优化方法
🎙️ Aaron Defazio自适应优化算法
具有动量的随机梯度下降法(SGD)是当前针对许多ML问题的最先进的优化方法。但是还有其他一些方法,这些方法通常统称为自适应优化方法。这些方法近年来不断创新,而且这些方法对于一些条件不足的问题(特别是SGD不适用的情况下)特别有用。
在随机梯度下降法的公式中,网络中的每个权重均使用相同的学习率(全局$ \gamma $)进行更新。与此不同的是,对于自适应的方法,我们针对每个权重分别调整学习率。为了达到这个目的,我们使用从梯度获得的关于每个权重的信息。
在实践中经常使用的网络在其不同部分具有不同的结构。例如,CNN的前几层部分可能神经图像比较大但是通道不是很多,而在网络的后期,我们可能得到小的神经图像,但是卷积的核具有大量的通道。这两种操作非常不同,因此,对于网络的前面部分而言效果很好的学习率可能对网络的后部分效果不好。这意味着逐层自适应去调整学习率可能会很有效果。
网络最后部分的权重(下图1中的4096)直接决定了网络的输出,换言之对输出有非常大的影响。因此,我们需要为这些权重降低学习率。相反,较早层的单个权重将对输出产生较小的影响,尤其是在网络权重值是随机初始化的时候。
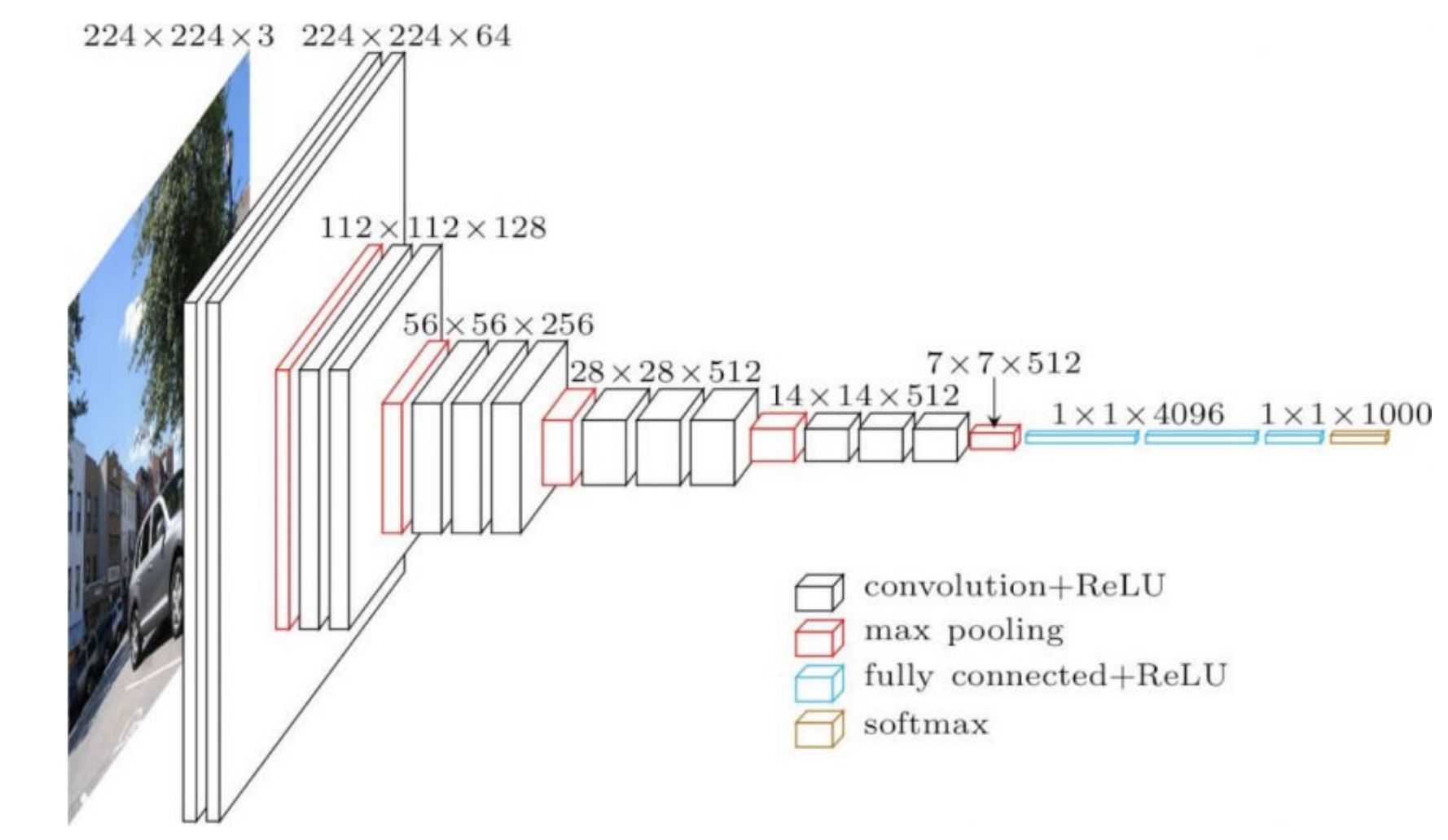
图1: VGG16
均方根优化(RMSprop)
均方根优化(RMSprop)的关键思想是通过均方根对梯度进行归一化。
