Traduction automatique à faibles ressources I
🎙️ Marc'Aurelio RanzatoTraduction automatique neuronale
La traduction automatique neuronale (NMT pour Neural Machine Translation) est une approche d’apprentissage de bout en bout pour la tâche de traduction ayant le potentiel de surmonter bon nombre des faiblesses des systèmes de traduction conventionnels basés sur les phrases. Son architecture se compose généralement de deux parties, l’une prenant la séquence de texte d’entrée (encodeur) et l’autre pour générer le texte de sortie traduit (décodeur). La NMT est souvent accompagnée d’un mécanisme d’attention qui l’aide à faire face efficacement aux longues séquences d’entrée. Le décodeur apprend à s’aligner (en douceur) par le biais de l’attention. Un exemple de traduction de l’italien vers l’anglais est présenté dans la figure ci-dessous :

Figure 1 : Un exemple de traduction de l'italien vers l'anglais
Jeux de données parallèles
Un jeu de données parallèles contient une collection de textes originaux dans une langue L1 et leurs traductions dans une langue L2 (ou consiste en des textes de plus de deux langues). Comme le montre la figure ci-dessous, il peut être utilisé comme données étiquetées pour entraîner les systèmes de NMT.

Figure 2 : Un ensemble de données parallèles composé d'italien et d'anglais
Entraîner la NMT
La méthode standard d’entraînement de la NMT consiste à utiliser le maximum de vraisemblance. Étant donné une phrase source $\vx$ et les paramètres du modèle $\vtheta$, nous chercherons à maximiser la vraisemblance logarithmique de la probabilité conjointe de toutes les séquences ordonnées de tokens dans la phrase cible $\vy$. L’équation ci-dessous l’illustre :
\[- \log\ p( \vy \mid \vx; \vtheta) = - \sum_{j=1}^{n} \log\ p(\vy_j \mid \vy_{j-1}, \ldots \vy_1,\vx; \vtheta)\]C’est utilisé comme un score pour indiquer la probabilité que la phrase cible soit réellement une traduction de la phrase source. Un signe moins est ajouté devant l’équation pour transformer celle-ci en un problème de minimisation.
Modèle de langage
Dans la modélisation du langage, étant donné un token $\vx_t$ au temps $t$, nous essayons de prédire le mot suivant $\vy_t$. Comme le montre la figure ci-dessous, l’état caché $\vz_t$ est généré par un bloc RNN/ConvNet/Transformer en fonction du vecteur d’entrée $\vx_t$ et de l’état caché précédent $\vz_{t-1}$.
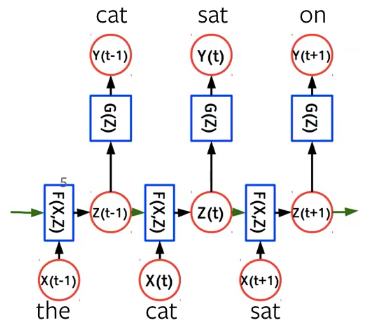
Figure 3 : Modèle de langage
Architecture encodeur-décodeur (Seq2Seq)
Étant donné un jeu de données parallèles (avec des phrases sources et des phrases cibles), nous pouvons utiliser les phrases sources pour entraîner un modèle seq2seq.
Étape 1 : Représentation de la source Représenter chaque mot de la phrase source en tant qu’enchâssement via l’encodeur source.
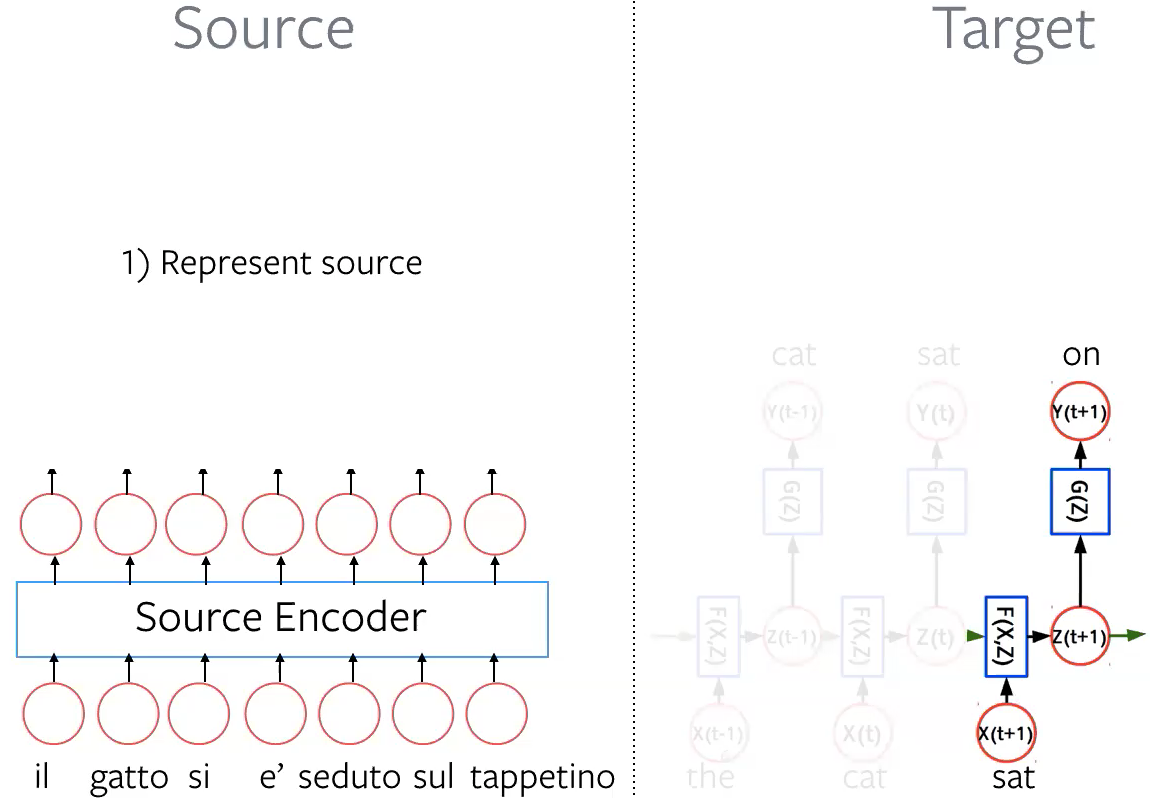
Figure 4 : Représenter la source
Etape 2 : Attribuer un score à chaque mot source (attention) Prendre le produit scalaire entre la représentation cachée cible $\vz_{t+1}$ et tous les enchâssements de la phrase source. Puis utiliser la fonction SoftMax pour obtenir une distribution sur les tokens source (attention).
