Traduction automatique à faibles ressources II
🎙️ Marc’Aurelio RanzatoNous commençons par les algorithmes d’apprentissage automatique standard qui peuvent être appliqués dans le domaine de la traduction automatique. Ensuite, nous approfondissons la compréhension des différentes perspectives de cette application. Notre cadre porte en plusieurs langues et plusieurs domaines, mais finalement nous voulons maximiser la précision de la traduction d’un certain domaine dans une classe de langue.
Données pour la traduction automatique
- Jeu de données parallèles
- Données monolingues
- Paires de langues multiples
- Domaines multiples
Techniques d’apprentissage automatique
- Apprentissage supervisé
- Apprentissage semi-supervisé
- Apprentissage multi-tâches/multimodal
- Adaptation au domaine
En examinant de plus près le type de données qui nous sont présentées dans le domaine de la traduction automatique, nous pouvons mieux comprendre comment ces applications peuvent être mises en correspondance avec les techniques d’apprentissage automatique. Par exemple, si nous avons un jeu de données parallèles dans l’espace de la traduction automatique, nous avons son équivalent dans l’apprentissage supervisé. Deuxièmement, nous pourrions avoir des données monolingues en traduction automatique, ce qui se traduit par un apprentissage semi-supervisé dans le cadre de l’apprentissage automatique. Troisièmement, si nous avons des paires multilingues dans la traduction automatique, nous pouvons comparer cela à l’apprentissage multi-tâches. Et enfin, si nous avons plusieurs domaines en traduction automatique, nous pouvons comparer cela à l’adaptation de domaine dans l’apprentissage automatique. Lorsque vous avez plusieurs domaines, vous souhaitez naturellement utiliser différentes techniques d’adaptation.
Études de cas : traduction de l’anglais au népalais
Commençons par une étude de cas simple dans le domaine de l’apprentissage supervisé. Par exemple, disons que nous avons une phrase en anglais et que nous voulons la traduire en népalais. Ceci est similaire à l’apprentissage multitâche dans le sens où nous avons une tâche, puis nous ajoutons une autre tâche qui vous intéresse. Puisque nous avons plusieurs domaines, nous pouvons commencer à réfléchir aux techniques d’adaptation au domaine et analyser quelles techniques d’adaptation au domaine sont applicables à la traduction automatique.
Nous pouvons définir notre méthode d’apprentissage supervisé comme suit lors de la traduction de l’anglais au népalais :
\[\mathcal{D}=\left\{\left(\vx, \vy\right)_{i}\right\}_{i=1, \ldots, N}\]Notre perte par échantillon, en utilisant le transformer habituel basé sur l’attention, est définie comme suit :
\[\mathcal{L}(\vtheta)=-\log p(\vy \mid \vx ; \vtheta)\]Nous pouvons régulariser le modèle en utilisant :
- le dropout
- le lissage d’étiquette

Figure 1 : Apprentissage supervisé de l'anglais au népalais
En commençant par le cadre d’apprentissage supervisé, nous pouvons utiliser l’exemple de traduction mentionné plus haut. Notre jeu de données est :
\[D = \{(\vx,\vy)_i\}_{i=1, \vect{...}, N}\]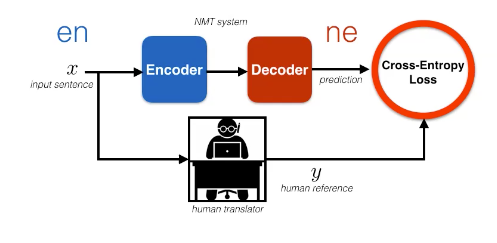
Figure 2 : Visualisation de l'apprentissage supervisé
Nous pouvons entraîner ce modèle en utilisant le maximum de vraisemblance où nous voulons maximiser ${ \vy\vert \vx } $.
Une façon de représenter cette méthodologie est via un diagramme où nous avons un encodeur bleu qui traite les phrases anglaises et un décodeur rouge qui traite le népalais. À partir de là, nous voulons calculer notre perte d’entropie croisée et mettre à jour les paramètres de notre modèle. Nous pouvons également vouloir régulariser le modèle en utilisant le dropout ou le lissage d’étiquettes. En outre, nous pouvons avoir besoin de régulariser en utilisant la perte logarithmique :
\[-\log p(\vy\mid \vx ; \vtheta )\]Remarque : la translittération n’est pas une traduction mot à mot. Cela signifie que vous utilisez les caractères d’une langue pour traduire logiquement le mot dans une autre langue.
Comment améliorer la généralisation ?
Approche semisupervisée
Figure 3 : Apprentissage semisupervisé de l'anglais au népalais
Nous pouvons également obtenir des données monolingues supplémentaires côté source avec cette approche.
