NLP için Derin Öğrenme
🎙️ Mike LewisGenel Bakış
- Son senelerdeki inanılmaz gelişmeler:
- İnsanlar bazı diller için insan çevirmenler kullanmak yerine makine çevirisini tercih ediyor
- Birçok soru cevap veri setinde gösterilen süper-insan performansları
- Dil modelleri akıcı paragraflar üretebiliyor (örn. Radford et al. 2019)
- Her bir görev için çok az uzman bilgisine ihtiyaç var, bunları epeyce genel modellerle elde edebiliyoruz
Dil Modelleri
- Dil modelleri yazıya bir olasılık atarlar: $p(x_0, \cdots, x_n)$
- Çok fazla olası cümle olabilir, bu yüzden sadece bir ayırıcı eğitemeyiz
- En popüler metod zincir kuralını kullanarak bu dağılımı faktörize etmektir:
Sinirsel Dil Modelleri
Örneğin bir yazıyı sinirsel ağa girdi olarak veriyoruz, sinirsel ağ bunu bir vektöre eşleyecektir. Bu vektör bir sonraki kelimeyi temsil eder ve sonunda büyük bir kelime gömme matrisimiz olur. Kelime gömme matrisi, modelin çıktı olarak verebileceği her kelime için bir vektör içerir. Daha sonra bağlam vektörü ile her bir kelime vektörünün iç çarğımını alarak benzerliği hesaplarız. Bir sonraki kelimeyi tahmin etmek için bir olabilirlik (likelihood) elde ederiz, ve bu modeli maksimum olabilirlik (maximum likelihood) ile eğitiriz. Buradaki önemli nokta kelimelerle direkt olarak ilgilenmememiz, alt-kelime dediğimiz şeylerle ya da karakterlerle ilgileniyor olmamız.
\[p(x_0 \mid x_{0, \cdots, n-1}) = \text{softmax}(E f(x_{0, \cdots, n-1}))\]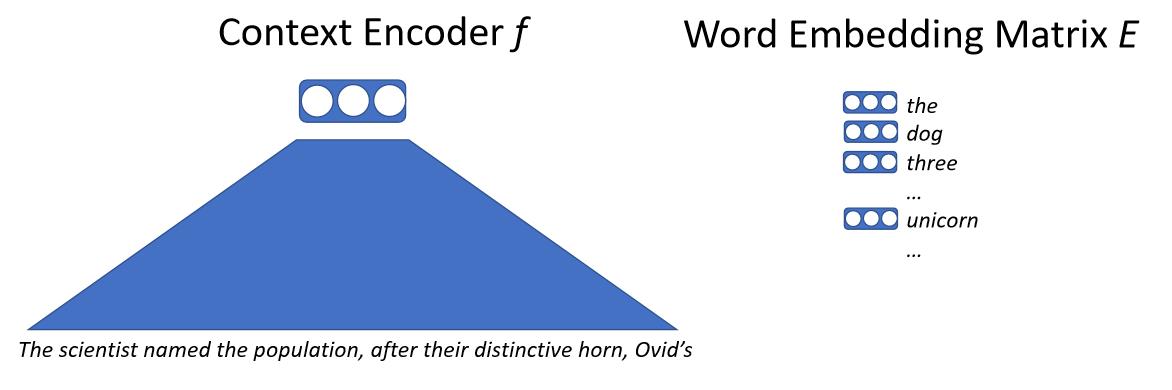
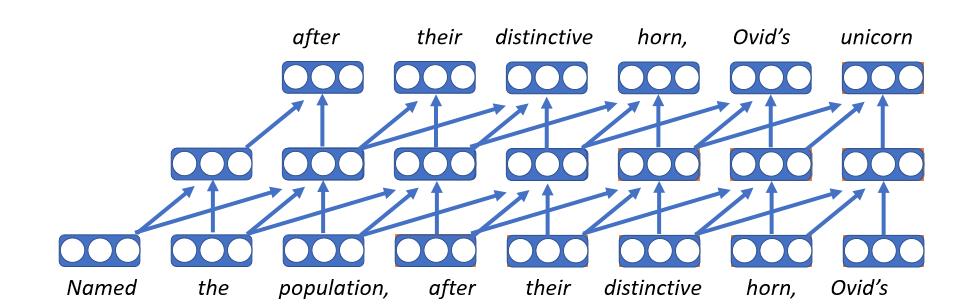
Evrişimli Dil Modelleri
- İlk sinirsel dil modeli
- Her kelimeyi vektör olarak göm, bu da gömme matrisinde çizelgeye bakarak karşılığını bulmaya tekabül ediyor, böylece hangi bağlamda olursa olsun o kelime aynı vektörü veriyor