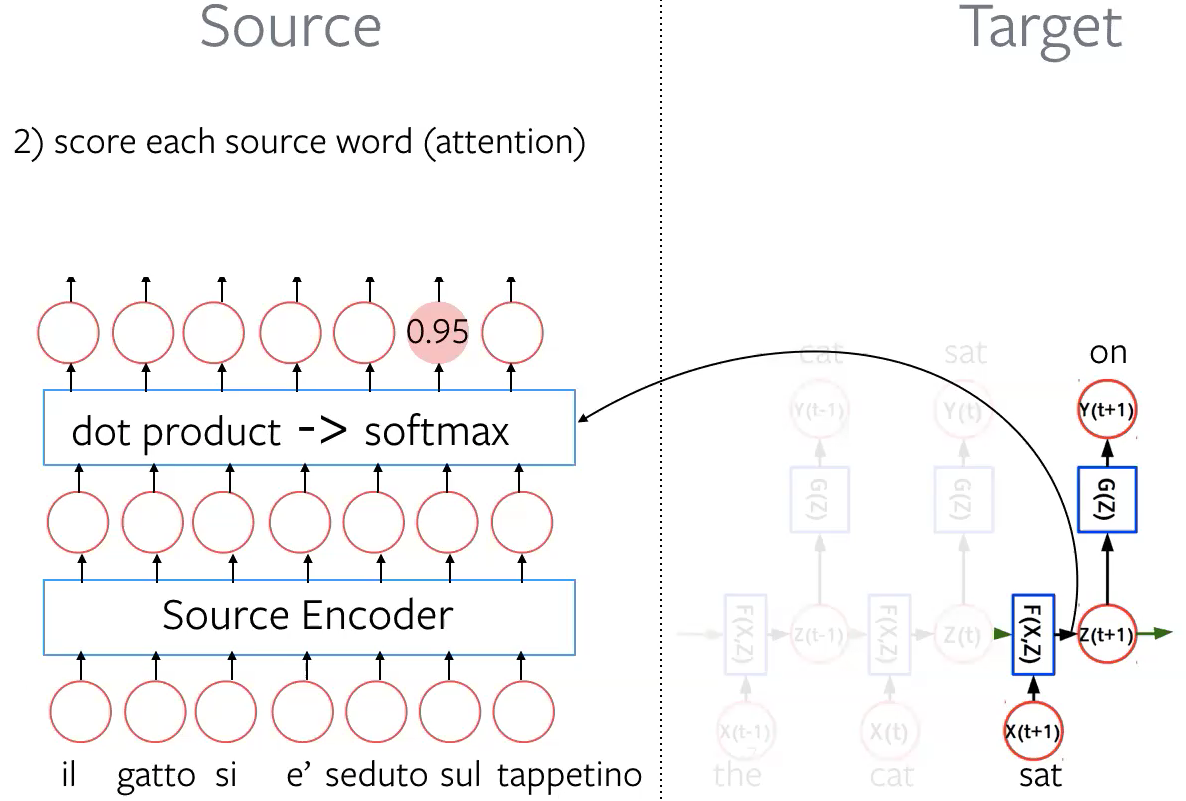
Figure 5 : Attribuer un score chaque mot source
Étape 3 : combiner la cible cachée avec le vecteur source. Prendre la somme pondérée (les poids sont dans le vecteur de score d’attention) des enchâssements source et la combiner avec la représentation cachée cible $\vz_{t+1}$. Après transformation finale $G(\vz)$, on obtient une distribution $\vy_{t+1}$ sur le mot suivant.
