Decoding Language Models
🎙️ Mike Lewisビームサーチ
ビームサーチは、言語モデルを解読してテキストを生成するためのもう一つのデコーディング技術です。ビームサーチでは、各ステップで$k$ 個の最も確率の高い(最良の)部分翻訳(仮説)を追跡し続けます。各仮説のスコアは、その確率の対数と同じです。
ビームサーチは、最もスコアの高い仮説を選択します。
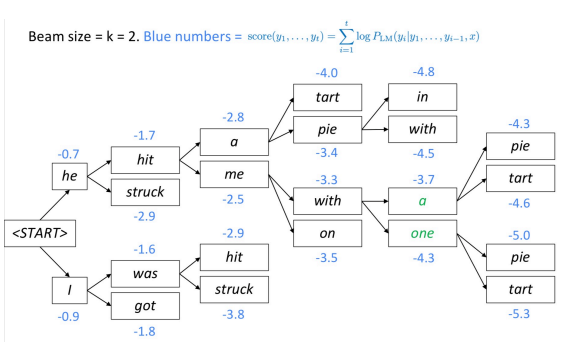
図1: ビームによるデコーディング
ビーム木はどのくらいの深さまで続いているのでしょうか?
ビーム木は文末トークンに到達するまで続きます。文末トークンを出力した時点で仮説は終了です。
なぜ(ニューラル機械翻訳では)ビームサイズが非常に大きいと空の翻訳(中身がない翻訳)になることが多いのでしょうか?
学習時には、計算量が多いため、アルゴリズムはビームを使用しないことが多いです。その代わりに、自己回帰的な確率の分解(以前の正しい出力が与えられ、$n+1$の最初の単語を予測する)を使用します。モデルは学習中にそれ自身のミスにさらされることがないので、ビームに「nonsense」が現れる可能性があります。
まとめ:すべての$k$個の仮説がエンドトークンを生成するまで、または最大解読限界Tに達するまでビーム探索を続けます。
サンプリング
最も可能性の高い文までは必要ないかもしれません。その代わりに、モデル分布からサンプリングすることができます。
しかし、モデル分布からサンプリングすることは、それ自体に問題があります。一度「悪い」選択がサンプリングされると、モデルは学習中には決して直面しなかった状態になり、「悪い」評価が続く可能性が高くなります。そのため、恐ろしい負のフィードバックループに陥ってしまう可能性があります。
Top-Kサンプリング
この手法は、上位$k$個 のベストな値だけを含むように、$k-1$個以下を切り捨て、残ったものを再び正規化することで確率分布を構成し、そこからサンプリングをするという、純粋なサンプリング手法です。
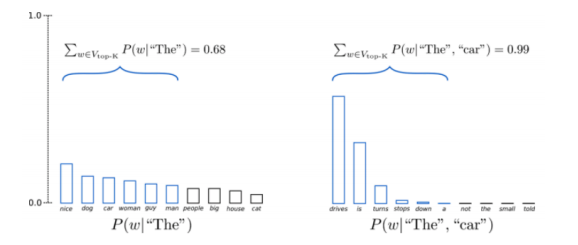
図2: Top-Kサンプリング
質問:Top-Kサンプリングはなぜそんなにうまくいくのですか?
