SEER, AVID + CMA, Distillation, Barlow Twins
🎙️ Ishan MisraSEER : Apprendre à partir d’images non répertoriées
Par rapport au jeu de données Imagenet, les images du monde réel peuvent avoir des distributions différentes (dessins animés, memes) et avoir ou non un objet proéminent. Afin de vérifier si les modèles fonctionnent bien sur des images en dehors de la base de données Imagenet, les auteurs de SEER ont décidé de tester la méthode SWAV sur des données à grande échelle. SEER (SElf-supERvised) est donc la méthode SWAV testée sur des milliards d’images non filtrées.
Le graphique suivant compare les performances des quatre modèles finetunés sur Imagenet. En utilisant la méthode SEER, un modèle peut être entraîné avec plus d’un milliard de paramètres qui vont se transférer très bien à Imagenet.
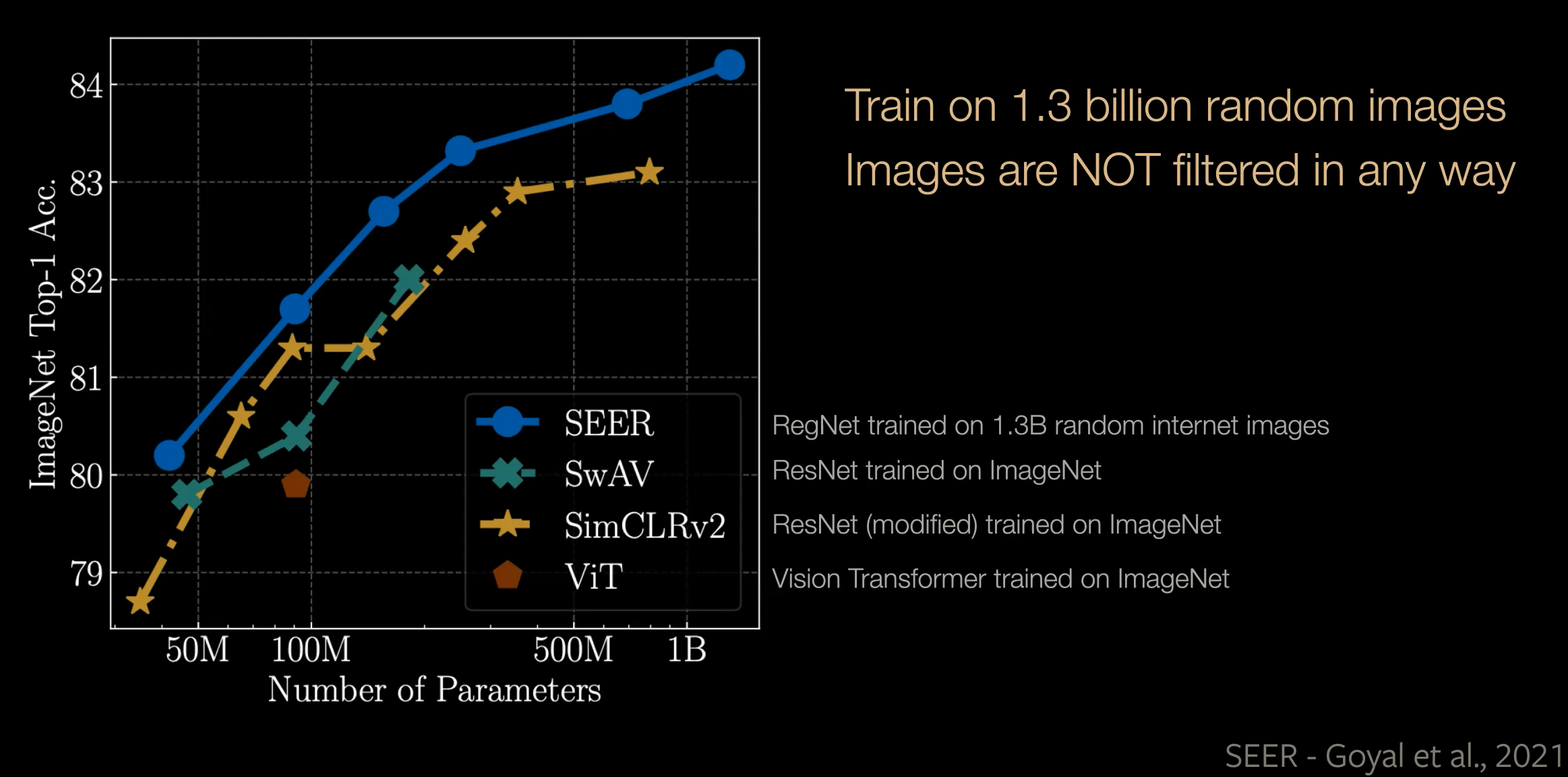
Figure 1 : Comparaison sur ImageNet de SEER à d'autres méthodes
Comme le montre le tableau suivant, les performances de SEER sont comparables à celles des réseaux entraînés sur des données organisées avec une supervision faible.
