Evrişimli Ağların Uygulamaları
🎙️ Yann LeCunPosta Kodu Tanıma
Önceki derste evrişimli ağların nasıl sayıları tanıyabileceğini gösterdik, ancak modelin nasıl her bir sayıyı seçerken yanındaki sayılardan kaynaklanan karışıklığı önleyebildiği sorusunu cevaplamadık. Bir sonraki adım üst üste gelen/gelmeyen nesneleri saptamak ve genel Maximum Olmayanı Baskılama (Non-Maximum Supression, NMS) yaklaşımını kullanmak. Bu örnekte girdilerin üst üste gelmeyen sayılar olduğu varsayımı göz önüne alındığında, izlenecek strateji birden fazla evrişimsel ağ eğitip çoğunluk oylamasını kullanarak veya evrişimli ağ tarafından üretilen en yüksek skora sahip sayıyı seçmektir.
CNN’lerle Tanıma
Burada üst üste gelmeyen beş haneli posta kodlarını tanıma görevini sunuyoruz. Sisteme her bir haneyi nasıl ayıracağına dair yönergeler verilmemiştir, ama sistem beş hane tahmin etmesi gerektiğini bilmektedir. Fig. 1’de görüldüğü üzere, sistem 4 farklı boyutta, her biri farklı çıktılar üreten evrişimli ağlardan oluşmaktadır. Çıktı matris şeklinde gösterilmektedir. Dört çıktı matrisi son katmanda farklı çekirdek (kernel) genişliklerine sahip modellerden gelmektedir. Her bir çıktıda 0’dan 9’a 10 kategoriyi ifade eden 10 satır bulunmaktadır. Daha büyük olan beyaz kare o kategoride daha yüksek bir skoru temsil etmektedir. Bu dört çıktı bloğunda son katman çekirdeklerinin yatay eksendeki boyutları sırasıyla 5, 4, 3, ve 1’dir. Kernel boyutu modelin girdiye baktığı pencerenin genişliğini belirler, böylece kullanılan her model farklı pencere boyutları ile tahmin yapmış olur. Daha sonra model çoğunluk oylaması yöntemini uygulayarak o pencerede en yüksek skora sahip olan kategoriyi seçer. Kullanışlı bilginin çıkarılabilmesi için, tüm karakterlerin tüm kombinasyonlarının olası olduğu ve dolayısıyla çıktıların doğru posta kodları olduğunu garanti altına almak için girdi kısıtlamalarını kullanarak hata düzeltmeleri yapılmasının faydalı olacağı göz önünde bulundurulmalıdır.

Fig 1. Posta kodu tanımada kullanılan birden fazla sınıflandırıcı
Karakterlerin sırasının nasıl belirlenmesi için püf noktası bir en kısa yol algoritması kullanmaktır. Olası karaklerin aralıklarını ve toplam kaç basamak tahmin etmemiz gerektiğini bildiğimizden bu probleme basamak oluşturmanın ve basamaktan basamağa geçişin minimum maliyetini hesaplayarak yaklaşabiliriz. İzlenecek yol grafikteki sol alt hücreden sağ üst hücreye doğru kesintisiz olmalı ve yalnızca sağdan sola, yukarıdan aşağıya hareketler içerecek şekilde kısıtlanmalıdır. Eğer aynı sayılar yan yana tekrar edilirse, algoritmanın bu sayıların tek basamak tahmin etmektense bunların tekrar eden sayılar olduğunu ayırt edebilmesi gerektiğine dikkat edin.
Yüz Saptama
Evrişimli ağlar saptama görevlerinde iyi çalışırlar ve yüz saptama bir istisna değildir. Yüz tanıma gerçekleştirmek için, üzerinde, örneğin 30 $\times$ 30’luk bir pencere boyutuna sahip bir evrişimli ağ eğiteceğimiz ve ağa girdinin yüz içerip içermediğini sorabileceğimiz, yüz içeren ve içermeyen resimlerden oluşan bir verikümesi oluşturmamız gerekir. Eğitildikten sonra modeli yeni bir resme uyguladığımızda, 30 $\times$ 30’luk bir pencerede bir yüz varsa, evrişimli ağ karşılık gelen konumlarda parlayacaktır. Ancak, iki problem vardır.
-
Yanlış Pozitifler: Resmin bir kısmının bir yüz olmadığı bir çok durum vardır. Eğitim aşamasında model bunların hepsini görmeyebiliriz (diğer bir deyişle tamamen temsilci bir kümeyi). Bu nedenle model test aşamasında model bir çok yanlış pozitifle karşılaşabilir.
