Architecture encodeur-predicteur-décodeur d'un transformer
🎙️ Alfredo CanzianiLe transformer
Avant d’élaborer l’architecture encodeur-prédicteur-décodeur, nous allons passer en revue deux modèles que nous avons déjà vus.
Architecture d’un EBM conditionnel à variable latente
Dans l’architecture d’un EBM conditionnel à variable latente, nous avons $x$ la variable conditionnelle qui va dans un prédicteur. Nous avons $\vy$ qui est la valeur cible. Les modules de décodage produisent $\vytilde$ lorsqu’on leur donne une variable latente $z$ et la sortie du prédicteur. $\red{E}$ est la fonction d’énergie qui minimise l’énergie entre $\vytilde$ et $\vy$.
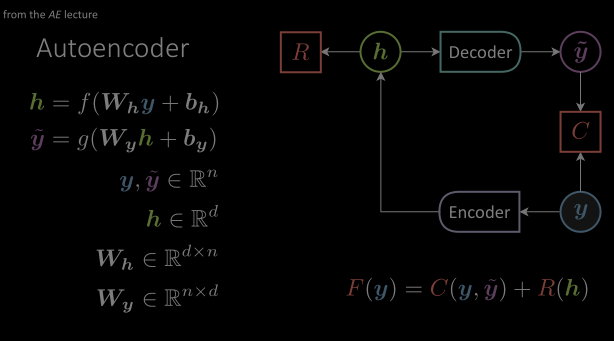
Figure 1 : Architecture d'un EBM conditionnel à variable latente
Architecture d’un auto-encodeur
Dans l’architecture d’un auto-encodeur, nous avons observé qu’il n’y a pas d’entrée conditionnelle mais seulement une variable cible. L’architecture entière essaie d’apprendre la structure de ces variables cibles. La valeur cible $\vy$ est introduite dans un module encodeur qui la transforme en un espace de représentation caché, ne laissant passer que les informations les plus importantes. Et le décodeur fera en sorte que ces variables reviennent à l’espace cible original avec une valeur $\vytilde$. La fonction de coût va essayer de minimiser la distance entre $\vytilde$ et $\vy$.
Figure 2 : Architecture d'un autoencodeur de base composé de modules encodeur et décodeur
Architecture de l’encodeur-prédicteur-décodeur
Figure 3 : L'architecture du transformer avec un module de retard unitaire
Dans un transformer, $\vy$ (phrase cible) est un signal temporel discret. Il a une représentation discrète dans un index temporel. Le $\vy$ est introduit dans un module de retard unitaire suivi d’un encodeur. Le retard unitaire transforme ici $\vy[j] \mapsto \vy[j-1]$ La seule différence avec l’auto-encodeur ici est cette variable retardée. Nous pouvons donc utiliser cette structure dans le modèle de langage pour produire le futur lorsqu’on nous donne le passé.
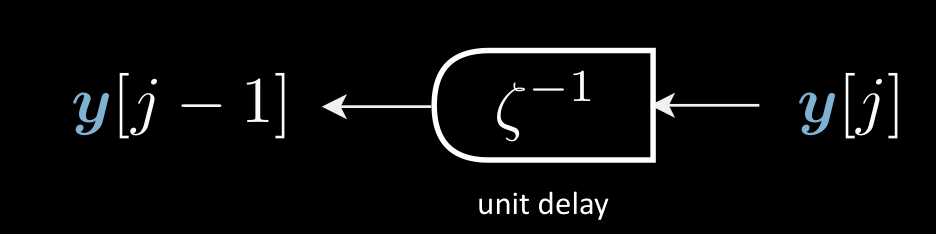
Figure 4 : Un module de retard unitaire transforme $\vy[j] \mapsto \vy[j-1]$
Le signal observé, $\vx$ (phrase source) passe également par un encodeur. La sortie de l’encodeur et de l’encodeur retardé est introduite dans le prédicteur qui donne une représentation cachée $\vh$. Ceci est très similaire à l’auto-encodeur débruiteur car le module de retard agit comme un bruit dans ce cas. $\vx$ fait de cette architecture entière un auto-encodeur débruiteur conditionnel retardé.
Module encodeur
Vous pouvez voir l’explication détaillée de ce module dans les notes de l’année dernière disponibles ici.
Module prédicteur
Le module prédicteur du transformer suit une procédure similaire à celle de l’encodeur. Cependant, il y a un sous-bloc supplémentaire (c’est-à-dire l’attention croisée) à prendre en compte. De plus, la sortie des modules encodeurs agit comme les entrées de ce module.
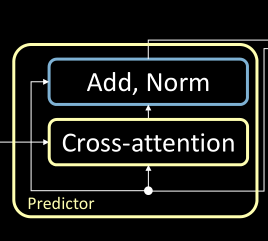
Figure 5 : Le module prédicteur composé d'un bloc d'attention croisée
Attention croisée
Vous pouvez consulter l’explication détaillée de l’attention croisée dans les notes de l’année dernière disponibles ici.
Module décodeur
Contrairement à ce que les auteurs du papier du transformer définissent, le module décodeur est composé de blocs 1D-convolution et Add, Norm.
La sortie du module prédicteur est introduite dans le module décodeur et la sortie du module décodeur est la phrase prédite.
On peut l’entraîner en fournissant la séquence cible retardée.
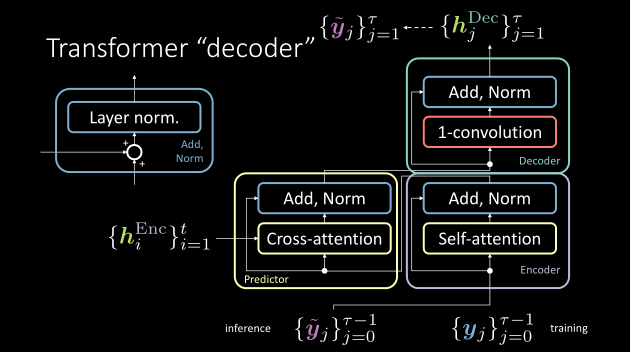
Figure 6 : La notation correcte des modules encodeur, prédicteur et décodeur dans un transformer
📝 Rahul Ahuja, jingshuai jiang
Loïck Bourdois
15 Apr 2021