この手法がうまくいくのは、悪いものをサンプリングするときに、分布の裾を切り落とすことで、良い言語がなす多様体から脱落しないようにするからです。
テキスト生成を評価する
言語モデルを評価するには、単にホールドアウトされたデータの対数尤度を評価する必要があります。しかし、テキストの評価は困難です。一般的には参照を伴う単語オーバーラップ評価指標(BLEU, ROUGEなど)が使われていますが、それぞれに問題があります。
Sequence-To-Sequence モデル
条件付き言語モデル
条件付き言語モデルは、テキストのランダムなサンプルを生成するのには役に立ちませんが、入力が与えられた下でテキストを生成するのには便利です。
例を挙げてみましょう。
- フランス語の文が与えられると、英語の翻訳を生成する
- 文書が与えられた場合、要約を生成する。
- 発話が与えられた場合、次の応答を生成する
- 質問が与えられたら、答えを生成する。
Sequence-To-Sequence モデル
一般的に、入力テキストはエンコードされます。この結果として得られる埋め込みは「思考ベクトル」として知られており、これをデコーダに渡して単語ごとにトークンを生成します。
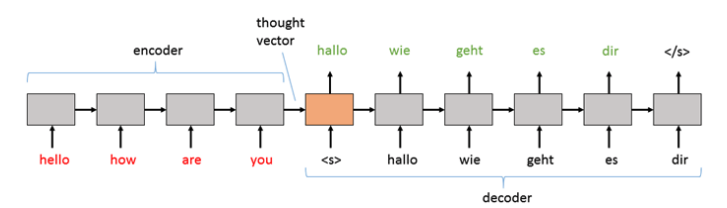
図3: 思考ベクトル
Transformerのsequence-to-sequenceモジュールには、2つのスタックがあります。
-
エンコーダースタック:Self-attentionはマスクされていないので、入力中のすべてのトークンが入力中の他のすべてのトークンを見ることができます。
-
デコーダースタック:自身のに対してattentionを使用する他に、完全な入力に対してもattentionを使用します。
図4: Sequence to Sequence Transformer
出力内のすべてのトークンは、出力内のそれ以前のトークンと直接接続し、入力内のすべての単語とも接続します。この接続により、このモデルは非常に表現力が高く、強力なものになります。これらの変換器は、以前のリカレントモデルや畳み込みモデルに比べて、翻訳スコアを向上させました。
Back-translation
逆翻訳
これらのモデルを学習する際には、通常、ラベル付けされた大量のテキストに頼ります。欧州議会の議事録から得たデータが良いソースとなります。このデータではテキストは手動で異なる言語に翻訳されており、モデルの入出力として使用することができます。
問題
- 欧州議会ではすべての言語が代表されているわけではないので、興味のあるすべての言語の翻訳ペアが得られるわけではありません。データが必ずしも得られない言語の学習用テキストをどうやって見つけるのか?という問題があります。
- Transformerのようなモデルは、より多くのデータがあればより良い結果が得られるので、どのようにして単言語のテキストを効率的に使うか、という問題が生じます。例えば入力と出力のペアがない場合にどうするか、などです?
ドイツ語を英語に翻訳するモデルを訓練したいとします。逆翻訳のアイデアは、最初に英語からドイツ語への逆モデルを訓練することです。
- 数は限られているものの、対になっているテキストを使用することで、同じ意味を表す2つの言語の文章を手に入れることができます。