-
Farklı Yüz Boyutları Tüm yüzler 30 $\times$ 30 piksel değildir, yani farklı boylardaki yüzler saptanamayabilir. Bunu çözmenin yollarından biri aynı resmin çoklu-ölçekli versiyonlarını oluşturmaktır. Orijinal saptayıcı 30 $\times$ 30 civarı boyuta sahip yüzleri saptar. resim $\sqrt 2$ katsayısıyla ölçeklendirilirse, model orijinal görüntüdeki daha küçük yüzleri, 30 $\times$ 30 yaklaşık 20 $\times$ 20 piksele dönüştüğünden tanıyabilecektir. Daha büyük yüzleri tanıyabilmek için görüntü küçültülebilir. Bu işlem masrafın yarısı original, ölçeklenmemiş resmi işlemekten geldiğinden masrafsız bir işlemdir. Tüm diğer ağların masraflarının toplamı neredeyse ölçeklenmemiş resmi işlemekle aynıdır. Ağın boyutu resmin bir boyutunun karesidir, yani görüntüyü $\sqrt 2$ ile ölçeklerseniz, çalıştırmanız gereken ağ 2 kat daha küçük olur. Tüm masraf $1+1/2+1/4+1/8+1/16…$, yani 2’dir. Çok ölçekli bir model kullanmak hesaplama maliyetini sadece iki katına çıkarır.
Bir Çok Ölçekli Yüz Saptama Sistemi

Fig. 2. Yüz saptama sistemi
Fig. 3’te gösterilen harita yüz saptayıcılarının skorlarını gösterir. Bu yüz saptayıcı 20 $\times$ 20 boyutuna sahip yüzleri saptar. (Ölçek 3 - Scale 3) İnce ölçekte çok fazla yüksek skor varıdr ama bunlar kesin değildir. Ölçek arttığında (Ölçek 6 - Scale 6), daha fazla kümelenmiş beyaz bölgeler görüyoruz. Bu beyaz bölgeler saptanan yüzleri göstermektedir. Yüzün son konumunu elde etmek için maksimum olmayan baskılama uygularız.

Fig. 3. Farklı ölçek katsayıları için yüz saptama skorları
Maksimum Olmayan Baskılama
Her yüksek skorlu bölgede büyük olasılıkla bir yüz vardır. Eğer yüzler ilkinin yakınlarında tahmin edilirse, bu sadece birinin dikkate alınması ve kalanların yanlış olduğu anlamına gelir. Maksimum olmayan baskılamayla, üst üste gelen sınırlayıcı kutulardan en yüksek olanı alır ve diğerlerini kaldırırız. Sonuç en uygun konumda tek bir sınırlayıcı kutu olacaktır.
Negatif Madenciliği (Negative Mining)
Son bölümde bir modelin test esnasında, bir nesnenin yüze çok benzer görünmesi için birçok sebep olduğundan, yüksek sayıda yanlış pozitifle karşılaşacağını tartıştık. Hiçbir eğitim kümesi yüze benzeyen ama yüz olmayan tüm nesneleri içermeyecektir. Bu problemi negatif madenciliği yöntemiyle azaltabiliriz. Negatif madenciliğinde, modelin yüz olarak saptadığı yüz olmayan parçalardan bir negatif verikümesi oluştururuz. Verikümesi, saptayıcı modelinin yüz içermediği bilinen girdiler üzerinde çalıştırılmasıyla oluşturulur. Daha sonra saptayıcı bu negatif verikümesi de kullanarak eğitilir. Bu süreci modelimizin yanlış pozitiflere karşı sağlamlığını artırmak için tekrar edebiliriz.
Anlamsal Bölütleme
Anlamsal bölütleme (semantic segmentation) girdi resmindeki her bir piksele bir kategori atanması görevidir.
CNN for Long Range Adaptive Robot Vision, Uzun Menzilli Uyarlanabilir Robot Görüsü için CNN
Bu projede amaç, robotun yolları ve engelleri ayırt edebilmesi için girdi görüntülerinden bölgeleri etiketlemekti. Fig. 4’te görüldüğü üzere, yeşil kısımlar robotun ilerleyebileceği alanlar, kırmızı kısımlarsa uzun bitkiler gibi engellerdir. Ağı bu görev için eğitmek için, resimden bir parça aldık ve ilerlenebilir olup olmadığını (yeşil ya da kırmızı) elle işaretledik. Sonrasında evrişimli ağa verilen parçanının rengini tahmin etmesini sorarak eğittik. Sistem yeterince eğitildiğinde tüm resme uygulandı ve resimdeki tüm kısımları yeşil veya kırmızı olarak etiketledi.

