Özdenetimli Öğrenme - Pretex Görevleri
🎙️ Ishan MisraDenetimin başarı hikayesi: Ön eğitim
Geçtiğimiz on yılda, birçok farklı bilgisayarlı görü problemi için büyük başarı formüllerinden biri ImageNet sınıflandırması için denetimli öğrenme uygulanarak bir görsel temsil öğrenilmesidir. Ve, büyük miktarda etiketlenmiş veri bulunmadığı zaman bu öğrenilmiş temsilleri veya öğrenilmiş model ağırlıklarını başka bilgisayarlı görü görevleri için başlatma olarak kullanmak.
Bununla birlikte, ImageNet büyüklüğündeki bir veri kümesi için notlar almak son derece zaman alıcı ve masraflıdır. Örneğin 14M resim içeren ImageNet verisini etiketlemek kabaca 22 yıl alacaktır.
Bu yüzden, topluluk etiketleme işlemleri için sosyal medya resimlerindeki hashtag’ler, GPS yerelleştirme veya etiketin veri örnekleminin bir özelliği olduğu özdenetimli yaklaşımlar gibi bir alternatif aramaya başladı.
Fakat alternatif etiketleme işlemleri aramadan önce önemli bir soru karşımıza çıkıyor:
İşlemlerden sonra ne kadar veri elde edilebiliriz?
- Eğer bütün resimleri nesne seviyesinde kategori ve sınırlayıcı kutu notları ile arayacaksak, kabaca 1 milyon resim var.
- Eğer sınırlayıcı kutu için sınırlamaları kaldırırsak, uygun olan resim sayısı 14 milyona çıkıyor (yaklaşık olarak).
- Bununla birlikte, internetteki ulaşılabilir bütün resimleri dikkate alırsak, mevcut veri büyüklüğü 5 kat artmış olacaktır.
- Ve, sonrasında resimlerin dışında kalan elde edilmesi ve anlamlandırılması için diğer duyusal girdilere ihtiyaç duyan bir veri vardır.
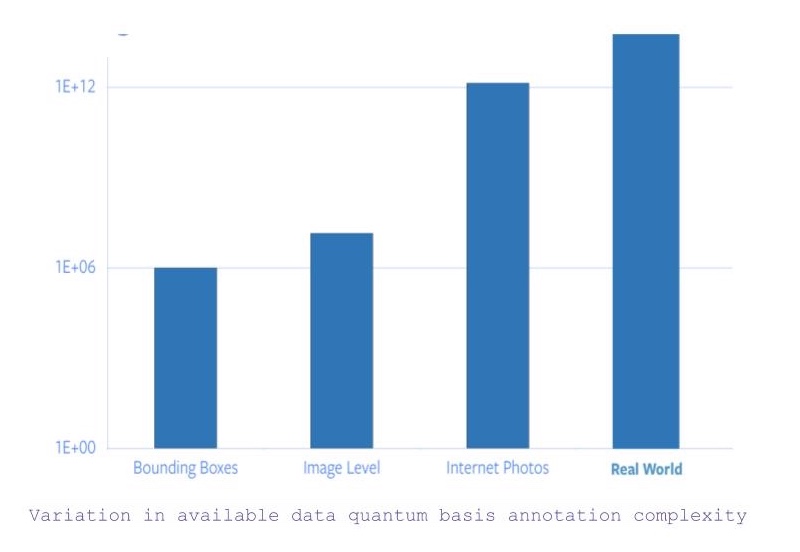
Figure 1: Variation in available data quantum basis complexity of annotation
Bu yüzden, sadece ImageNet’e özel notlandırma 22 yıl sürmekle beraber tüm internetteki fotoğraflar ve ötesi hiçbir şekilde mümkün değildir.
Ender konseptlerin problemi (Long Tail Problemi)
Genellikle internet resimleri için olan etiketlerin dağılımını gösteren çizimler uzun bir kuyruk gibi görünür. Bunun nedeni resimlerin birçoğunun az sayıda resim içeren çok fazla etiketin olmasına rağmen çok az bir etikete karşılık gelmesidir. Bu yüzden kategoriler için notlandırılmış örneklem elde etmek işaretlenmiş olmak için büyük miktarlarda veri gerektirmektedir.
