Introduction aux auto-encodeurs
🎙️ Alfredo CanzianiApplications de l’auto-encodeur
DALL-E : Création d’images à partir de texte
DALL-E (publié par OpenAI) est un réseau neuronal basé sur l’architecture Transformer créant des images à partir de légendes de texte. Il s’agit d’une version à $12$ milliards de paramètres de GPT-3 entraînée sur un jeu de données de paires texte-image.

Figure 1 : DALL-E : entrée-sortie
Rendez-vous sur le site d’Open AI pour jouer avec les légendes !
Auto-encodeur
Définitions
Entrée
-
$\vx$ : est observé à la fois pendant l’apprentissage et le test
-
$\vy$ : est observé pendant l’apprentissage mais pas pendant le test
-
$\vz$ : n’est pas observé (ni pendant l’apprentissage ni pendant le test)
Sortie
-
$\vh$ : est calculé à partir de l’entrée (cachée/interne)
-
$\vytilde$ : est calculé à partir de la cachée (prédit $\vy$, ~ signifie circa)
Vous êtes confus ?
Reportez-vous à la figure ci-dessous pour comprendre l’utilisation des différentes variables dans différentes techniques d’apprentissage automatique.
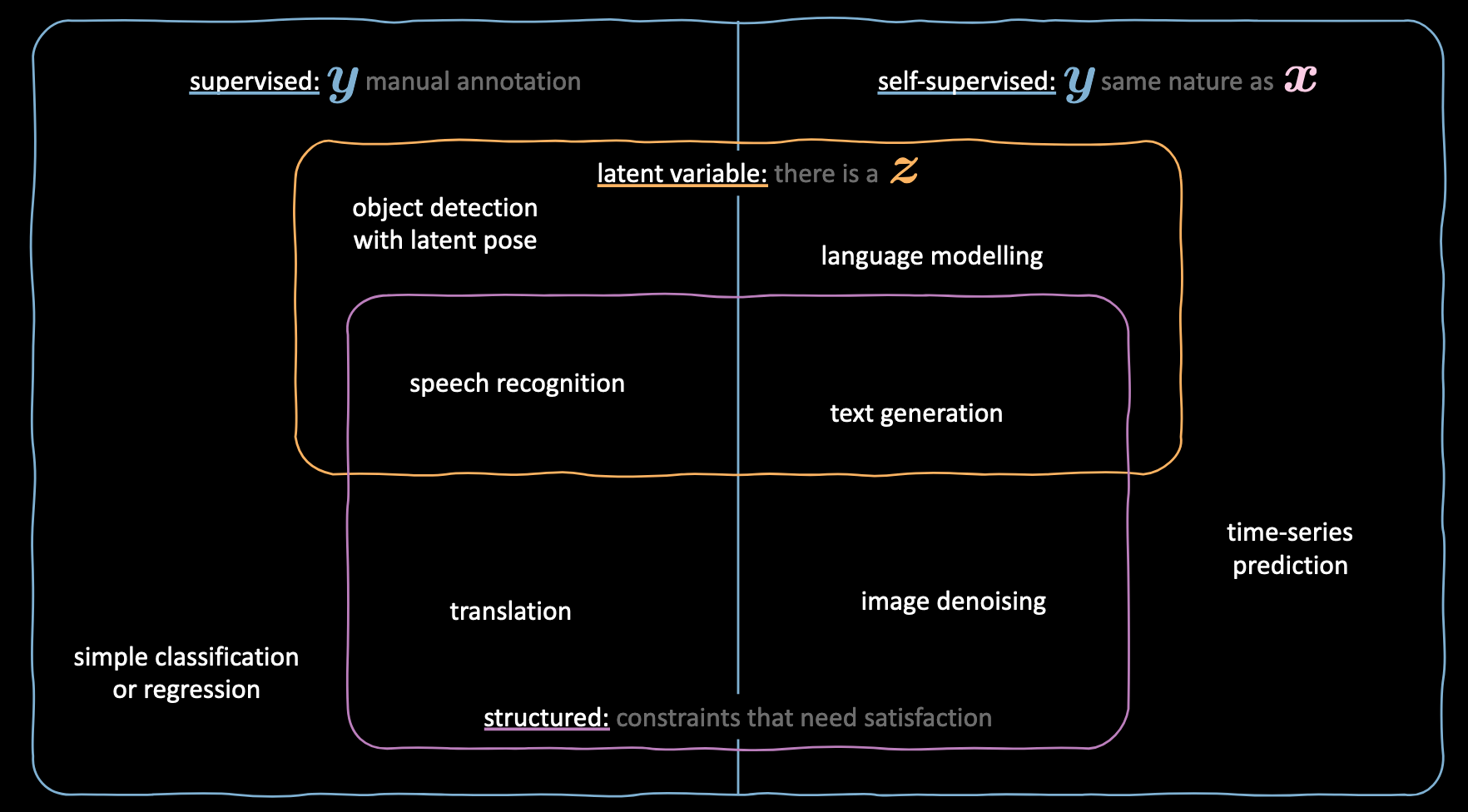
Figure 2 : Définitions des variables dans les différentes techniques d'apprentissage automatique
Introduction
Ces types de réseaux sont utilisés pour apprendre la structure interne d’une entrée et l’encodeur dans une représentation interne cachée $\vh$.