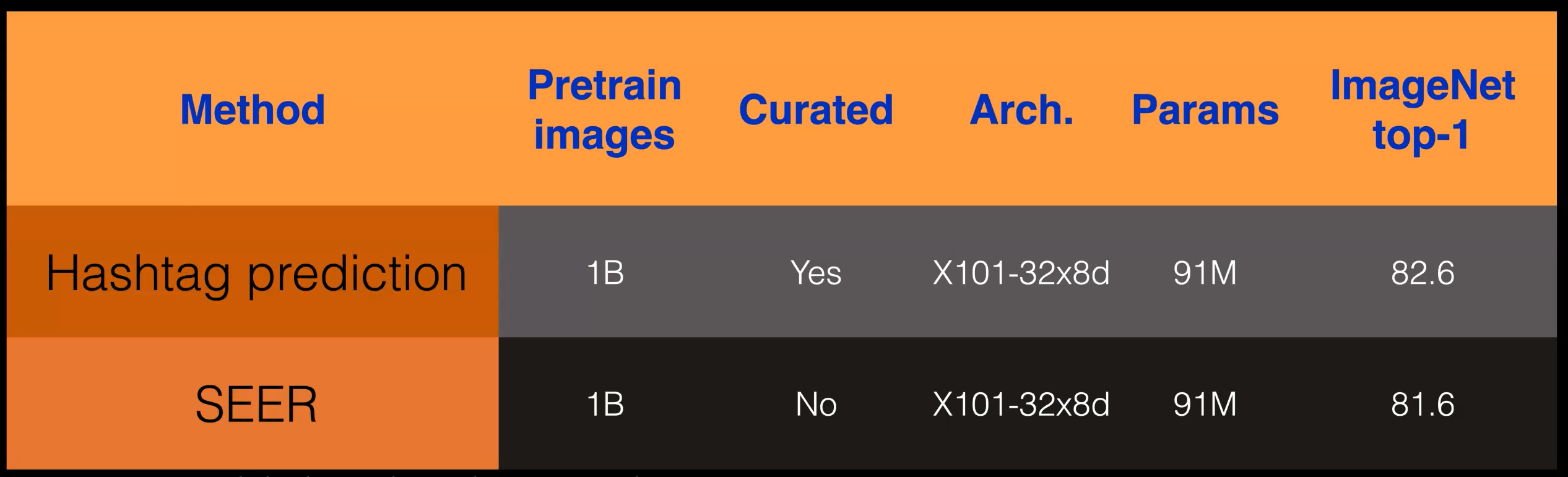
Figure 2 : Performance de SEER par rapport au modèle de supervision faible
AVID + CMA
Audio Visual Instance Discrimination with Cross Modal Agreement est une méthode qui combine l’apprentissage contrastif et les techniques de clustering.
Pour l’apprentissage contrastif sur un jeu de données audio-vidéo, lorsque les entrées (audio-vidéo) sont transmises aux deux encodeurs ($f_a, f_v$), nous obtenons deux enchâssements (audio et vidéo). Les enchâssements d’un même échantillon doivent être proches dans l’espace des caractéristiques par rapport aux enchâssements de différents échantillons.