\[\begin{array}{c} \mathcal{D}=\left\{(\vx, \vy)_{i}\right\}_{i=1, \ldots, N} \\ \mathcal{M}^{s}=\left\{\vx_{j}^{s}\right\}_{j=1, \ldots, M_{s}} \end{array}\]Lorsque nous utilisons le cadre d’apprentissage semi-supervisé, nous pouvons soit pré-entraîner, soit ajouter une perte au terme d’entropie croisée supervisé :
\[\mathcal{L}^\text{DAE}(\vtheta)=-\log p(\vx \mid \vx+\vect{n})\]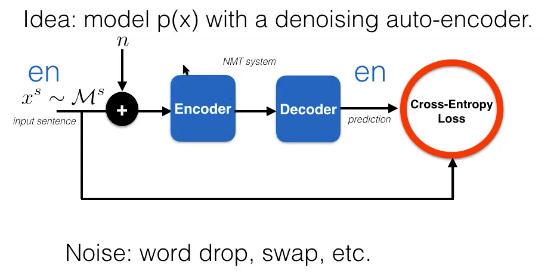
Figure 4 : Schéma de l'apprentissage semi-supervisé
Une façon d’exploiter un jeu de données supplémentaire est d’essayer de modéliser $p(\vx)$ avec une approche semi-supervisée. Une façon de modéliser \(p(\vx)\) est via un auto-encodeur débruiteur (DAE pour denoising auto-encoder). Cette méthode est particulièrement utile car l’encodeur et le décodeur partagent une méthodologie de traduction automatique similaire. Dans l’approche d’apprentissage semi-supervisé, en passant de l’anglais au népalais, nous avons :
\[\mathcal{D} =\lbrace {(\vx, \vy)_{i} \rbrace }_{i=1, \vect{...}, N}\] \[\mathcal{M}^{s}=\left\{\vx_{j}^{s}\right\}_{j=1, \vect{...}, M_{s}}\]Lorsque nous voulons prédire les étiquettes manquantes à l’aide du bruit de décodage et d’entraînement, nous pouvons utiliser la perte d’entropie croisée comme suit :
\[\mathcal{L}^\text{ST}(\vtheta)=-\log p(\bar{\vy} \mid \vx+n)\] \[\mathcal{L}(\vtheta)=\mathcal{L}^{\sup }(\vtheta)+\lambda \mathcal{L}^\text{ST}(\vtheta)\]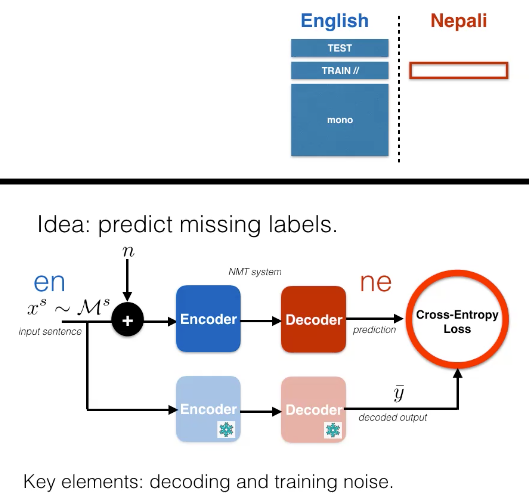
Figure 5: Apprentissage semi-supervisé
Approche auto-entraînement/pseudo-apprentissage
Une autre approche serait via l’auto-entraînement ou le pseudo-apprentissage. Il s’agit d’un algorithme des années 90. L’idée est de prendre la phrase du jeu de données monolingue, d’y injecter du bruit, puis d’encoder la mauvaise traduction effectuée. On effectue une prédiction pour produire le résultat souhaité. Il est possible de régler les paramètres en minimisant la perte d’entropie croisée standard sur les données étiquetées. En d’autres termes, nous minimisons $L^{\sup} (\vtheta) + \lambda L^\text{ST} \vtheta$. En fait, nous utilisons une version périmée de notre modèle pour produire le résultat souhaité, à savoir $\vy$.
Algorithme :
- entraînement du modèle $p(\vy \mid \vx)$ sur $\red{D}$.
- répétition de :
- décoder $\vx^s \sim \mathcal{M}^s$ en $\bar{\vy}$ et créer un jeu de données supplémentaire \(\mathcal{A}^s = \{(\vx^s_j,\vy_j\}_{j=1,\vect{...},M_s})\).
- réentraîner le modèle sur : $\mathcal{D} \cup \mathcal{A}^s$
Cette méthode fonctionne car :
- lorsque nous produisons $\vy$, nous essayons typiquement d’apprendre la procédure de recherche
- nous insérons du bruit qui crée un lissage de l’espace de sortie
Approche avec des données monolingues
Si nous travaillons d’autre part avec des données monolingues, nous devons d’abord entraîner un système de rétrotraduction automatique.
L’ajout de données monolingues côté cible présente deux avantages :
- le décodeur apprend un bon modèle de langage
- il y a une meilleure généralisation grâce à l’augmentation de données
L’algorithme reste le même que ci-dessus, avec des systèmes d’encodeurs et de décodeurs plus petits :
Algorithme :
- on entraîne le modèle $p(\vx\mid \vy)$ sur $\mathcal{D}$.
- on décode $\vy^t \sim \mathcal{M}^t$ en $\vx$ avec $p(\vx\mid \vy)$ et on crée un jeu de données supplémentaire $\mathcal{A}^t = \lbrace ( \bar {\vx}_k,\vy^t_k \rbrace _{k=1,\vect{…},M_t})$
- on ré-entraîne le modèle $p(\vy\mid \vx)$ sur : $\mathcal{D} \cup \mathcal{A}^t$.
Enfin, nous pouvons mettre ces deux algorithmes ensemble dans un processus itératif.
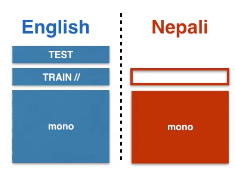
Figure 6 : Scénario de cas d'apprentissage semi-supervisé
Nous pouvons obtenir des données monolingues supplémentaires du côté source et du côté cible.
Le processus que nous pouvons suivre est via cet algorithme :
- on entraîne le modèle $p(\vx \mid \vy)$ et $p(\vy \mid \vx)$ sur $\mathcal{D}$.
