自我監督學習-物以類聚法和PIRL
🎙️ Ishan Misra“前置”任务中到底差了什么东西呢?
前置任务通常都包含前置步骤,也就是自我监督部份,和之后就是我们的转移任务,也就一般是分类任务或物体任务。我们希望前置任务和转移任务都可以「对齐」,意思是解开前置任务会很好地帮助解决转移任务的问题。所以,很多研究都以设计前置任务和实现这些任务为主要。
不过,还是不清楚为什么履行一个非语义任务就可以生成好的特征?比如,为什么我们期望去学习「语义」来尝试去解决一些好像拼图游戏这样的东西?或为什么应该去「预测主题标签」来在一些转移了的任务上更好的去分类物件呢?所以,问题也还是存在。到底我们应该如何去设计一个好的前置任务来很好地对齐转移任务呢?
其一个去评估这个问题的方法就是去看看每一层中的「表示」(请参阅图1)。如果最后一层中的「表示」不是对齐好转移任务,那个前置任务就或许不是用来解决的正确任务。
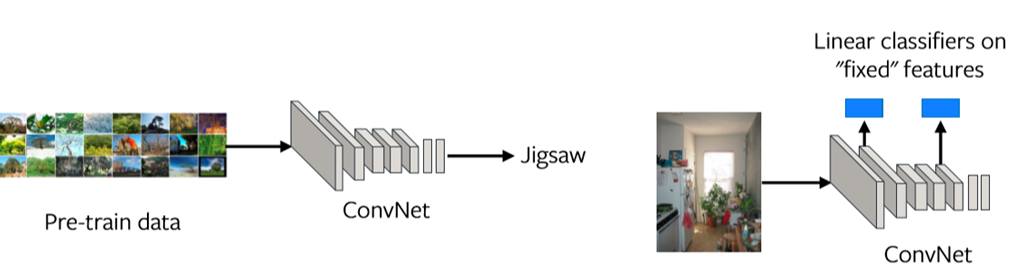
图 1: 每一层的特征「表示」
图2 用拼图式前置训练来在VOC07上的线性分类器绘制出每一层的平均精度均值。可以很清楚的看到最后一层是专门用在拼图问题上。
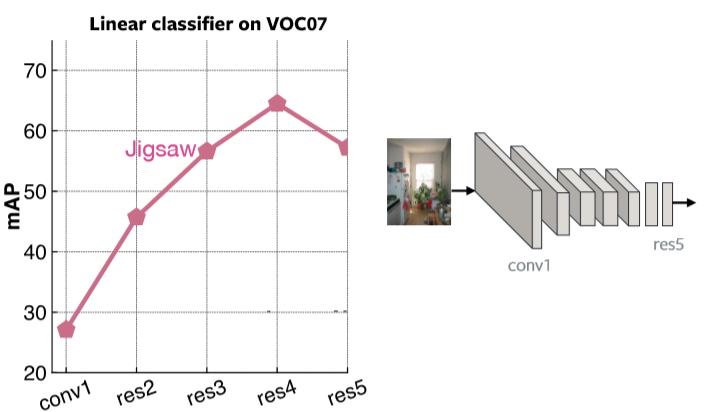
图 2: 用基于拼图的方法的每一层的效能
到底我们想在预先训练过的模型中想要什么「特征」呢?
-
如何去表示出图片们如何相互关联
- 物以類聚法: 去增强视觉性「表示」的通用性
-
不受”干扰性因素”影响–不变性
例如:物体的实际位置﹑灯光﹑实际的颜色
- 例如:物体的实际位置﹑灯光﹑实际的颜色
两种方法来达到上方的属性,就是 「类聚」和 「对比式学习」。它们已经比前置任务本身的任务表现出更好的效能。其一个属于类聚的方法是物以類聚法 和另一个属于不变性的是PIRL。
物以類聚法:提高视觉性「表示」的通用性
把特征的空间类聚已来是一个去看出那些图像相互关联的方法。
方法
物以類聚法遵循这两个步骤。一个是类聚步骤,而另一个是预测步骤。
类聚:特征类聚
我们先取一个预先训练过的网络,然后用它来在图片们中取一堆特征。这个网路可以是任何一种预先训练过的网络。 K均值类聚然后就在这些特征中运行,所可那样每一张图片就如物以类聚那样类聚在一个属于自己的群中,然后那就图以群分那样成为图片的标签。

图 3: 类聚步骤
适宜性: 预测那一个群的任务,
这一步,我们重头来训练一个网路来预测图像的拟似标签。这些拟似标签由第一步由的物以类聚然后群分得来的拟似标签。
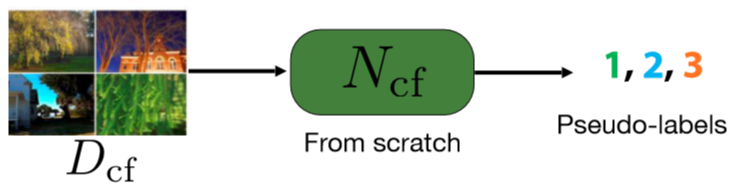
图 4: 预测步骤
一个标准的预先训练和转移任务就是这样,先预先训练一个网络,之后就在后期任务中评估这个网络,如图5第一行中显示出来的那样。在数据集$D_{cf}$中使用物以类聚式 来生成多个群。我们之后就由无到有那样在这个数据中学到一个网路$N_{pre}$。最后,使用$N_{cf}$在所有后期工作。
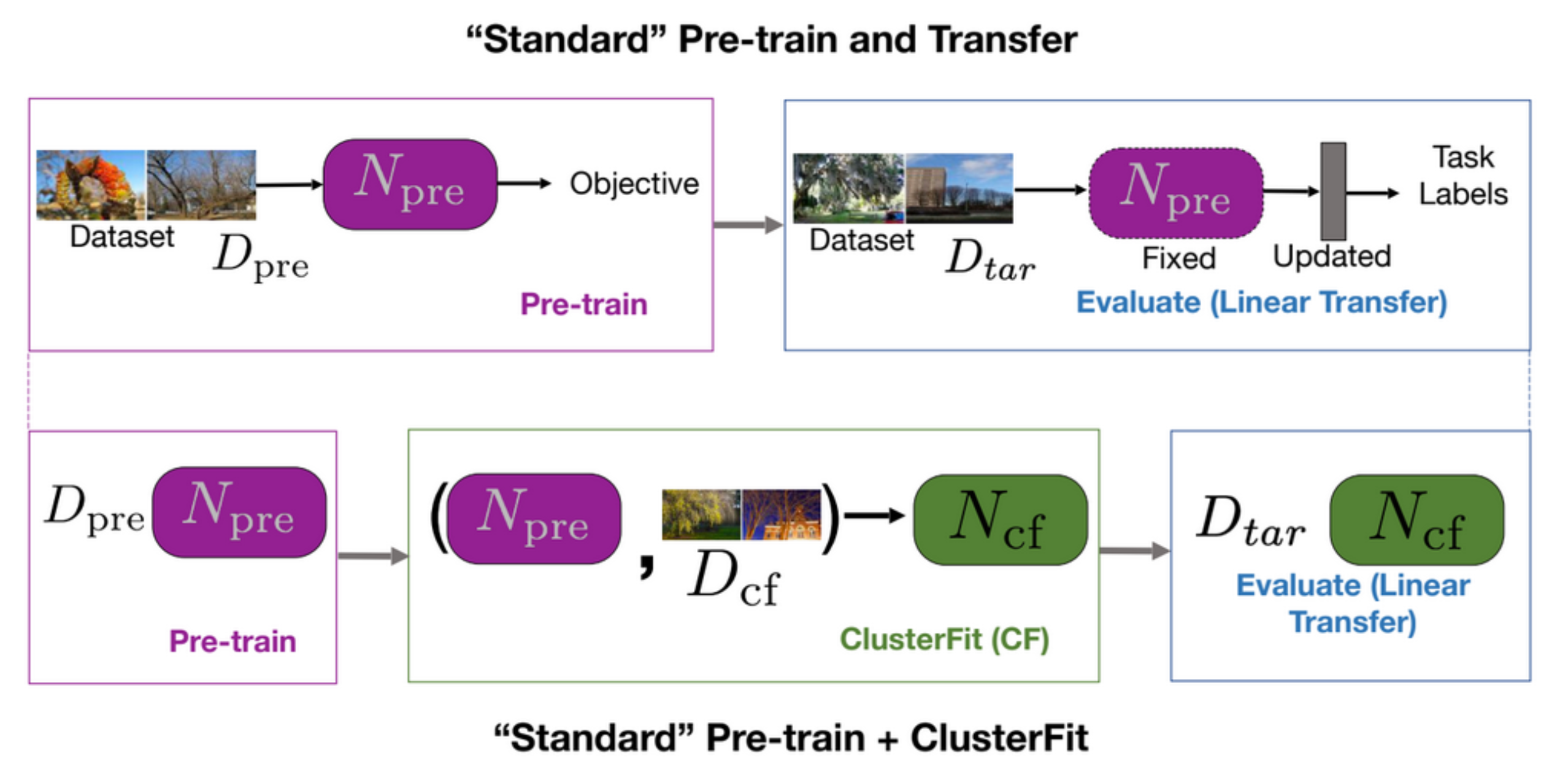
图 5: "标准" 预先训练+转移 VS "标准" 预先训练+物以类聚式
为什么物以类聚法能行
原因为什么物以类聚式能行是因为在物以类聚步骤中,只有必要的信息被抓取起来,而人工性的就会抛弃,令第二个网路学到一些更通用的。