- Her adımda aynı ileri besleme ağını uygula
- Malesef, geçmişte uzunluğun sabit olması demek sınırlı bağlamda şartlanması anlamına gelir
- Bu modellerin çok hızlı olma avantajları var
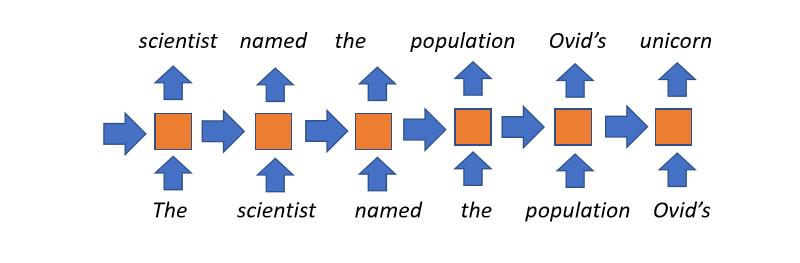
Yinelemeli Dil Modelleri
- Birkaç yıl öncesine kadarki en popüler yaklaşım
- Konsept olarak açık ve anlaşılabilir: her zaman aralığında belli bir durum elde ederiz (daha önceki zaman adımından gelen ve şu ana kadar ne okuduğumuzu gösteren). Bu durum şu anda okunan kelime ile birleştirilerek daha sonraki durum için kullanılır. Ne kadar zaman adımı varsa o bu işlem o kadar tekrar ettirilir.
- Sınırsız bağlam kullanır: örneğin bir kitabın başlığı kitabın son kelimesinin gizli durum(state)larını etkileyecektir.
- Dezavantajlar:
- Her zaman adımında bütün okunmuş doküman uzunluğu belli bir vektöre sıkıştırılır, bu da modelin sıkışma noktası olur (bottleneck)
- Gradyanlar uzun bağlamlarda yok olmaya eğilimlidir
- Zaman adımları üstünde paralelleştirilmesi mümkün değildir, yani yavaş eğitilir
Dönüştürücü (Transformer) Dil Modelleri
- Doğal dil işleme (NLP)’de en son kullanılan model
- Ceza konseptini ortaya çıkarttı
- Üç ana aşama:
- Girdi aşaması
- Değişik parametreli $n$ tane dönüştürücü (transformer) bloğu (kodlayıcı katlanlar)
- Çıktı aşaması
- Orijinal transformer makalesindeki 6 transformer modüllü (kodlayıcı katmanlı) örnek:
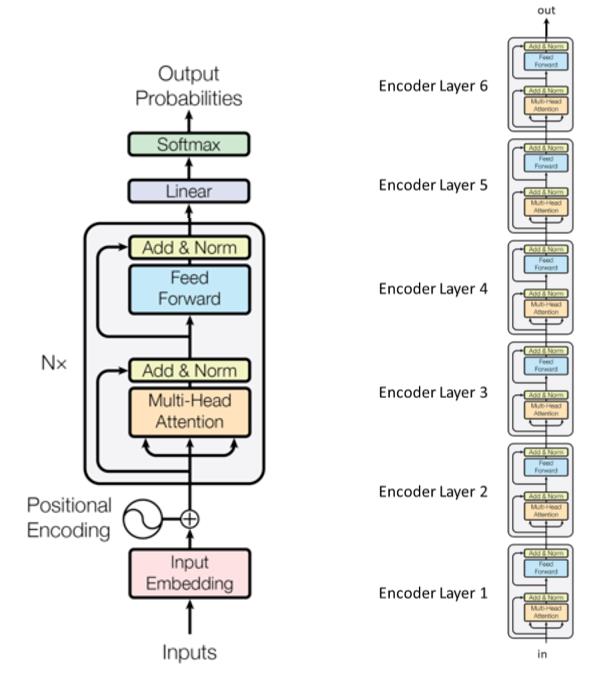
Alt katmanlar “Ekleme&Normalize” (Add & Norm) ile gösterilen kutularla birbirine bağlanırlar. “Add” kısmı artık (residual) bir bağlantı olduğunu gösteriyor, bu da gradyanın yok olmasını engellemekte yardımcı oluyor. Norm ise katman normalizasyonunu gösteriyor.