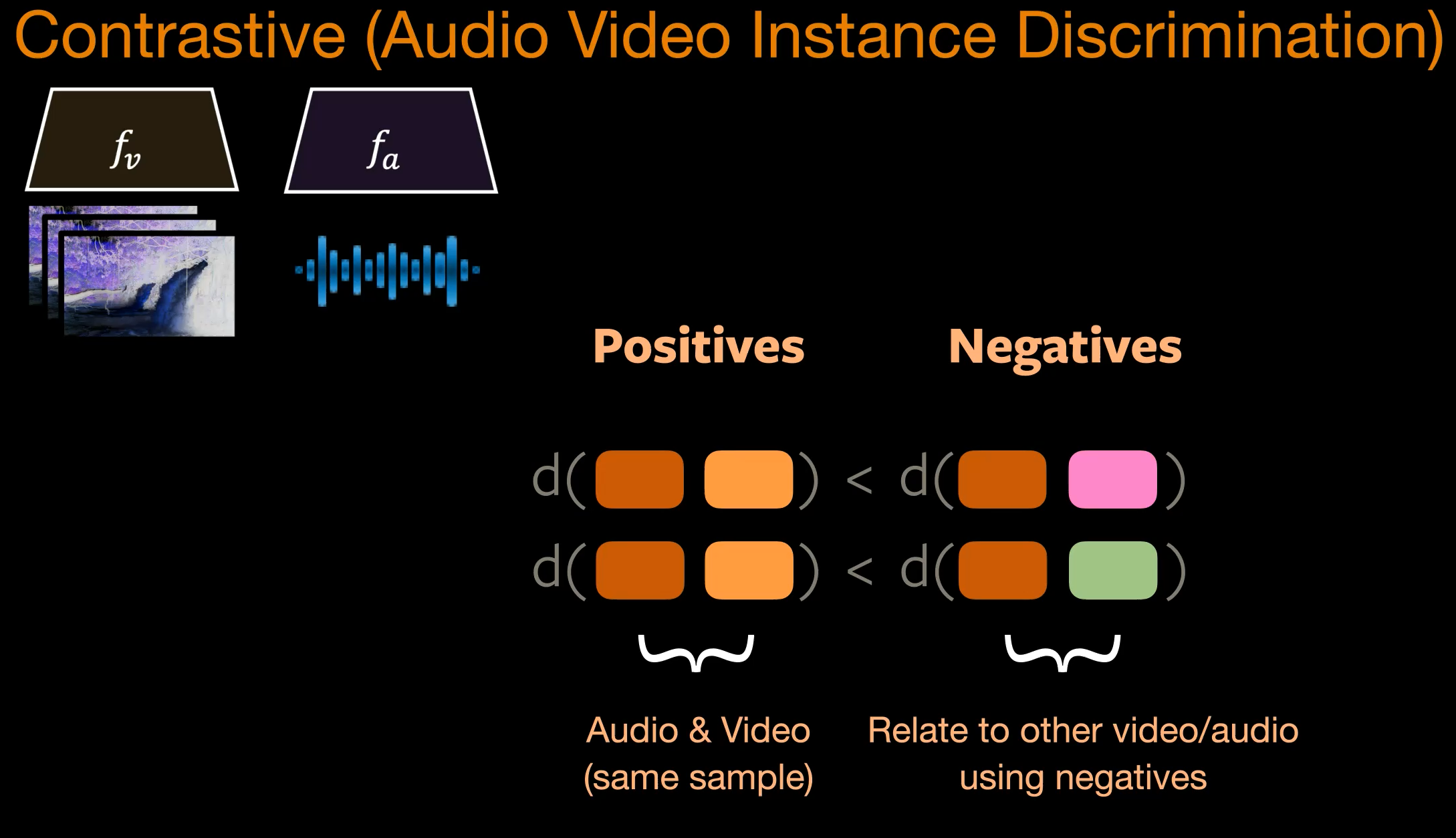
Figure 3 : AVID - Audio Visual Instance Discrimination
Pour introduire le clustering, la notion de positifs et négatifs est étendue comme le montre l’image suivante. Le calcul des similarités dans les enchâssements vidéo et audio à partir d’un point de référence vers tous les autres échantillons donne lieu à un ensemble positif et un ensemble négatif. Un échantillon tombe dans l’ensemble positif lorsque ses enchâssements audio et vidéo sont tous deux similaires aux enchâssements de référence.