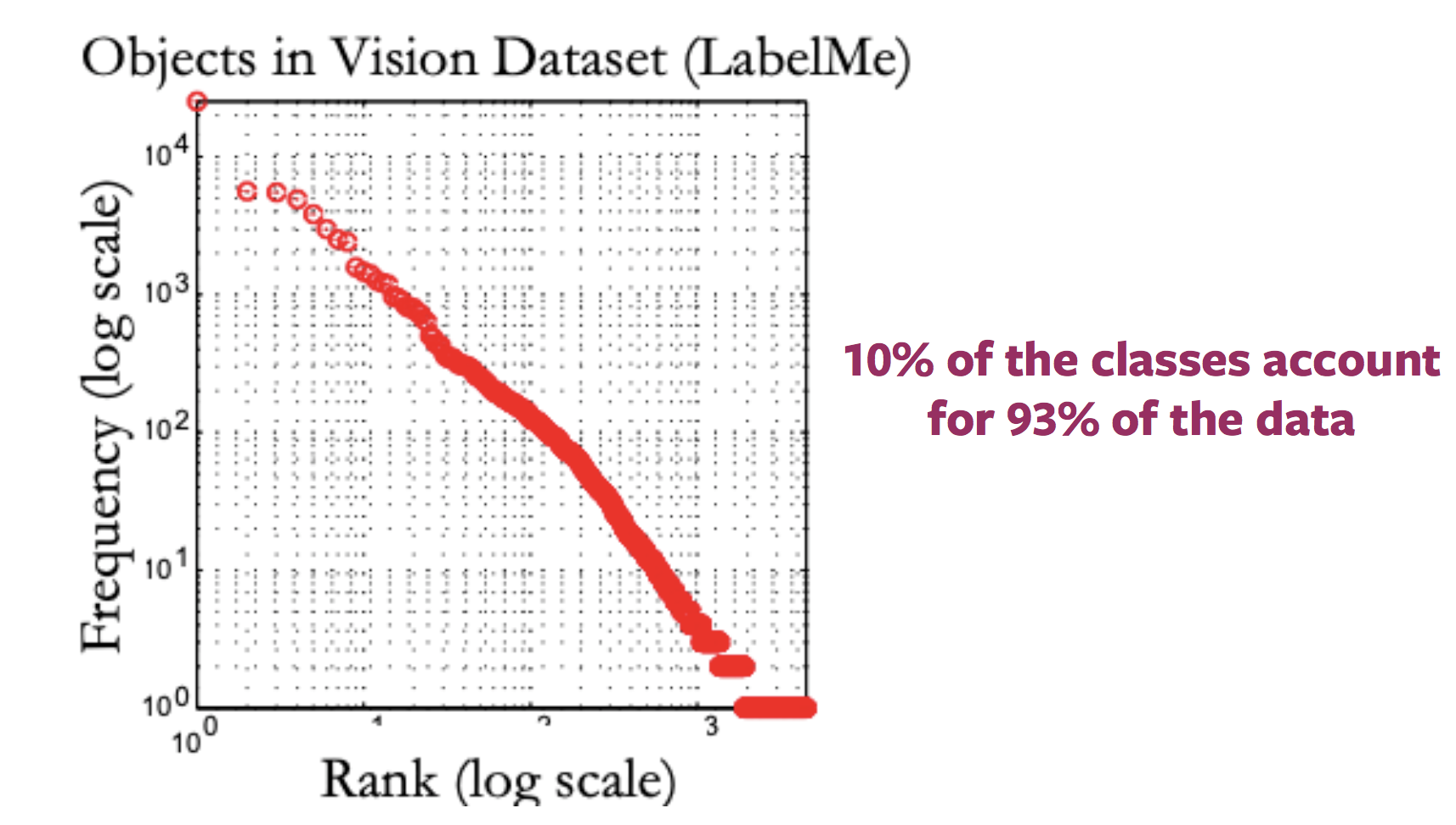
Figure 2: Variation in distribution of available images with labels
Farklı Alanlardaki Problemler
Bu ön eğitimli ImageNet metodu ve downstream görevi üzerinde ince ayar downstream görev resimleri medikal resimler gibi tamamıyla farklı bir alana ait olduğu zaman daha da belirsiz olmaktadır. Ve, farklı alanlarda ön eğitim için ImageNet’ten bir miktar veri kümesi elde etmek mümkün değildir.
Özdenetimli Öğrenme Nedir?
Özdenetimli öğrenmeyi Tanımlamak için İki Yol
-
Temel Denetimli Öğrenme Tanımı, diğer bir deyişle ağlar yarı otomatik bir şekilde insan girdisi kullanmadan etikleme yapmak için denetimli öğrenmeyi uygular.
-
Öngörü Problemi, verinin bir miktarının gizli ve kalanının kullanıma uygun olduğu durumlar. Bu yüzden amaç ya gizli veriyi öngörme yada gizli verinin bazı özelliklerini öngörmektir.
Özdenetimli Öğrenme Denetimli ve Denetimsiz Öğrenmeden Hangi Yönleriyle Ayrılır?
- Denetimli öğrenme görevi önceden tanımlı (ve genellikle insanlar tarafından sağlanmış) etiketlere sahiptir,
- Denetimsiz Öğrenme herhangi bir denetim, etiket veya doğruluk olmadan sadece veriye sahiptir.
- Özdenetimli Öğrenme verilen bir veri örneklemi için eş zamanda oluşan bir yöntemden veya eş zamanda oluşan veri örnekleminin bir paçasından etiketlerini türetir.
Doğal Dil işlemede Özdenetimli Öğrenme
Word2Vec
- Verilen bir girdi cümelesi için, görev bu cümlede eksik olan bir kelimeyi öngörmeyi kapsamaktadır, ki bu kelime özel olarak bu görevi inşa etme amacıyla çıkarılmıştır.
- Bu yüzden, etiket seti sözlükteki bütün olası kelimeler haline gelir, ve doğru etiket bizim cümleden çıkardığımız kelime olur.
- Böylece, ağ sonrasında düzenli gradyan tabanlı yöntemler kullanılarak kelime seviyesinde gösterimi öğrenmek için eğitilebilir.
Neden Özdenetimli Öğrenme?
- Özdenetimli öğrenme verinin gösterim öğrenimini sadece verinin farklı parçalarının nasıl etkileşimde olduğunu gözlemleyerek olanak verir.
- Böylece büyük miktarda notlandırışmış veri gereksinimini indirir.
- Ek olarak, bir veri örneklemi ile ilişkili olabilecek birden fazla yöntemin geliştirilmesine olanak verir.