在下面的等式中,对梯度进行平方意味着对梯度向量的每个元素分别进行平方。
\[\begin{aligned} v_{t+1} &= {\alpha}v_t + (1 - \alpha) \nabla f_i(w_t)^2 \\ w_{t+1} &= w_t - \gamma \frac {\nabla f_i(w_t)}{ \sqrt{v_{t+1}} + \epsilon} \end{aligned}\]其中 $\gamma$ 是整体学习率,$\epsilon$ 是接近于电脑的 $\epsilon$ 的一个非常小值(大约介于 $10 ^{-7}$ 至 $10^{-8}$ 之间)(这是为了避免除以零而报错),$v_{t + 1}$ 是梯度的二阶矩估计。
我们通过指数移动平均值(这是计算随时间变化的数量平均值的标准方法)来更新嘈杂的$v$值。我们需要对新值提供更大的权重,因为它们会提供更多信息。这里的方法以指数形式降低旧值的权重。 计算 $v$ 的时候旧的值在每个步骤中都乘上$\alpha$来指数降低权重,该 $\alpha$ 常数在0到1之间变化。这会让旧值递减,直到它们对梯度二阶矩的指数移动平均值贡献非常低为止。
这个方法会不断计算梯度二阶矩的指数移动平均值,因为是非中心的二阶矩,因此我们不用在计算的时候减去剃度的均值。梯度的二阶矩用来对梯度进行逐个归一,这意味着梯度的每个元素都将除以二阶矩的平方根。如果梯度的期望值较小,则此过程类似于将梯度除以标准差。