- on répète
- Phase 1
- décoder $\vy^{t} \sim \mathcal{M}^{t}$ en $\bar{\vx}$ avec $p(\vx \mid \vy)$, créer un jeu de données supplémentaire
- décoder $\vx^{s} \sim \mathcal{M}^{s}$ en $\bar{\vy}$ avec $p(\vy \mid \vx)$, créer un jeu de données supplémentaire
- Phase 2
- on ré-entraîne à la fois $p(\vy \mid \vx)$ et $p(\vx \mid \vy)$ sur : \(\mathcal{D} \cup \mathcal{A}^{t} \cup \mathcal{A}^{s}\)
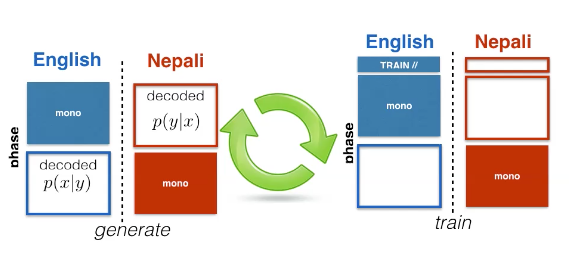
Figure 7 : Diagramme d'apprentissage semi-supervisé
Comment traiter plusieurs langues ?
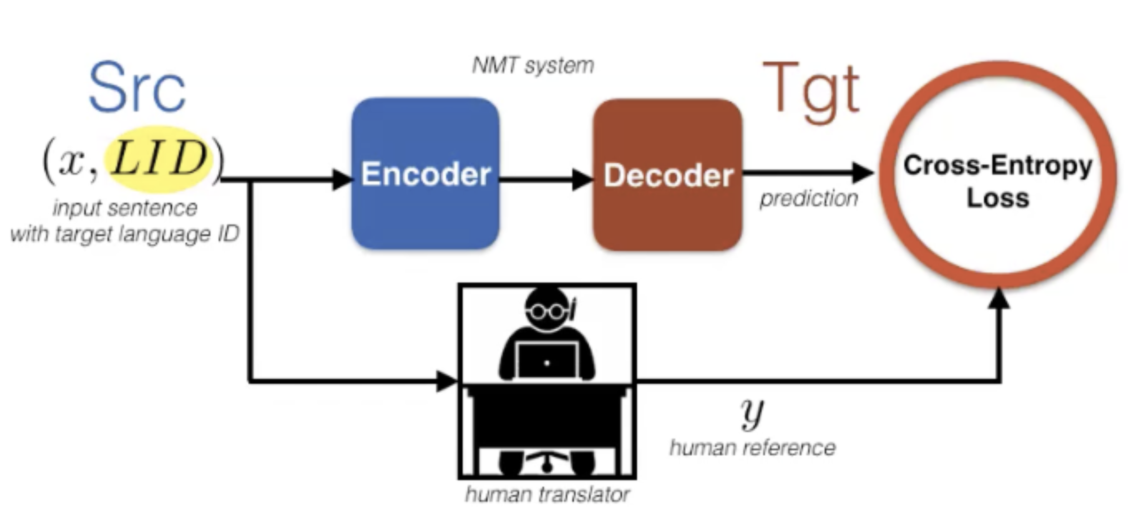
Figure 8 : Scénario de cas d'apprentissage semi-supervisé sur plusieurs langues
Voici le cadre d’apprentissage pour l’entraînement multilingue qui partage l’encodeur et le décodeur à travers toutes les paires de langues. On prépointe un identifiant de la langue cible à la phrase source pour informer le décodeur de la langue désirée et qui concatène tous les ensembles de données ensemble.
Mathématiquement, l’entraînement utilise la perte standard d’entropie croisée :
\[\mathcal{L} (\vtheta )=-\sum_{s,t} \mathbb{E}_{( \vx,\vy )} \sim\mathcal{D}[\log p(\vy \mid \vx,t)]\]Comment traiter l’adaptation de domaine ?
Si nous avons de petites données dans la validation de domaine, nous pouvons finetuner. En gros, on entraîne sur le domaine A et on finetune sur le domaine B en poursuivant l’entraînement pendant un petit moment sur l’ensemble de validation.
Traduction non supervisée
Considérons l’anglais et le français.
\[\begin{array}{l} \mathcal{M}^{t}=\left\{\vy_{k}^{t}\right\}_{k=1, . ., M_{t}} \\ \mathcal{M}^{s}=\left\{\vx_{j}^{s}\right\}_{j=1, . ., M_{s}} \end{array}\]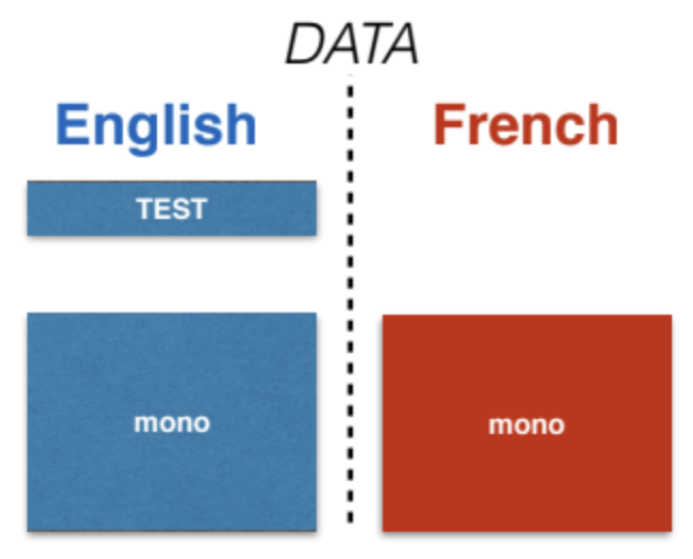
Figure 9 : Traduction automatique non supervisée sur l'anglais et le français
Rétrotraduction itérative
L’architecture suivante traduit d’abord le français en quelques mots anglais inconnus et aléatoires. Puisqu’il n’y a pas de référence de base, ce qui peut être fait est de donner cette traduction à un autre système de traduction automatique allant de l’anglais au français. Le problème ici est le manque de contraintes sur $\bar{\vx}$.
