解码语言模型
🎙️ Mike Lewis集束搜索
集束搜索是用于解码语言模型并生成文本的另一种技术。 在每一步中,该算法都会跟踪$ k $最有可能(最好)的部分翻译(假设)。 每个假设的得分等于其对数概率。
该算法选择最佳评分假设。
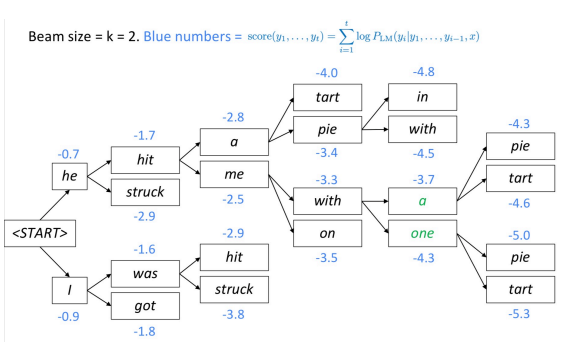
Fig. 1: 集束编码
束树的分支深度有多深?
束树一直持续到到达句子标记的结尾为止。 输出句子标记的结尾后,假设就完成了。
为什么(在NMT中)很大的集束通常会导致空的平移?
在训练时,该算法通常不使用波束,因为它非常珍贵。 相反,它使用自回归因式分解(鉴于先前的正确输出,预测$ n + 1 $个第一个单词)。 该模型在训练期间不会暴露于自身的错误,因此“胡说八道”有可能出现在光束中。
总结:持续进行集束搜索,直到所有$ k $假设都产生结束令牌或直到达到最大解码限制T。
采样
我们可能不想要最可能的顺序。 相反,我们可以从模型分布中采样。
但是,从模型分布中采样会带来自己的问题。 一旦对“不良”选择进行了采样,模型就处于训练期间从未面临的状态,从而增加了继续进行“不良”评估的可能性。 因此,该算法可能陷入糟糕的反馈循环中。
Top-K 采样
一种纯采样技术,您可以将分布截断为$ k $最佳值,然后对分布重新进行归一化和采样。
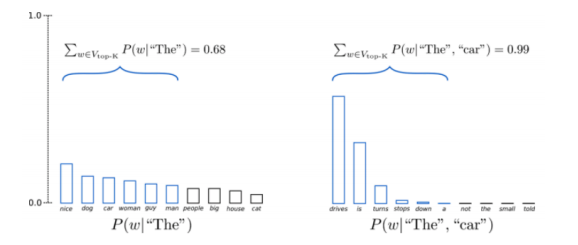
Fig. 2: Top K 采样
问题:为什么Top-K采样效果如此好?
这个方法之所以有效,是因为当我们仅通过使用分布的头部并切掉尾部来采样不好的东西时,它实际上是在试图防止掉好语的歧义。
文字生成评估
评估语言模型仅需要记录保留数据的可能性。 但是,很难评估文本。 通常,会使用带有参考的单词重叠量度(BLEU,ROUGE等),但是它们有自己的问题。
序列到序列模型
条件语言模型
条件语言模型对于生成英语的随机样本不是有用的,但是对于在给定输入的情况下生成文本是有用的。
例子:
-给定法语句子,生成英语翻译 -给定文档,生成摘要 -进行对话后,产生下一个回应 -给定问题,生成答案
###序列到序列模型
通常,输入文本是经过编码的。 这种结果的嵌入称为“思想向量”,然后将其传递到解码器以逐字生成令牌。
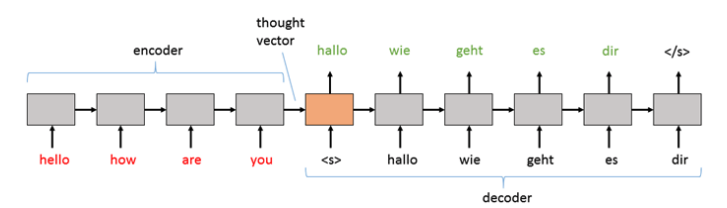
Fig. 3: 思想向量
###序列转换器
转换器的时序变化有2个堆栈:
1.编码器堆栈–不会注意自我注意,因此输入中的每个令牌都可以查看输入中的其他所有令牌
2.解码器堆栈–除了专注于自身之外,它还专注于完整的输入
Fig. 4: 序列转换器
输出中的每个标记都直接连接到输出中的每个先前标记,并且还直接连接到输入中的每个单词。 连接使模型表现力强。 这些转换器在翻译得分方面比以前的递归和卷积模型有所改进。
回译
在训练这些模型时,我们通常依赖大量的带标签文本。 良好的数据来源来自欧洲议会的议事程序-文本被手动翻译成不同的语言,然后我们可以将其用作模型的输入和输出。
###问题
-并非所有的语言都在欧洲议会中代表,这意味着我们不会获得我们可能会感兴趣的所有语言的翻译对。我们如何找到用于训练的文本却不一定能获得其数据的语言? -由于转换器这样的模型在处理更多数据时表现更好,因此我们如何有效地使用单语文本,即没有输入/输出对?