在分母中使用小的$\epsilon$不会导致大的偏移,因为当$v$非常小时,意味着整个梯度也非常小。
带动量学习率自适应 (ADAM)
ADAM,或称带动量学习率自适应(RMSprop加动量),是一种更常用的方法。动量更新将基于指数移动平均值,而当我们处理$\beta$时,我们不需要更改学习率。就像在RMSprop中一样,我们在这里取平方梯度的指数移动平均值。
\[\begin{aligned} m_{t+1} &= {\beta}m_t + (1 - \beta) \nabla f_i(w_t) \ v_{t+1} &= {\alpha}v_t + (1 - \alpha) \nabla f_i(w_t)^2 \ w_{t+1} &= w_t - \gamma \frac {m_{t}}{ \sqrt{v_{t+1}} + \epsilon} \end{aligned}\]其中 $m_{t+1}$ 是动量的指数移动平均值。
这里没有加上用于在早期迭代期间保持移动平均值无偏的偏差校正。
实用建议
在训练神经网络时,SGD通常在训练过程开始时梯度会传播错方向,而RMSprop会朝正确的方向走。但是,RMSprop就像SGD一样会受到噪声的影响,因此一旦接近局部最小化时,RMSprop就会在最佳位置附近反复变化。就像我们为SGD增加动力一样,加上动力时候ADAM也有类似的效果改进。这是对解决方案的一个很好的估计,因此相对于RMSprop,通常建议使用ADAM。
