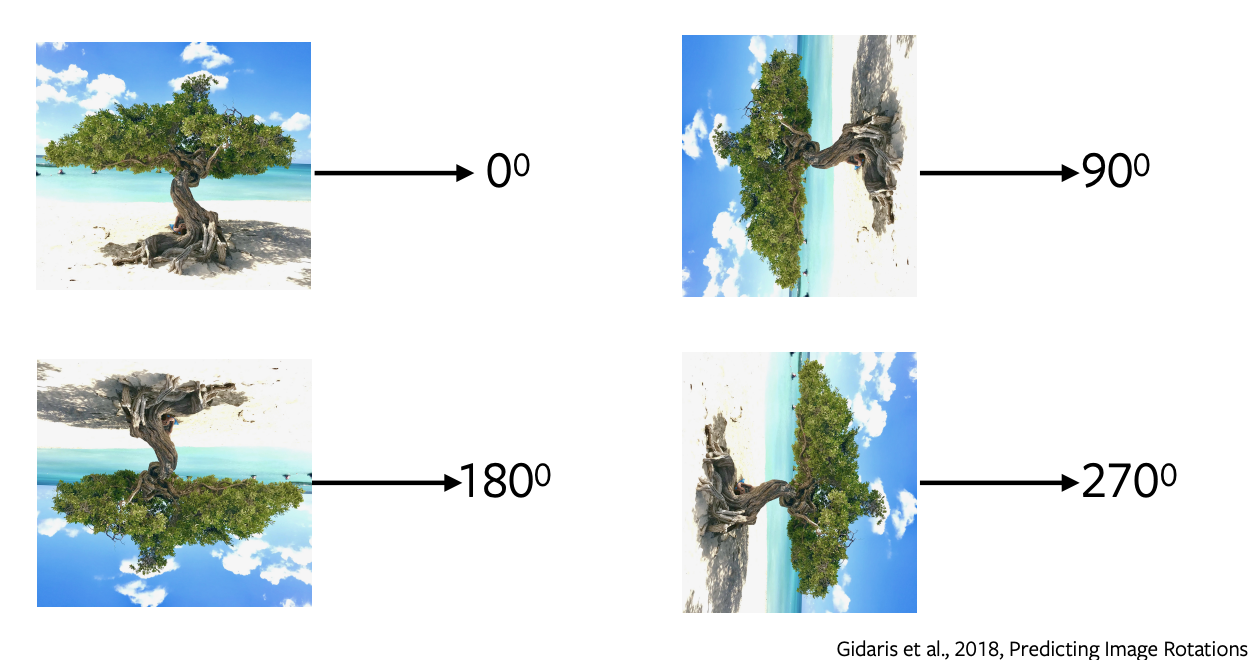
Figure 5: 이미지의 회전
회전이 도움이 되는 이유와 작동하는 이유
경험적으로 작동한다는 것이 입증되었습니다. 경험의 근거가 되는 직관은 회전을 예측하기 위해 모델이 이미지의 대략적인 경계와 표현을 이해해야 한다는 것입니다. 예를 들어, 하늘을 물에서 분리하거나 모래를 물에서 분리하거나 나무가 위로 자라는 것 등을 이해해야 합니다.
색칠하기

Figure 6: 색칠하기
이 Pretext 작업에서는 회색 이미지의 색상을 예측합니다. 모든 이미지에 대해 공식화 할 수 있습니다. 색상을 제거하고이 회색 이미지를 네트워크에 공급하여 색상을 예측합니다. 이 작업은 옛날 회색 필름을 채색하는 데 유용합니다 [//] : <> (이 Pretext 작업을 적용 할 수 있습니다). 이 작업의 이면에 있는 직관은 네트워크가 나무가 녹색, 하늘이 파란색 등과 같은 의미있는 정보를 이해해야한다는 것입니다.