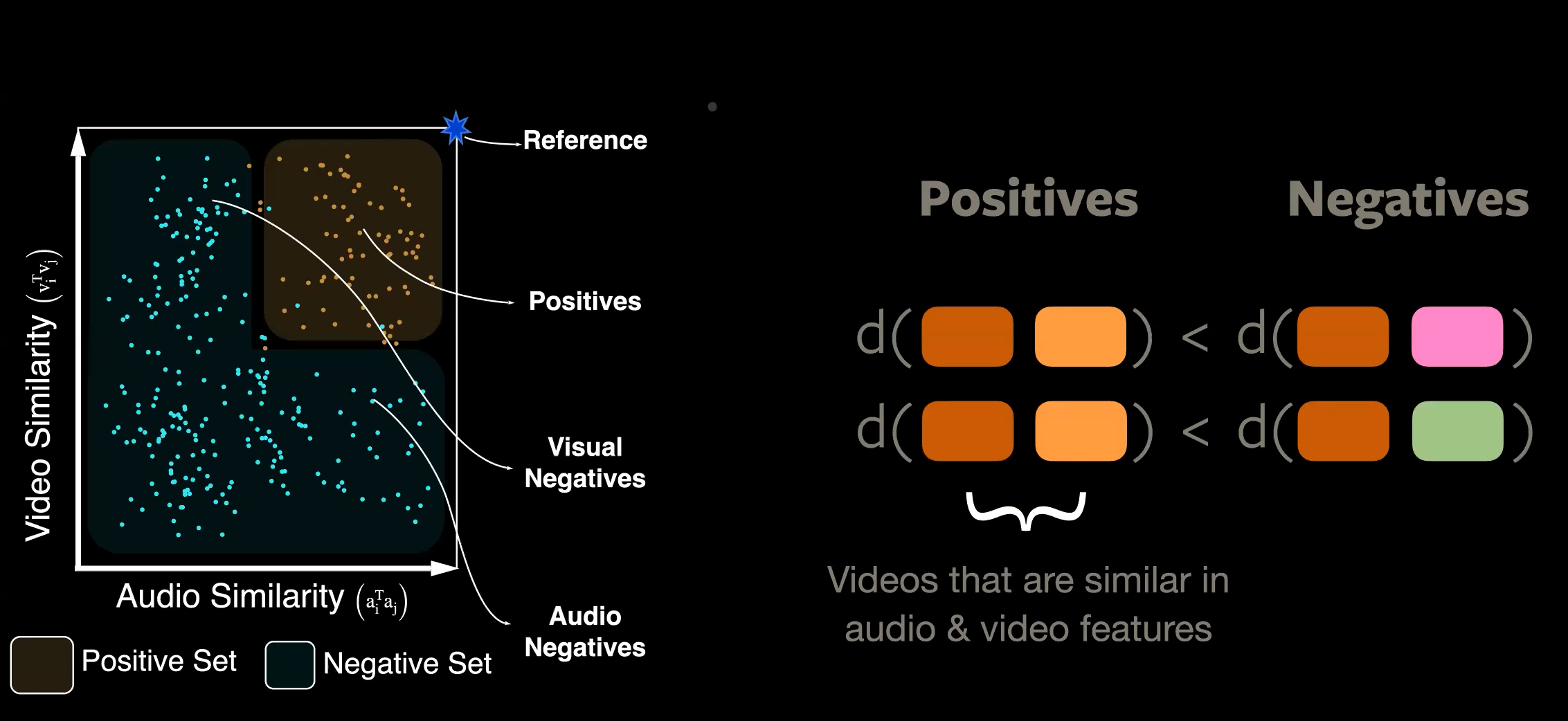
Figure 4 : Cross Modal Agreement (CMA)
Distillation
Les méthodes de distillation sont des méthodes basées sur la maximisation de la similarité. Comme les autres méthodes d’apprentissage autosupervisé, la distillation tente d’empêcher les solutions triviales. Elle le fait par l’asymétrie de deux manières différentes :
- Règle d’apprentissage asymétrique entre l’étudiant et l’enseignant.