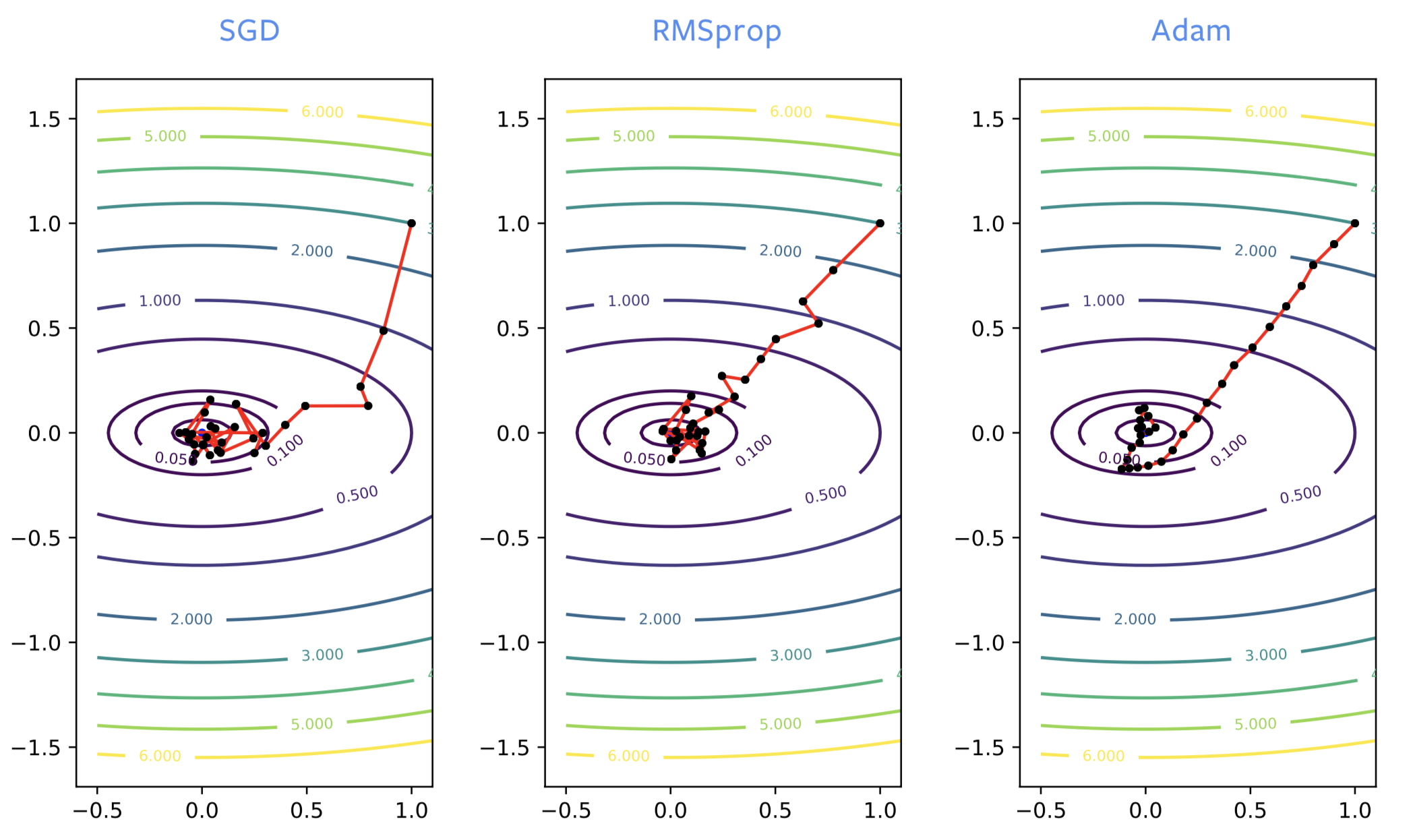
图2: SGD,RMSprop,ADAM
ADAM对于训练某些使用语言模型的网络是必需的。为了优化神经网络,通常首选带动量的SGD或ADAM。但是,ADAM的理论在论文中知之甚少,它也有几个缺点:
- 可以证明,在非常简单的测试问题上,该方法无法收敛。
- ADAM已知会产生泛化错误。如果对神经网络进行了训练,并且使其对训练数据的损失为零,那么它将不会对之前从未见过的其他数据点产生零损失。与使用SGD时相比,特别是在图像问题上,泛化误差更为常见。其中原因可能包括它找到的是最接近的局部最小值,ADAM或其结构中的噪声较小,等等。
- 使用ADAM,我们需要维护3个缓冲区,而SGD需要2个缓冲区。除非我们训练一个大小为几GB的模型,否则这并不重要。而在模型很大这种情况下,这些缓冲区可能无法容纳在内存中。
- 需要调试2个动量参数而不是1。
归一化层
归一化层不是改善优化算法,而是改善网络结构本身。它们是现有层之间的附加层。目的是提高优化和泛化性能。
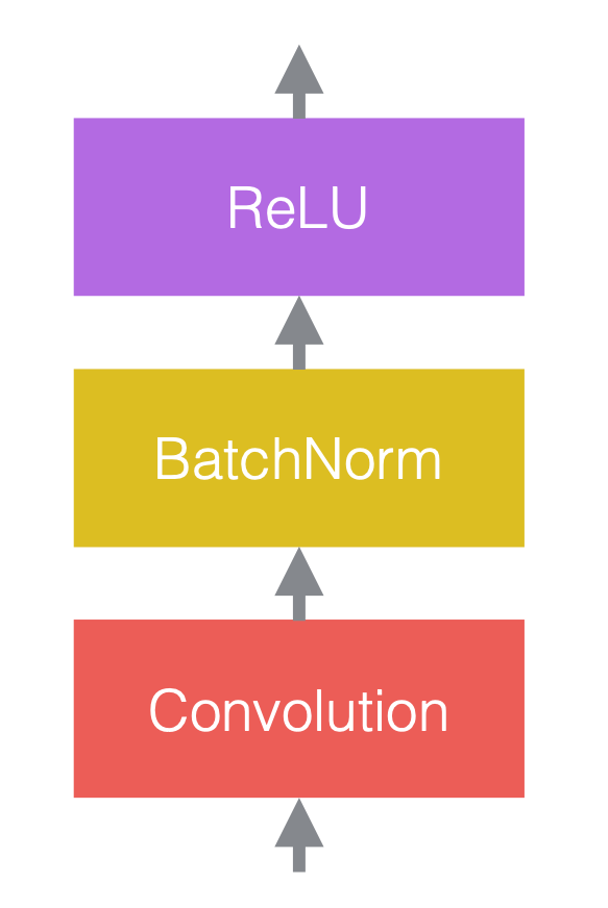