Nous avons déjà appris à entraîner des modèles à base d’énergie, regardons le réseau ci-dessous :
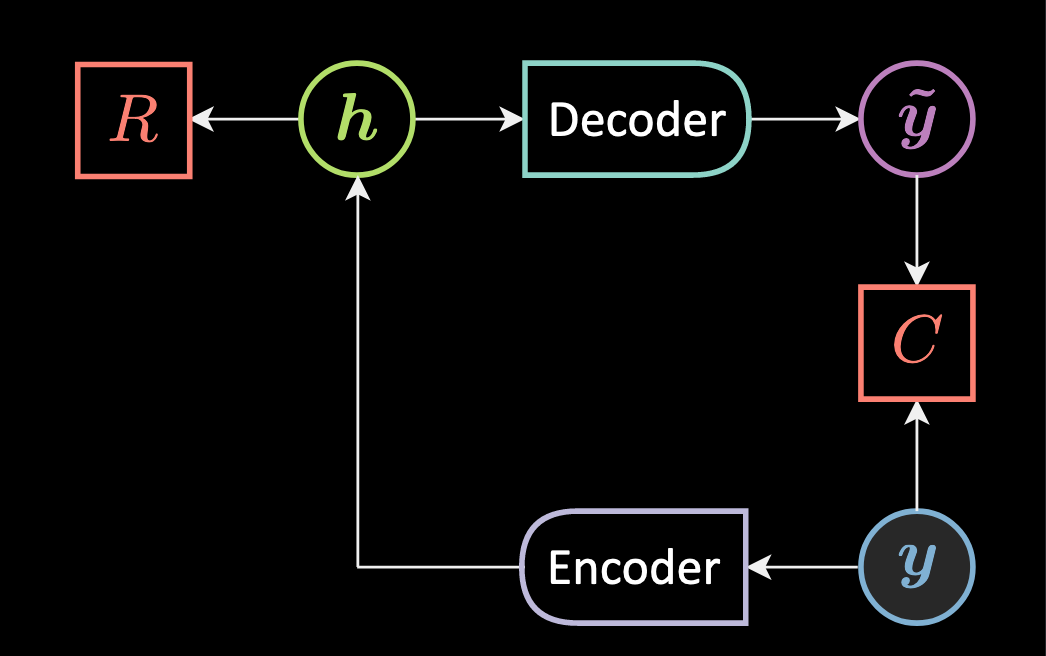
Figure 3 : Architecture de l'auto-encodeur
Ici, au lieu de calculer la minimisation de l’énergie $\red{E}$ pour $\vz$, on utilise un encodeur qui approxime la minimisation et fournit une représentation cachée $\vh$ pour une $\vy$ donnée.
\[\vh = \Enc(\vy)\]Ensuite, la représentation cachée est convertie en $\vytilde$ (ici nous n’avons pas de prédicteur, nous avons un encodeur).
\[\vytilde= \Dec(\vh)\]En gros, $\vh$ est la sortie d’une fonction d’écrasement $f$ de la rotation de notre entrée/observation $\vy$.