Bilgisayarlı Görüde Özdenetimli Öğrenme
Genel olarak, bilgisayarlı görü süreci pretex görevi ve real (downstream) görevi olmak üzere 2 görevi kapsayan özdenetimli öğrenmeyi kullanır.
- Real (downstream) görevi yetersiz notlandırılmış veri ile sınıflandırma veya sezim görevi gibi herhangi bir şey olabilir.
- Pretext görevi öğrenilmiş görsel gösterimler veya downstream görevi sırasında öğrenilmiş model ağırlıkları yardımıyla görsel gösterim öğrenmek için çözülmüş bir görevdir.
Pretext Görevi Geliştirme
- Bilgisayarlı görü problemleri için pretext görevleri ya resim ve video yada video ve ses kullanılarak geliştirilebilir.
- Her bir pretext görevi için, görünen parça ve gizli parça vardır ki görev ya gizli parçayı yada gizli parçanın bazı özelliklerini öngörmektir.
Örnek Pretext Görevi: Resim Parçalarının Göreceli Pozisyonunu Öngörme
- Girdi: 2 resim parçası, biri anchor resim parçasıyken diğeri sorgu resim parçasıdır.
- 2 resim parçası verildiğinde, ağ göreceli sorgu resim parçasının anchor resim parçasına göre pozisyonu öngörmeye ihtiyaç duyar.
- Böylece, verilen anchor için sorgu resminde 8 olası lokasyon olduğu için bu problem 8 sınıflı sınıflandırma problemi olarak modellenebilir.
- Ve, bu görev için etiket, otomatik olarak anchor’a göre sorgu resim parçasının göreceli pozisyonu beslenerek üretilebilir.
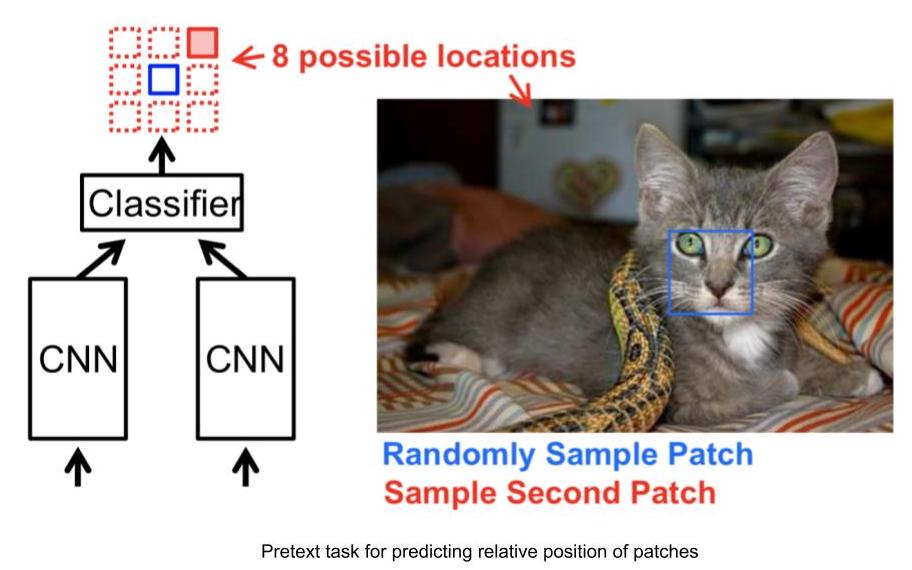
Figure 3: Relative Position task
Göreceli Pozisyon Öngörü Görevi ile öğrenilen Görsel Gösterim
Öğrenilmiş görsel gösterimin etkililiğini ağ tarafından sağlanan bir resim parçasının temel öznitelik gösteriminin en yakın komşularını kontrol ederek değerlendirebiliriz. Verilen bir resim parçasının en yakın komşularını hesaplamak için,
- Veri kümesindeki bütün resimlerin CNN gösterimlerini hesapla ki bu retrieval için örneklem havuzu olarak alınacaktır.
- Gereken resim parçası için CNN gösterimini hesapla.
- Uygun olan resimlerin öznitelik vektörleri havuzundan gereken resmin öznitelik vektörlerinin en yakın komşularını tanımla.
Göreceli pozisyon görevi nesne rengi gibi faktörleri değiştirmeyerek girdi resmine çok benzeyen resim parçalarını bulur. Böylece göreceli pozisyon görevi görsel gösterimi öğrenme kabiliyetine sahiptir ki benzer görsel görünümlere sahip resim parçaları için gösterimler gösterim uzayına da yakın olmuş olur.

Figure 4: Relative Position: Nearest Neighbours
Resimlerin Rotasyonlarını Öngörme
- Rotasyonları öngörme basit ve anlaşılır bir mimarisi olan ve minimal örnekleme ihtiyaç duyan popüler pretext görevlerinden biridir.
- 0, 90, 180, 270 derecelerdeki rotasyonları resme uygularız ve bu rotasyonlu resimleri resme hangi sıra ile hangi rotasyon uygulanmış bilgisini öngörmek için ağa göndeririz ve ağ rotasyonu öngörmek için basit olarak 4 sınıflı sınıflandırma yapar.
- Rotasyonları öngörmek hiçbir anlamsal bilgi vermez, sadece bu pretex görevini bir downstream görevinde kullanmak için bazı öznitelikleri ve gösterimleri öğrenmede bir vekil gibi kullanmış oluruz.