색상 매핑은 결정적이지 않으며 몇 가지 가능한 실제 솔루션이 존재한다는 점에 유의하는 것이 중요합니다. 따라서 물체에 대해 가능한 색상이 여러가지인 경우 네트워크는 가능한 모든 솔루션의 평균 인 회색으로 색상을 지정합니다. 다양한 채색을 위해 Variational Auto Encoder 및 잠재 변수를 사용하는 최근 작업이 있습니다.
빈칸 채우기
이미지의 일부를 숨기고 이미지의 나머지 주변 부분에서 숨겨진 부분을 예측합니다. 이것은 네트워크가 자동차가 도로에서 달리고 건물이 창문과 문으로 구성되어 있음을 나타내는 것과 같은 데이터의 암시적 구조implicit structure를 학습하기 때문에 작동합니다.
동영상에 대한 Pretext 작업
비디오는 일련의 프레임으로 구성되며, 이 개념은 프레임 순서 예측, 공백 채우기 및 개체 추적과 같은 일부 Pretext 작업에 활용할 수 있는 자기 감독self-supervision의 개념입니다.
Shuffle & Learn

Figure 7: 보간
여러 개의 프레임이 주어지면, 세 개의 프레임을 추출하고 올바른 순서로 추출 되면 positive로 레이블을 지정하고 셔플되면 negative로 레이블을 지정합니다. 이것은 이제 프레임의 순서가 올바른지 여부를 예측하는 이진 분류 문제가 됩니다. 따라서 시작 지점과 끝 지점이 주어지면, 중간이 둘의 유효한 보간interpolation인지 확인합니다.
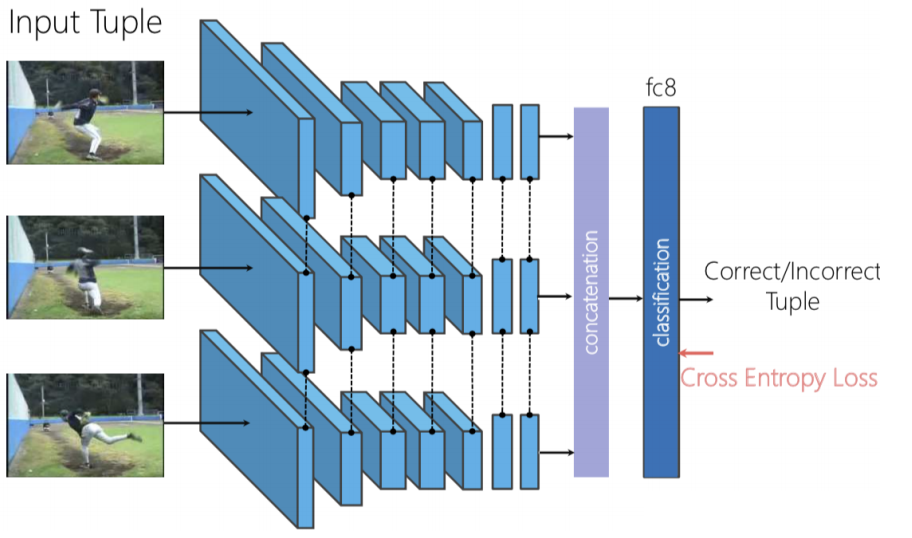
Figure 8: Shuffle & Learn 구조
세 개의 프레임이 독립적으로 순전파하는 Triplet Siamese 네트워크를 사용할 수 있습니다. 그런 다음 생성 된 특징을 합치고concatenate하고 이진 분류를 수행하여 프레임이 셔플되는지 여부를 예측합니다.

Figure 9: 근접 이웃 표현
다시 말하지만 근접 이웃 알고리즘Nearest Neighbours algorithm을 사용하여 네트워크가 학습하는 내용을 시각화 할 수 있습니다. 위 그림 9에서는, 먼저 피쳐 표현을 얻기 위해 순전파feed-forward 한 다음 표현 공간에서 가장 가까운 이웃을 살펴 보는 쿼리 프레임이 있습니다. ImageNet, Shuffle & Learn, Random의 비교를 통해, 이웃 간의 뚜렷한 차이를 관찰 할 수 있습니다.