在神经网络中,我们通常将线性运算与非线性运算交替出现。非线性运算也称为激活函数,例如ReLU。我们可以将归一化层放置在线性层之前或激活函数之后。最常见的做法是将它们放在线性层和激活函数之间,如下图所示。
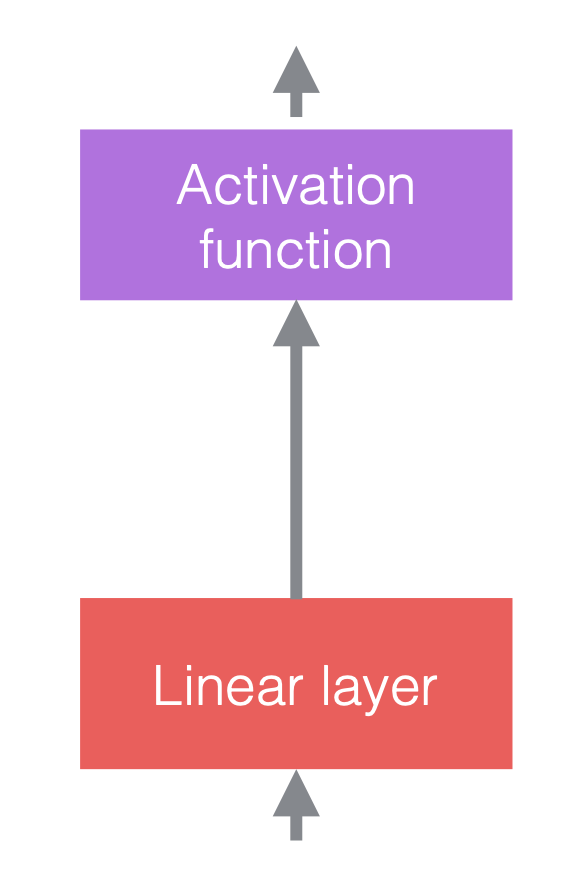 |
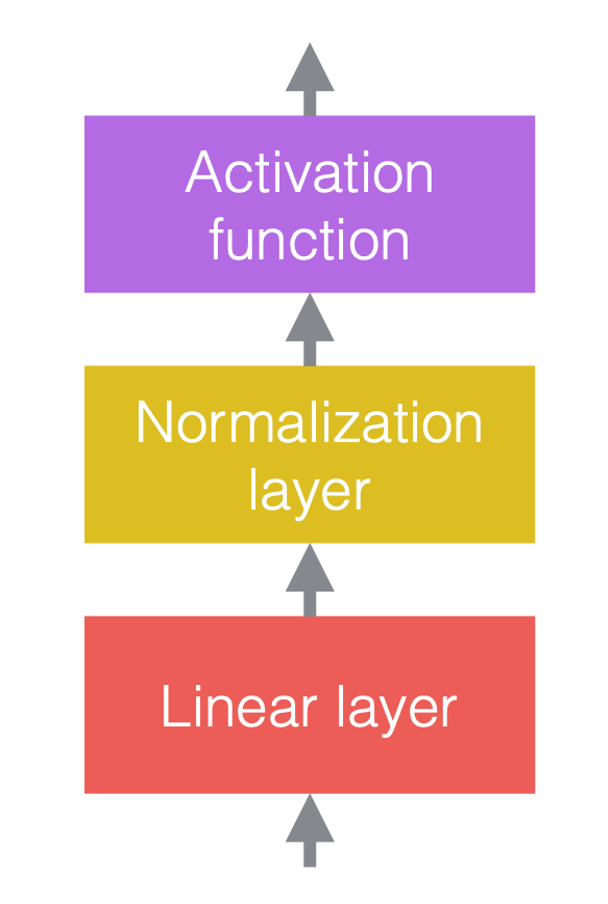 |
 |
| (a) 加上归一化之前 | (b) 加上归一化之后 | (c) 卷积神经网络中的例子 |
在图3(c)中,卷积是线性层,然后是批处理归一化,然后是ReLU。
值得注意的是,归一化层会影响经过的数据,但是它们不会改变网络的功能,因为在适当配置权重的情况下,未归一化的网络仍可以提供与归一化网络相同的输出。
归一化操作
这是归一化的通用运算:
\[y = \frac{a}{\sigma}(x - \mu) + b\]其中$x$是输入向量,$y$是输出向量,$\mu$是$x$均值的估计,$\sigma$是$x$的标准差(std)的估计,$a$是可学习的比例因子,$b$是可学习的偏差项。
如果没有可学习的参数$a$和$b$,则输出向量$ y $的分布将具有固定的均值0和标准差1。比例因子$a$和偏差项$b$维持网络的表示能力,即,输出值仍可以在任何特定范围内。请注意,$a$和$b$不会逆转规范化,因为它们是可学习的参数,并且比$\mu$和$\sigma$稳定得多。