$\vytilde$ est la sortie de la fonction d’écrasement $g$ de la rotation de notre représentation cachée $\vh$.
Notez qu’ici, $\vy$ et $\vytilde$ appartiennent tous deux au même espace d’entrée et $\vh$ appartiennent à $\mathbb{R}^d$ qui est la représentation interne. $\mW_h$ et $\mW_y$ sont des matrices de rotation.
\[\vy, \vytilde \in \mathbb{R}^n \\ \vh \in \mathbb{R}^d \\ \mW_h \in \mathbb{R}^{d \times n} \\ \mW_y \in \mathbb{R}^{n \times d}\]C’est ce qu’on appelle un auto-encodeur. L’encodeur effectue un amortissement et nous n’avons pas à minimiser l’énergie $\red{E}$ mais $\red{F}$ :
\[\red{F}(\vy) = \red{C}(\vy,\vytilde) + \red{R}(\vh)\]Coûts de reconstruction
Vous trouverez ci-dessous deux exemples d’énergies de reconstruction :
Entrée à valeur réelle :
\[\red{C}(\vy,\vytilde) = \Vert{\vy-\vytilde}\Vert^2 = \Vert \vy-\Dec[\Enc(\vy)] \Vert^2\]C’est la distance euclidienne carrée entre $\vy$ et $\vytilde$.
Entrée binaire
Dans le cas d’une entrée binaire, nous pouvons simplement utiliser l’entropie croisée binaire :
\[\red{C}(\vy,\vytilde) = - \sum_{i=1}^n{\vy{_i}\log(\vytilde{_i}) + (1-\vy{_i})\log(1-\vytilde{_i})}\]Fonctions de perte
Moyenne sur tous les échantillons d’entraînement de la fonction de perte par échantillon :
\[\mathcal{L}(\red{F}(\cdot),\mY) = \frac{1}{m}\sum_{j=1}^m{\ell(\red{F}(\cdot),\vy^{(j)})} \in \mathbb{R}\]Nous prenons la perte d’énergie et essayons de pousser l’énergie vers le bas sur ${vytilde$$
\[\ell_{\text{energy}}(\red{F}(\cdot),\vy) = \red{F}(\vy)\]Cas d’utilisation
La taille de la représentation cachée $\vh$ obtenue à l’aide de ces réseaux peut être aussi bien plus petite que plus grande que la taille de l’entrée.
Si nous choisissons une $\vh$ plus petite, le réseau peut être utilisé pour la réduction non linéaire de la dimensionnalité.
Dans certaines situations, il peut être utile d’avoir un $\vh$ plus grand que l’entrée, cependant, dans ce scénario, un auto-encodeur simple s’effondrerait. En d’autres termes, puisque nous essayons de reconstruire l’entrée, le modèle est enclin à copier toutes les caractéristiques d’entrée dans la couche cachée et à les transmettre comme sortie. Il se comporte ainsi essentiellement comme une fonction d’identité. Il faut éviter ça car cela signifierait que notre modèle n’apprend rien.
Pour éviter que le modèle ne s’effondre, nous devons utiliser des techniques qui limitent la quantité de régions pouvant prendre des valeurs d’énergie nulles ou faibles. Ces techniques peuvent être une sorte de régularisation telle que des contraintes d’éparsité, l’ajout de bruit supplémentaire ou l’échantillonnage.
Auto-encodeur débruiteur
Nous ajoutons une augmentation/corruption comme un bruit gaussien à une entrée échantillonnée à partir de la variété d’apprentissage $\vyhat$ avant de la donner au modèle. Nous nous attendons à ce que l’entrée reconstruite $\vytilde$ soit similaire à l’entrée originale $\vy$.