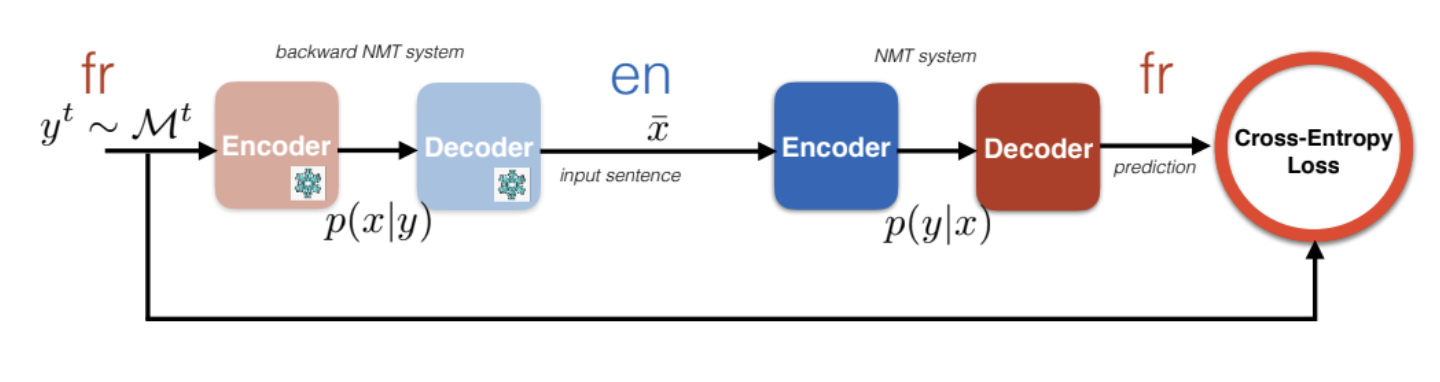
Figure 10 : Rétrotraduction itérative pour l'anglais et le français
Auto-encodeur débruiteur (DAE)
Le DAE ajoute une contrainte sur $\bar{\vect{x}}$ pour s’assurer que le décodeur produit couramment dans la langue désirée. Une façon de faire est d’ajouter le débruitage d’encodage à la fonction de perte. Cela peut ne pas fonctionner car le décodeur peut se comporter différemment lorsqu’on lui donne des représentations provenant d’un encodeur français par rapport à un encodeur anglais (manque de modularité).
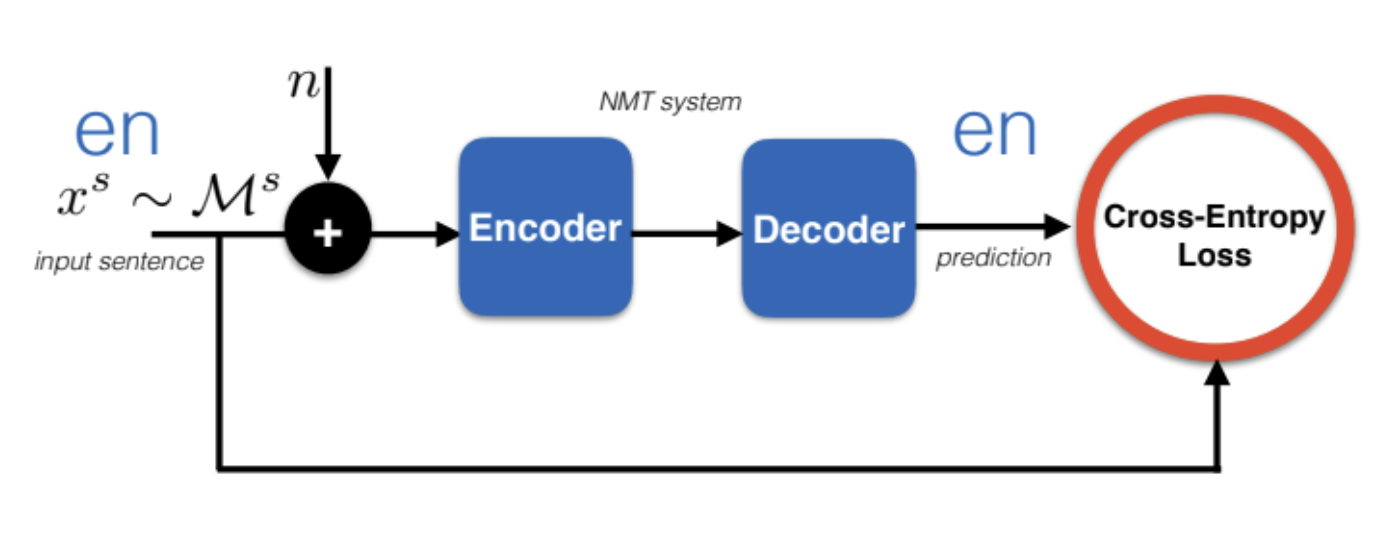
Figure 11 : Auto-encodeur débruiteur (DAE)
Approche multilingue
Une façon de résoudre le problème est de partager tous les paramètres de l’encodeur et du décodeur afin que l’espace des caractéristiques soit partagé, peu importe si on donne une phrase en français ou en anglais (un seul encodeur et décodeur maintenant).