- L’architecture asymétrique entre l’étudiant et l’enseignant.
BYOL
BYOL (Bootstrap Your Own Latent) est une technique de distillation dont l’architecture est présentée ci-dessous.
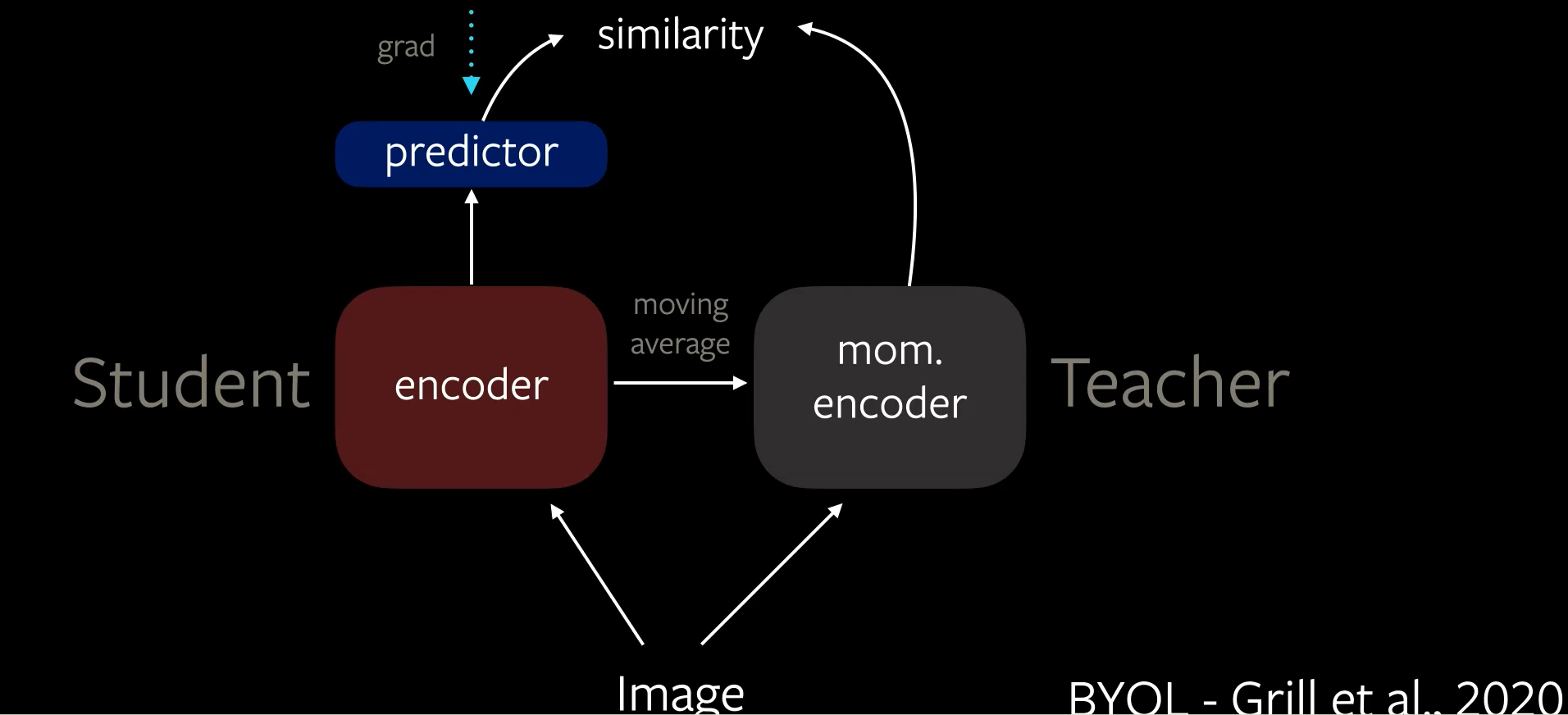
Figure 5 : Architecture BYOL
Il y a une asymétrie dans l’architecture entre l’étudiant et l’enseignant car l’étudiant a une tête de prédiction supplémentaire. La rétropropagation du gradient ne se fait qu’à travers l’encodeur de l’étudiant créant clairement une asymétrie dans le taux d’apprentissage. Dans BYOL, il y a une source supplémentaire d’asymétrie qui se trouve dans les poids de l’encodeur de l’étudiant et de l’encodeur de l’enseignant avec l’encodeur de l’enseignant qui est créé comme une moyenne mobile de l’encodeur de l’étudiant. Ces trois asymétries vont empêcher le modèle d’avoir des solutions triviales.