ImageNet은 첫 번째 입력에 대한 체육관 장면임을 알아낼 수 있으므로, 전반적인 의미 체계를 축소하는 데 능숙합니다. 마찬가지로 두 번째 쿼리에 대해서는 잔디 등이 있는 야외 장면임을 파악할 수 있습니다. 반면 Random을 관찰하면 배경색이 매우 중요하다는 것을 알 수 있습니다.
Shuffle & Learn을 관찰 할 때 색상 또는 의미 개념에 초점을 맞추고 있는지 명확하지 않습니다. 추가적으로 검사와 다양한 예를 살펴본 결과, 사람의 자세를 보고있는 것이 관찰되었습니다. 예를 들어, 첫 번째 이미지에서 사람은 거꾸로 되어 있고 두 번째 이미지에서는 장면이나 배경색을 무시하고 쿼리 프레임과 유사한 특정 위치에 발이 있습니다. 그 이유는 우리의 Pretext 작업이 프레임의 순서가 올바른지 여부를 예측하고 있었기 때문이며, 이를 위해 네트워크는 장면에서 움직이는 것, 이 경우에는 사람에 초점을 맞출 필요가 있습니다.
인간의 이미지가 주어지면 코, 왼쪽 어깨, 오른쪽 어깨, 왼쪽 팔꿈치, 오른쪽 팔꿈치 등과 같은 특정 키 포인트가 어디에 있는지 예측하는 키 포인트 추정 작업human key-point estimation에 이 표현을 미세 조정fine-tuning하여 정량적으로 검증했습니다. 이 방법은 추적 및 포즈 추정에 유용합니다.
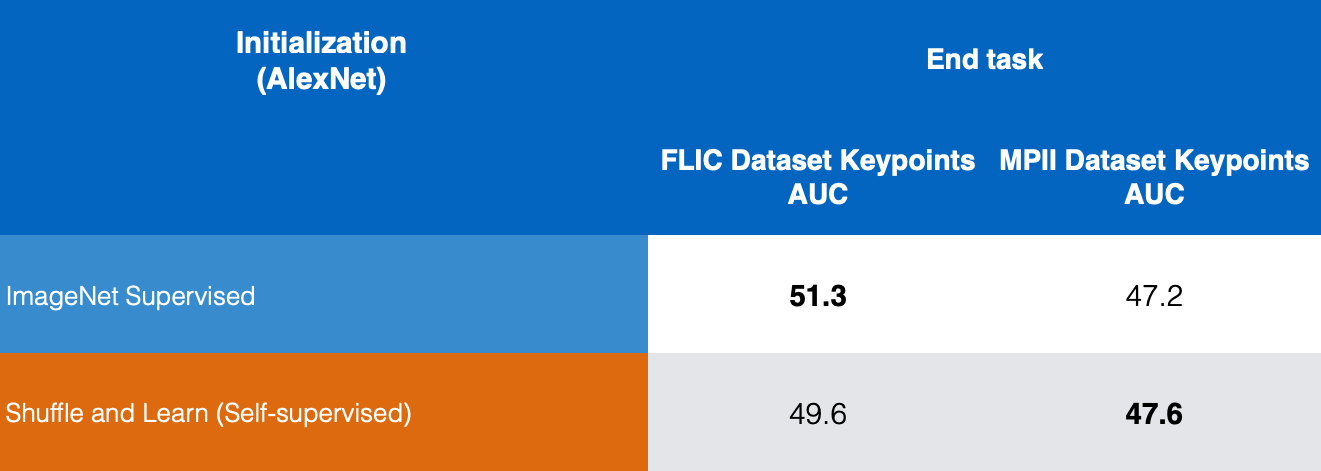
Figure 10: 키 포인트 추정 작업 비교
그림 10에서는, FLIC 및 MPII 데이터 세트에 대해서 지도학습으로 학습 된 ImageNet과 자기 지도 학습으로 학습 된 Shuffle & Learn의 결과를 비교하고 Shuffle and Learn이 키 포인트 추정에 좋은 결과를 제공한다는 것을 알 수 있습니다.