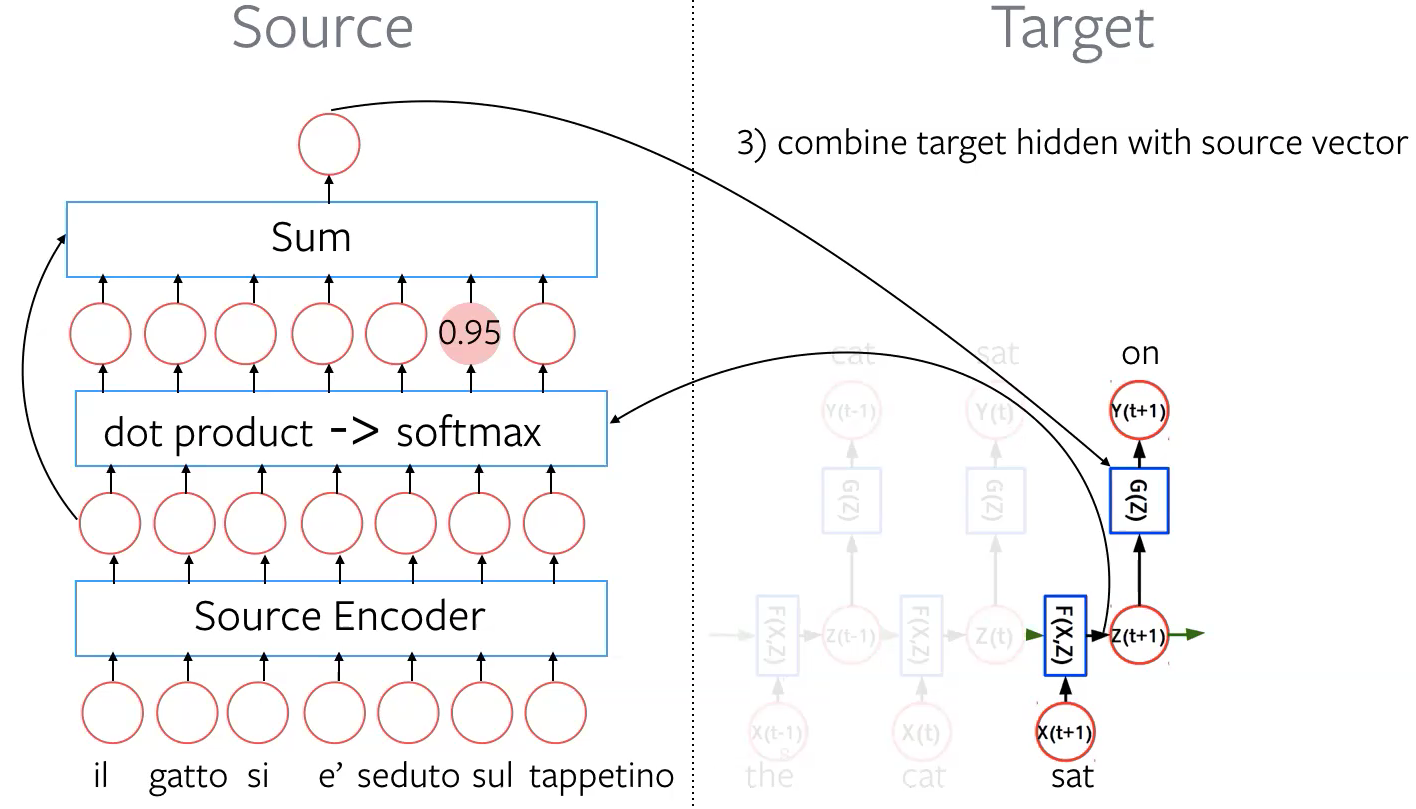
Figure 6 : Combiner la cible cachée avec le vecteur source
L’alignement est appris implicitement dans le modèle seq2seq. Tous les tokens peuvent être traités en parallèle efficacement avec des ConvNets ou des transformers.
Tester notre NMT
Une fois que nous disposons du modèle de traduction et que nous connaissons son efficacité sur l’ensemble d’apprentissage, nous souhaitons le tester pour voir comment le modèle va réellement générer des traductions à partir des phrases sources.