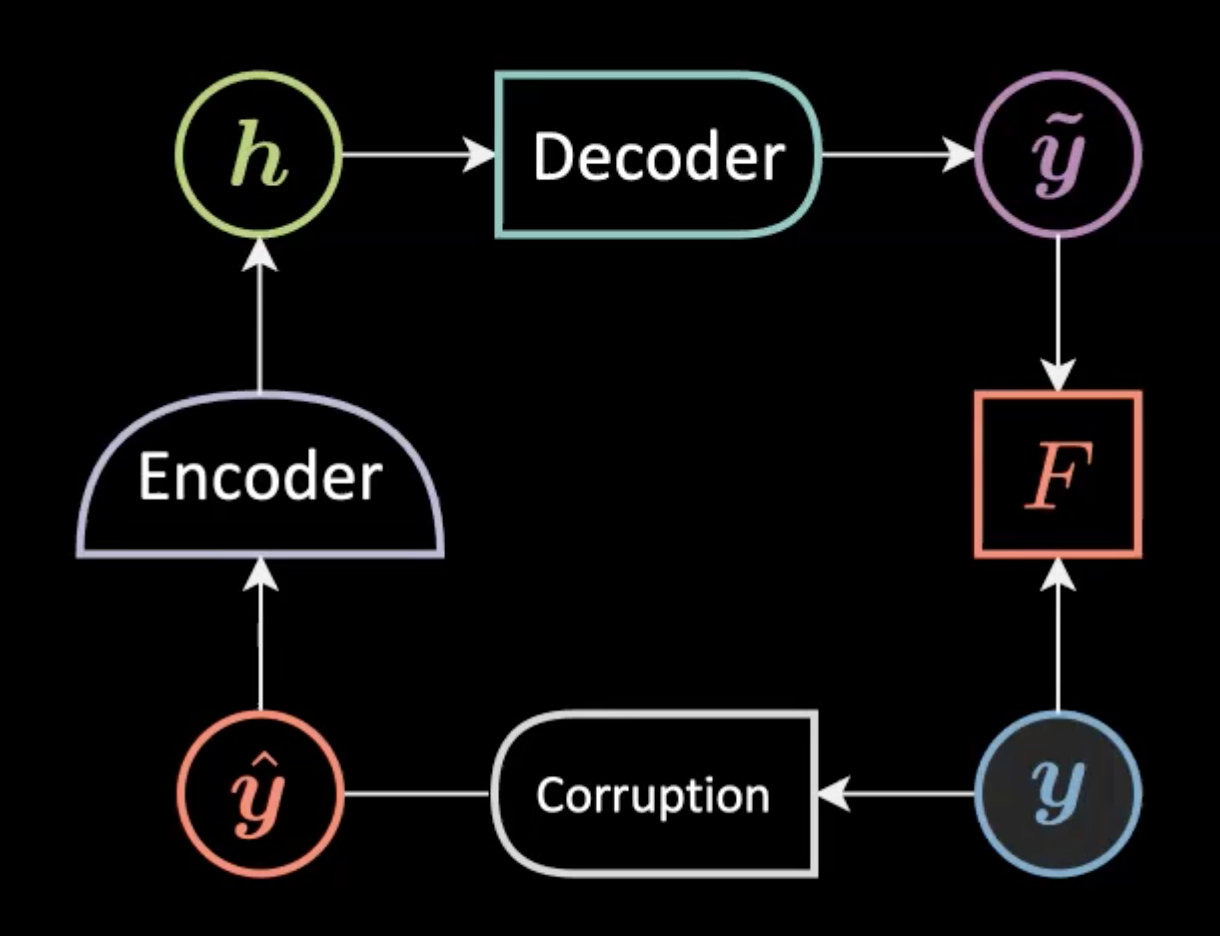
Figure 4 : Architecture du réseau de l'auto-encodeur débruiteur
Une note importante : le bruit ajouté à l’entrée originale doit être similaire à ce que nous attendons dans la réalité afin que le modèle puisse facilement s’en remettre.