비디오 및 사운드에 대한 Pretext Tasks
비디오와 사운드는 다중 양식multi-modal 입니다. 또는 감각 입력이 비디오 용이고 다른 하나는 사운드 용인 다중 양식multi-modal입니다. 우리는 주어진 비디오 클립이 오디오 클립과 일치하는지 여부를 예측하려고 합니다.

Figure 11: 비디오, 사운드 샘플링
드럼 오디오가 포함 된 비디오가 주어지면 해당 오디오가 포함 된 비디오 프레임을 샘플링하고 Positive set이라고 합니다. 다음으로 드럼의 오디오와 기타의 비디오 프레임을 Negative set로 태그 지정합니다. 이제 이 문제를 이진 분류 문제로 해결하도록 네트워크를 훈련시킬 수 있습니다.
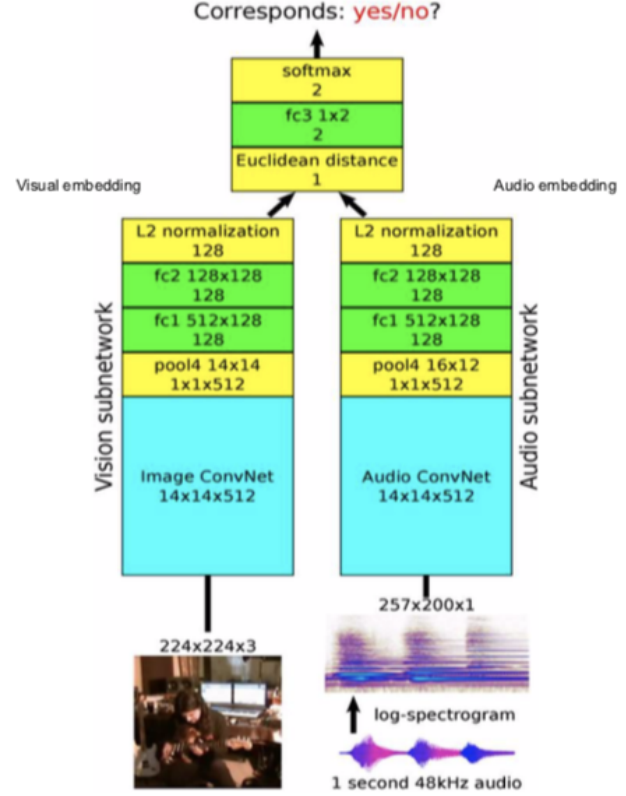
Figure 12: Architecture
Architecture: 비디오 프레임을 비전 서브 네트워크로 전달하고 오디오를 오디오 서브 네트워크로 전달하여 128 차원 기능과 임베딩을 제공 한 다음, 이를 융합하여 두 가지가 일치하는지 예측하는 이진 분류 문제를 풀게 됩니다.
프레임에서 소리가 나는 것을 예측하는 데 사용할 수 있습니다. 직관은 기타 사운드라면 네트워크는 기타가 어떻게 보이는지 대략 이해해야하며 드럼에서도 마찬가지 입니다.
“pretext” task가 학습 하는 것을 이해하기
-
Pretext 작업은 보완적이어야합니다.
- 예를 들어 상대 위치 및 색칠하기이라는 pretext 작업을 살펴 보겠습니다. 아래와 같이 두 가지 pretext 작업을 모두 학습하도록 모델을 학습시켜 성능을 높일 수 있습니다.