Le décodage en faisceau est utilisé pour rechercher dans l’espace des $\vy$ selon la formule suivante :
\[{\operatorname{argmax}} \log p(\vy \mid \vx;\vtheta)\]Chaque choix potentiel (le nombre de mots dans le vocabulaire) a un score de probabilité. À chaque étape, la recherche en faisceau (beam search en anglais) sélectionne les $k$ meilleurs scores parmi toutes les branches (maintient une file d’attente avec $k$ chemins les mieux notés), puis développe chacun d’entre eux et conserve les $k$ meilleurs scores. Comme l’illustre l’exemple ci-dessous :
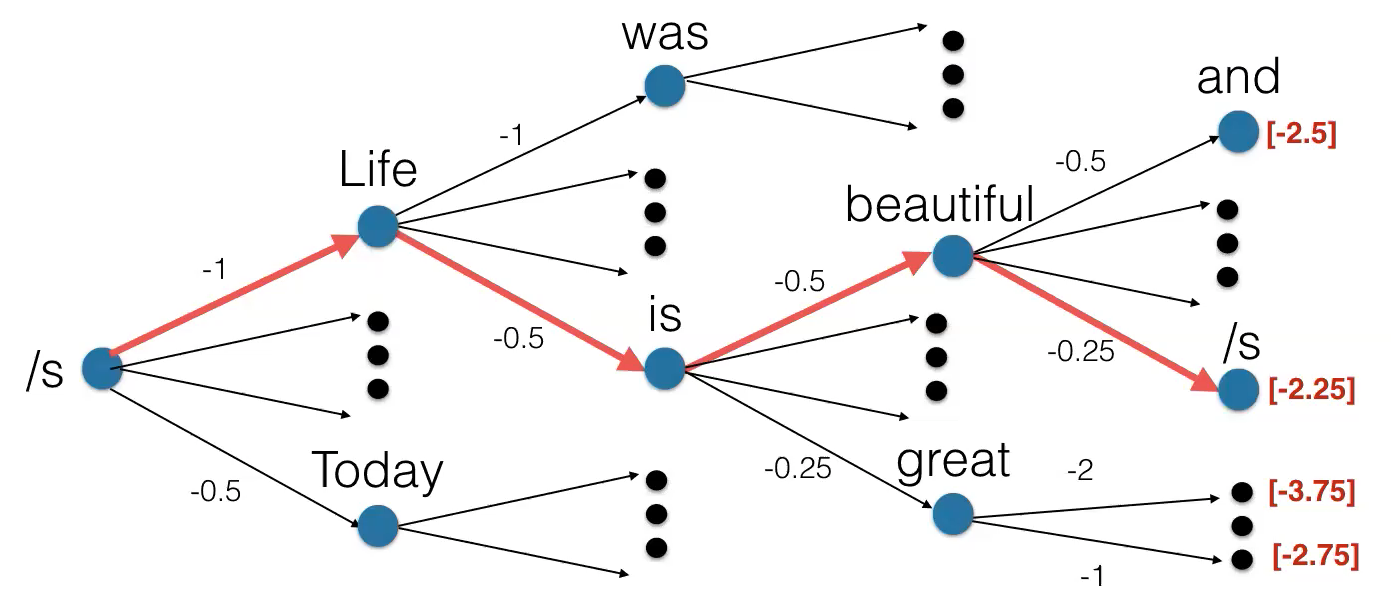
Figure 7 : Recherche en faisceau
Soit $k = 2$
- Partant du symbole /s, elle choisit les 2 meilleurs scores parmi tous les choix possibles (Vie, Aujourd’hui).
- On continue à partir de Vie et Aujourd’hui et on développe chacun de ces deux mots. On calcule le score du chemin de retour au symbole de départ. On choisit les 2 chemins les mieux notés (Vie est et Vie était).
- Et ainsi de suite, jusqu’à atteindre la fin de la phrase.
- À la toute dernière étape, on sélectionne le chemin le plus performant.
La recherche en faisceau est une procédure avide et très efficace en pratique. Il existe un compromis entre le coût de calcul et l’erreur d’approximation (plus la valeur de $k$ est grande, meilleure est l’approximation et plus élevé est le coût de calcul).
Problèmes de la recherche en faisceau : La recherche en faisceau sélectionnera toujours le chemin ayant le score le plus élevé. Ainsi, la solution sera biaisée à cause de cette stratégie. Elle ne gère pas bien l’incertitude.
Autres méthodes de décodage : échantillonnage, échantillonnage top-$k$, reclassement génératif et discriminatif.
Résumé de l’entraînement et de l’inférence d’une NMT
Apprentissage : prédire une phrase cible à la fois et minimiser la perte d’entropie croisée.
Inférence : trouver la phrase cible la plus probable (approximativement) en utilisant la recherche en faisceau.
Évaluation : calcul du score BLEU sur les hypothèses retournées par la procédure d’inférence.
Nous calculons d’abord la moyenne géométrique des précisions modifiées des n-grammes, $p_n$.
\[p_n = \frac{\sum_{\text{generated sentences}} \sum_{\text{ngrams}} \text{Clip(Count(ngram matches))}}{\sum_{\text{generated sentences}} \sum_{\text{ngrams}} \text{Count(ngram)}}\]Les traductions candidates plus longues que leurs références sont déjà pénalisées par la mesure de précision n-gram modifiée Il n’est pas nécessaire de les pénaliser à nouveau. Par conséquent, nous introduisons un facteur multiplicatif de pénalité de brièveté, BP (désigné par \(f_{\text{BP}}\) dans la formule). Avec BP en place, une traduction candidate bien notée doit maintenant correspondre aux traductions de référence en termes de longueur, de choix de mots et d’ordre des mots.
\[s_\text{BLEU} = f_{\text{BP}} \exp\left({\sum_{n=1}^{N} \frac{1}{N} \log \ p_n}\right)\]En bref, le score BLEU (désigné par $s_{\text{BLEU}}$ dans la formule) mesure la similarité entre la traduction générée par le modèle et une traduction de référence créée par un humain.
Traduction automatique dans d’autres langues
La théorie ci-dessus repose sur deux hypothèses :
- Les langues que nous avons considérées sont l’anglais et l’italien, qui sont toutes deux des langues européennes ayant des points communs.
- Nous avons beaucoup de données car, en général, nous avons besoin de trois points de données pour estimer un paramètre et ces modèles ont des centaines de millions de paramètres.