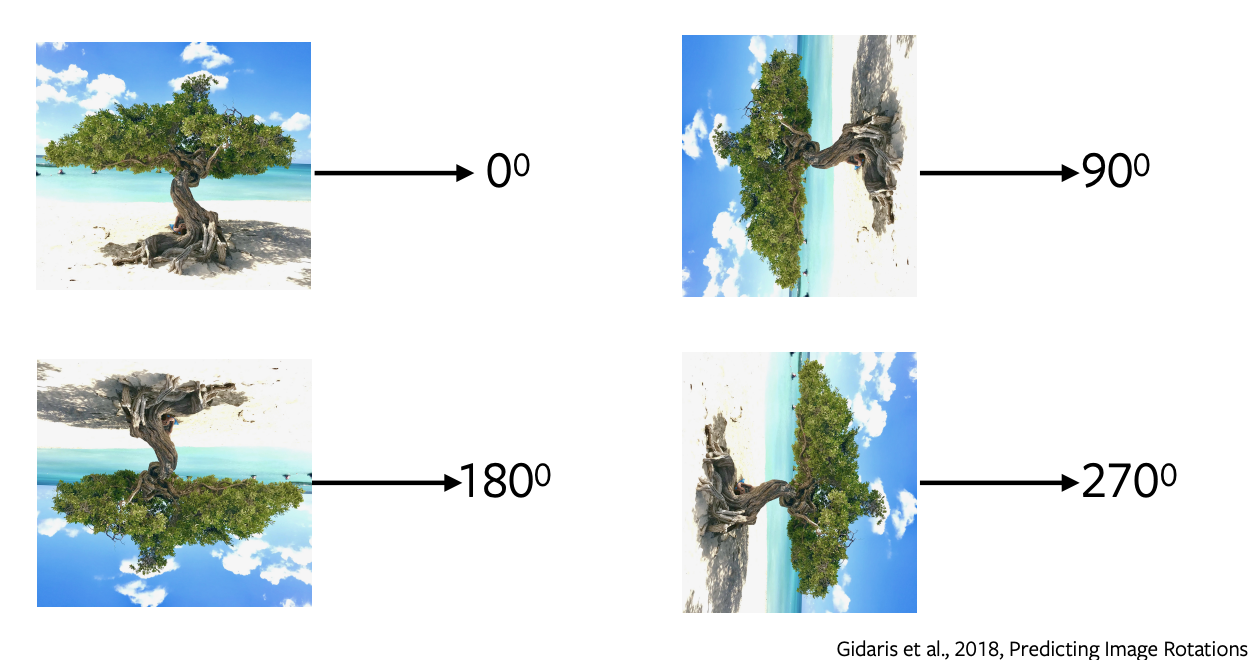
Figure 5: Rotations of Image
Neden Rotasyon faydalıdır veya Neden İşe Yarar?
Çalıştığı deneysel olarak kanıtlanmıştır. Arkasındaki sezgi rotastonları öngörmek için modelin kaba sınırlara ve bir resmin gösterimine ihtiyaç duymasıdır. Örneğin, gökyüzünü sudan ayırmak veya kumu sudan ayırmak zorunda kalacaktır veya ağaçların yukarıya doğru uzamasını anlayacaktır gibi gibi.
Renklendirme

Figure 6: Colorisation
Bu pretext görevinde, gri tonlamalı bir resmin renklerini öngöreceğiz. Herhangi bir resim için formüle edilebilir ve sadece renkler kaldırılarak ve bu gri tonlamalı resim ile ağ beslenerek resmin rengi öngörülebilir. Bu görev eski gri tonlamalı resimleri renklendirme gibi bazı açılardan oldukça faydalıdır. Bu görevin arkasındaki sezgi ağın ağaçlar yeşildir, gökyüzü mavidir gibi gibi bazı anlamlı bilgileri anlamaya ihtiyaç duymasıdır.
Renk haritalamanın deterministik olmadığını ve birçok olası doğru çözümün olabileceğini söylemek önemli. Bu yüzden bir nesne için, eğer birçok olası renk varsa ağ o objeyi gri olarak işaretleyecektir ki bu birçok farklı olası çözümün olduğunu gösterir. Bazı yeni çalışmalar değişimsel otokodlayıcılar ve çeşitli renklendirme için gizli değişkenlerde kullanmaktadırlar.
Boşlukları Doldur
Resmin bir parçasını gizler ve gizlenmiş parçayı resmin kalan parçasından öngörmeye çalışırız. Bu yöntem işe yarıyor çünkü ağ arabanın yolda gitmesi, binaların pencerelerden ve kapılardan oluşması gibi verinin kapalı yapısını öğreniyor.
Videolar için Pretext Görevler
Videolar görüntü sekanslarından oluşmaktadır ve bu notasyon özdenetimli öğrenmenin arkasıdaki fikirdir ki görüntülerin sırasını öngörme, boşlukları doldurma ve nesne takip etme gibi bazı pretext görevler için geliştirilebilir.
Karıştırma & Öğrenme

Figure 7: Interpolation
Bir grup görüntü verildiğinde, 3 görüntüyü alırız ve eğer bu alınan görüntüler doğru sırayla alınmışsa pozitif olarak etiketleriz, eğer karışık alınmışsa negatif olarak etiketleriz. Problem görüntülerin doğru sırada olup olmadığını öngörmeye çalışan bir ikili sınıflama problemine dönüşmüş olur. Böylece verilen bir başlangıç ve bitiş noktası için, ortadaki ikili interpolasyonların geçerli olup olmadığını kontrol ederiz.