假设我们要训练一个将德语翻译成英语的模型。回译的想法是首先训练英语到德语的反向模型
-使用一些有限的双向文本,我们可以获取2种不同语言的相同句子 -一旦有了英语到德语的模型,就可以将很多单语单词从英语翻译成德语。
最后,使用在上一步中已“反向翻译”的德语单词训练德语到英语模型。我们注意到:
-反向模型的好坏并不重要-我们可能会有嘈杂的德语翻译,但最终翻译成纯净的英语。 -我们需要学会超越英语/德语对的数据(已经翻译)理解英语-使用大量的单语英语
###迭代反向翻译
-我们可以迭代回译的过程,以生成更多的双向文本数据并达到更好的性能-只需继续使用单语数据进行培训即可。 -在并行数据不多的情况下有很大帮助
##大型多语言MT
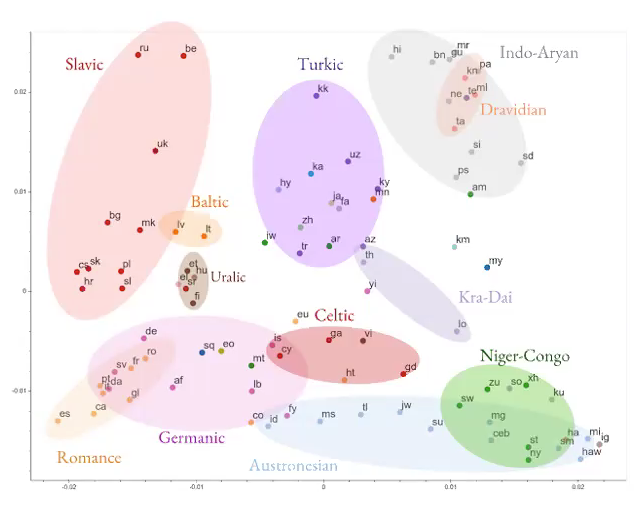
Fig. 5:多语言 MT
-与其尝试学习一种语言到另一种语言的翻译,不如建立一个神经网络来学习多种语言的翻译。 -模型正在学习一些与语言无关的常规信息。

Fig. 6: 多语言 NN 结果
效果非常好,尤其是当我们想要训练模型以将其翻译成对我们来说没有太多可用数据的语言(资源匮乏的语言)时。
NLP的无监督学习
有大量文本,没有任何标签,很少有监督数据。 仅阅读未标记的文本,我们可以了解多少种语言?