- 英語からドイツ語へのモデルができたら、たくさんの単言語の単語を英語からドイツ語に翻訳します。
最後に、前のステップで「逆翻訳」されたドイツ語の単語を使って、ドイツ語から英語へのモデルを訓練します。ここで注意したいことがあります。
- 逆翻訳モデルがどれだけ優れているかは問題ではありません:ノイズの多いドイツ語の翻訳があっても、最終的にはきれいな英語に翻訳されるかもしれません。
- 英語とドイツ語のペア(すでに翻訳されている)のデータを超えて、英語を理解することを学ぶ必要があります。
反復逆翻訳
- 逆翻訳の手順を反復することで、より多くの対になるテキストデータを生成し、より良いパフォーマンスを得ることができます。やることは、単言語データを使って訓練を続けるだけです。
- 並列データが少ない場合に非常に役立ちます。
大規模多言語機械翻訳
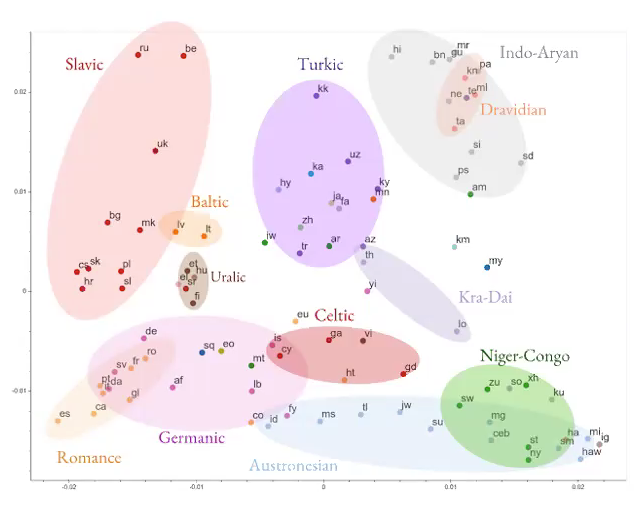
Fig. 5: 多言語機械翻訳
- ある言語から別の言語への翻訳を学習しようとするのではなく、複数の言語の翻訳を学習するためのニューラルネットを構築してみてください。
- そのようなモデルは、言語に依存しないなんらかの一般的な情報を学習します。

図6: 多言語 NN の結果
特に、利用可能なデータが多くない言語を翻訳するためのモデルを訓練したい場合には、素晴らしい結果が得られます(リソースの少ない言語)。
NLPのための教師なし学習
ラベルのない膨大な量のテキストがあり、教師ありデータがほとんどないとします。ラベルのついていないテキストを読むだけで、その言語についてどれだけのことがわかるのでしょうか?
word2vec
直感的説明:テキスト中に単語が近くに出てくると関連性がありそうです。ですので、この情報を使ってラベルのついていない英文を見ただけで意味がわかるようになることを期待します。
- 目標は、単語のベクトル空間表現を学習することです。
事前学習タスク:いくつかの単語をマスクして、隣り合う単語を使って空白を埋めます。

図7: word2vec マスキングの可視化
例えば、「角がある」「銀髪」は、他の何かの動物よりも「ユニコーン」という文脈で出てくる可能性が高いという考え方です。
単語に、線形射影を適用します。
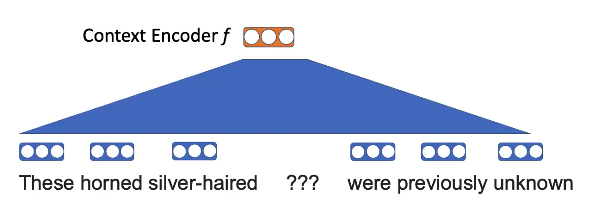
図8: word2vec 埋め込み
知りたいもの
\[p(\texttt{unicorn} \mid \texttt{These silver-haired ??? were previously unknown})\] \[p(x_n \mid x_{-n}) = \text{softmax}(\text{E}f(x_{-n})))\]単語埋め込みはなんらかの構造を持っています。
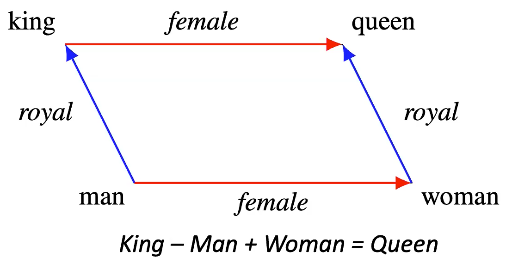
Fig. 9: 埋め込み構造の例
- 学習後に、「王様」の埋め込みに「女性」の埋め込みを加えれば、「女王様」の埋め込みに非常に近い埋め込みが得られるという考えかたです。
- これはベクトル間の意味のある違いを示しています。
質問:単語の表現は文脈に依存しているのですか、独立しているのですか?
独立していて、他の単語とどのように関係しているかはわかりません。
質問:このモデルが苦戦するであろう状況の例は何でしょうか?