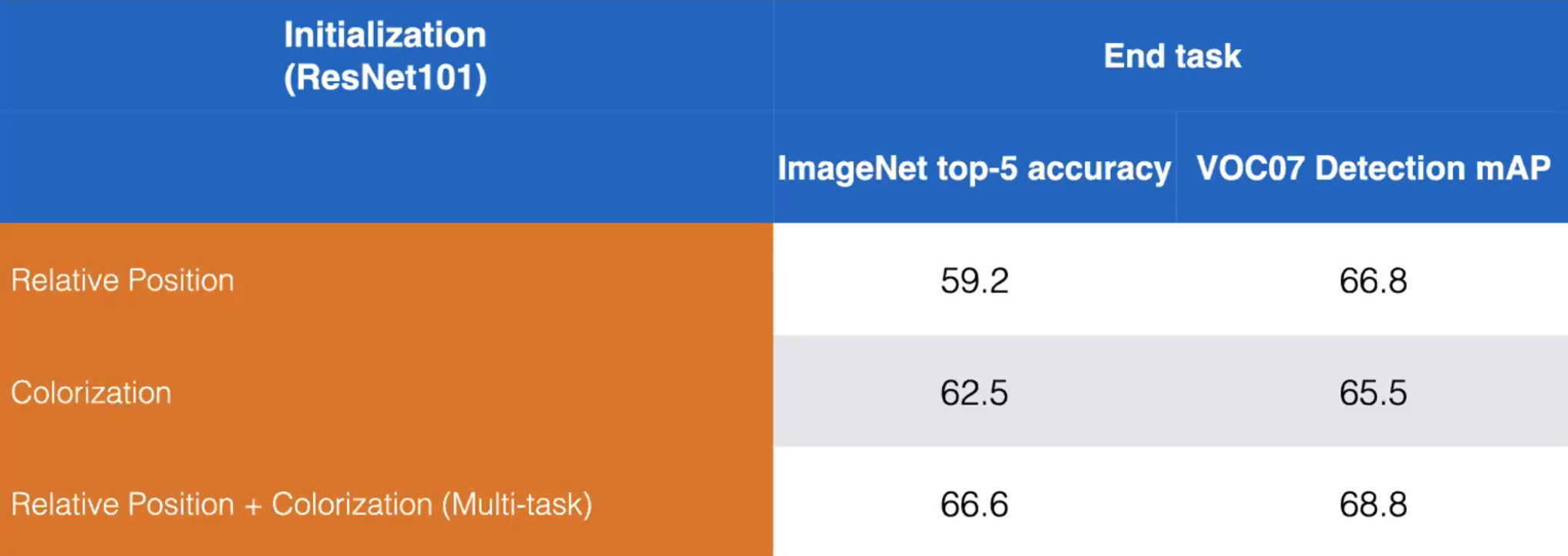
Figure 13: 상대 위치 및 색칠하기 pretext 작업의 분리 된 학습과 결합 된 학습의 비교. ResNet101. (Misra)
-
단일 pretext 작업은 SS 표현을 배우는 데 정답이 아닐 수 있습니다.
- pretext 작업은 예측하려는 내용이 크게 다릅니다 (어려움)
- 간단한 분류이므로 상대 위치가 용이
- 마스킹 및 채우기가 훨씬 더 어렵습니다 -> 더 좋은 표현 학습
- Contrastive methods은 pretext 작업보다 더 많은 정보를 생성합니다. <!–
-
Question: How do we train multiple pre-training tasks?
- The pretext output will depend on the input. The final fully-connected layer of the network can be swapped depending on the batch type.
- For example: A batch of black-and-white images is fed to the network in which the model is to produce a coloured image. Then, the final layer is switched, and given a batch of patches to predict relative position. –>
-
Question: 여러 사전 학습 작업을 어떻게 학습합니까?
- pretext 출력은 입력에 따라 다릅니다. 네트워크의 최종 완전 연결 계층은 배치 유형에 따라 교체 될 수 있습니다.
- 예: 흑백 이미지 배치가 모델이 컬러 이미지를 생성하는 네트워크에 공급됩니다. 그런 다음 마지막 레이어가 전환final layer is switched되고, 상대적 위치를 예측하기 위한 패치 배치가 제공됩니다.
-
Question: pretext 과제에 대해 얼마나 훈련해야합니까?
- 경험에 근거한 규칙Rule of thumb : downstream 작업을 개선 할 수 있는 매우 어려운 pretext 작업이 있습니다.