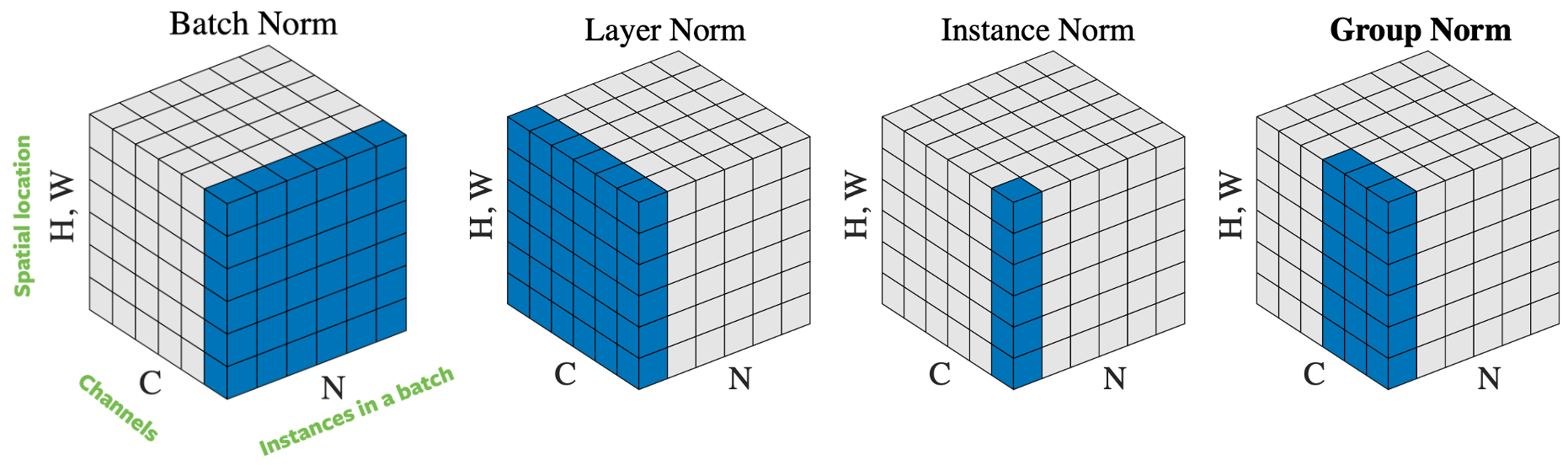
图4: 归一化操作.
基于如何选择样本进行归一化,有几种方法可以对输入向量进行归一化。图4列出了4种不同的归一化方法,假设一个批量的$N$个图片,高度为$H$宽度为$W$,并且有$C$个通道:
- 批量归一化:规范化仅应用于输入的一个通道。这是最先提出的也是最著名的方法。请阅读如何训练ResNet7:批量归一化以获取更多信息。
- 层归一化:在所有通道的一张图像中应用归一化。
- 实例归一化:仅对一幅图像和一个通道应用标准化。
- 组归一化:归一化应用于一个图像,但跨多个通道。例如,通道0至9是一个组,然后通道10至19是另一个组,依此类推。实际上,组的大小几乎总是32。这是Aaron Defazio推荐的方法,因为它在实践中具有良好的性能,并且与SGD不冲突。
实际应用中,批处理规范和组规范适用于计算机视觉问题,而层规范和实例规范则广泛用于语言问题。
为什么归一化有效?
重要的是通过均值和标准差的计算以及归一化的应用来进行反向传播:否则,网络训练会有所不同。反向传播计算相当困难且容易出错,但是PyTorch能够为我们自动计算,这非常有帮助。下面列出了PyTorch中的两个归一化层类:
torch.nn.BatchNorm2d(num_features, ...)
torch.nn.GroupNorm(num_groups, num_channels, ...)