言葉の解釈は文脈に強く依存します。したがって、曖昧な単語や複数の意味を持つかもしれない単語の例では、埋め込みベクトルがその単語を正しく理解するのに必要な文脈を捉えられないので、モデルは苦戦するでしょう。
GPT
文脈を追加するために、条件付き言語モデルを訓練することができます。そして、各時間ステップで単語を予測するこの言語モデルが与えられ、モデルの各出力を他の特徴量に置き換えます。
- 事前学習:次の単語を予測する
-
fine-tuning:特定のタスクに合わせて学習済みモデルを調整します。
例:
- 名詞か形容詞かを予測する
- いくつかのアマゾンのレビュー、レビューの感情スコアを予測する
このアプローチは、モデルを再利用できる点で優れています。1つの大きなモデルを事前に学習しておき、他のタスクに合わせて微調整することができます。
ELMo
GPTは左方向の文脈しか考慮しないので、モデルは将来の単語に依存することができません。これはモデルができることをかなり制限します。
ここでは、2つの言語モデルを学習します。
- テキストの左から右に1つのモデルを用意します。
- テキストの右から左に1つのモデルを用意します。
- 単語表現を得るために、2つのモデルの出力を連結します。これで、右方向と左方向の文脈の両方に条件をつけることができるようになりました。
これはまだ 「浅い」組み合わせでなので、左右の文脈の間にもう少し複雑な相互作用が欲しいところです。
BERT
BERT は、文書穴埋めタスクもあるという意味で word2vec に似ています。しかし、word2vecでは線形射影を行っていましたが、BERTでは、より多くの文脈を見ることができる大規模なtransformerがあります。訓練のために、トークンの15%をマスクし、空白を予測しようとします。
BERT(RoBERTa)をスケールアップすることができます。
- BERTの事前学習のための目的関数の単純化
- バッチサイズのスケールアップ
- 大量のGPUでの学習
- さらに多くのテキストで学習
BERTのパフォーマンスのさらに大きな改善:質問応答タスクのパフォーマンスは、今では人間を超えています。
NLPのための事前学習
NLPのために研究されてきた様々な自己教師あり事前学習アプローチを簡単に見てみましょう。
-
XLNet:
XLNetは、すべてのマスクされたトークンを条件付き独立に予測するのではなく、ランダムな順序で自己回帰的に予測します。
-
SpanBERT:
トークンの代わりにマスクスパンを用います。
-
ELECTRA:
単語をマスキングするのではなく、トークンを類似したもので置換します。 そして、そのトークンが置換されたかどうかを予測する二値分類問題を解きます。
-
ALBERT:
A Lite Bertの略です。BERTを修正し、レイヤー間で重みを共有することで軽量化する。これにより、モデルのパラメータとそれに伴う計算が削減されます。興味深いことに、これらの軽量化にも関わらずALBERTの精度はそこまで低下することはありませんでした。
-
XLM:
多言語BERT:英語のテキストを与える代わりに、複数の言語からのテキストを与えます。予想通り、言語間のつながりをより良く学習しました。
上記の様々なモデルから得られた主なポイントは以下の通りです。
-
多くの異なる事前学習の目的関数が効果的に働く
-
単語間の深い双方向の相互作用をモデル化することが重要
-
まだ明確な限界がない事前学習のスケールアップからの大きな利益
上で議論したモデルのほとんどは、テキストの分類問題を解決するために設計されています。しかし、seq2seqモデルのように逐次的に出力を生成するテキスト生成問題を解決するためには、事前学習に少し異なるアプローチが必要です。
条件付き生成のための事前学習:BARTとT5
BART:テキストのノイズ除去による seq2seq モデルの事前学習
BARTでは、事前学習のために、文を受け取り、ランダムにマスキングトークンによってそれを破損させます。BERTの目的関数のようにマスキングトークンを予測するのではなく、破損した文全体を与え、正しい文全体を予測させます。
この seq2seq 事前学習アプローチは、破損のさせ方の設計に柔軟性を与えてくれます。文章をシャッフルしたり、フレーズを削除したり、新しいフレーズを導入したりすることができます。
BARTはSQUADタスクとGLUEタスクでRoBERTaに匹敵する性能を示しました。しかし、要約、対話、抽象的なQAデータセット上では新しいSOTAを叩き出しました。これらの結果は、BARTがBERT/RoBERTaよりもテキスト生成タスクで優れていることを示しており、BARTを用いる理由となります。
NLPにおけるいくつかの未解決問題
- 世界の知識をどのように統合すべきか?