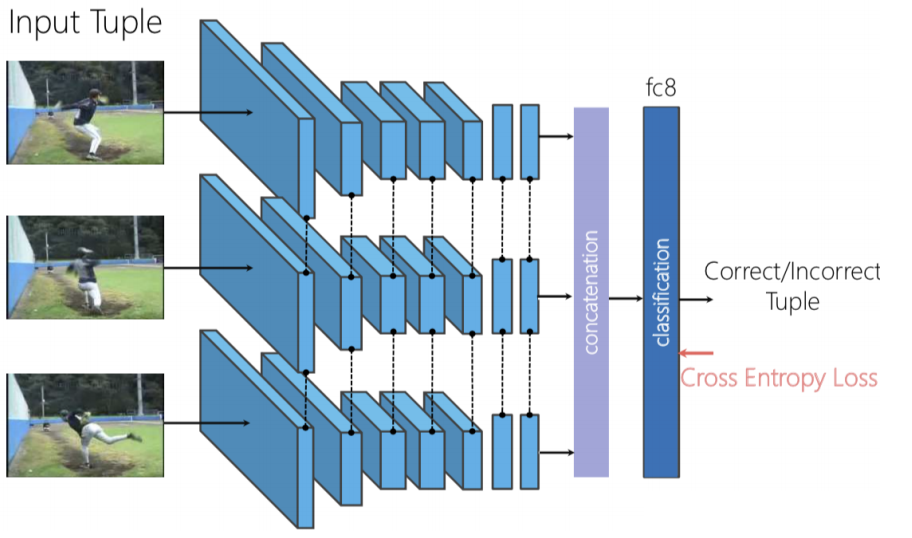
Figure 8: Shuffle & Learn architecture
Üç görüntünün bağımsız olarak ileri beslendiği ve sonrasında üretilen özniteliklerin peşpeşe sıralandığı ve görüntülerin karışık olup olmadığını öngörmek için ikili sınıflama uyguladığımız bir üçlü Siamese ağı kullanabiliriz.

Figure 9: Nearest Neighbors Representation
Bir taraftanda, ağımızın ne öğrendiğini görselleştirmek için en yakın komşu algoritmasını kullanabiliriz. Yukarıdaki Fig. 9’da ilk olarak öznitelik gösterimi elde etmek için ağa ileriye doğru beslediğimiz bir sorgu resmine sahibiz. Karşılaştırma yaparken ImageNet tarafından, Shuffle & Learn tarafından ve rastgele olarak sağlanan komşular arasındaki kesin farkı gözlemleyebiliriz.
ImageNet bütün anlamsalı daraltmada iyidir çünkü ilk girdi için bir spor sahnesi olduğunu anlayabilir. Benzer olarak, ikinci sorgu için çimenli bir dış mekan sahnesi olduğunu anlayabilir. Oysaki rastgele olarak gözlemlediğimiz zaman arkaplan renklerine yüksek önem verdiğini görürüz.
Karıştırma & Öğrenme’yi gözlemlerken, onun renklere veya anlamsal konsepte odaklanıp odaklanmadığı hemen anlamak mümkün değil. Birçok başka denetleme ve çeşitli örneği gözlemledikten sonra, insanın konumuna baktığı gözlemlenebilir. Örneğin, sahneyi veya arkaplan resmini gözardı edersek, birinci resimde insan tersdir ve ikinci resimde ayaklar sorgu resmine benzer olarak özel bir pozisyondadır. Bunun arkasındaki mantık bizim pretext görevinin görüntülerin doğru sırada olup olmadığını öngörmesidir ve bunu yapmak için ağ sahnede neyin hareket ettiğine odaklanmasına ihtiyacı vardır, ki bu örnekte hareket eden insandır.
Bu insan anahtar nokta tahmin etme görevi gösterime ince ayar yapılarak nicel olarak doğrulanmıştır ki verilen bir insan resminde burun, sol omuz, sağ omuz, sol dirsek gibi kesin anahtar noktalarını öngörürüz. Bu takip etme ve konum tahmin etme için faydalı bir yöntemdir.
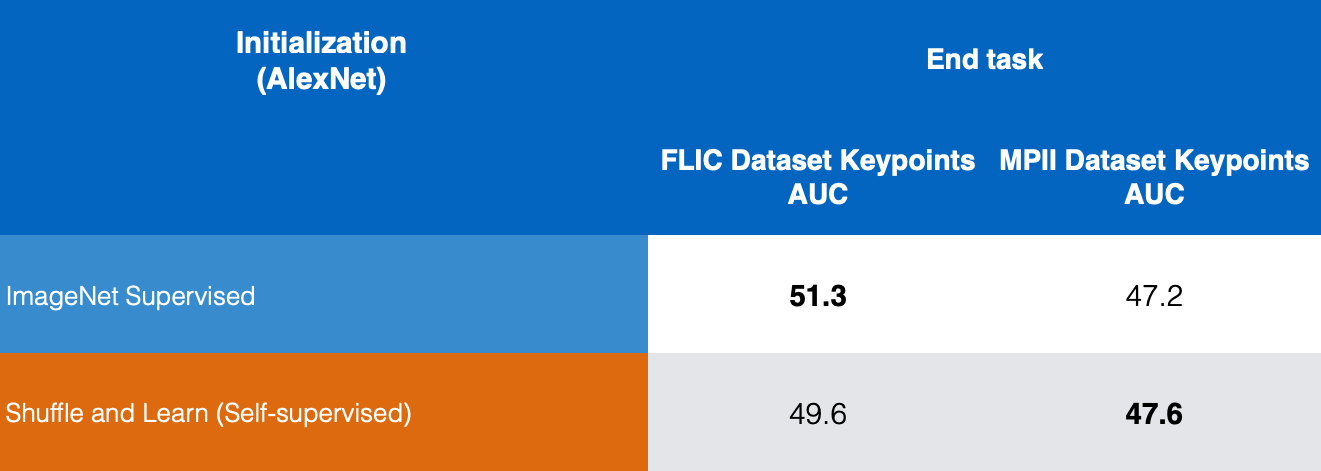
Figure 10: Keypoint Estimation comparison
Figüre 10’da, FLIC ve MPII veri kümeleri üzerinde denetimli ImageNet ve özdenetimli Shuffle & Learn sonuçları karşılaştırılmıştır ve Karıştırma ve Öğrenme, anahtar nokta tahmin etmede iyi sonuçlar verdiğini görebiliriz.
