Deep Learning for NLP
🎙️ Mike Lewis概要
- 自然言語モデルの、近年の驚くべき進歩
- 一部の言語では、人間の翻訳者よりも機械翻訳が好まれるようになっています。
- 多くの質問応答タスクのデータセットで、超人的なパフォーマンスを発揮しています。
- 言語モデルは人間が書いたような自然な段落を生成することができます。(例:Radford et al.)
- タスクごとに必要とされる専門技術は最小限で、かなり汎用的なモデルでこれらのことを達成することができます。
言語モデル
- 言語モデルは、テキストに確率を割り当てます: $p(x_0, \cdots, x_n)$
- 候補となりうる文が多いので、分類器の訓練はできません
- 最もポピュラーな方法は、連鎖律を用いて分布を分解する方法です。
ニューラル言語モデル
基本的には、ニューラルネットワークにテキストを入力すると、ニューラルネットワークはすべてのコンテキストをベクトルに写像します。このベクトルは次の単語を表現し、これによって大きな単語埋め込み行列を得ます。単語埋め込み行列には、モデルが出力する可能性のあるすべての単語のベクトルが含まれています。そして、文脈ベクトルと各単語ベクトルのドット積によって類似度を計算します。次の単語を予測する尤度を得て、最尤推定によってこのモデルを訓練します。ここで重要なのは、単語を直接扱うのではなく、部分語と呼ばれるものや文字を扱うということです。
\[p(x_0 \mid x_{0, \cdots, n-1}) = \text{softmax}(E f(x_{0, \cdots, n-1}))\]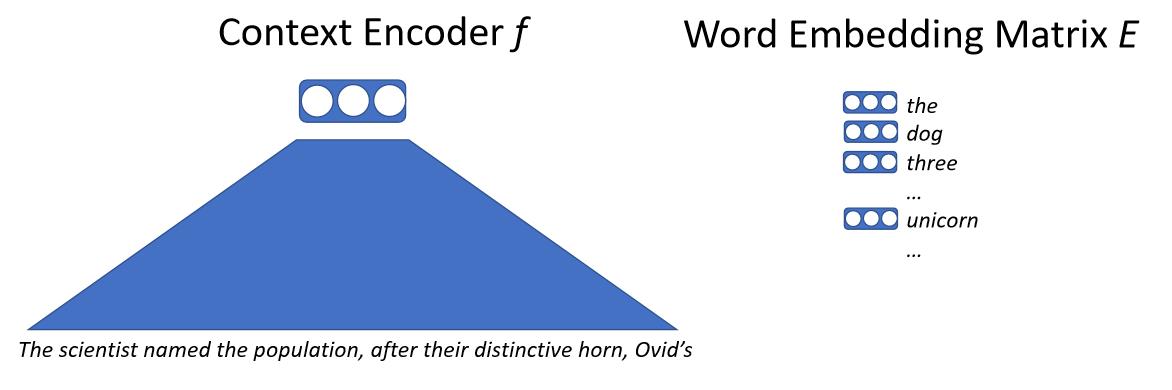
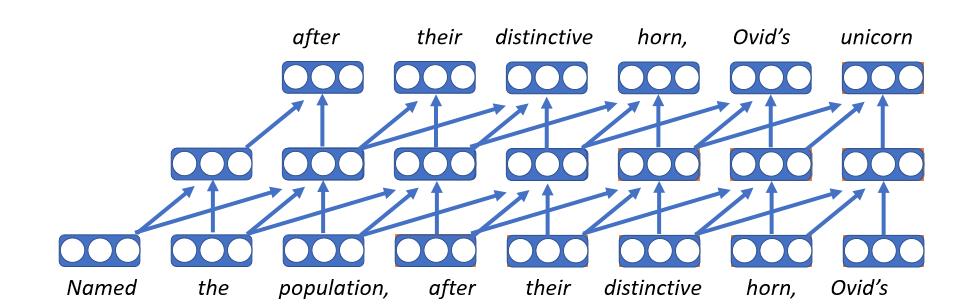
畳み込み言語モデル
- 最初のニューラル言語モデルです。
- 各単語をベクトルとして埋め込みます。これは埋め込み行列のルックアップテーブルです。したがって、どのような文脈で出てきても同じベクトルを得ることになります。
- 各タイムステップで同じフィードフォワードネットワークを適用します。
- 残念ながら、固定長の系列しか扱えないということは、制限された文脈でしか条件付けられないことを意味します。
- これらのモデルは、非常に高速であるという利点があります。
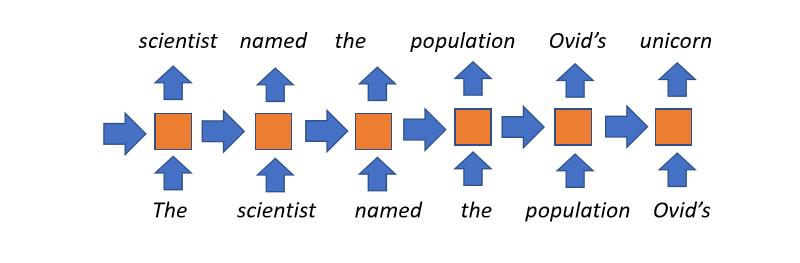
再帰的言語モデル
- 数年前までは最もポピュラーなアプローチでした。
- 概念的には簡単です。各時間ステップで、ある状態を持ちます。これは、現在の単語が読まれ、後の状態で使用されているものと組み合わされます(昔の時間ステップからの入力を受け取りますが、これはこれまで読んだ内容を表現しています)。そして、必要な数だけこのプロセスを繰り返します。
- 制限のない文脈を用いる:原理的には、本のタイトルは、本の最後の単語の隠れ状態に影響を与えます。
- 欠点:
- 読み取った文書の全履歴は、各タイムステップで固定サイズのベクトルに圧縮されていますが、これはこのモデルのボトルネックとなっています。