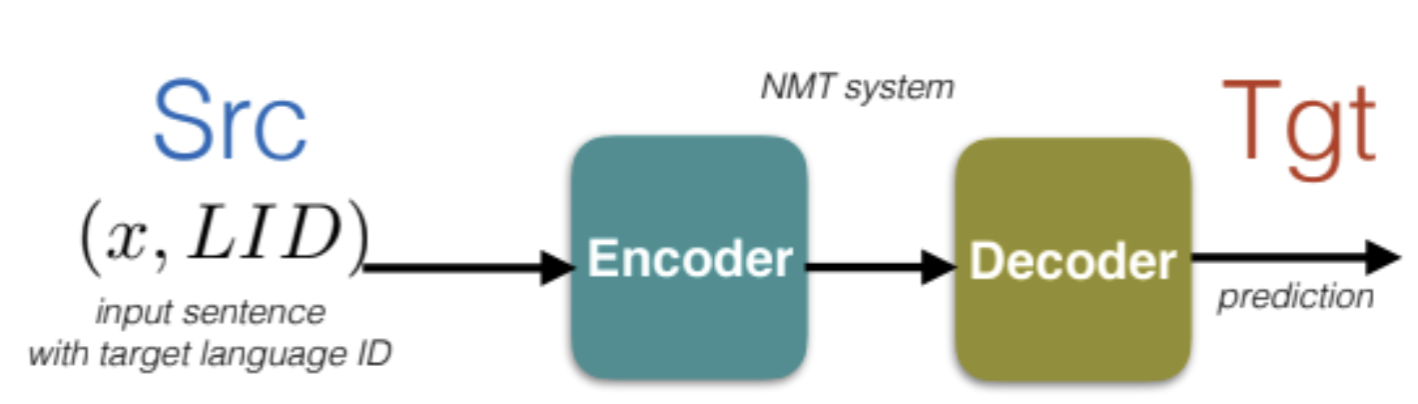
Figure 12 : Approche multilingue
Score BLEU
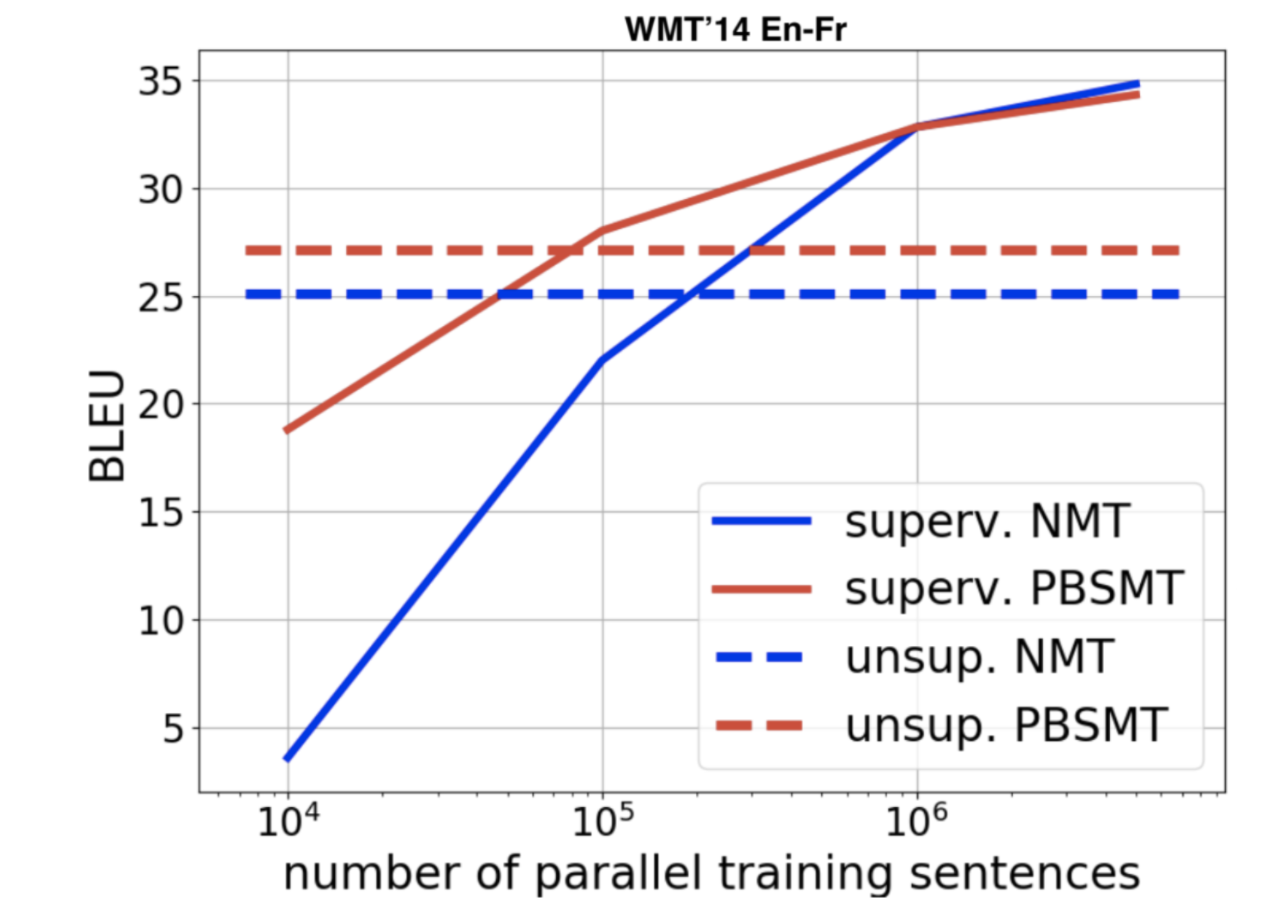
Figure 13 : Score BLEU
Ce graphique explique pourquoi la traduction automatique est un apprentissage à très grande échelle. Il faut compenser le manque de supervision directe en ajoutant de plus en plus de données.