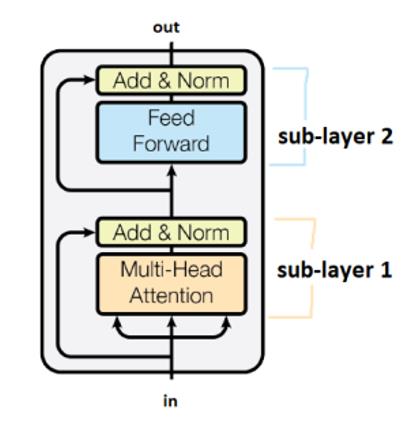
Dönüştürücüler değişik zaman adımlarındaki ağırlıkları paylaşırlar.
Çok başlı dikkat (Multi-headed attention)
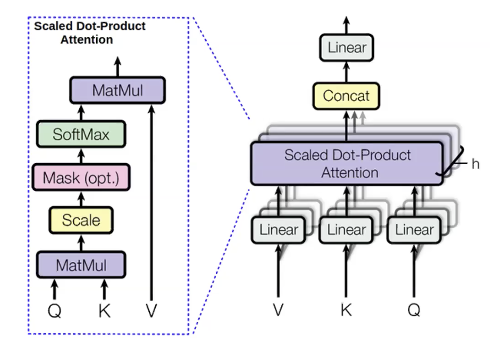
Tahmin etmeye çalıştığımız kelimeler için , query(q) (sorgu) denilen değerleri hesaplarız. Daha önceki tahminler için kullanılan tüm kelimeler keys(k) (anahtar) olarak adlandırılırlar. Query, bağlam hakkında fikir veren, örneğin daha önceki sıfatlar gibi şeylerdir. Key ise şu anki kelime ile ilgili bilgi taşıyan etiketlerdir, örneğin şu anki kelimenin sıfat olup olmaması gibi. q hesaplandığında, daha önceki kelimelerin dağılımı olan ($p_i$)’yı şöyle hesaplarız:
\[p_i = \text{softmax}(q,k_i)\]Daha sonra values(v) (değer) denilen değerleri de hesaplarız. Value’lar kelimelerin içeriklerini temsil ederler.
Değerleri hesapladığımızda, saklı durumları dikkat dağılımını maksimize ederek hesaplayabiliriz:
\[h_i = \sum_{i}{p_i v_i}\]Farklı query, value ve keyler için aynı şeyi paralel şekilde birden fazla kez hesaplarız. Bunun nedeni sonraki kelimeyi tahmin ederken değişik şeyleri kullanmak. Örneğin, “unicornlar” kelimesini, ondan önceki üç kelime olan “Bu”, “boynuzlu” ve “gümüş-beyazı” ile tahmin ederken. “Boynuzlu” ve “gümüş-beyazı” kelimelerinden bir unicorn olduğunu bilmiş oluyoruz. Ama “Bu” (These) kelimesi olduğundan unicorn’un çoğul olacağını biliyoruz. Bu nedenle, önceden gelen üç kelimeyi de daha sonraki kelimenin tahmininde kullanmayı isteriz. Çok başlı dikkat, her kelimenin birden fazla önceden gelen kelimeye bakmasına yarayan bir yol.
Çok başlı dikkatin bir büyük avantajı ise çok fazla parallelleştirmeye imkanı olması. RNN’lerin aksine, çok başlı dikkatin tüm başları ve tüm zaman adımları aynı anda hesaplanabiliyor. Bütün zaman adımlarını aynı anda hesaplamanın problemi ise, sadece önceki kelimelere şartlamak isterken gelecekteki kelimelere de bakabiliyor olmamız. Bu da öz-dikkat maskeleme denilen yöntemle çözülebilir. Kullanılan “maske” bir alt üçgen kısmında sıfırlar olan ve üst üçgen kısmında negatif sonsuz olan bir üst üçgenlenmiş matris. Bu maskeyi dikkat modülünün çıktı kısmına eklemek şöyle bir etki yaratıyor: her kelimenin solundaki kelime sağındaki kelimeden çok daha fazla dikkat skoruna sahip oluyor, böylece model pratikte sadece önce gelen kelimelere odaklanıyor. Dil modelinde bu maske uygulamasını kullanmak çok önemli çünkü matematiksel olarak doğru yapan şey bu, fakat metin kodlayıcılarında iki yönlü bağlamlar da önemli olabilir.