- 長いコンテキストでは、勾配消失が生じる傾向があります。
- 時間ステップ間で並列化できないので、訓練が遅くなります。
Transformer言語モデル
- NLPで使用されている最新のモデル
- 革命的なペナルティ
- 3つの主要段階
- 入力段階
- $n$ 個の異なるパラメータを持つtransformerブロック(エンコーディング層)の繰り返し
- 出力段階
- Transformerの原論文で用いられた、transformerモジュール(エンコード層)を6個積んだ例
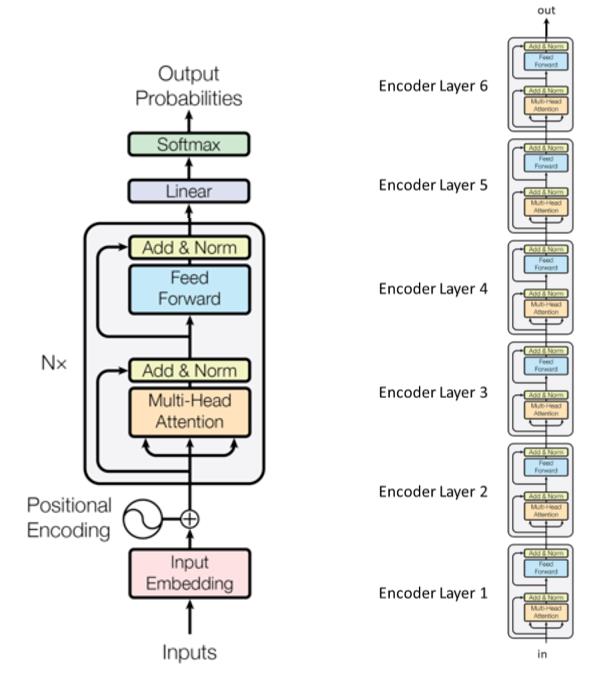
サブレイヤーは 「Add&Norm」と書かれたボックスで接続されています。「Add」の部分はresidual connectionを意味し、勾配消失を防ぐのに役立ちます。ここでの「norm」はlayer normalizationを表しています。
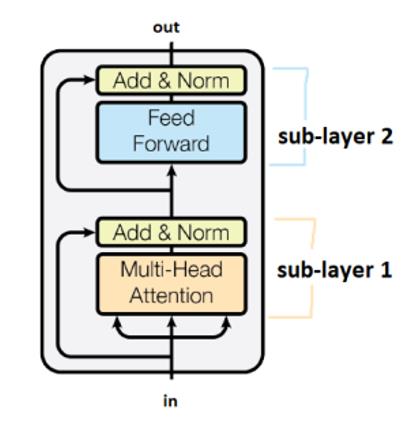
Transformerは、時間ステップ間で重みを共有することに注意してください。
Multi-headed attention
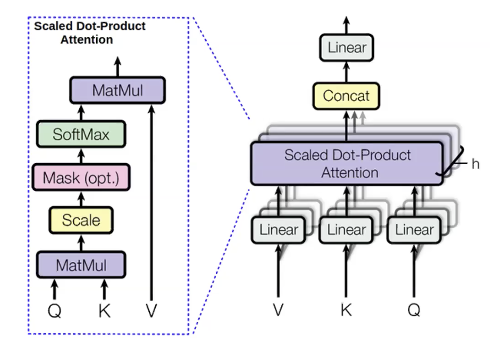
我々が予測しようとしている単語については、クエリ(q) と呼ばれる値を計算します。予測に用いる、予測する単語の前にある全ての単語については、キー(k) と呼ばれる値を計算します。クエリは、「予測する単語の前の形容詞」といったような文脈を伝えるものです。キーは、「現在の単語が形容詞であるかどうか」などの情報を含むラベルのようなものです。qが計算されると、前の単語の分布($p_i$)を導出することができます。
\[p_i = \text{softmax}(q,k_i)\]次に、前の単語について バリュー(v) と呼ばれる量も計算します。バリューは単語の内容を表します。
バリューが得られたら,attention分布を最大化することで隠れ状態を計算します。
\[h_i = \sum_{i}{p_i v_i}\]同じものを異なるクエリ、バリュー、キーで複数回並列に計算します。これは、異なるものを使って次の単語を予測したいからです。例えば、前の3つの単語「These」「horned」「silver-white」を使って「unicorns」という単語を予測する場合を考えます。私たちは、「horned」と「silver-white」によって、それがユニコーンであることがわかります。しかし、「These」によって複数のユニコーン、つまり、「unicorns」であることがわかります。したがって、次の単語が何であるかを知るために、この3つの単語をすべて使いたいと考えるでしょう。Multi-headed attentionは、それぞれの単語に、その単語の以前の複数の単語を見させる方法です。