- 실제로는 pretext 과제가 훈련되어 재 훈련되지 않을 수 있습니다. 개발 과정에서 전체 파이프 라인의 일부로 훈련됩니다.
자기 지도 학습 확장
직소 퍼즐
-
이미지를 여러 타일로 분할 한 다음이 타일을 섞습니다. 그런 다음 모델은 타일을 원래 구성으로 다시 역 셔플링un-shuffling하는 작업을 수행합니다. (Noorozi & Favaro, 2016)
- 입력에 적용된 순열permutation 예측
- 이것은 이미지의 각 타일이 독립적으로 평가되도록 타일 배치를 생성하여 수행됩니다. 컨볼 루션 출력이 합쳐지게concatenated 되고 아래 그림과 같이 순열이 예측됩니다.
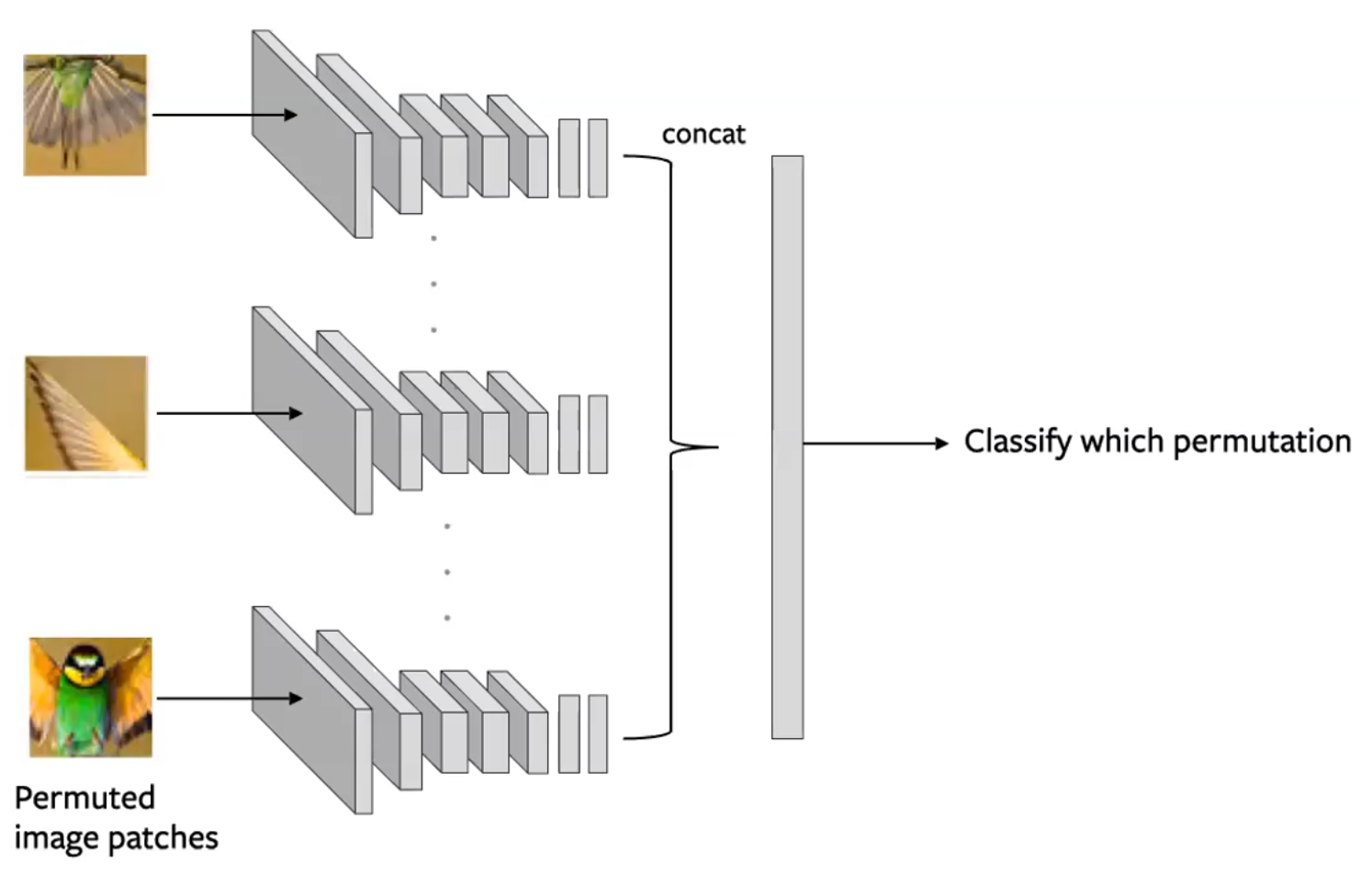
Figure 14: Jigsaw pretext task를 위한 Siamese network. 각 타일은 순열 예측을 위한 인코딩이 합쳐진 형태로 독립적으로 전달됩니다.(Misra)
<!– * Considerations: 1. Use a subset of permutations (i.e.: From 9!, use 100) 2. The n-way ConvNet uses shared parameters 3. The problem complexity is the size of the subset. The amount of information you are predicting.