FLoRes Ne-En
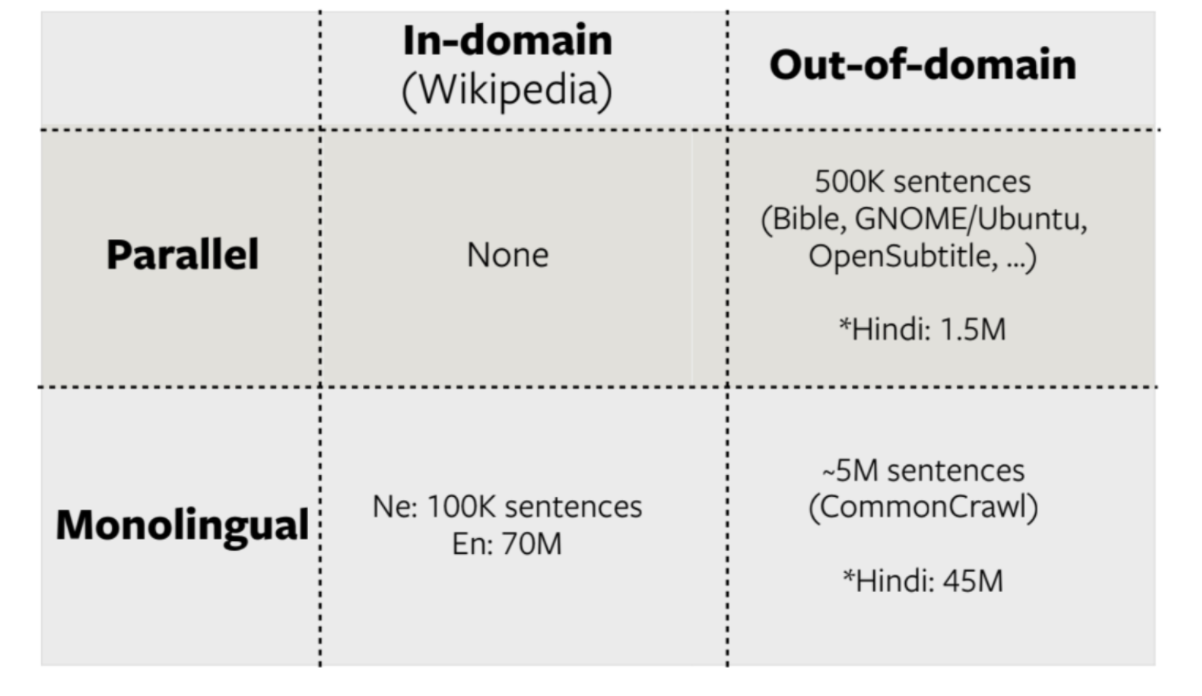
Figure 14 : FLoRes Ne-En
Résultats
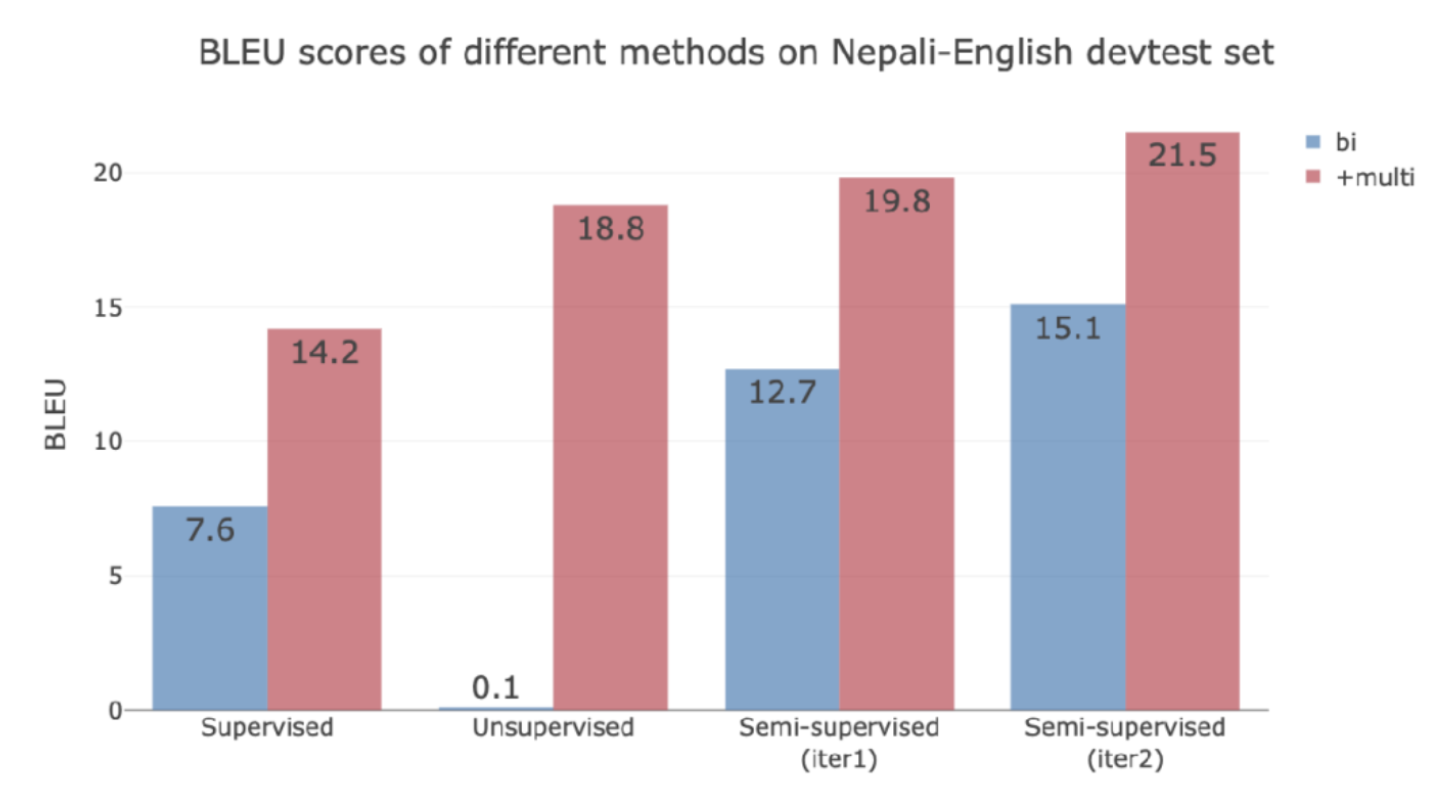
Figure 15 : Résultats de FLoRes Ne-En
L’apprentissage non supervisé ne fonctionne pas du tout dans ce cas car deux monolingues sont issus de domaines différents et il n’y a aucun moyen de trouver des corresponances.
Si l’on ajoute des données en anglais et en hindi, puisque l’hindi et le népalais sont similaires, les quatre modèles s’améliorent considérablement (en rouge).
Si nous voulons ajouter une langue qui est moins apparentée, nous devons en ajouter autant. La traduction automatique à faibles ressources nécessite de grandes données et de grands calculs !
En conclusion, moins vous avez de données étiquetées, plus vous devez utiliser de données :
L’apprentissage supervisé :
- Chaque donnée fournit $X$ bits d’information utiles pour résoudre la tâche