SimSiam
Des études récentes ont montré que les trois sources d’asymétrie présentes dans BYOL ne sont pas nécessaires pour empêcher les solutions triviales. Dans l’architecture SimSiam (Simple Siamese), l’étudiant et l’enseignant partagent le même ensemble de poids et il existe deux sources d’asymétrie :
- Dans l’architecture de l’encodeur de l’étudiant avec une tête de prédiction supplémentaire.
- Dans le taux d’apprentissage, lors de la rétropropagation, où les gradients ne passent que par l’encodeur de l’étudiant mais pas par celui de l’enseignant. Après chaque époque, les poids de l’encodeur étudiant sont copiés dans l’encodeur de l’enseignant.
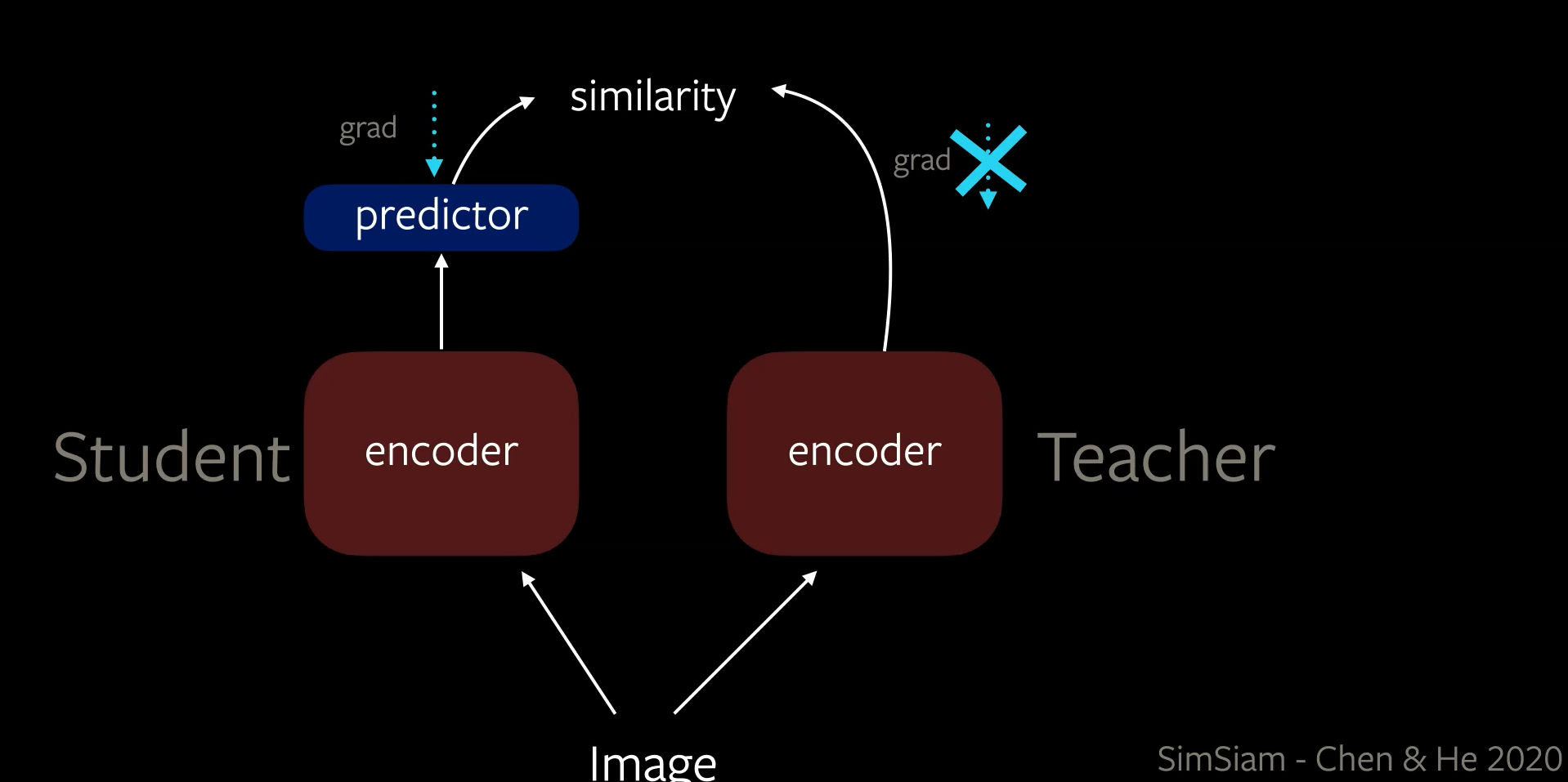
Figure 6 : Architecture de SimSiam
Barlow Twins
Hypothèse issue de la théorie de l’information
L’hypothèse du codage efficace a été proposée par Horace Barlow en 1961 comme modèle théorique du codage sensoriel dans le cerveau. Barlow a émis l’hypothèse que les impulsions électriques dans le cerveau forment un code neuronal permettant de représenter efficacement les informations sensorielles. C’est-à-dire que ce code minimise le nombre d’impulsions nécessaires pour transmettre un signal donné notamment d’un point de vue énergétique notamment. Cette hypothèse est basée sur la théorie de l’information.
Mise en œuvre