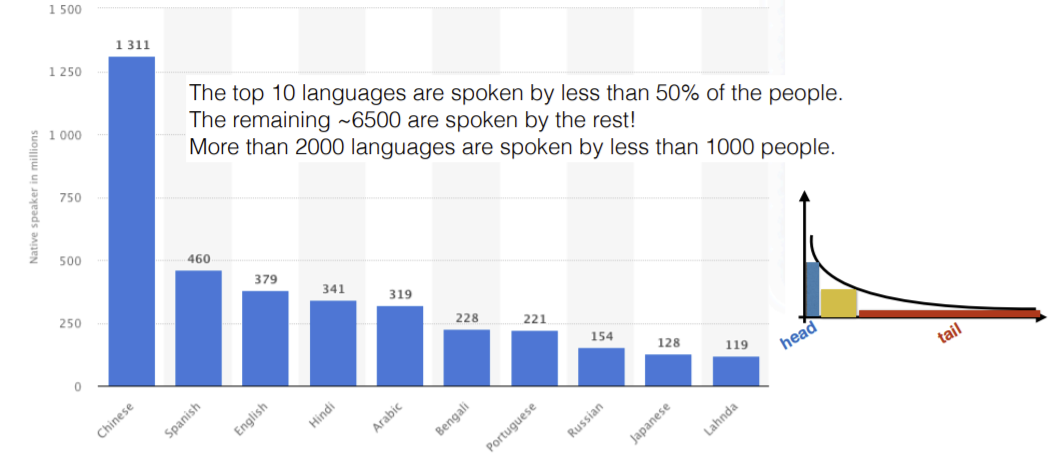
Figure 8 : Statistiques des langues parlées dans le monde, la queue représente le nombre énorme de langues avec peu de locuteurs
Si l’on considère les statistiques, il y a plus de 6000 langues dans le monde et seuelement 5% de la population mondiale a l’anglais comme langue maternelle. Il y a un certain nombre de langues pour lesquelles nous n’avons pas beaucoup de données disponibles et les performances de Google Translate sont faibles. L’autre problème de ces langues est qu’elles sont surtout parlées et non écrites.
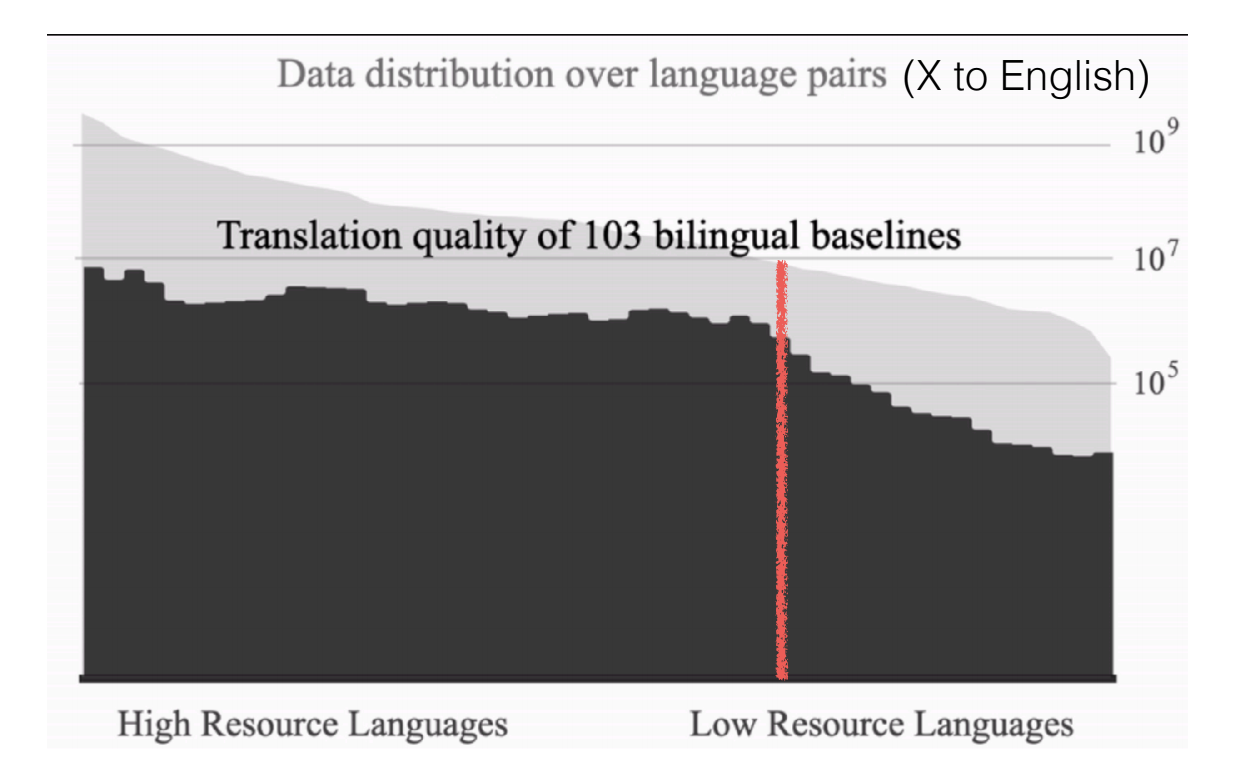
Figure 9 : La qualité de la traduction se dégrade rapidement pour les langues à faibles ressources
La traduction automatique en pratique
Prenons l’exemple d’un système de traduction automatique dans lequel nous traduisons des actualités de l’anglais vers le népalais. Le népalais est une langue à faible ressource et la quantité de données parallèles pour l’entraînement est très faible.
