Reconnaissance vocale et Graph Transformer Network I
🎙️ Awni HannunReconnaissance de la parole moderne
Cette section est une introduction à la reconnaissance vocale moderne : pourquoi elle est devenue si bonne mais aussi quels sont les problèmes qui subsistent.
- La reconnaissance automatique de la parole s’est grandement améliorée depuis 2012
- La performance de la machine peut être aussi bonne ou meilleure que la performance humaine.
- La reconnaissance vocale a encore des difficultés dans le cadre :
- d’un discours conversationnel,
- de plusieurs locuteurs,
- de beaucoup de bruit de fond,
- de l’accent des locuteurs,
- de certaines caractéristiques ne sont pas bien représentées dans les données d’entraînement.
- Les systèmes de reconnaissance vocale d’avant 2012 étaient constitués d’un grand nombre de composants conçus à la main :
- un grand ensemble de données n’est pas utile donc les jeux de données sont petits,
- la combinaison des modules uniquement au moment de l’inférence (au lieu de les apprendre ensemble) a entraîné des erreurs en cascade,
- les chercheurs ont du mal à savoir comment améliorer les systèmes complexes.
- Améliorations des systèmes de reconnaissance vocale après 2012 :
- remplacement d’une grande partie des composants traditionnels,
- ajout de plus de données,
- les deux éléments ci-dessus fonctionnent ensemble dans un cycle vertueux.
La perte Connectionist Temporal Classification
Étant donné un audio en entrée $\mX$ composé de $T$ trames d’audio, nous souhaitons produire une transcription $\mY$. Nous considérerons que notre transcription est constituée de lettres donc $y_1$ est la première lettre $y_U$ est la dernière lettre.
\[\mX=[x_1,...,x_T],\ \mY=[y_1,...,y_U]\]Nous voulons maximiser la probabilité conditionnelle (le score) pour évaluer la transcription :
\[\log{P(\mY \mid \mX;\theta)}\]Exemple 1
\[\mX=[x_1, x_2, x_3],\ \mY=[c,a,t]\]$\mX$ a trois images, $\mY$ a trois lettres. Le nombre d’entrées correspond au nombre de sorties, c’est donc facile de calculer la probabilité par correspondance un à un.
\[\log{P(c \mid x_1)} + \log{P(a \mid x_2)} + \log{P(t \mid x_3)}\]Exemple 2
\[\mX=[x_1, x_2, x_3, x_4],\mY=[c,a,t]\]- Alignement : trois possibilités
- $A_1$: $x_1\rightarrow c$, $x_2\rightarrow a$, $x_3\rightarrow t$, $x_4\rightarrow t$
- $A_2$: $x_1\rightarrow c$, $x_2\rightarrow a$, $x_3\rightarrow a$, $x_4\rightarrow t$
- $A_3$: $x_1\rightarrow c$, $x_2\rightarrow c$, $x_3\rightarrow a$, $x_4\rightarrow t$
- Quel alignement devons-nous utiliser pour calculer le score ? Tous. Nous allons essayer d’augmenter le score de tous les alignements et espérer que le modèle fera le tri en interne. Le modèle peut décider d’optimiser ces différents alignements, les pondérer en conséquence et apprendre lequel est le meilleur.
Rappel : utilisez l’actual-softsoftmax pour additionner les probabilités logarithmiques.
Nous voulons $\log{(P_1+P_2)}$ from $\log{P_1}$ and $\log{P_2}$
\[\begin{aligned} \text{actual-softmax}(\log{P_1}, \log{P_2}) &= \log{P_1}+\log{P_2} \\ &= \log{(e^{\log{P1}}+e^{\log{P2}})} \end{aligned}\]Graphe d’alignement
Le graphe d’alignement est un moyen de coder l’ensemble des alignements possibles sur une entrée de longueur arbitraire.
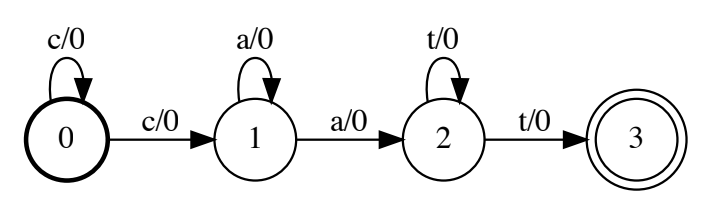
Figure 1 : Graphe d'alignement
Ce graphe est parfois appelé « accepteur d’états finis pondérés » (ou WFSA pour weighted finite state acceptor). L’état gras $0$ au début est un état de départ, le cercle concentrique $3$ est un état d’acceptation. Sur chaque arête, il y a une étiquette et un poids de part et d’autre d’une barre oblique (tous les poids valant $0$ dans l’image ci-dessus). Tout chemin dans ce graphe est un encodage d’un alignement.