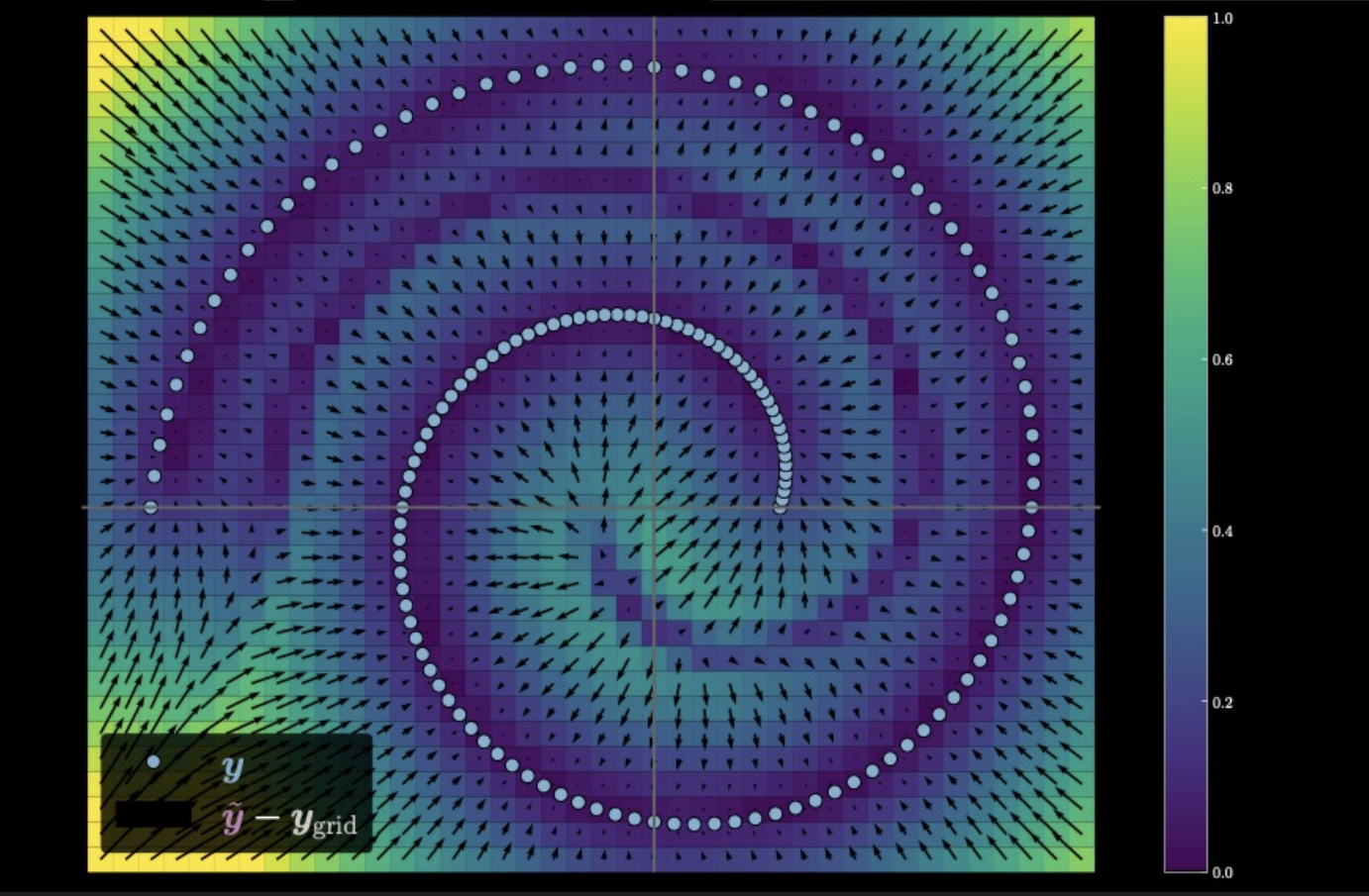
Figure 5 : Mesure de la distance de déplacement des données d'entrée.
Dans l’image ci-dessus, les points de couleur claire sur la spirale représentent la variété de données originale. En ajoutant du bruit, on s’éloigne des points originaux. Ces points avec bruit sont introduits dans l’auto-encodeur pour générer ce graphique. La direction de chaque flèche pointe vers le point de données original vers lequel le modèle pousse le point avec bruit, tandis que la taille de la flèche indique de combien. Nous voyons également une région en violet foncé en forme de spirale car les points de cette région sont équidistants de deux points sur la variété de données.
📝 Vidit Bhargava, Monika Dagar
Loïck Bourdois
18 March 2021