要明白这点,来进行一个相当简单的实验。我们加标签性噪声到ImageNet-1K,在这个数据集上训练这个网路。然后,我们在后期工作中,就在ImageNet-9K中评估这个网路的「特征表示」。就如它在图6中所示的那样,我们加不同数量的标签性噪声到ImageNet-1K,然后在ImageNet-9K中以不同的方法来评估转移出来的效能。
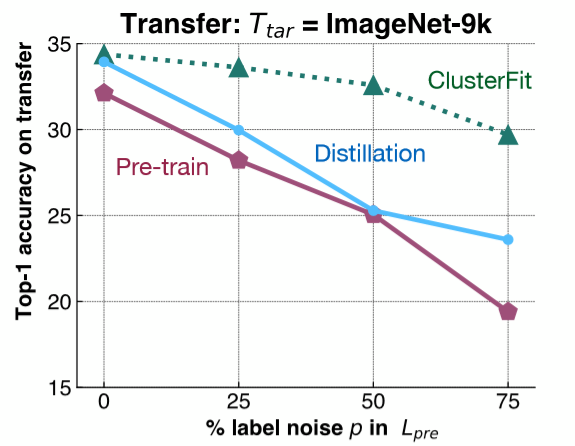
图 6: 对照实验
粉色线显示出训练过的网路的性能,当噪声的数量上升时,性能就下量。蓝线代表模型的蒸馏法,也就是我们用原来的网路,然后用它来生成标签。蒸馏法一后都比预先训练过的网络有更好的性能。绿线,就是物以类众,它同时地这些方法有更出色的效能。这个结果证实了我们的假设。
- 问题:为什么用蒸馏法来比较。物以类聚法和蒸馏法有什么不同?
在模型中的蒸馏法,我们用一个训练过的网络,然后用它的 比如这样,我们拿一个所有类的分布,然后用这个分布来训练第二个网路。这个更柔和性的分布就会帮助我们所有原来的类型(initial classes)。在物以类聚法中,我们不用担心标签空间(label space)。
性能
我们使用了这个方法去自我监督学习。这里,拼图就在物以类聚中被用来取得一个预先训练过的网路$N_{pre}$. 在图7中,我们看到在不同数据集中显示出转移出来的性能是惊人地比别的自我监督方法还要高。
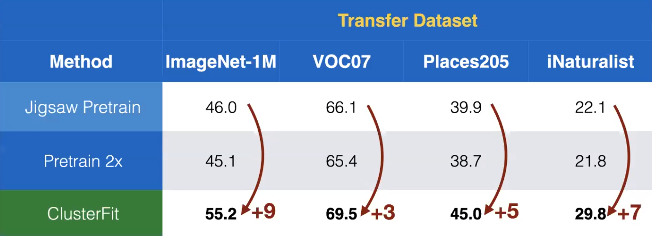
图 7: 不同数据集上的转移出来的性能
物以类聚法都可用在任何预先训练过的网路中,而且能行的。无需额外的数据或标签﹑架构中的改变就就能给予更多想要的东西,请看图8。在某些地方,我们可以想物以类聚法就如自我监督的微调步骤,它提高「表示」的质量。
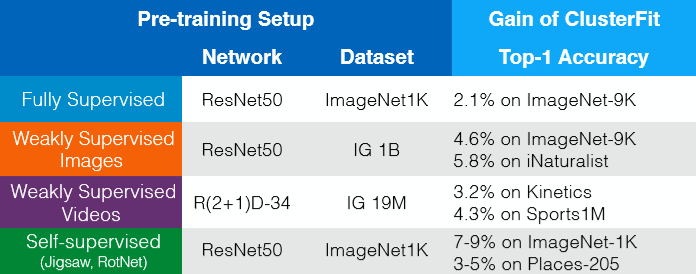
图 8: 无需额外的数据或标签﹑架构中的改变就就能给予更多想要的东西。
前置任务不变量「表示」式自我监督学习,英文Self-supervised Learning of Pretext Invariant Representations,英文简称 (PIRL)
对比式学习
对比式学习是其本上就是一个一般构架去尝试学习一个能特征的空间,这空间是可以结合一起的,或特征的空间是可以把相关的点放在一起的,同时把一些不相关的点推远。

图 9: 相关图像群和不相关图像群
在这个例子中,想像一下蓝色盒子们是有关联性的点,而绿色盒子们是有关联性的,而紫色盒子们是有关联性的。
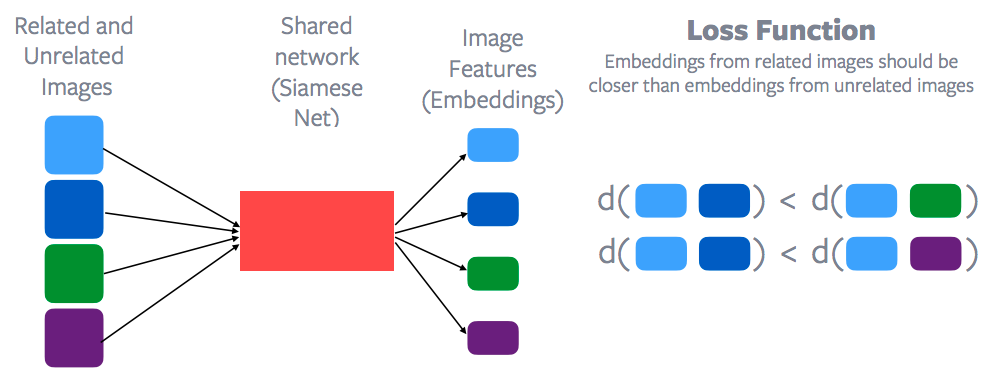
图 10: 对比式学习和损失函数
用在每一个数据点的特征都是由同一个网路中抽取的,也就是连体网络,连体网络去抽取很多图片的特征,然后这些就被用在数据点上。然后一个对比性的损失函数就被用上了,它会最小化蓝色点们之间的距离,相反地增加蓝色点和绿色点之间的距离。或蓝色点们之间的距离应该比蓝色点和绿色点细。或蓝色点们之间的距离应该比蓝色点和紫色点细。所以,有相关性的样本们的嵌入空间比没有相关性的样本们的嵌入空间接近。这就是对比式学习的大概的概念,和当然的,杨立昆是第一位提出这个方法的老师。所以对比式学习是现在是在自我监督学习中东山再起。基本上,很多有出色能力的自我监督学习都是建立在对比式学习。
如何去定义有关系或无关系的?