Problème : trop d’alignements
Il y a un problème lorsque l’on utilise tous les alignements. L’entrée audio $\mX$ peut avoir beaucoup de trames (en pratique elles peuvent être des milliers). La transcription $\mY$ peut contenir beaucoup de lettres (en pratique des centaines ou plus). Il s’agit donc d’un nombre astronomique d’alignements, nous ne pouvons donc pas calculer un score individuel et tous les additionner.
Solution : l’algorithme forward (programmation dynamique)
Dans la variable forward $\alpha_t^u$, l’indice $t$ est l’endroit où nous sommes dans l’entrée et l’exposant $u$ est l’endroit où nous sommes dans la sortie. Elle représente le score pour tous les alignements de longueur $t$ qui se terminent dans la sortie $y_u$.
Supposons que $\mX=[x_1,x_2,x_3,x_4]$, $\mY=[c,a,t]$, la variable forward $\alpha_2^c$ représente le score de tous les alignements possibles de longueur deux jusqu’aux deux premières trames qui se termine par $c$ dans la première sortie de la transcription. Il n’y a qu’un seul alignement possible pour ce $x_1\rightarrow c$, $x_2\rightarrow c$. C’est donc simple à calculer :
\(\alpha_2^c=\log{P(c \mid x_1)}+\log{P(c \mid x_2)}\).
De même, $\alpha_2^a$ n’a qu’une seule possibilité :
\(\alpha_2^a=\log{P(c \mid x_1)}+\log{P(a \mid x_2)}\).
Pour $\alpha_3^a$, il y a deux alignements possibles :
- $A_1$: $x_1\rightarrow c$, $x_2\rightarrow c$, $x_3\rightarrow a$
- $A_2$: $x_1\rightarrow c$, $x_2\rightarrow a$, $x_3\rightarrow a$
C’est l’approche naïve pour calculer $\alpha_3^a$.
En utilisant cette variable directe, nous cherchons à modéliser la distribution de probabilité $P(\mY \mid \mX) = \sum_{a \in A} P(a)$, où $A$ est l’ensemble de tous les alignements possibles de $\mY$ à $\mX$. Ceci se décompose comme suit :
\[P(\mY \mid \mX) = \sum_{a \in A} \prod_{t=1}^T P(a_t \mid \mX)\]où $P(a_t \mid \mX)$ sont les logits de sortie d’un système tel qu’un RNN.
En d’autres termes, pour calculer la vraisemblance de la transcription $\mY$, nous devons marginaliser sur un nombre irréductiblement grand d’alignements.
Nous pouvons le faire avec une décomposition récursive de la variable directe.
La présentation ci-dessous est inspirée d’un article de distill.pub qui est une excellente introduction à l’algorithme.
Tout d’abord, nous permettons à un alignement de contenir la sortie vide $\epsilon$ afin de tenir compte du fait que les séquences audio sont plus longues que leurs transcriptions correspondantes.
Nous réduisons également les répétitions, de sorte que ${a, \epsilon, a, a, \epsilon, a}$ correspond à la séquence $aaa$.
Nous allons également définir $\alpha$ en utilisant une transcription alternative $Z$, qui est égale à $\mY$ mais est entrecoupée de $\epsilon$.
En d’autres termes, $Z = {\epsilon, y_1, \epsilon, y_2, …, y_n, \epsilon }$.
Supposons maintenant que $y_i = y_{i+1}$, de sorte que $Z$ contient une sous-séquence $y_i, \epsilon, y_{i+1}$, et supposons que $y_{i+1}$ se trouve à la position $s$ dans $Z$.
Alors l’alignement pour $\alpha_{s}^t$ peut être obtenu de deux manières : soit la prédiction au temps $t-1$ peut être $y_{i+1}$ (auquel cas la répétition est collapsée), soit la prédiction au temps $t-1$ peut être epsilon. On peut donc décomposer :
où les éléments de la somme représentent les deux préfixes possibles de l’alignement. Si, d’autre part, nous avons $y_i \ne y_{i+1}$ alors il y a la troisième possibilité supplémentaire que la prédiction au temps $t-1$ soit égale à $y_i$. Ainsi, nous avons la décomposition
\[\alpha_s^t = (\alpha_{s, t-1} + \alpha_{s-1, t-1} + \alpha{s-2, t-1}) P(z_s \mid \mX)\]En calculant $\alpha_{\vert Z\vert}^{T}$, nous pouvons effectivement marginaliser tous les alignements possibles entre la transcription $\mY$ et l’audio $\mX$, ce qui permet un apprentissage et une inférence efficaces. C’est ce qu’on appelle la Connectionist Temporal Classification ou CTC.
📝 Cal Peyser, Kevin Chang
Loïck Bourdois
14 Apr 2021