批量归一化是最早开发的方法,并且是最广为人知的方法。但是,Aaron Defazio建议改为使用组规范。它更稳定,理论上更简单,并且通常效果更好。组大小32是一个很好的默认值。
请注意,对于批范数和实例范数,使用的均值/标准差在训练后是固定的,而不是每次评估网络时都重新计算,这是因为需要多个训练样本来进行归一化。对于组规范和分层规范而言,这不是必需的,因为它们的归一化仅针对一个训练样本。
优化的死亡
有时,我们可以闯入一个我们一无所知的领域,并改善他们当前实现事物的方式。一个例子是在磁共振成像(MRI)领域中使用深层神经网络来加速MRI图像重建。

图5: 有时候它很有效!
MRI重建
在传统的MRI重建问题中,原始数据是从MRI机器上获取的,并使用简单的框架/算法从中重建图像。 MRI机器一次(每隔几毫秒)捕获二维傅立叶域中的数据,一次一行或一列。该原始输入由一个频率和一个相位通道组成,该值表示具有特定频率和相位的正弦波的大小。简而言之,可以将其视为具有真实和虚构通道的复杂值图像。如果我们在此输入上应用傅立叶逆变换,即将所有这些正弦波按其值加权后相加,就可以得到原始的解剖图像。
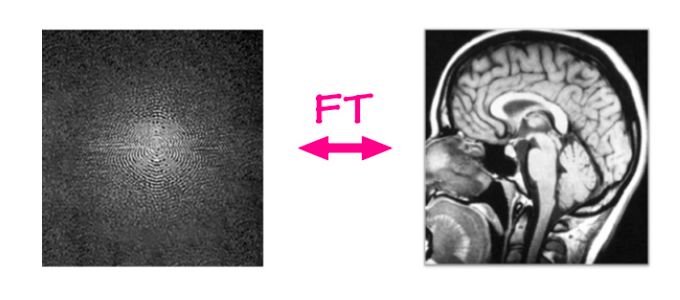
图6: MRI重建
当前存在从傅里叶域到图像域的线性映射,并且无论图像有多大,它都是非常高效的,实际上要花费毫秒。但是问题是,我们可以更快地做到吗?
加速MRI
加速MRI是需要解决的新问题,所谓加速是指使MRI重建过程更快。我们希望更快地运行机器,并且仍然能够产生相同质量的图像。我们可以做到这一点的一种方法,并且到目前为止,最成功的方法是不捕获MRI扫描中的所有列。我们可以随机跳过一些列,尽管在实践中捕获中间列很有用,因为它们在整个图像中包含很多信息,但是在它们之外,我们只是随机捕获。问题在于我们不能再使用线性映射来重建图像。图7中最右边的图像显示了应用于子采样傅立叶空间的线性映射的输出。显然,这种方法不会给我们带来非常有用的输出,并且还有做一些更加智能化的提升空间。

图7: 二次采样傅立叶空间上的线性映射
压缩感知
长期以来,理论数学上最大的突破之一是压缩感测。 Candes等人的论文显示,从理论上讲,我们可以从二次采样的傅立叶域图像中获得完美的重构。 换句话说,当我们试图重建的信号是稀疏的或稀疏的结构时,则可以通过较少的测量来完美地重建它。但是,要使此方法有效,有一些实际的要求-我们不需要随机采样,而是需要不连贯地采样-尽管实际上,人们最终只是随机采样。另外,对整列或半列进行采样需要花费相同的时间,因此在实践中我们也对整列进行采样。