而主要的问题是如何定义什么是有关系和无关系。如果是监督学习,那就很明显的所有狗图片都是有关系的,而不是狗的就是无关系的。但在自我监督学习中,也不是太清楚的去定义什么是有关系和无关系,而其他主要的不同是一些如前置任务用很多数据来一次过进行推断。如果你看下损失函数,它永远都包含多张图片。在第一行,它基本上包含蓝色图片和绿色图片,而第二行它包含蓝色图片和紫色图片。但如果你去看一些拼图这或旋转这样的任务,你永远都会单独地推理一张图片。这是另一个和对比式学习有所差异的地方:对比式学习是一次过推理多个数据点。
用之前说过的技巧来说:视频的帧或数据的顺序性质。视频中邻近的帧是相关的,不同视频的帧或时间点距离很远的帧都是不相关的。而这个形成出很多自我监督学习的方法的基础。这方法是叫CPC,也就是对比式预测编码(contrastive predictive coding,简称CPC),它取决于信息的顺序性质,加上它基本上说样本是很接近就是相关的,比如时空上那样,如果不接近的就是不相关的,而且大多数工作基本上都是在利用这一点:它能要么是在语音领域或视频﹑文字﹑特定图像。而最近,我们也在视频和音讯上努力,简单地说就是对应的视频和音讯就是有关的,而各自来自不同视频的视频和音讯就是不相关的。
追踪物体
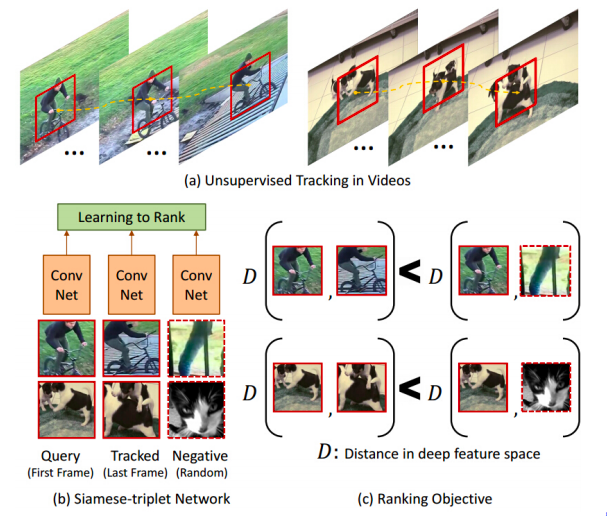
图 11: 追踪物体
一些早期的工作,比如自我监督学习,也使用对比式学习方法,而它们定义有关系的例子的方式是相当有趣的。你在一个视频上运行一个物体追踪器,然后追踪器给你视频中的其中一些连续性的帧,而你就说这些被追踪到的连续性的帧就是和原来的连续性的帧是有关系的。相反地,任何来自不同的视频的连续性的帧就是没关系的。所以简单给出这些有关系的和没有关系的样本。在图11(c)中,你就会有这个相似距离符号的符号。这个网路想尝试去学出这些连续性的帧们是来自同一个视频就是有关系的,而连续性的帧们是各自来自不同的视频的话,那就是不相关的。某种程度上来说,它自动地学习物体不同的姿势。它尝试把一些都是单车的物体,不同角度或不同姿势的狗,都分别地聚集起来。
图片中接近的部份 vs. 图片中遥远的部份
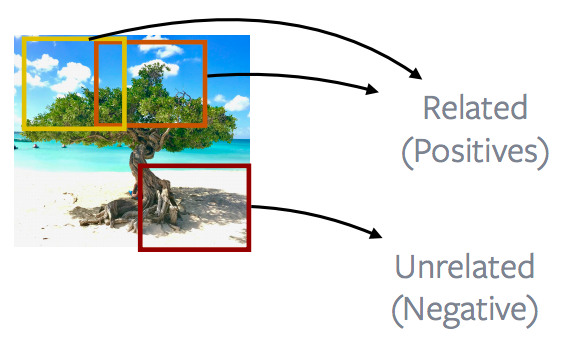
图 12: Nearby patches *vs.* distant patches of an Image
一般来说,如果说及图片的话,很多工作都是以图片中接近的部份 vs. 图片中遥远的部份来完成的,所以大部份CPCv1和CPCv2方法都利用图片的属性。所以图片中接近的部份 叫造正和图片中遥远的部份叫造负,而目的就是用这个正和负的定义来最小化其对比性损失(contrastive loss )。
图片中的部份 vs. 其他图片中的部份
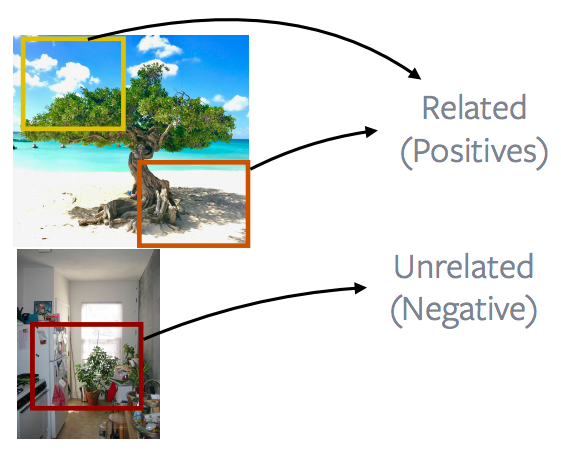
图 13: 图片中的部份 vs. 其他图片中的部份
更流行或更有效的方法就是去看一张图片的部份们,然后用它们来别的图片的部份们进行对比。这就成为很出的方法的基础,比如区分法(discrimination)和MoCO﹑PIRL﹑SIMCLR。这个想法基本上就是图片中所显示的。说得更深,这些方法所做的就是完全随机地抽取图片中的部份。这些部份可以重叠,或它们也可以在一个部份在另一个部份中,或它们可以完全分散开;然后加上了一些数据增强的方法。在这个例子中,就说,重复出现的颜色或移除了的颜色等等。然后将这两个图片的部份定义为正例子。另一个部份是由不同的图片中抽取的。而且这又一次是随机抽取的部份和基本上就变成负例子。而且很多这些方法会抽取很多负面部份和用它们来进行对比法学习。所以这里就有两个正例子,但这里是有很多负面例子来进行对比法学习。
前置任务的基本原理
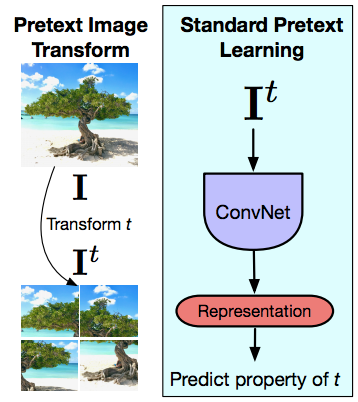
图 14: 前置任务时对图片进行转变和标准前置任务中的学习
现在说下PIRL一些,而且尝试去明白前置任务和对比法学习的重大差异,这个重大差异在它们的前置任务中比较起来是大有不同的。再说一次,前置任务永远只会对单张图片推断一次。所以想法是给予一张图片,然后先转变这个图片,这个例子就用拼图式转变,然后输入这个转变到卷积网,然后去预测变换的属性,比如就是交替的步骤或旋转角度,或什么颜色移除了等等。所以前置任务永远都是对单张图片进行推理。而且第二样东西就是你所用上的前置任务要真的去理解和得到转变的属性。所以它真的要精确地得到转变后什么转变了,比如拼图各个交替的步骤或旋转角度,也就是当最后一层的「表示们」都要跟随转变和改变了什么﹑最后一层的设计来最大度地和实际上以PIRL 方式来运行,那是因为您要真心去尝试解决这些前置任务。但不幸地,这就意味着最后一层的表示得到的信息是很基本的。它们得到一些如有关旋转的息或更多。而这些表示们的设计意图或预期目标是它们对事物是有不变量的,就如它要辨认一只猫,无论是坐起来,立起来,更是90度解度式躺下都要辨认到。而当您解决特定的前置任务时,您却唱反调做相反的东西。我们是说我们应该可以去认出这张图片是否直立起或是否向侧面转起来。不过,当你想这些低层(low-level/很基本的)的表示为协变时,和你想用在的任务上中包括一些在3D上有预测性的任务,那就有很多例外了。所以你想要预测在什么角度上看的话,看到的影响到会有什么转变,你实际上就是在两个不同的角度上看或更多。但除非你有那用在内容意思性任务(semantic tasks)的那种独特的任务,那你用来转变的东西就是不变量才可以来用在输入们中。
不变性一直以来到底有多重要呢?