Multi-headed attentionの大きな利点は、かなりの並列処理が可能であることです。RNNとは異なり、Multi-headed attentionでは、Multi-headed attentionモジュールのすべてのヘッドとすべての時間ステップを一度に計算します。すべての時間ステップを一度に計算することの問題点は、我々が前の単語だけを条件としたいのに対し、未来の単語も見てしまうことです。これを解決する一つの方法として、self-attentionマスキングと呼ばれるものがあります。このマスクは、下の三角形にゼロを、上の三角形に負の無限大を持つ上三角行列です。注意モジュールの出力にこのマスクを追加する効果として、左のすべての単語は右の単語よりもはるかに高い注意スコアを持っているので、実際にはモデルは前の単語だけに焦点を当てることができます。マスクの適用は言語モデルを数学的に正しくするために重要ですが、テキストエンコーダーでは双方向のコンテキストが役立ちます。
トランスフォーマー言語モデルを機能させるための一つの細かいテクニックは、入力にpositional embeddingを追加することです。順序のようないくつかの特徴は言語を解釈する上で重要です。ここで使用されている技術は、異なる時間ステップで別々の埋め込みを学習し、それらを入力に追加することです。これが順番の情報を与えます。
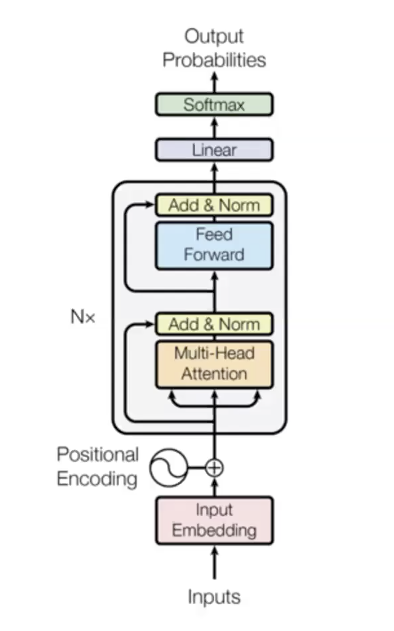
このモデルが優れている理由:
- このモデルは、各単語のペア同士を直接的につなげます。各単語は前の単語の隠れ状態に直接アクセスでき、勾配消失を緩和します。それは非常に難しい関数を非常に簡単に学習します。
- すべての時間ステップは並列に計算されます。
- self-attentionの計算量は二乗オーダーです(すべての時間ステップは他のすべての時間ステップに注意を向けることができる)ので、最大シーケンスの長さが制限されます。
いくつかのコツ (特に multi-head attention と positional encodingについて) と デコーディング言語モデル
コツ1: Layer normalizationを多用した訓練の安定化(これは本当に役に立ちます)
- Transformerにとってはとても大事なことです
コツ2:Warm-upとルート分の1の訓練スケジューリング
- 学習率スケジューリングを利用する:transformerをうまく動作させるためには、学習率をゼロから数千ステップまで線形に減衰させる必要があります。
コツ3:慎重な初期化
- 機械翻訳のようなタスクに本当に役立ちます。
コツ4:ラベルの平滑化
- これも機械翻訳のようなタスクに本当に役立ちます。
上述したいくつかの方法で行った結果を以下に示します。これらのテストでは、右の ppl と呼ばれている指標は perplexity です(ppl が低いほど良い)。
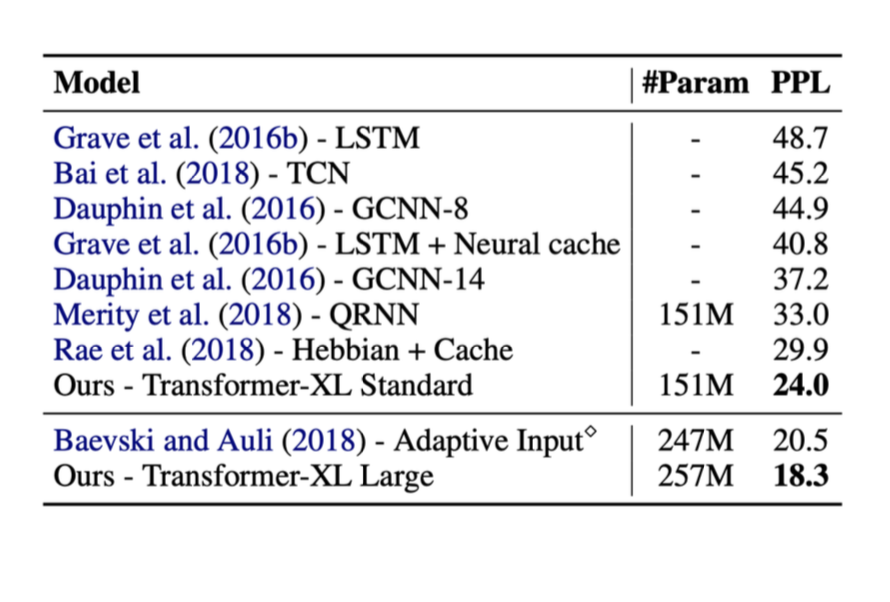
Transformerが導入されると、性能が大幅に向上していることがわかります。
Transformer言語モデルについてのいくつかの重要な事実
<!– - Minimal inductive bias
- All words directly connected, which will mitigate vanishing gradients.