- Besoin de $N$ échantillons
- Besoin d’un modèle de taille $Y$B
Apprentissage non supervisé :
- Chaque donnée fournit $X$/$1000$ bits
- Besoin de $N \times 1000$ échantillons
- Besoin d’un modèle de taille $Y \times f(1000)$ MB
Perspectives
En général, dans le domaine de l’apprentissage automatique et de la traduction automatique, nous considérons un décalage de domaine entre la distribution d’entraînement et la distribution de test. Lorsque nous avons un domaine légèrement différent, nous devons procéder à une adaptation au domaine (par exemple, l’étiquetage du dommaine ou le finetuning).
Inadéquation de domaine entre la source et la cible (STDM pour Source-Target Domain Mismatch)
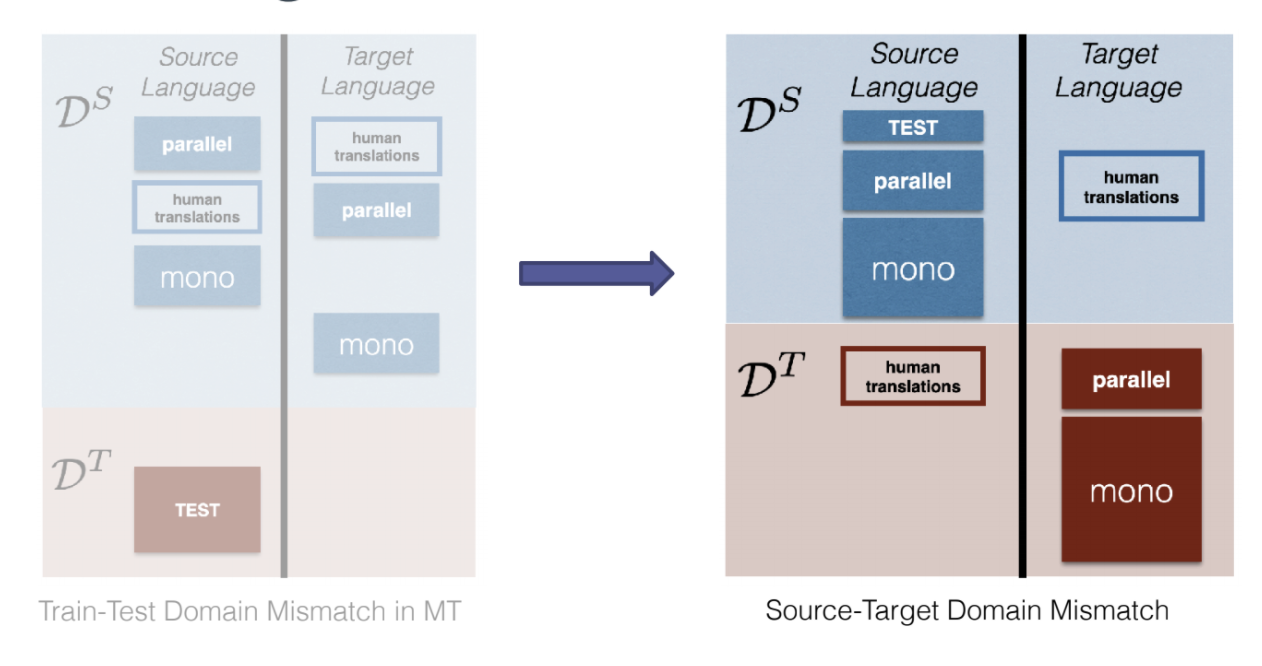
Figure 16 : inadéquation entre le domaine source et le domaine cible dans une langue donnée
Comment quantifier l’inadéquation ?