不变性一直以来都是那个用在特征学习的字。有时如SIFT,也就是颇受欢迎的人工性制作出来的特征,这里我们输入的是转移了的不变量。加上监督网路,比如这样,监督式亚历斯网路(supervised Alex nets),它们都是在训练到成为不变量的数据增强。你想这个网路去分类出这果树的拼图或不同的旋转,而不是问它去预测出对输入所用到的转变的过程是什么。
PIRL
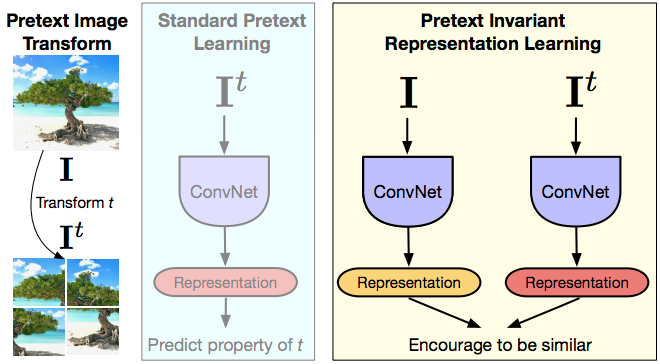
图 15: PIRL
这就是启发PIRL的原因。所以PIRL意思是前置任务的不变量「表示」式学习(pretext invariant representation learning),它的想法是你想那些表示为不变量或在输入和转变后中尽可能取得少量的信息。所以你有一张图片,你也有它转变后的版本,你把这两张图同时输入到前馈式中的光积层中,你就得到各自的表示和你基本上想要这些表示们是相似的。就前面提到的符号而言,图片$I$和任何前置时的图片转变后的版本$I^t$都是有关系的样本,加上别的图片的话都是无关系的样本。所以在这方法中,当你的架构起这个网路时,那就希望表示们对转变$t$只有小量的信息,和假设你是在使用对心式学习。所以对比式学习这部份基本上就是这样,你有已保存好的特征$v_I$,它是来自原来的图片$I$,然后你有特征$v_{I^t}$,它是来自转变后的版本,然后你想这两个的特征都一样。之前书上看到那两个不同而出色的转变法,也就是拼图法和旋转法,之前说过的。在一些地方上来说,这就如多重任务学习,但只不过真正想要做到的是预测这两个设计好的旋转。你正在尝试成为拼图的不变量。
使用大量的負例子
过去一直以来令对比式学习有出色的成功的重点,就是做出了一个成功的尝试,那就是使用大量的負例子。在2018中,其中一篇好论文就是这个介绍区分法的论文,它介绍了內存库的概念。这成为研究中很多成功开发出来的技巧的关键和动力。內存库能很好地取得到很多負例子,而又不增加对计算的需求。而你所做的就是每一张图片的储存它的特征向量,之后你就在对比法学习中用这个特征向量。
如何運作
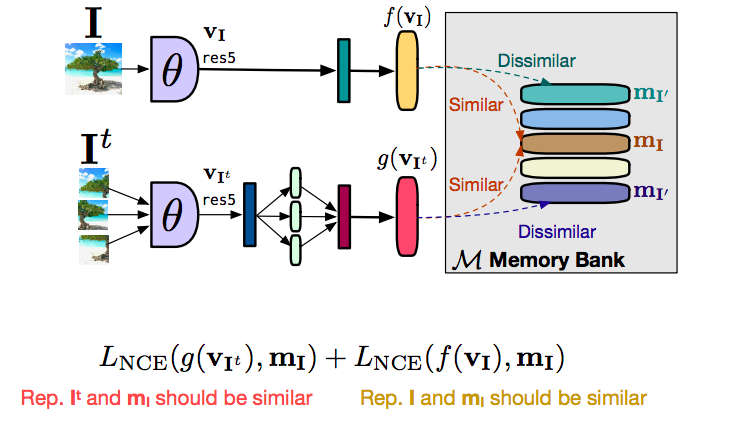
图 16: 内存库如何運作