###word2vec
直觉-如果单词在文本中并排出现,可能很相关,所以我们希望通过查看未标记的英语文本,我们可以了解它们的含义。
-目标是学习单词的向量空间表示(学习嵌入)
预训练任务-遮掩一些单词,并使用相邻的单词填充空白。

Fig. 7: word2vec 遮掩可视化
例如,这里的想法是,“角兽”和“银发”比其他动物更容易出现在“独角兽”的背景下。
拿出单词并应用线性投影
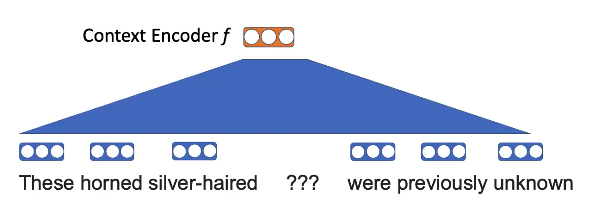
Fig. 8: word2vec 词嵌
想知道
\[p(\ texttt {unicorn} \ mid \ texttt {这些银发的???以前是未知的})\] \[p(x_n \ mid x _ {-n})= \ text {softmax}(\ text {E} f(x _ {-n}))))\]词嵌入具有某种结构
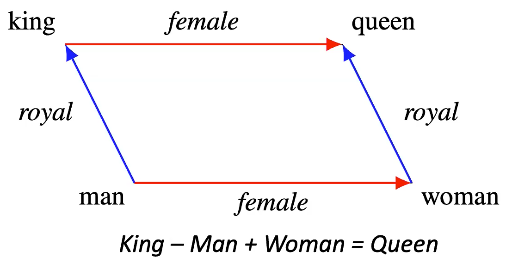
Fig. 9: 词嵌结构举例
-这个想法是,如果我们在训练后将“国王”的嵌入内容加上“女性”的嵌入内容,将得到非常接近“女王”的嵌入内容 -显示向量之间的一些有意义的差异
####问题:单词表示形式是依赖于上下文还是独立于上下文?
独立且不知道它们与其他单词的关系
####问题:这个模型可能会遇到什么情况的例子?
单词的解释在很大程度上取决于上下文。因此,在含糊的单词(可能具有多种含义的单词)的情况下,由于嵌入向量无法捕获正确理解该单词所需的上下文,因此该模型将难以解决。
GPT
要添加上下文,我们可以训练条件语言模型。然后给定该语言模型,该语言模型在每个时间步预测一个单词,将模型的每个输出替换为其他功能。
-预训练-预测下一个字 -微调-更改为特定任务。例子: -预测名词还是形容词 -给出一些包含亚马逊评论的文字,预测评论的情感评分
这种方法很好,因为我们可以重用模型。我们预训练一个大型模型,并可以微调其他任务。
ELMo
GPT仅考虑向左上下文,这意味着该模型不能依赖任何将来的单词-这限制了该模型可以做的很多事情。
这里的方法是训练两种语言模型
-文字从左到右 -文字从右到左 -连接两个模型的输出以获得单词表示形式。现在可以同时在向右和向左上下文中进行调节。
这仍然是“浅”的组合,我们希望左右上下文之间进行一些更复杂的交互。
BERT
BERT与word2vec相似,因为我们也有一个空白任务。但是,在word2vec中,我们有线性投影,而在BERT中,有一个大型的变压器,可以查看更多上下文。为了进行训练,我们屏蔽了15%的代币,并尝试预测空白。
可以扩大BERT(RoBERTa)的规模:
-简化BERT预训练目标 -扩大批量 -在大量GPU上训练 -训练更多文字
在BERT性能的基础上进行更大的改进-在问答任务性能方面,现在是超人的。
预训练 NLP
监督的预训练方法。
-XLNet:
XLNet无需独立地有条件地预测所有被屏蔽的令牌,而是以随机顺序自动回归地预测被屏蔽的令牌。
-SpanBERT
掩码跨度(连续单词的顺序)而不是标记
-ELECTRA::
而不是掩盖单词,我们用类似的标记代替标记。然后,我们通过尝试预测令牌是否已被替换来解决二进制分类问题。
-ALBERT:
Lite Bert:我们对BERT进行修改,方法是在各层之间绑上权重,使其更轻。这减少了模型的参数和所涉及的计算。有趣的是,ALBERT的作者不必在准确性上做出太多妥协。
-XLM:
多语言BERT:我们不提供此类英文文本,而是提供多种语言的文本。不出所料,它更好地学习了跨语言的联系。
上面提到的不同模型的主要收获是
-许多不同的预训练目标都能很好地发挥作用!