Fig 4. CNN for Long Range Adaptive Robot Vision, Uzun Menzilli Uyarlanabilir Robot Görüsü için CNN (DARPA LAGR program 2005-2008)
Tahmin edilecek 5 kategori vardı: 1) Parlak yeşil, 2) Yeşil, 3) Mor: Engel hattı, 4) Kırmızı: Engel 5) Parlak kırmızı: Kesinlikle bir engel
Stereo Etiketler (Fig. 4, Sütun 2) Görüntüler robottaki dört kamera tarafından yakalandı ve stereo görü için iki gruba ayrıldı. Her bir pikselin üç boyutlu uzaydaki pozisyonları, stereo kamera çiflerinin arasındaki uzaklık bilindiğinden, her iki kamerada da görüntülenen pikseller arasındaki görece uzaklık kullanılarak hesaplandı. Bu süreç beynimizin, gördüğümüz cisimler arası uzaklığı tahmin ederkenki süreçle aynıdır. Hesaplanan pozisyon bilgisini kullanarak, yere bir düzlem oturduldu ve pikseller bu düzleme yakınsa yeşil, yüksekse kırmızı olarak işaretlendi.
- Evrişimli Ağın Motivasyonu ve Sınırları: Stereo görü sadece 10 metreye kadar çalışır ve robotu ilerletmek uzun menzilli görü gerektirir. Bir evrişimli ağsa, doğru eğitildiğinde, çok daha uzaktaki cisimleri saptayabilir.

Fig 5. Uzaklıkla Normalize Edilmiş Görüntülerin Ölçekten Bağımsız Piramidi
- Modelin Girdileri: Önemli önişleme adımları uzaklıkla normalize edilmiş görüntülerin ölçekten bağımsız piramidinin oluşturulmasını kapsar (Fig 5). Bu işlem daha önce gördüğümüz çoklu ölçeklerde yüz saptama örneğinde yaptığımız işleme benzerdir.
Modelin Çıktıları (Fig. 4, Sütun 3)
Model görüntüde ufka kadar her bir piksel için bir etiket üretir. Bunlar çoklu-ölçekli evrişimli ağın sınıflandırıcı çıktılarıdır.
- Model Nasıl Uyarlanabilir Olur: Robotlar stereo etiketlere devamlı erişime sahiptir, bu onların tekrar eğitilerek yeni ortamlara uyum sağlayabilmelerini sağlar. Lütfen sadece son katmanın eğitileceğine dikkat edin. Önceki katmanlar laboratuvarda eğitilmiş ve sabit bırakılmıştır.
Sistem Performansı
Bir bariyerin arkasından GPS koordinatını almaya çalışırken robot bariyerin arkasını uzaktan “görüp” ondan kaçınacak şekilde yolunu planlamıştır. Bu CNN’in 50-100m uzaktaki nesneleri saptayabilmesi sayesindedir.
Sınırlama
2000’lerde hesaplama kaynakları sınırlıydı. Robot yaklaşık olarak saniyede bir kare işleyebiliyordu ve bu önünde bir insanın yürümesi halinde bunu bir tam saniye geçmeden anlayamayacağı anlamına geliyordu. Bu sınırlama için çözüm Az-Masraflı Görsel Odometri modeli olarak bilinir. Bu model sinir ağı tabanlı değildir, ~2.5m görüye sahiptir, ama hızlı tepki verir.
Görüntü Ayrıştırma (Scene Parsing) ve Etiketleme
Bu görevde model her bir piksel için bir nesne kategorisi (binalar, arabalar, gökyüzü vb.) üretir. Mimari yine çoklu-ölçeklidir (Fig. 6).