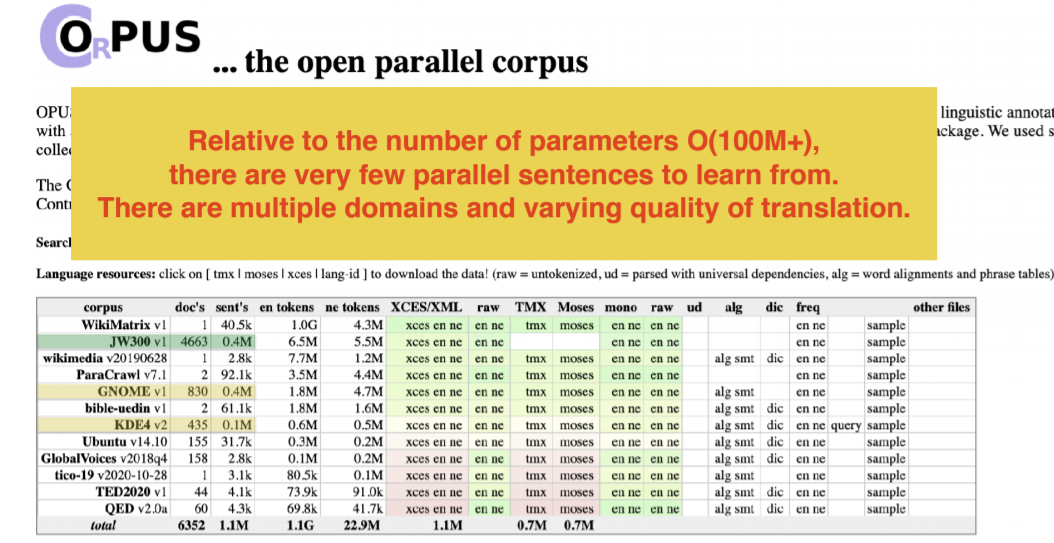
Figure 10 : Ressources du jeu de données « Open Parallel Corpus » pour l'anglais vers le népalais
L’Open Parallel Corpu est un endroit où nous pouvons obtenir ces jeux de données. Il y a 2 problèmes ici :
- si nous cherchons un jeu de données de données en népalais, nous voyons que soit il y en a très peu de qualité, soit un grand sans contenu utile.
- il est possible que les données source et cible ne soient pas parallèles. Nous pouvons avoir plus de données en anglais dans certaines catégories, plus de données en népalais dans d’autres catégories. Il y a des cas où ces deux ne correspondent pas.
Une façon de résoudre ces problèmes est de faire appel à d’autres langues liées au népalais. Par exemple, l’hindi est une langue aux ressources beaucoup plus élevées et appartient à la même famille que le népalais. Nous pouvons étendre cela à d’autres langues également.
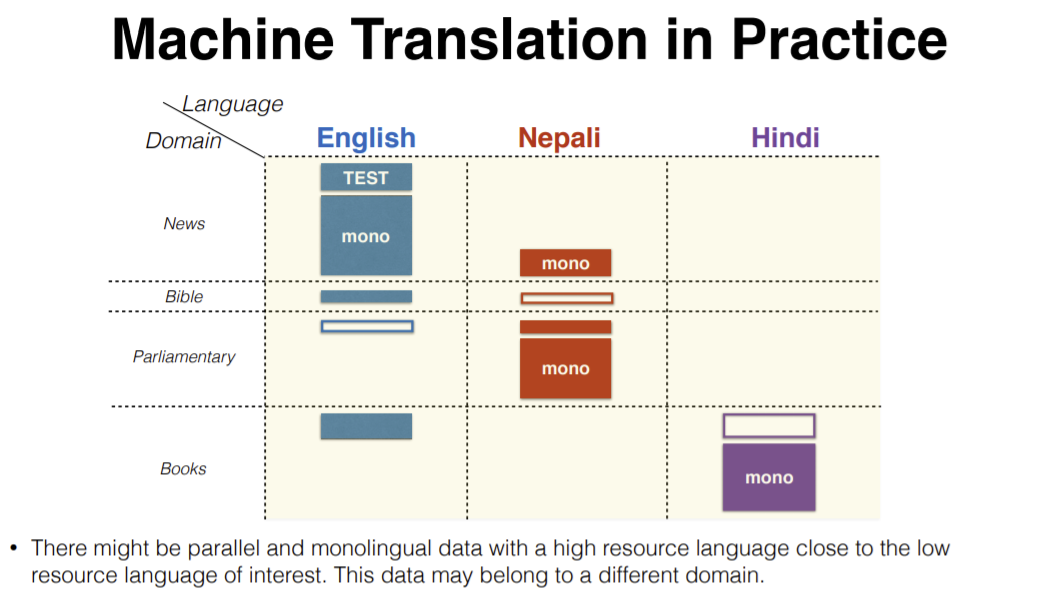
Figure 11 : Traduction automatique de l'anglais au népalais avec l'aide d'autres langues comme l'hindi
Traduction automatique à faibles ressources
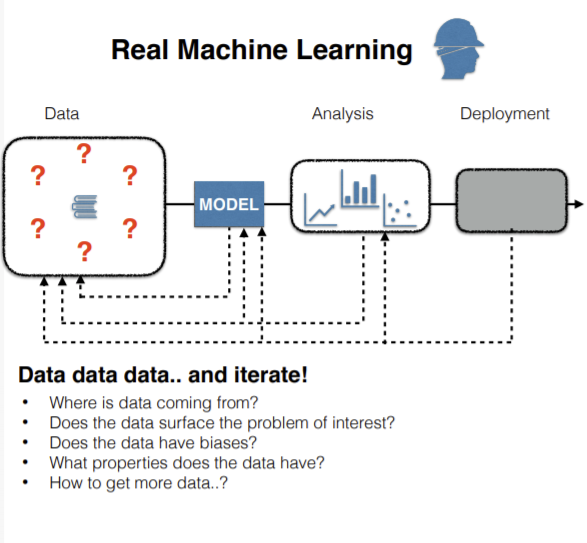
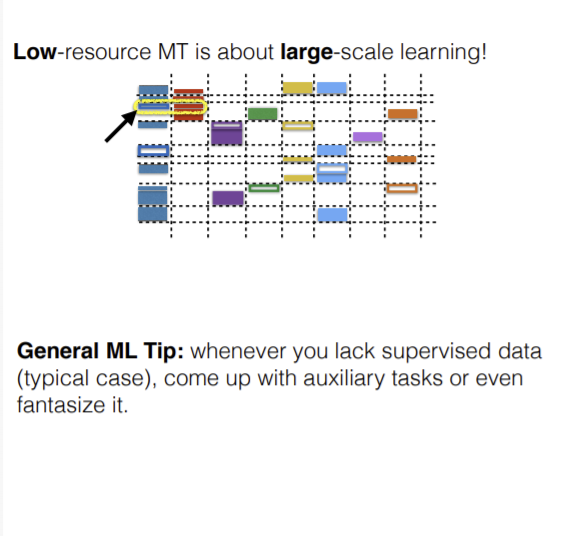
En pratique, chaque fois qu’un modèle est entraîné, de nombreux efforts sont déployés pour analyser le modèle et les propriétés des données. Il s’agit d’un processus itératif nécessitant d’avoir une vue d’ensemble de la situation. Deuxièmement, s’il y a moins de données, nous pouvons réduire l’échelle du modèle, ce qui n’est pas souhaitable. Nous devons trouver des moyens d’élargir le jeu de données d’une manière ou d’une autre ou utiliser des techniques non supervisées.