Videolar ve Ses için Pretext Görevi
Video ve ses biri videolar için biri de ses için olmak üzere 2 yönteme veya duyusal girdilere sahip olduğumuz çoklu modeldir. Bir girdi video klibinin ses klibine ait olup olmadığını öngörmeye çalışırız.

Figure 11: Video and sound sampling
Verilen sesli bir videoda, karşılık gelen sesleriyle beraber videolardan örneklemler al ve bunları pozitif set olarak adlandır. Sonra sesi ve bir gitar video görüntüsünü al ve negative olarak isimlendir. Şimdi problemi ikili sınıflandırma problemi olarak çözmek için ağımızı eğitebiliriz.
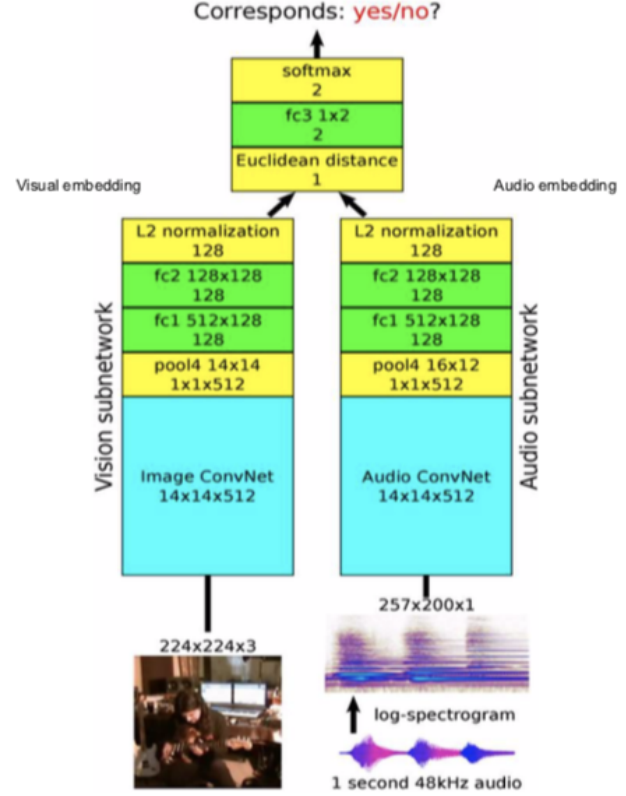
Figure 12: Architecture
Mimari: Video görüntülerini görsel alt ağdan geçir ve sesi alt ses ağından geçir ki bu bize 128 boyutlu bir öznitelikleri ve gömüleri verecektir, sonrasında bunları birleştirip birbirlerinin karşılığı olup olmadığını öngören ikili sınıflandırma problemi olarak çözebiliriz.
Bu yöntem görüntüde sesi yapanın ne olabileceğini öngörmek için kullanılabilir. Burada sezgi, ses eğer gitarın sesi ise ağın kabaca gitarın neye benzediğini anlamaya ihtiyacı vardır ki bu durum sesler içinde geçerlidir.
“Pretext” Görevinin Ne Öğrendiğini Anlama
-
Pretext görevi tamamlayıcı olmalıdır.
- Mesela Göreceli Pozisyon ve Renklendirmeyi örnek olarak ele alalım. Bir modeli aşağıda gösterilen her iki pretext görevini öğrenmek için eğiterek performansını artırabiliriz.