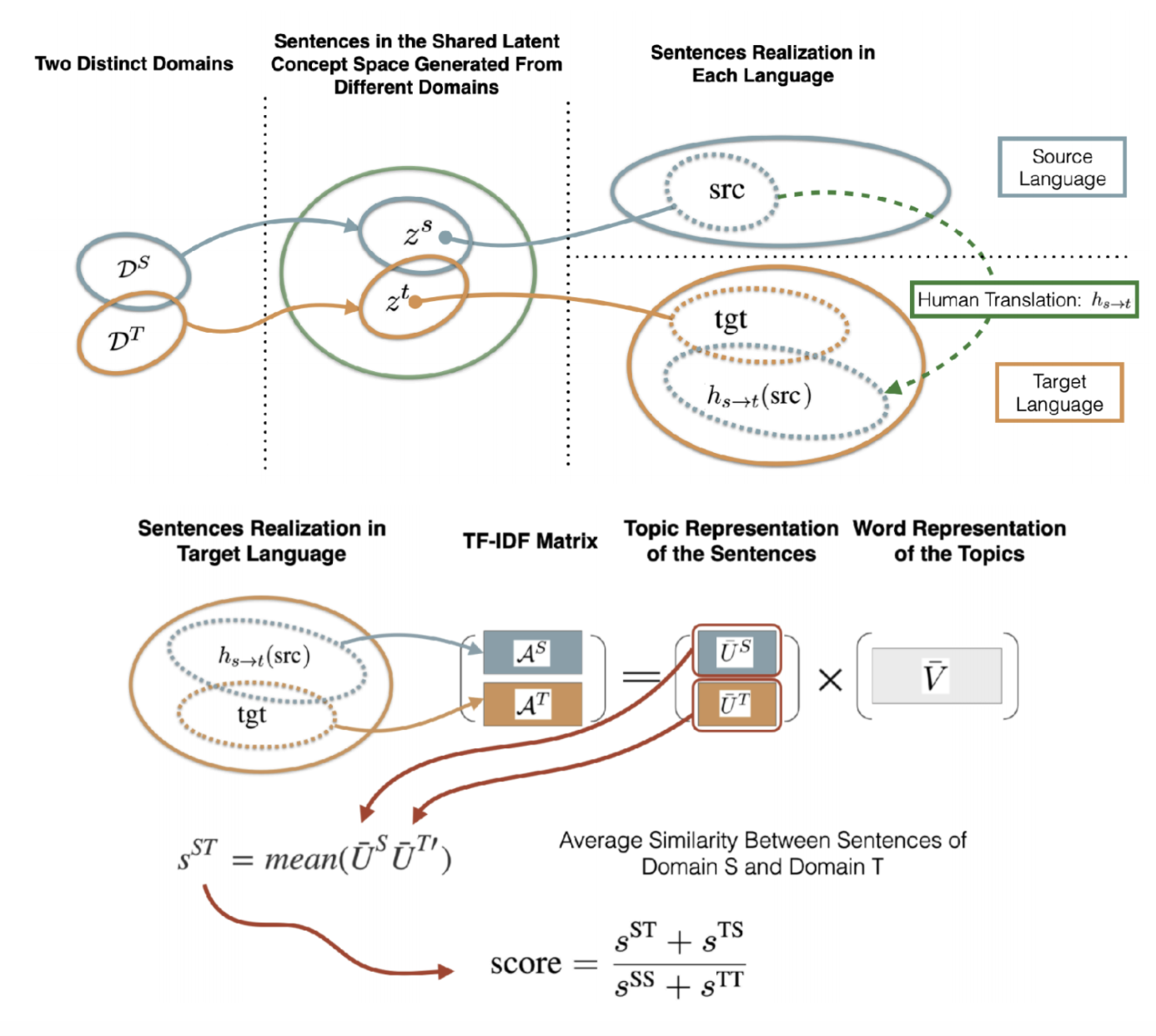
Figure 17 : Quantification de l'inadéquation
En conclusion :
- Inadéquation de domaine entre la source et la cible : un nouveau type de décalage de domaine, intrinsèque à la tâche de traduction automatique.
- L’inadéquation de domaines est particulièrement significative dans les paires de langues à faibles ressources.
- La métrique et le cadre contrôlé permettent d’étudier et de mieux comprendre l’inadéquation de domaines.
- Les méthodes qui exploitent les données monolingues du côté source sont plus robustes à l’inadéquation de domaines.
- En pratique, l’influence de l’inadéquation dépend de plusieurs facteurs, tels que la quantité de données parallèles et monolingues, les domaines, la paire de langues, etc. En particulier, si les domaines ne sont pas trop distincts, l’inadéquation de domains peut même aider à régulariser !
📝 Angela Teng, Joanna Jin
Loïck Bourdois
17 May 2021