 |
 |
| (a) Collecte de données en apprentissage machine | (b) Tâches à faibles ressources en apprentissage machine |
Défis
Définition approximative de la traduction automatique à faibles ressources : une paire de langues peut être considérée comme à faibles ressources lorsque le nombre de phrases parallèles est de l’ordre de 10 000 ou moins.
Défis rencontrés dans les tâches de traduction automatique à faibles ressources :
- Jeux de données :
- Trouver des données pour l’entraînement
- Trouver des données d’évaluation de haute qualité
- Métrique :
- Évaluation humaine
- Évaluation automatique
- Modélisation :
- Paradigme d’apprentissage
- Adaptation au domaine
- Généralisation
- Mise à l’échelle
En outre, il y a des défis qui sont rencontrés dans les tâches générales de traduction automatique :
- Biais d’exposition (entraînement pour la génération)
- Modélisation de l’incertitude
- Évaluation automatique
- Calcul du budget
- Modélisation des queues
- Efficacité
Cycle de recherche MAD
Le cycle de recherche repose sur 3 piliers :
- Données : nous collectons les données que nous voulons explorer.
- Modèle : nous fournissons les données collectées et utilisons la distribution des données, nous développons des algorithmes et construisons des modèles.
- Analyse : après avoir obtenu le modèle, nous le testons en vérifiant son adéquation avec la distribution des données ou ses performances à l’aide de différentes métriques.
Ce processus est itéré plusieurs fois pour obtenir une bonne a performance.
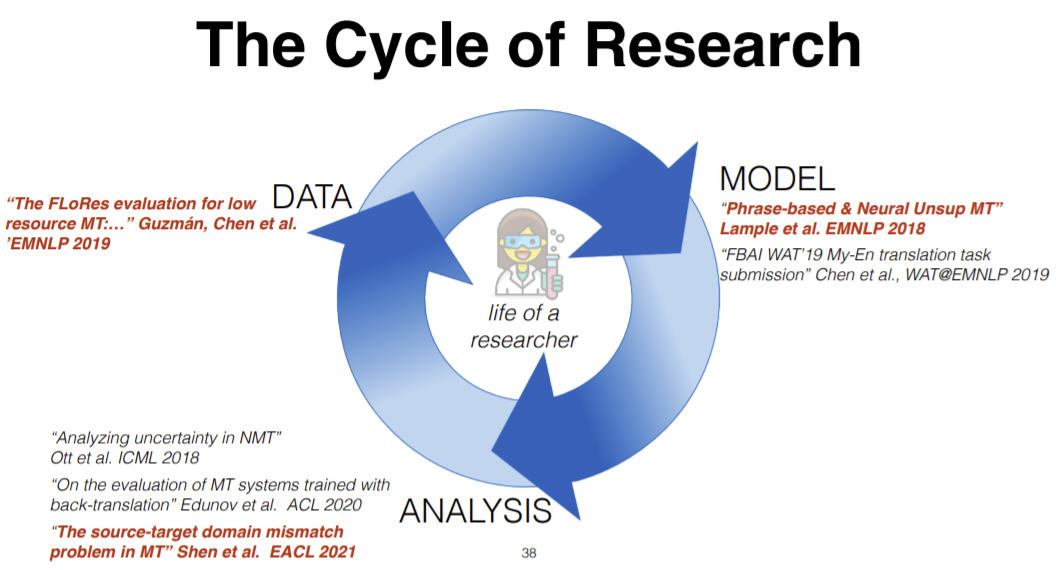
Figure 14 : 3 piliers dans le cycle de la recherche.