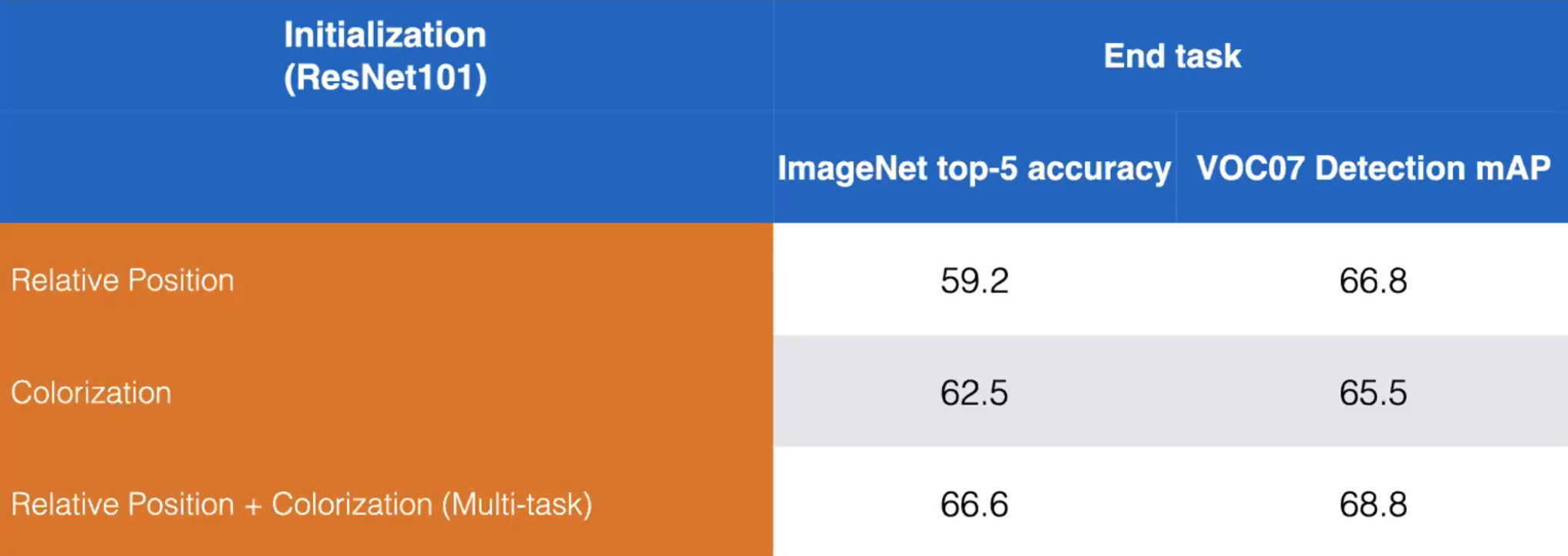
Figure 13: Comparison of disjoint vs combined training of Relative Position and Colorization pretext tasks. ResNet101. (Misra)
-
Tek bir pretext görevi, SS gösterimi öğrenmek için doğru bir cevap olmayabilir.
-
Pretext görevleri neyi öngörmeye çalışmaları (zorlukla) yönünden fazlasıyla çeşitlilik gösterebiliyor.
- Göreceli pozisyon basit bir sınıflandırma olduğu için kolaydır.
- Maskeleme ve doldurma çok daha zordur –> daha iyi bir gösterim
- Karşıtsal yöntemler bile pretext görevlerine göre daha fazla bilgi üretir.
-
Soru: Birden fazla ön eğitimli görevi nasıl eğitiriz?
- pretext çıktısı girdiye bağlı olacaktır. Ağın son tam bağlantılı katmanı toptan tipine bağlı olarak takas edilebilir.
- Örneğin: Siyah-beyaz resimlerden oluşan bir toptan ile renkli resimler üreten bir model beslenebilir. Sonra son katman değiştirilir, ve dizilerden oluşan bir toptan göreceli pozisyon öngermek için verilir.
-
Soru Bir pretex görevi üzerinde ne kadar eğitim yapılmalıdır?
- Temel kural: downstream görevini geliştiren çok zor bir pretext görevine sahip ol.
- Pratikte, pretext görevi eğitilmişde olabilir eğitilmemişte. Geliştirme aşamasında, bütün sürecin bir parçası olarak eğitilir.
Özdenetimli Öğrenmeyi Ölçeklendirme
Jigsaw Bulmacaları
-
Bir resmi birden fazla desene ayır ve sonra bu desenleri karıştır. Model daha sonra desenlerin orijinal konfigürasyona geri karıştırılmasıyla görevlendirilir.. (Noorozi & Favaro, 2016)
- Girdiye hangi permütasyonun uygulandığını öngör.
- İşlem bir resmin her bir deseninin bağımsız olarak değerlendirilmesi gibi desenlerden oluşan toptanları oluşturmasıyla biter. Evrişimsel çıktı sonrasında peşpeşe sıralanır ve permütasyon aşağıdaki figürdeki gibi öngörülür.