-建模单词之间的深层双向交互至关重要
-通过扩大预训练获得巨大收益,尚无明确限制
上面讨论的大多数模型都是为解决文本分类问题而设计的。然而,为了解决文本生成问题,就像seq2seq模型一样,我们顺序地生成输出,我们需要一种稍微不同的方法进行预训练。
####条件生成的预训练:BART和T5
BART:通过消噪文本来预训练seq2seq模型
在BART中,为了进行预训练,我们采用一个句子并通过随机屏蔽标记来破坏它。我们没有预测掩蔽标记(就像在BERT目标中一样),而是提供了整个损坏的序列并尝试预测整个正确的序列。
这种seq2seq的预训练方法为我们提供了设计腐败方案的灵活性。我们可以随机播放句子,删除短语,引入新短语等。
BART能够在SQUAD和GLUE任务上匹配RoBERTa。但是,它是关于摘要,对话和抽象QA数据集的新SOTA。这些结果加强了我们使用BART的动力,在文本生成任务方面比BERT / RoBERTa更好。
NLP中一些未解决的问题
-我们应该如何整合世界知识 -如何建模长文档? (基于BERT的模型通常使用512个令牌) -我们如何最好地进行多任务学习? -我们可以用更少的数据进行微调吗? -这些模型真的了解语言吗?
###总结
-在大量数据上的训练模型优于对语言结构进行显式建模。
从偏差方差的角度来看,变形金刚是低偏差(非常具有表现力)模型。向这些模型提供大量文本要比对语言结构进行显式建模(高偏差)更好。架构应通过瓶颈压缩序列
-通过预测未标记文本中的单词,模型可以学到很多关于语言的知识。事实证明,这是一个很好的无监督学习目标。这样就可以轻松微调特定任务
-双向上下文至关重要
###课后问题的其他见解:
量化“理解语言”有哪些方法?我们怎么知道这些模型真正理解语言?
“奖杯因为太大而无法放入手提箱。”:解决这句话中的“ it”对于机器来说是棘手的。人类擅长于此任务。有一个数据集,其中包含如此困难的示例,并且人类该数据集具有95%的性能,在Transformers带来革命之前,计算机程序只能实现约60%的性能,现代Transformer模型能够在该数据集上实现90%以上的性能,这表明这些模型不仅仅是在记忆/利用数据,但通过数据中的统计模式学习概念和对象。
此外,BERT和RoBERTa在SQUAD和Glue上实现了超人的性能。 BART生成的文本摘要对人类来说非常真实(BLEU分数很高)。这些事实证明了模型确实可以某种方式理解语言。
####地面语言
有趣的是,讲师(FAIR研究科学家迈克·刘易斯)正在研究一种名为“地面语言”的概念。该研究领域的目的是建立能够聊天或谈判的对话主体。与文本分类或文本摘要相比,聊天和谈判是目标不明确的抽象任务。
####我们可以评估模型是否已经具有世界知识吗?
“世界知识”是一个抽象概念。通过向他们询问有关我们感兴趣的概念的简单问题,我们可以从最基本的层面测试模型以了解他们的世界知识。像BERT,RoBERTa和T5这样的模型具有数十亿个参数。考虑到这些模型是在庞大的信息文本库(如Wikipedia)上进行训练的,它们将使用其参数存储事实并能够回答我们的问题。此外,我们还可以考虑在对某些任务进行模型微调之前和之后进行相同的知识测试。这将使我们对模型已“遗忘”了多少信息有所了解。
📝 Trevor Mitchell, Andrii Dobroshynskyi, Shreyas Chandrakaladharan, Ben Wolfson
20 Apr 2020