Les exemples mis en évidence dans la figure 14 seront discutés plus en détail dans les sections suivantes.
Données
Pour revenir à l’exemple de traduction d’actualités en anglais-népalais, nous collectons des données appartenant à différents domaines. Ici, le jeu de données de la Bible, de GNOME/Ubuntu ne seront pas d’une grande aide pour la traduction d’actualités.
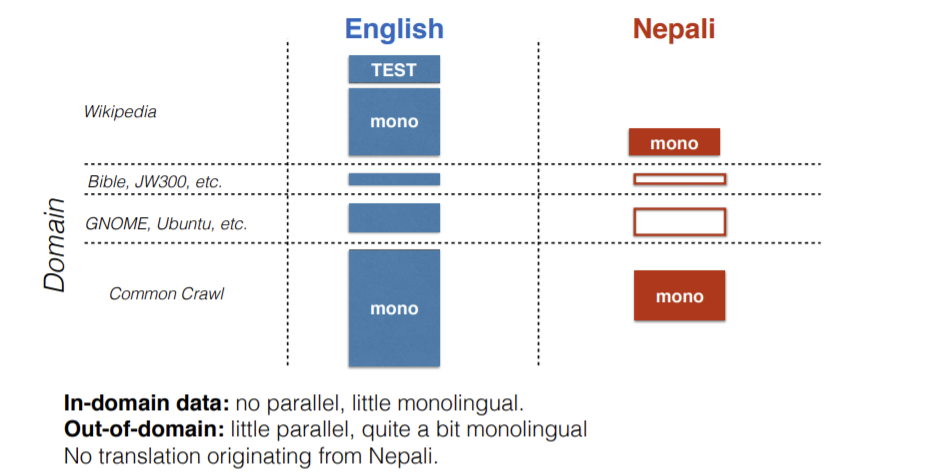
Figure 15 : Jeux de données anglais-népalais
La question ici est : comment pouvons-nous évaluer la partie de l’ensemble de données absente sur le côté droit (népalais) ?
Cette question a conduit à la création du FLoRes Evaluation Benchmark. Il contient des textes (tirés d’articles de Wikipédia) en népalais, singhalais, khmer et pachto. Il ne s’agit pas de jeux de données parallèles.
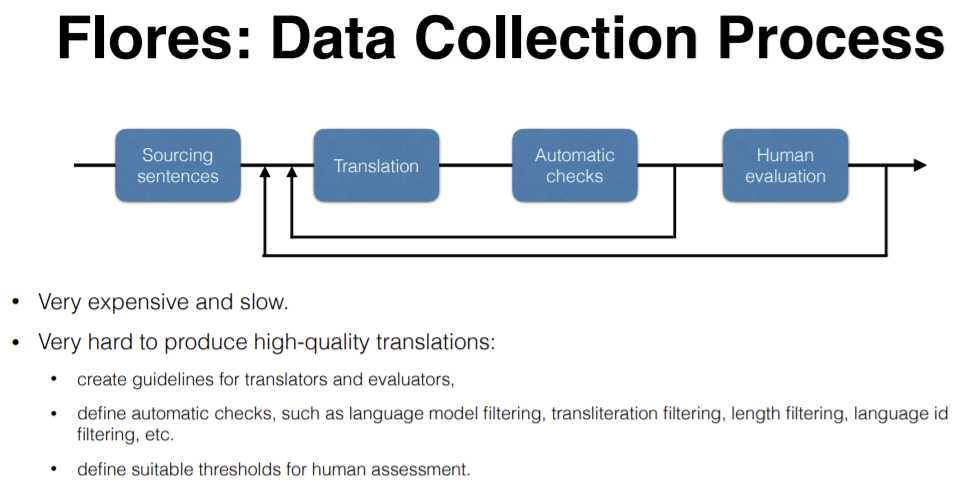
Figure 16 : Processus de collecte des données de Flores
Ces phrases sont traduites et la qualité des traductions est déterminée à l’aide de contrôles automatiques et d’évaluations humaines. Il existe plusieurs techniques dans les vérifications automatiques. Un modèle a été entraîné sur chaque langue et la perplexité a été mesurée. Si la perplexité est trop élevée, nous revenons à l’étape de traduction comme indiqué ci-dessus. D’autres vérifications sont la translittération, l’utilisation de Google Translate, etc. Il n’y a pas de critères ou de conditions pour savoir quand cette boucle doit s’arrêter, cela dépend essentiellement de la perplexité et des éventuelles valeurs aberrantes.

Figure 17 : Quelques exemples de traductions anglaises-singhalaises
La figure 17 montre quelques exemples. Comme on peut le constater, elles ne sont pas vraiment fluides. Un autre problème est que les articles Wikipedia de la langue singhalaise contiennent surtout des sujets d’un nombre très limité de domaines (comme la religion, l’histoire du pays, etc.).
📝 Fanzeng Xia, Rohith Mukku
Loïck Bourdois
21 April 2021