另一个条件是我们需要在图像中具有“稀疏度”,稀疏度意味着图像中存在很多零或黑色像素。如果我们进行波长分解,则可以稀疏地表示原始输入,但是即使分解也可以使我们得到近似稀疏的图像,而不是精确稀疏的图像。因此,如图8所示,这种方法给我们提供了很好但不是完美的重建。但是,如果输入在波长域中非常稀疏,那么我们肯定会获得完美的图像。
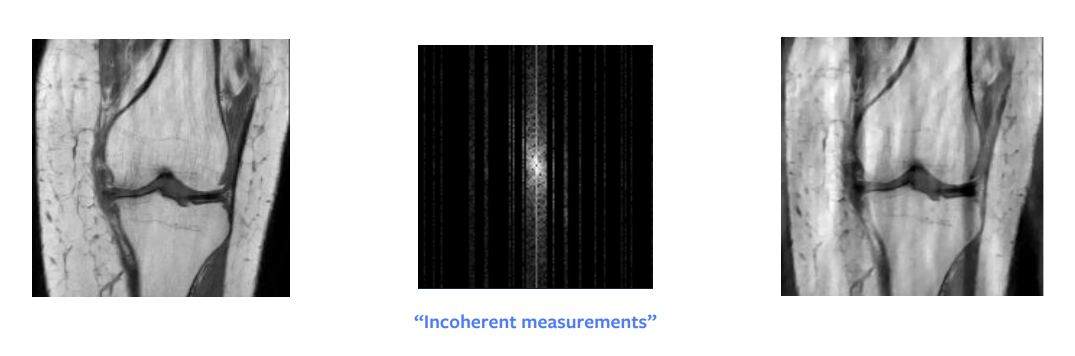
图8: 压缩感知
压缩感测基于优化理论。我们获得此重构的方法是解决一个最小优化问题,该问题具有一个附加的正则项:
\[\hat{x} = \arg\min_x \frac{1}{2} \Vert M (\mathcal{F}(x)) - y \Vert^2 + \lambda TV(x)\]其中$M$是将未采样条目归零的掩码函数,$\mathcal{F}$是傅里叶变换,$y$是观察到的傅里叶域数据,$\lambda$是正则化惩罚强度,并且$V$是正则化函数。
必须针对MRI扫描中的每个时间步长或每个“切片”解决优化问题,这通常需要比扫描本身更长的时间。这给了我们找到更好的东西的另一个理由。
谁需要优化?
为什么不使用大型神经网络直接生成所需的解决方案,而不是在每个步骤都解决一点优化问题?我们的希望是,我们可以训练出足够复杂的神经网络,使其本质上一步解决优化问题,并产生与在每个时间步解决优化问题所获得的解决方案一样好的输出。
\[\hat{x} = B(y)\]其中$B$是我们的深度学习模型,而$y$是观察到的傅立叶域数据。
15年前,这种方法很困难-但是如今,这种方法更容易实现。图9显示了针对该问题的深度学习方法的结果,我们可以看到输出比压缩感测方法好得多,并且看起来与实际扫描非常相似。
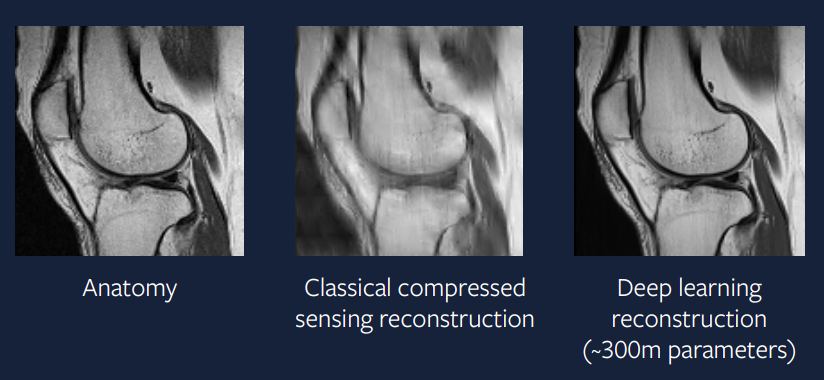
图9: 深度学习方法
用于生成此重构的模型使用ADAM优化器,组规范归一化层和基于U-Net的卷积神经网络。这种方法非常接近于实际应用,并且希望在几年后的临床实践中会看到这些加速的MRI扫描。 –>
📝 Guido Petri, Haoyue Ping, Chinmay Singhal, Divya Juneja
Harry (Chao) Yang
24 Feb 2020