- All time-steps computed in parallel. –>
- 帰納的バイアスが最小限です。
- すべての単語が直接接続されているため、勾配消失が緩和されます。
- すべての時間ステップは並列に計算されます。
Self-attentionの計算量は二乗オーダーである(すべての時間ステップは他のすべての時間ステップに注意を払うことができる)ため、最大シーケンス長が制限されます。
- Self-attentionの計算量は二乗オーダーなので、そのコストは実際には線形に増加してしまい、問題を引き起こす可能性があります。

Transformersはとてもよくスケールする
- 必要とするより遥に膨大な無制限の訓練データを使います。
- GPT 2は2019年に20億個のパラメータを使用しました。
- 2020年の最近のモデルでは17Bまでのパラメータを使用しました。
デコーディング言語モデル
テキストに対する確率分布を学習することができます。本質的には指数関数的に多くの可能性のある出力を得ることができるので、最大値を計算することはできません。最初の単語にどのような選択をしても、他のすべての決定に影響を与える可能性があります。 これを受けて、以下のような貪欲デコーディングが導入されました。
貪欲なデコーディングはうまくいかない
私たちは、各時間ステップで最も可能性の高い単語を選びます。しかし、この方法で最も可能性の高い単語の順番がわかるという保証はありません。なぜなら,もしある点でそのようなステップを選択しなければならないときに,以前のセッションをやり直すことができないからです。
網羅的な検索はできない
これは、すべての可能なシーケンスを計算する必要があり、$O(V^T)$の計算量がかかるため、あまりにも計算コストが高くなります。
質問と解答
-
Single-headのattentionモデルと比べたときの、multi-headのattentionモデルの利点は何ですか?
- 次の単語を予測するためには、複数の別々のものを観察する必要があります。Multi-headのattentionモデルは、次の単語を予測するために必要な文脈を理解するために、複数の前の単語に注意を向けることができます。
-
TransformerはCNNやRNNのinformational bottlenecksをどのように解決するのですか?
- Attentionモデルはすべての単語間の直接的な接続を可能にし、各単語は前のすべての単語に条件付けされるので、このボトルネックを効果的に解決することができます。
-
TransformerはGPUによる並列化を利用する点でRNNとどのように違うのでしょうか?
- Transformerのmulti-head attentionモジュールは高度な並列化が可能であるのに対し、RNNはそうではないため、GPU技術を利用することができません。実際、Transformerは単一の順伝播ですべての時間ステップを一度に計算します。
📝 Jiayu Qiu, Yuhong Zhu, Lyuang Fu, Ian Leefmans
Shiro Takagi
20 Apr 2020