-
Sometimes, this method can perform better on downstream tasks than supervised methods, since the network is able to learn some concepts about the geometry of its input.
-
Shortcomings: Few Shot Learning: Limited number of training examples
- Self-supervised representations are not as sample efficient –>
- 고려 사항 :
- 순열의 하위 집합을 사용합니다 (예 : From 9 !, 100 사용).
- n-way ConvNet은 공유 매개 변수를 사용합니다.
- 문제의 복잡성은 하위 집합의 크기입니다. 예측하는 정보의 양
-
때로는 이 방법이 감독 된 방법보다 downstream 작업에서 더 잘 수행 될 수 있습니다. 네트워크가 입력의 geometry에 대한 몇 가지 개념을 학습 할 수 있기 때문입니다.
-
Shortcomings: Few Shot Learning : 제한된 수의 학습 예제
- 자기 감독 표현은 샘플만큼 효율적이지 않습니다
평가 : 미세 조정 대 선형 분류기
이 평가 형식은 일종의 전이 학습Transfer Learning입니다.
-
미세 조정Fine-tuning: downstream 작업에 적용 할 때 전체 네트워크를 초기화로 사용하여 새 네트워크를 학습시키고 모든 가중치를 업데이트합니다.
-
선형 분류기 : Pretext 네트워크 위에 작은 선형 분류기를 훈련하여 downstream 작업을 수행하고 나머지 네트워크는 그대로 둡니다.
좋은 표현은 약간의 교육을 통해 전달되어야합니다.
- 다양한 작업에 대한 pretext 학습을 평가하는 것이 도움이 됩니다. 우리는 학습된 표현을 네트워크의 여러 레이어에서 고정 특징 백터으로 추출 할 수 있습니다. 그리고 그것들의 유용성을 여러 과제에 대해서 평가 할 수 있습니다.
- 측정: Mean Average Precision(mAP) – 우리가 고려하는 여러 과제들에 대해서 평균을 취한 정밀도 입니다.
- 이러한 작업의 몇 가지 예는 다음과 같습니다. 객체 감지(미세 조정 사용), 표면 정규 추정 (NYU-v2 데이터 세트 참조)
- 각 레이어는 무엇을 배우나요?
- 일반적으로 레이어가 깊어지면 표현을 사용하는 downstream 작업의 평균 평균 정밀도가 증가합니다.
- 그러나 최종 레이어는 레이어가 지나치게 특수화되기 때문에 mAP가 급격히 떨어집니다.
- 이것은 일반적으로 mAP가 항상 계층 깊이에 따라 증가한다는 점에서 감독되는 네트워크와 대조됩니다.
- 이것은 pretext 작업이 downstream 작업에 잘 정렬되지 않음을 나타냅니다.
📝 Aniket Bhatnagar, Dhruv Goyal, Cole Smith, Nikhil Supekar
SeungHeon
6 Apr 2020