La méthode des Barlow Twins propose une fonction objectif qui évite naturellement l’effondrement causé par les solutions triviales. Elle mesure la matrice de corrélation croisée entre les sorties des deux réseaux identiques (ayant préalablement eu en entrée des versions déformées d’un échantillon) et en les rendant aussi proches que possible de la matrice d’identité.
Les vecteurs de représentation des versions déformées d’un échantillon sont ainsi similaires, tout en minimisant la redondance entre les composantes de ces vecteurs (figure 7).
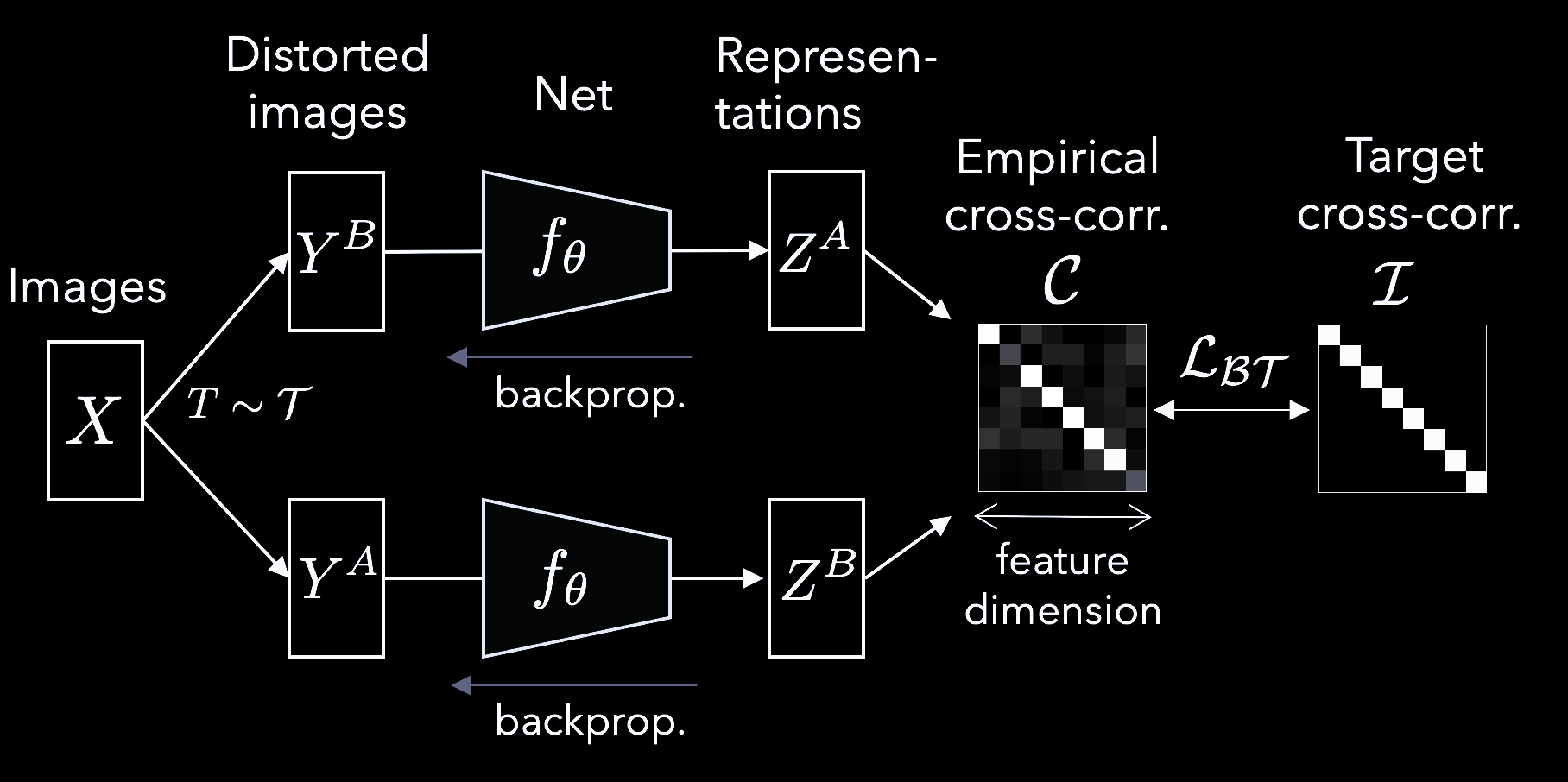
Figure 7 : Architecture des Barlow Twins
Plus formellement, cela produit deux vues déformées pour toutes les images d’un batch $X$. Les vues déformées sont obtenues via une distribution d’augmentations de données $\mathcal{T}$. Les deux batchs de vues déformées $Y^A$ et $Y^B$ sont ensuite soumis à une fonction $f_{\vtheta}$, typiquement un réseau profond avec des paramètres entraînables $\vtheta$, produisant respectivement des batchs de représentations $Z^{A}$ et $Z^{B}$.
La fonction de perte $\mathcal{L_{BT}}$ contient un terme d’invariance et un terme de réduction de la redondance :