我们先说说你如何去设立整个PIRL,而不用内存库。所以你有图片$I$和你有图片$I^t$,两你的前馈这两张图,你在原本的图片$I$得到一个特征向量$f(v_I)$,而特征向量$g(v_{I^t})$就由转变后的版本取得,也得到图片中分切开的部份们,在这个例子的话。而你想要的就是特征$f$和特征$g$要相似,而来自不相关的图片的特征要不相似。在这种情况下,我们能做的就是要大量负例子,我们要真的一次过同一时间前馈这些负图片,也就是你要一个很巨大的批量才能做到这个。当然,巨大的批量意思是不好了,也就是不可能在一个有限的GPU中做到的。而做到的方法就是要用上内存库了。这个内存库就是为数据集中的每张图片存储它的特征向量,而当你用相对式学习而不是用特征向量来分析负图片的差异,或批量中不同的图片的差异,那你就能由内存库中取回这些特征。那你就能由内存库中取回这些特征。你也能够由内存库中取出任何其他无关系的图片的特征,用取出的来替换原来要比较的来进行对比式学习。简单的去把目的分开为两部份,一个是对比部份,它带来转变后的图片的特征向量$g(v_I)$,类似于内存$m_I$中所有的表示。同样,我们有第二个对比式卷积网,它尝试令特征$f(v_I)$接近内存中表示的特征们。 实质上 $g$ 是被拉近到$m_I$,和$f$被拉近到$m_I$。由一方到另一方,$f$和$g$被拉到互相接近起来。而分开它们的原因是为了有稳定的训练,而且不这样做的话,我们无法去训练。基本上,训练就不会真的收敛起来。而把这个分开为两种形式,而不是直接对$f$和$g$进行对比式学习,我们就能去稳定训练过程和实际上地令它运作。
PIRL前置训练
而评估方法就用标准的前置训练评估设定。而转移训练,我们能先不以标签方式来训练图片们。标准的方式就是用image net,扔掉它的标签并当作为无人监督。
评估
而评估所用到的就是全面微调或训练一个线性分类器。而第二样我们会做的东西也就是测试PIRL和强化图片分布,强化图片分布方式就是用”野外”的图片来训练。所以我们随机地由Flickr取一百万,也就是YFCC数据集。之后我们就简单地用这些图片来进行预先训练,然后就在不同的数据集中实行移植。
评估物体识别任务
PIRL 是第一个在(标准的视觉性任务)中以它的物体识别任务来被评估的,而且在VOC07 + 12和VOC07数据集中,它的效能是能够超过以ImageNet 来前置训练的监督网络。事实上,PIRL 在更严格的评估标准($AP^{all}$)中也同时超过的。这是一个好迹象。
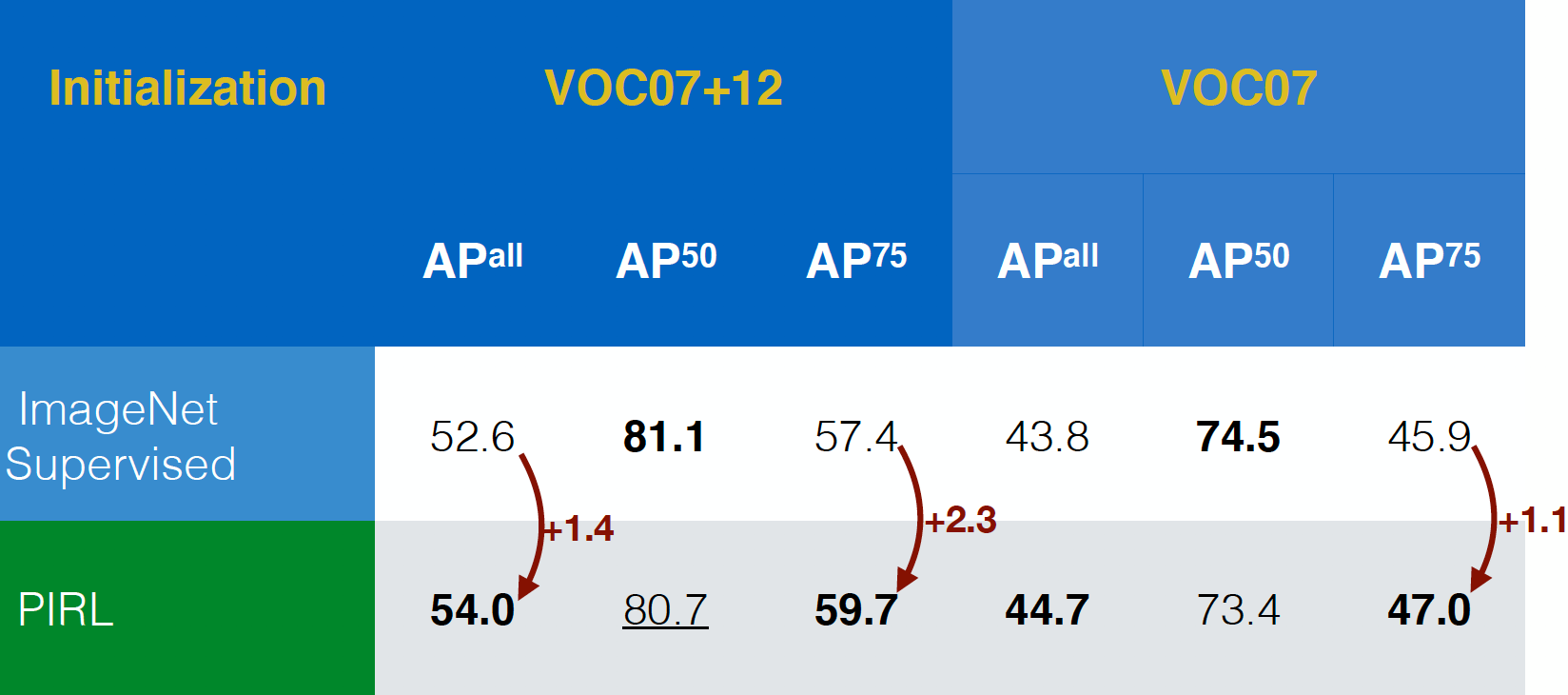