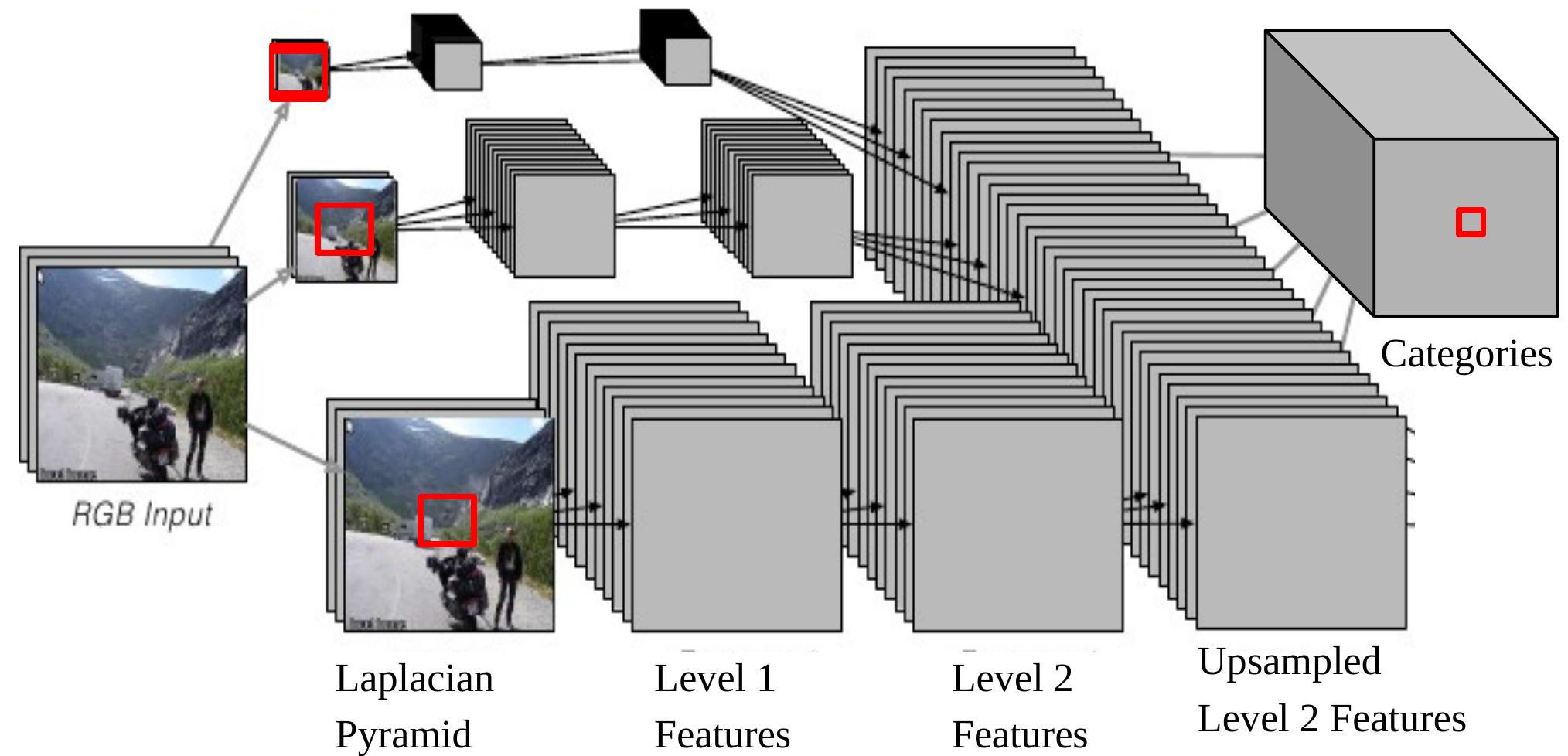
Fig. 6. Görüntü ayrıştırma için çoklu-ölçekli CNN
CNN çıktılarından birini girdisine yansıtırsak, original görüntünün Laplace piramidinin en altındaki $46\times46$’lık pencereye karşılık geleceğine dikkat edin. Bu $46\times46$’lık kadar bir piksel bağlamını merkezdeki pikselin kategorisine karar vermek için kullandığımız anlamına gelir.
Ancak, bazen bu bağlam boyutu daha büyük nesnelerin kategorilerini belirlemek için yeterli değildir.
Çoklu-ölçekli yaklaşım fazladan ölçeklendirilmiş görüntüleri girdi olarak kullanarak daha geniş görü sağlar. Adımlar aşağıdaki gibidir:
- Aynı resmi alın, ayrı ayrı 2 ve 4 kat küçültün.
- Ölçeklenmiş fazladan iki resmi aynı evrişimli ağa (aynı ağırlıklar, aynı kerneller) verin ve iki farklı 2. seviye özellik kümesi elde edin.
- Bu özellikleri orijinal görselin 2. seviye özellikleriyle aynı boyuta sahip olacak şekilde sık örnekleyin (upsampling).
- Üç (sık örneklenmiş) özellik kümesini üst üste koyarak bir sınıflandırıcıya verin.
Şimdi içeriğin, 1/4’üne küçültülmüş görselden gelen, en büyük efektif boyutu, $184\times 184\, (46\times 4=184)$.’tür.
Performans: Hiçbir son-işleme olmadan ve kareden-kareye çalıştırılarak, bu model standart donanımda bile çok hızlı çalışır. Eğitim verisinin küçük olmasına rağmen (2k~3k) rekor kıran sonuçlar elde edilmiştir.
📝 Shiqing Li, Chenqin Yang, Yakun Wang, Jimin Tan
2 Mar 2020