Dönüştürücü dil modelinin çalışmasında etkili olan bir detay da girdinin konumsal olarak gömülmesi. Dilde, sıralama gibi bazı özellikler anlama için önemlidir. Burada kullanılan teknik ise farklı zaman adımlarında ayrı ayrı gömmeler öğrenerek bunları girdiye eklemek, böylece girdi kelime vektörü ve konumsal vektörün bir toplamı oluyor, bu da sıralama bilgisini tutmuş oluyor.
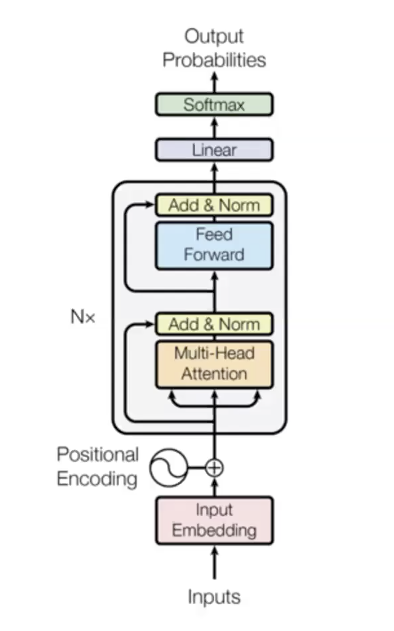
Neden bu model bu kadar iyi:
- Model her kelime ikilisi için direkt bağlantılar sağlıyor. Her kelime önceki kelimelerin gizli durumlarına direkt olarak, gradyanlar kaybolmadan erişebiliyor. Model çok pahalı bir fonksiyonu kolayca öğreniyor
- Her zaman adımı paralel olarak hesaplanıyor
- Öz-dikkat ikinci dereceden bir fonksiyon (her zaman adımı diğer adımlara bağlanabilir), bu da maksimum dizi boyutunu limitler
Bazı taktikler (özellikle çok başlı dikkat ve konumlamalı kodlama için) ve kodçözücü Dil Modelleri
Taktik 1: Eğitme sırasında katman normalizasyonunu çokça kullanmak, stabilizasyon için çok yararlı
- Dönüştürücüler için çok önemli
Taktik 2: Isınma + Ters karekök eğitme planlaması
- Öğrenme hızı planlamasını kullanmak: dönüştürücülerin iyi çalışması için, öğrenme hızını sıfırdan bininci adıma doğru lineer olarak azaltma planı yapmalısınız
Taktik 3: Dikkatli başlangıç değerleri
- Makine çevirisi gibi işlerde gerçekten yardımı oluyor
Taktik 4: Etiket düzleştirme
- Makine çevirisi gibi işlerde gerçekten yardımı oluyor
Aşağıdakiler, az önce bahsedilen metodların sonuçları. Bu testlerde, sağdaki ppl diye adlandırılan metrik ise perplexity (karışıklık)’dir (ppl ne kadar küçükse o kadar iyi).