图 17: 在不同的数据集中物体识别的性能
半监督学习评估
PIRL 过去是评估在半监督学习任务。说多一次,PIRL 性能真的非常好。事实上,PIRL比拼图式前置训练更出色。而第一行和第二行的不同就是,PIRL是不变量版本,而拼图式就是协变版本。
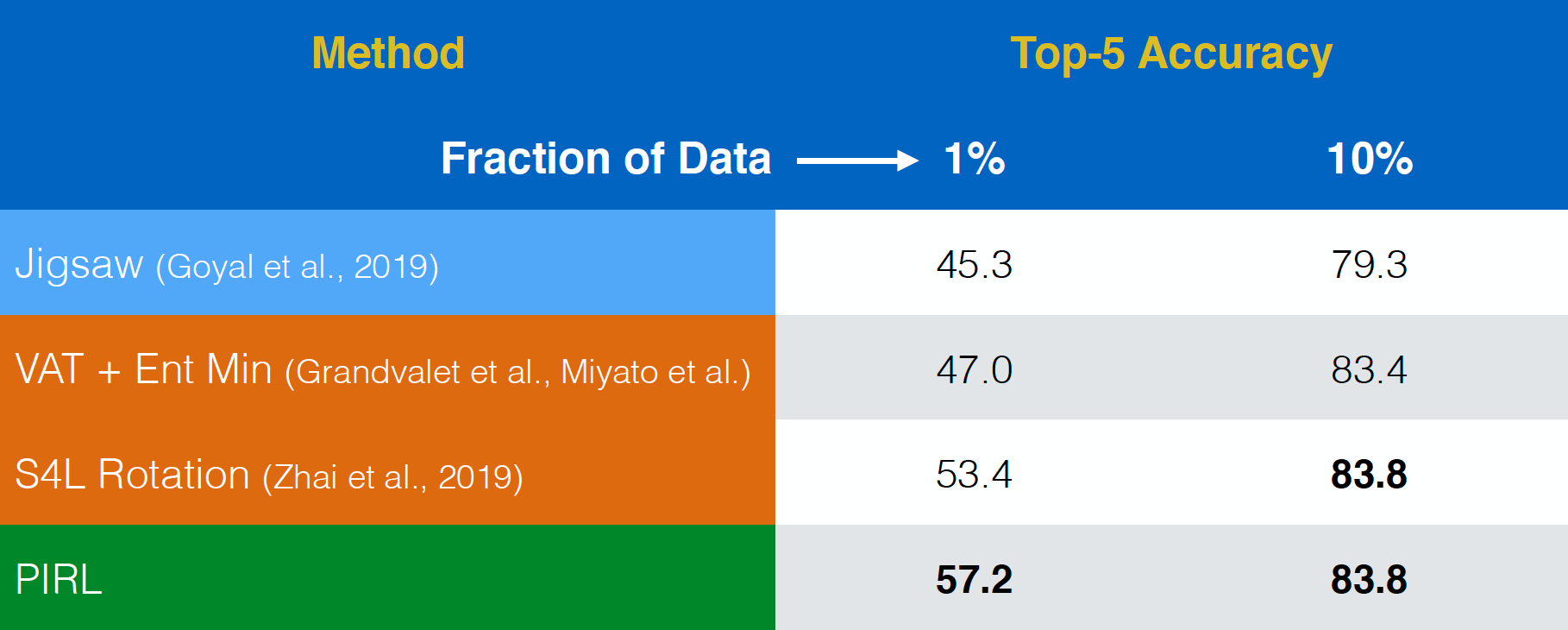
图 18: ImageNet上的半监督学习
线性分类评估
现在是线性分类评估,当PIRL出来时,它事实上是CPCv2的一部份。它也在一堆参数设置和一堆不同的架构中运行得不错。也当然的,现在你可以在方法如SimCLR和其他方法中看到一个很好的效能。事实上,SimCLR中第一名准确性就是在69-70中,而PIRL的话就在63附近。
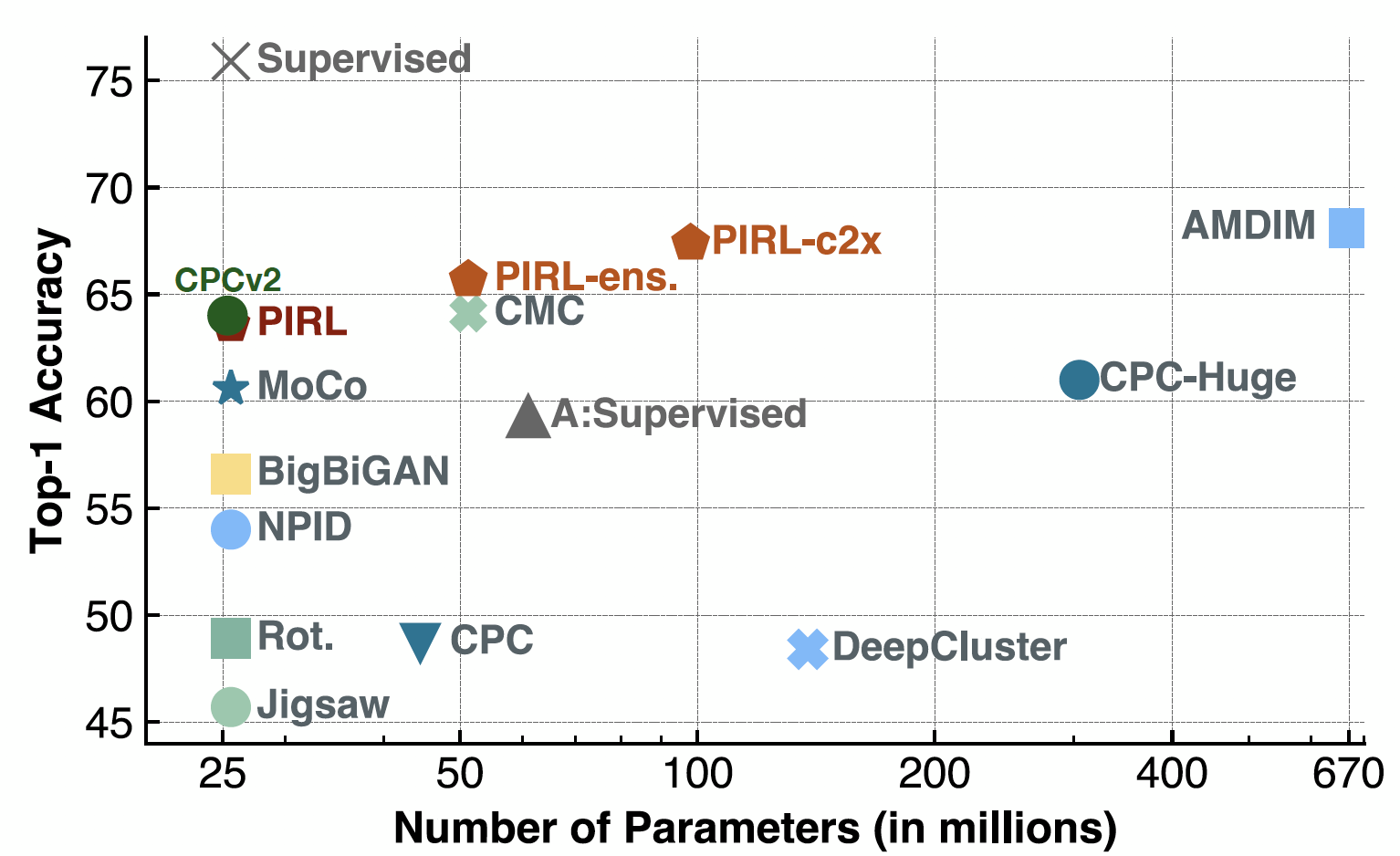
图 19: 使用线性模型进行ImageNet分类
Evaluating on YFCC images
在YFCC数据集中,PIRL被为评估 “在野生”的 Flickr 图像。它能做得比拼图更好,即使是$100$倍更小的数据集。这显示出在前置任务中的表示,而要考虑到在不变性的必要性,而不只单单是有预测性的前置任务。
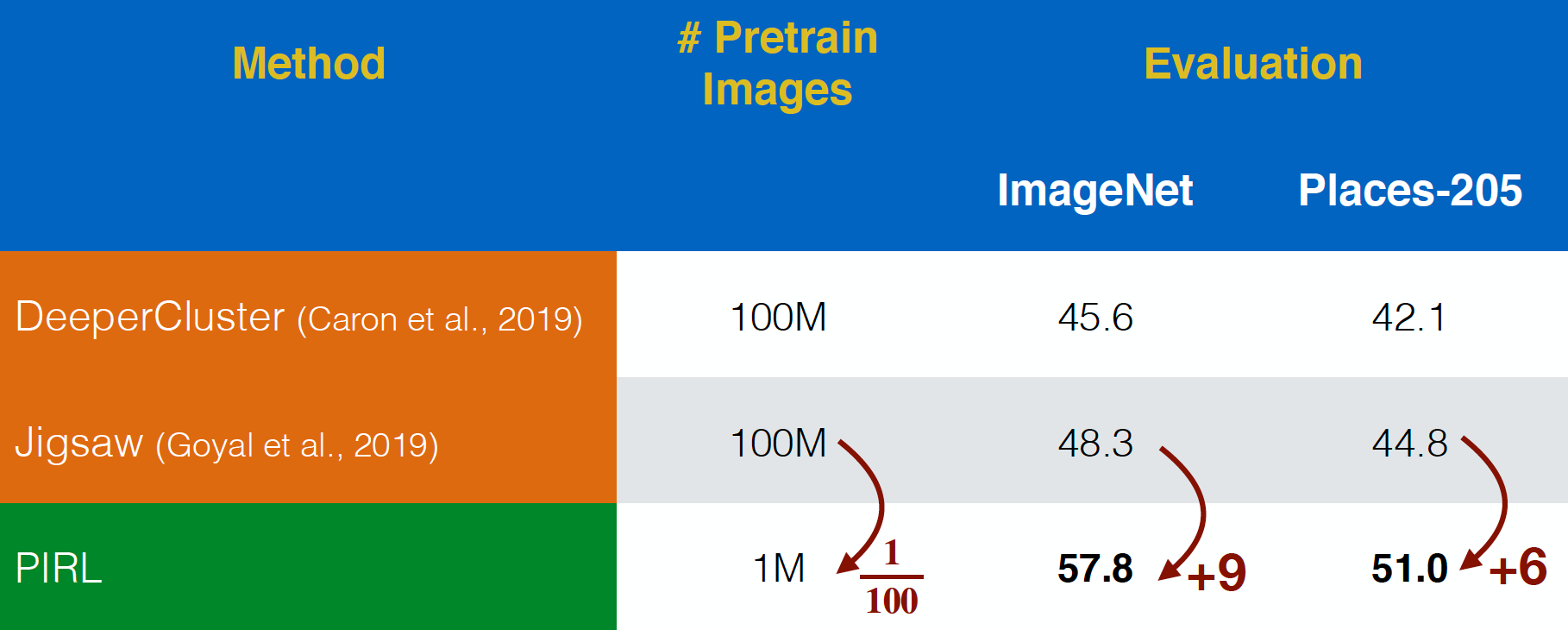
图 20: 未过训练的YFCC图像上的进行前置训练
事物的意思特征
现在,回来这里去验一下内容性特征,我们看到PIRL和拼图式在不同的表示层的最高准确度,由conv1到res5的。有趣的是,对于PIRL和拼图式,它们的精度都在不同的层中不断提高,但拼图版就在第五层下降起来了。相反PIRL的准确性不断提高,而且了解得更多和更多的意思性。
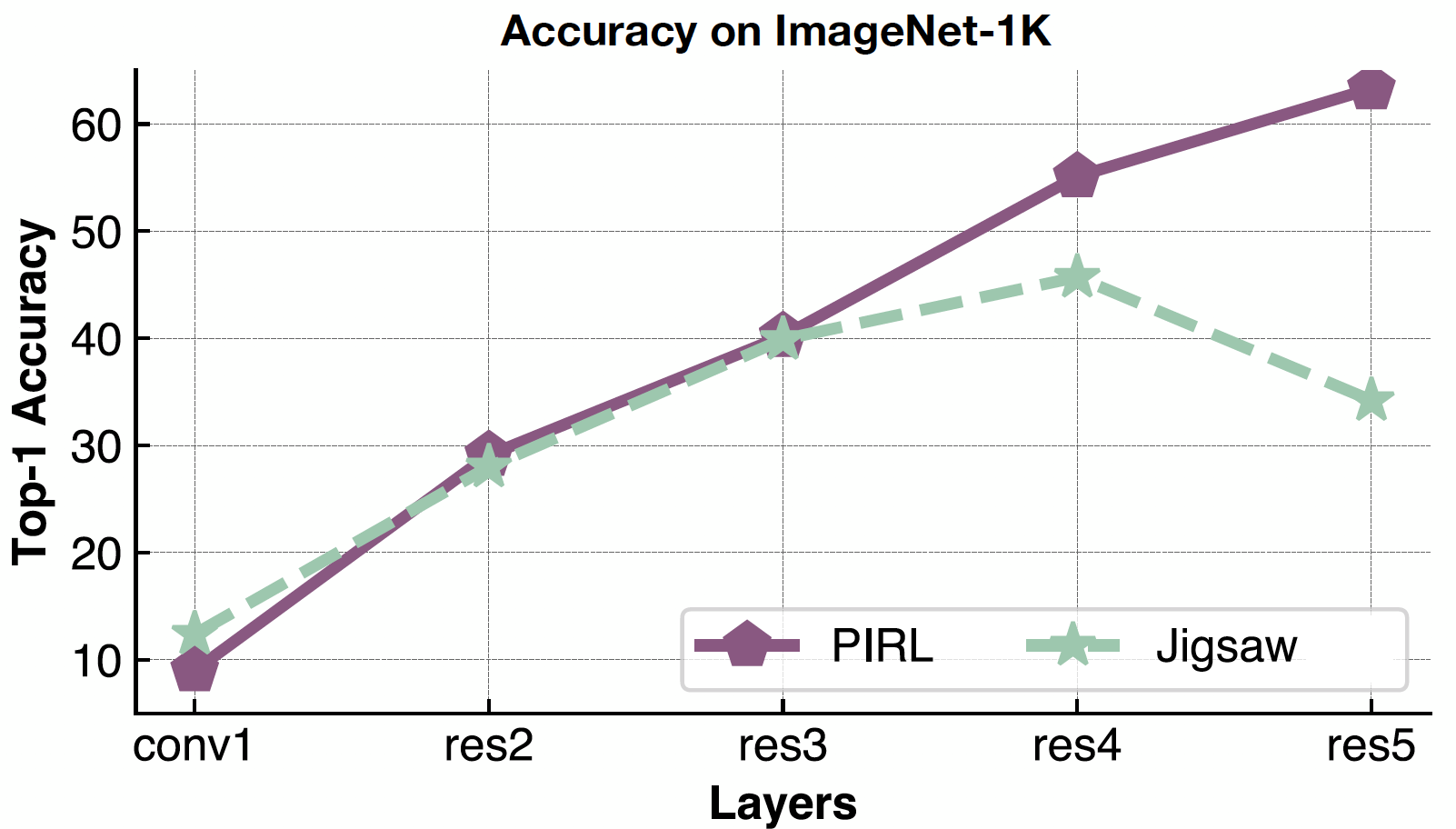
图 21: 每层PIRL的表示的质量
每层PIRL的表示的质量
PIRL 能很好地处理问题的复杂度,因为你永远都不会预测交换的次数(如拼图),您只是将它们用作输入。所以,PIRL可以简单地扩展到362,880个在9个格的可能的交换。相反在拼图式中,因为你是在预测交换的次数,你的输出空间的大小就限制你。
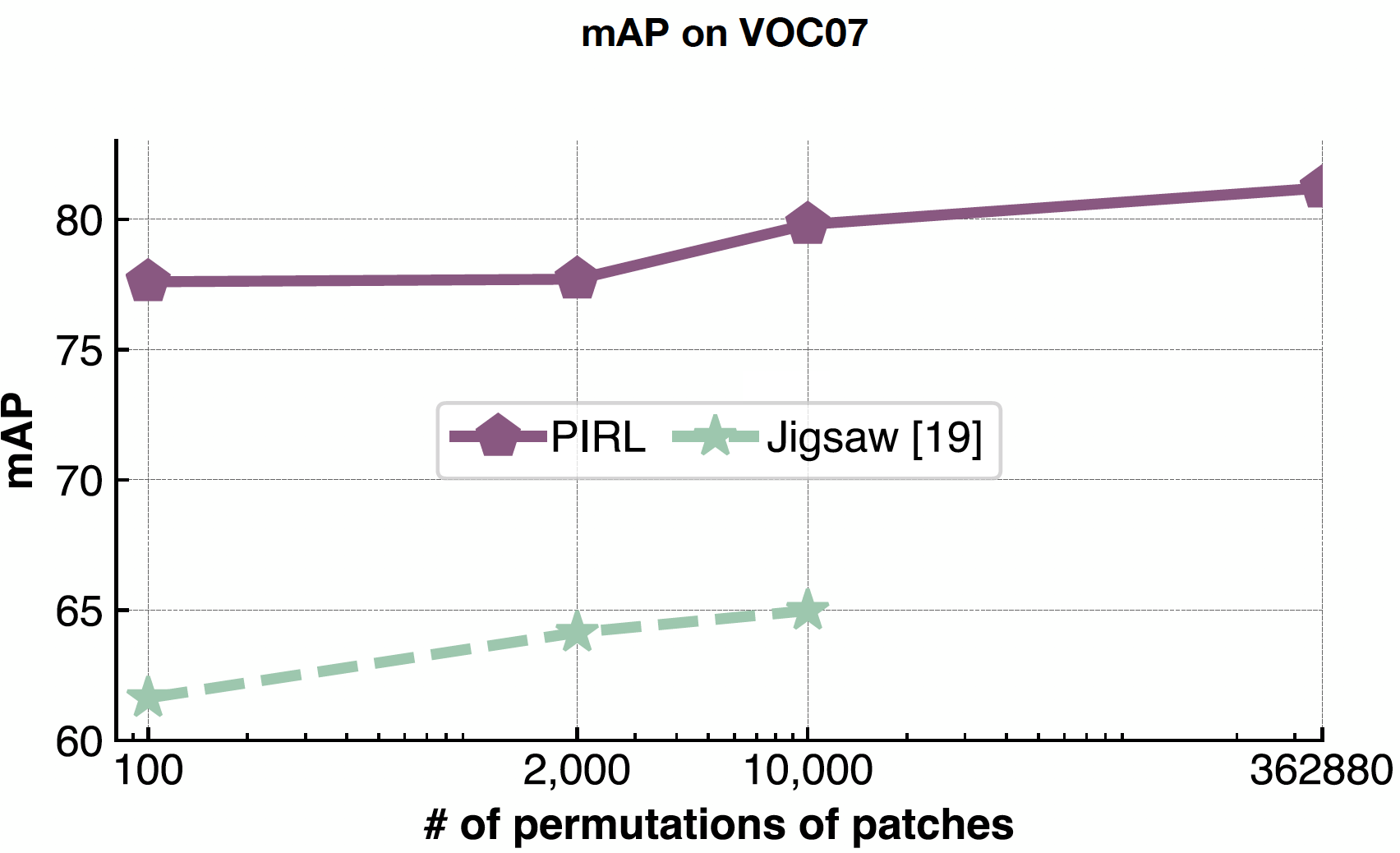
图 22: 改变格子交换的次数所带来的影响