\[\mathcal{L_{BT}} \triangleq \underbrace{\sum_i (1-\mathcal{C}_{ii})^2}_\text{terme d'invariance} + ~~\lambda \underbrace{\sum_{i}\sum_{j \neq i} {\mathcal{C}_{ij}}^2}_\text{terme de réduction de la redondance}\]où $\lambda$ est une constante contrôlant l’importance des premier et deuxième termes de la perte. Et on a $\mathcal{C}$ la matrice de corrélation croisée calculée entre les sorties des deux réseaux identiques le long de la dimension du batch :
\[\mathcal{C}_{ij} \triangleq \frac{ \sum_b z^A_{b,i} z^B_{b,j}} {\sqrt{\sum_b {(z^A_{b,i})}^2} \sqrt{\sum_b {(z^B_{b,j})}^2}}\]où $b$ indexe les échantillons de batch et $i,j$ indexe la dimension vectorielle des sorties des réseaux.
$\mathcal{C}$ est une matrice carrée dont la taille correspond à la dimension de la sortie du réseau.
Intuitivement, en essayant d’égaliser les éléments diagonaux de la matrice de corrélation croisée à $1$, le terme d’invariance de l’objectif rend la représentation invariante aux distorsions appliquées.
En essayant d’égaliser les éléments hors diagonale de la matrice de corrélation croisée à $0$, le terme de réduction de la redondance décorréle les différentes composantes vectorielles de la représentation.
Cette décorrélation réduit la redondance entre les unités de sortie, de sorte que les unités de sortie contiennent des informations non redondantes sur l’échantillon.
📝 Duc Anh Phi, Krishna Karthik Reddy Jonnala
Loïck Bourdois
17 May 2021