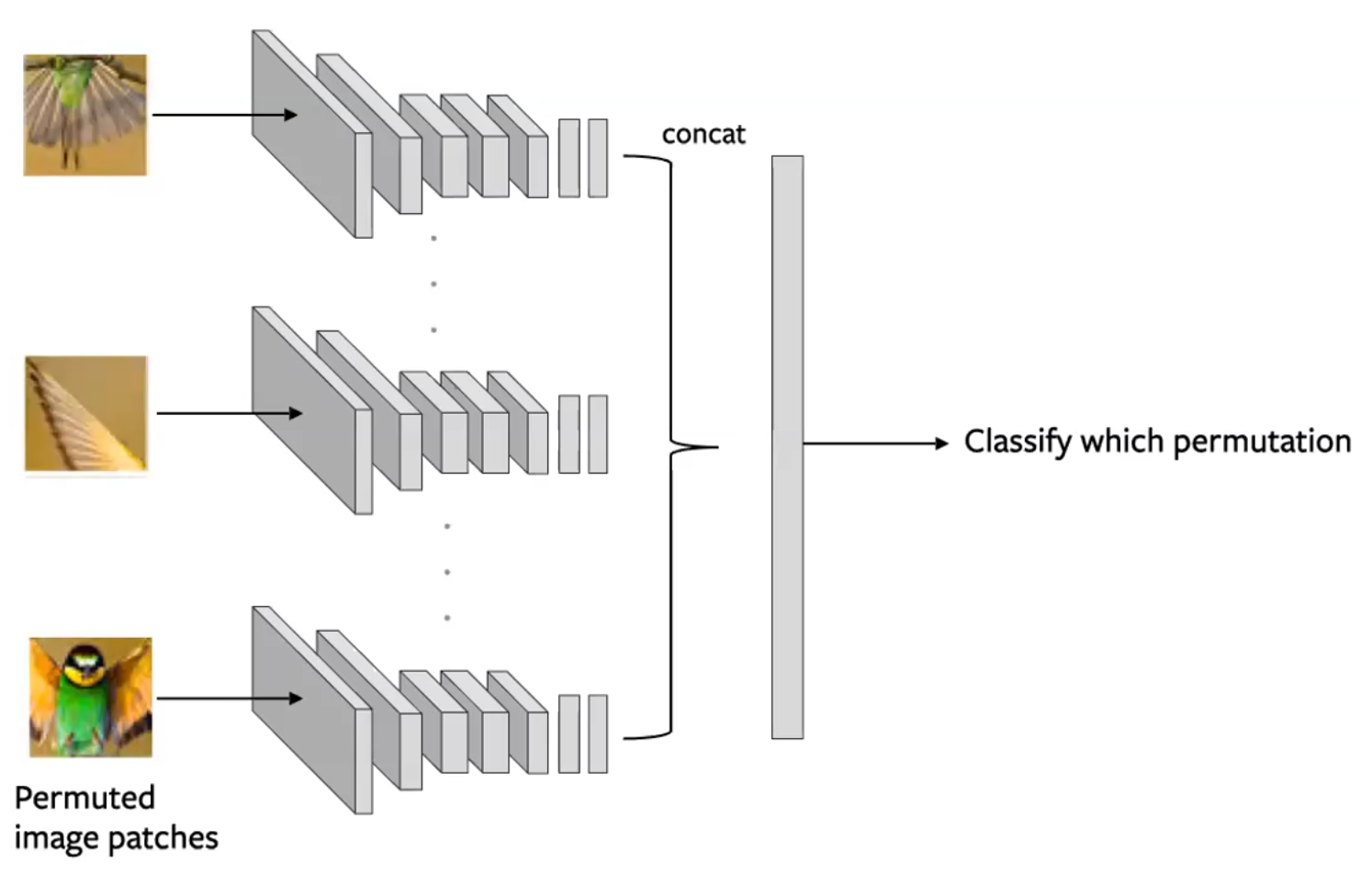
Figure 14: Siamese network architecture for a Jigsaw pretext task. Each tile is passed through independently, with encodings concatenated to predict a permutation. (Misra)
- Göz önünde tutulanlar:
- Bir permütasyon altseti kullan (diğer bir deyişle: 9! sayısından, 100 sayısını kullan)
- n sınıflı ConvNet, paylaşılan parametreler kullanır.
- Karmaşıklık problemi altsetin büyüklüğüdür. öngördüğün bilgi büyüklüğü.
-
Bu yöntem bazen downstream görevlerde denetimli yöntemlerden daha iyi çalışır, çünkü ağ girdisinin geometrisine dair bazı konseptleri öğrenme kabiliyetine sahiptir.
-
Yetersizlikler: Few Shot Learning: Limitli sayıdaki eğitim örnekleri
- Özdenetimli gösterimler örnek olarak verimli değillerdir.
Değerlendirme: İnce Ayar vs Doğrusal Sınıflama
Bu değerlendirme formu bir tür öğrenme aktarmasıdır.
-
İnce Ayar: Downstream göreve uyguladığımız zaman, bir başlatıcı olarak bütün ağda yeni bir tane daha eğitebilmek ve bütün ağırlıkları güncellemek için kullanırız.
-
Doğrusal Sınıflandırıcı: pretex ağımızın en üst seviyesinde, downstream görevini uygulamak için küçük bir doğrusal sınıflandırıcı eğitiriz ve ağın kalan kısmını öylece bırakırız.
İyi bir gösterim az bir eğitim ile transfer olabilmelidir.
- Farklı görevlerdeki çokluk üzerinde pretext öğrenimini değerlendirmek faydalıdır. Bu yüzden ağda farklı katmanlar tarafından oluşturulan gösterimin sabit öznitelik olarak çıkarılması ve bu farklı görevler karşısındaki yararlılıklarını değerlendirerek yapabiliriz.
- Ölçüm: Mean Average Precision (mAP) –Göz önüne aldığımız farklı bütün görevlerin kesinlik ortalaması.
- Bu görevlerden bazıları şunları içerir: Nesne Tanıma (ince ayar kullanılarak), Yüzey Normal Tahmini (bkz. NYU-v2 veri kümesi)
- Herbir katman ne öğrenir?
- Genel olarak, katmanlar derinleştikçe, kendi gösterimlerini kullanan downstream görevleri üzerindeki the mean average precision artacaktır.
- Bununla birlikte, son katman, katmanın fazlaca uzmanlaşmış olması sebebiyle mAP’de kesin bir düşüş görür.
- Bu denetimli ağlar ile zıtlık oluşturur, bu mAP’ler genellikle katmanın derinliği ile yükselir.
- Bu pretext görevlerinin downstream görevler ile iyi hizalanmamış olduğunu gösterir.
📝 Aniket Bhatnagar, Dhruv Goyal, Cole Smith, Nikhil Supekar
Yunus Emre Özköse
6 Apr 2020