- 長い文書をどのようにモデル化するか? (BERT ベースのモデルは通常 512 トークンを使用します)
- マルチタスク学習の最善の方法は何か?
- 少ないデータでfine-tuningできるのか?
- これらのモデルは本当に言語を理解しているのか?
まとめ
- 多くのデータでモデルを訓練することは、言語構造を明示的にモデル化することに勝ります。
バイアスバリアンスの観点から見ると、トランスフォーマーはバイアスの低い(非常に表現力の高い)モデルです。これらのモデルに多くのテキストを与えることは、明示的に言語構造をモデル化するよりも優れています(高バイアス)。アーキテクチャはボトルネックを介してシーケンスを圧縮する必要があります。
-
モデルはラベルの付いていないテキストの単語を予測することで、言語について多くのことを学ぶことができます。これは、教師なし学習の優れた目的関数であることがわかります。特定のタスクのためのfine-tuningも簡単です。
-
双方向のコンテキストが重要です。
授業後の質問からの追加の気づき
「言語を理解する」ことを数値化する方法にはどのようなものがあるのでしょうか?これらのモデルが本当に言語を理解していることをどのようにして知ることができるのでしょうか?
「The trophy did not fit into the suitcase because it was too big」という文章を考えます。 この文では、「it」の参照を解決するのは難しいです。この文の「it」の参照を解決するのは、機械にとっては難しいことです。人間はこの作業が得意です。このような難しい例で構成されたデータセットがあり、人間はそのデータセットで95%のパフォーマンスを達成しました。Transformerがもたらした革命の前は、コンピュータプログラムは60%程度の性能しか達成できませんでした。現代のtransformerのモデルは、そのデータセットで90%以上の性能を達成することができます。このことは、これらのモデルが単にデータを記憶/活用するのではなく、データの統計的パターンを通して概念や対象を学習していることを示唆しています。
さらに、BERTとRoBERTaは、SQUADとGlueで超人的な性能を達成しています。BARTによって生成された文書要約は、人間には非常にリアルに見えます(BLEUスコアが高い)。これらの事実は、モデルが何らかの形で言語を理解している証拠です。
Grounded Language
興味深いことに、講師のMike Lewis氏(FAIRの研究員)は「Grounded Language」という概念を研究しています。その研究分野は、雑談や交渉ができる会話エージェントを作ることを目的としています。雑談やネゴシエーションは、テキストの分類や要約に比べて、目的が不明確な抽象的な作業です。
モデルがすでに世界の知識を持っているかどうかを評価することはできるのでしょうか?
世界の知識は抽象的な概念です。我々は、非常に基本的なレベルで、我々が興味を持っている概念について簡単な質問をすることによって、モデルが世界の知識を持っているかどうかをテストすることができます。 BERT、RoBERTa、T5のようなモデルは、何十億ものパラメータを持っています。これらのモデルはウィキペディアのような膨大な情報テキストのコーパスで訓練されていることを考えると、パラメータを使って事実を記憶しており、我々の質問に答えることができるでしょう。さらに、あるタスクでモデルをfine-tuningする前と後に同じ知識テストを行うことも考えられます。これは、モデルがどれだけの情報を「忘れてしまった」かの感覚を与えてくれるでしょう。
📝 Trevor Mitchell, Andrii Dobroshynskyi, Shreyas Chandrakaladharan, Ben Wolfson
Shiro Takagi
20 Apr 2020