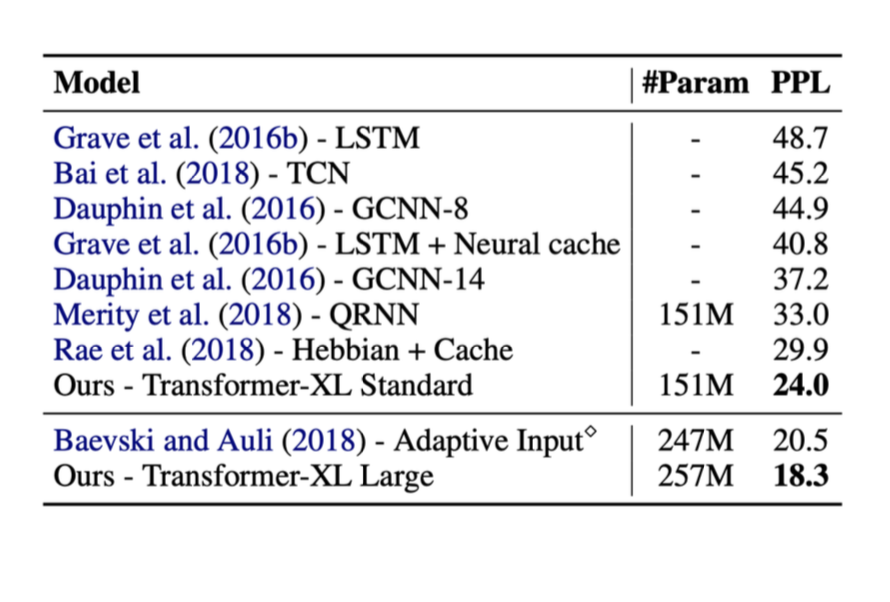
Dönüştürücüler işin içine girdiğinde performansın ne kadar arttığını görebilirsiniz.
Dönüştürücü Dil Modelleri’nin bazı önemli özellikleri
- Minimal model varsayımı
- Bütün kelimeler direkt olarak birbirine bağlı, kaybolan gradyanları azaltıyor.
- Bütün zaman adımları paralel olarak hesaplanıyor.
Öz-dikkat ikinci dereceden bir fonksiyon (her zaman adımı diğer adımlara bağlanabilir), bu da maksimum dizi boyutunu limitliyor.
- Öz dikkat ikinci dereceden olduğundan, maliyeti pratikte lineer olarak büyür, bu da problem oluşturabilir.

Dönüştürücüler büyütülmeye çok elverişlidir
- Sınırsız eğitme verisi, ihtiyacımız olandan bile fazla
- GPT-2, 2019’da 2 milyar parametre kullandı
- Son modeller 17 milyara kadar parametre kullanıyor
Kodçözücü Dil Modelleri
Artık bütün metin üzerinde bir olasılık dağılımı eğitebiliriz - ve üstel derecede fazla olasılıklı çıktılar elde edebiliriz, ve bu yüzden maksimumunu hesaplayamayız. İlk kelimeyi hangisi seçerseniz, bütün kararlar bu seçimden etkilenebilir. Bu nedenle, açgözlü kodçözme fikri ortaya sunuldu.
Açgözlü Kodçözme işe yaramıyor
Her zaman adımında en olası kelime alınır. Fakat bunun en olası diziyi verdiğinin garantisi yoktur çünkü eğer o adımı bir şekilde almak gerekirse, yapılan aramaya geri dönüp arayarak önceki aşamaları geri alma imkanı yoktur.
Kapsayıcı arama da mümkün değil
Tüm dizileri hesaplamayı gerektiriyor ve kompleksliği $O(V^T)$ olduğundan çok pahalı olur
Anlama ölçen Soru ve Cevaplar
-
Çok başlı dikkatin, tek başlı dikkate göre avantajı nedir?
- Bir sonraki kelimeyi tahmin etmek için birden çok şeyi görmeniz gerekiyor; başka bir deyişle dikkat önceki birden fazla kelimeye atanarak bir sonraki kelimeyi tahmin etmek için gerekli bağlamı anlamayı sağlıyor.
-
Dönüştürücüler, CNN ve RNN’lerin bilgi sıkışma noktalarını nasıl çözerler?
- Dikkat modelleri bütün kelimeler arasında direkt bağlantı olmasını sağlar, her kelimenin bir önceki kelimelere şartlı olması da bu sıkışma noktasını yok eder.
- Dönüştürücülerin RNN’lerden GPU paralelizasyonu açısından farkı nedir?
- Dönüştürücülerdeki çok başlı dikkat modülleri, GPU teknolojilerinden yararlanamayan RNN’lerin aksine oldukça paralelleştirilebilirlerdir. Hatta dönüştürücüler bir ileri geçişte bütün zaman adımlarını tek seferde hesaplayabilirler.
📝 Jiayu Qiu, Yuhong Zhu, Lyuang Fu, Ian Leefmans
mevah
20 Apr 2020