论文 “Misra & van der Maaten, 2019, PIRL” ,显示出PIRL如何很容易比扩展到其他任务,比如拼图法和旋转法等等。加上,它更能扩展到任务组合上,如拼图法加旋转法上。更进一步地,它更能够扩展到成为组合性任务,比如拼图+旋转。
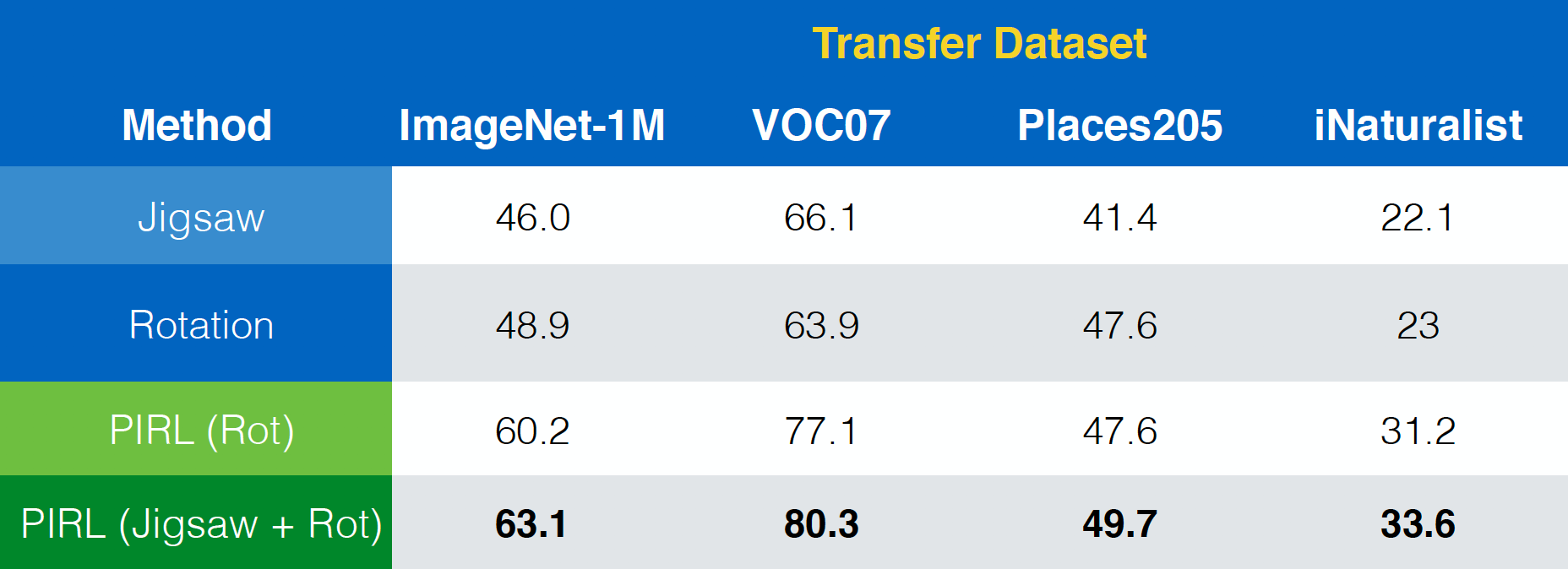
图 23: 在不同的前置任务(包括组合性任务)中使用PIRL
不变性 vs 性能
以不变性这个词的属性来说,也就是一般上就是断言PIRL的不变性是比聚类法更有不变性,也就是比那些前置任务们更有不变性。同样地,PIRL的效能是比聚类法高,结果就是比前置任务有更好的效能。这就说明出在你的方法中用更多的不变性,你的效能就更高。
缺点
- 还是不太清楚那一组数据转变的集合是重要有用的。因为拼图法能行,它还是不太清楚为什么能行。
- 模型大小和数据大小的饱和度。
- 为什么不变性是很重要呢?(一个想法就是总体来说在特定的监督任务上什么样子的一些不变性是可行的,这是未来的工作。)
所以总体来说,我们应该尝试去预测更多更多的信息,和去尝试有多不变性就我多不变性。
一些重要的问题,而被疑问出来
对比式学习和批量标准化(batch norms)
- 网路会不会只学了一些不重要的方式来把负例子和正例子分开,如果对比网路使用批量标准化的话(那信息会由一个地方传到另一个地方吗)?
回: 在PIRL中,是没有观察到这种现象,所以只使用通常的批量标准化。
- 所以是可以在任何对比式网路中用批量标准化吗?
回: 一般上,是对的。在SimCLR,一个批量标准化变种是被用来模拟一个很大的批量。所以,有着一些的一些调整批量标准化应该就能令训练容易一点。
- 之所以批量标准化能行是因为它以内存库来运作吗,它是没有一次过同时取出所有「表示」?(就如所MoCo论文没有明确地指明要用批量标准化)
回: 对啊。在PIRL中,同样的批量没有所有的表示,而且这可能是为什么批量标准化能行,这或许不是在批量中所有的表示都是相关的例子。
- 所以记忆库以外,是不是有其他建议如何在n对损失中如何做?我们应该用AlexNet或别的不用批量标准化的方法?或是否有一个方法来停止一下批量标准化?(这是给视频学习任务)
回: 一般在视频的帧都是相关的,而当是相关的,那批量标准化的效能就会降级。所以即使简单的Alex网实行,也会用上批量标准化,那是因为,当以批量标准化来训练就会更稳定。你更会用更高的学习率和你会在后期任务中用上批量标准化。你会用一个批量标准化的变种,比如群式规范化来用在视频学习任务中,因为它不会受批量的大小影响到。
在PIRL中的损失函数
- 在PIRL中,为什么NCE(噪声对比估算器)是被用来最小化损失,而不单单只用来作为数据分布的负概率:$h(v_{I},v_{I^{t}})$?
回: * 事实上,两个都会被用上。而使用NCE的原因是和记忆库如何设立有关的。所以,以K+1负例子们,这是等同于解开K+1二进制问题。 另一个做法是用归一化指数函数,也就是你用上归一化指数函数和最小化那个负对数似然(negative log-likelihood)。*
自我监督学习项目的相关秘诀
如何我们才能简单地令自我监督模型运作呢?我们如何开始实现它呢?
回: 一些地方上有特定类型的技巧,它们是在初始阶段是有用的。比如,你去看看有没有些是给前置训练的。旋转是可以很简单地实现。而会移动的部件的数量是可以很好地引导。而如果你想打算去实行现有的方法,那你就要集中看下作者所说的细节。比如用一样的学习率﹑批量标准化﹑等等。而用更多这些的东西,更难去实现自我监督学习。下一个要重点地考虑的是数据强化。如果你想令一些东西运作,那就要加更多数据强化。
生成模型
你有没有想过对比式网路和生成模型组合起来呢?
回: 通常地,是好主意。但,它没有一点地实行过,因为要有点棘手和很难去训练这样的模型。综合方法是很难去实行,但或许是未来所用到的方法。
蒸馏法
当有更有内容性的目标时,软分布会不会在模型中给更多不确定性呢?加上为什么叫蒸馏法?
回: 如果你训练一个一热标签(one hot labels),那你的模型就会变得过度自信。技巧如label smoothing都被用在一些方法上。 Label smoothing 只是蒸馏法的简单版,当你去尝试预测一个一热向量(one hot vector)。现在,而不是试图预测一热和一些零,你会预测,比如,0.97和剩余向量三个0.01(统一地)。蒸馏法就是这个的更明智的方式。而不是随机增加无关任务的可能性,你有一个预先训练的网络可以做到这一点。总体上更软的分布就是在前置训练方法中很有用。模型往往过于自信和所以更软的分布会更容易训练。它们也收敛得更快。这些好处存在于蒸馏法中。
📝 Zhonghui Hu, Yuqing Wang, Alfred Ajay Aureate Rajakumar, Param Shah
Jonathan Sum(😊🍩📙)
6 Apr 2020