自己教師あり学習 - Pretext Tasks
🎙️ Ishan Misra教師あり学習のサクセスストーリー: 事前学習
過去10年間、様々なコンピュータビジョンの問題の中でも大きな成功の秘訣の一つは、ImageNet分類の教師あり学習による視覚的表現の学習であり、また、これらの学習で得られた表現や学習されたモデルの重みを、ラベル付けされた大量のデータが利用できない他のコンピュータビジョンのタスクの初期値として利用することです。
しかし、ImageNetのような大規模なデータセットのアノテーションには、膨大な時間と費用がかかります。例えば、1400万枚の画像を用いたImageNetのラベル付けには、およそ22年の歳月がかかっています。
このため、研究コミュニティは、ソーシャルメディア画像のハッシュタグ、GPS位置情報、データサンプルからラベルを作る自己教師ありのアプローチなど、ラベル付けの代替的な方法を探し始めました。
しかし、ラベリングの代替手段を探す前に生じる重要な疑問があります。
結局どれだけのラベル付きデータが手に入るのでしょうか?
- オブジェクトレベルのカテゴリとバウンディングボックスのアノテーションを持つすべての画像を検索すると、約100万枚の画像があります。
- ここで、バウンディングボックス座標の制約を緩和すると、利用可能な画像の数は約1400万枚に跳ね上がります。
- しかし、インターネット上にある全ての画像を対象にすると、データ量は5桁も増えてしまいます。
- また、画像以外のデータもありますが、これを理解するためには他の感覚入力を必要とします。
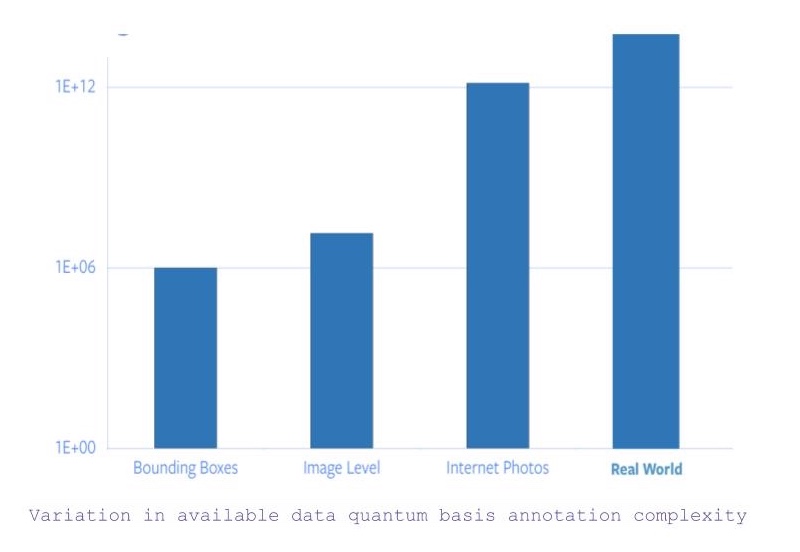
図1: アノテーションの利用可能なデータ量子基盤の複雑さのばらつき
したがって、ImageNetのアノテーションだけで22年分の時間がかかったという事実から、インターネット上のすべての写真やそれ以上の写真に対しても同じようにラベリングをすることは不可能です。
珍しい概念の存在の問題 (ロングテール問題(分布の裾が広がっているという問題))
一般的に、インターネット上の画像のラベルの分布を示すプロットは、ロングテール(分布の裾が広がっていること)のように見えます。つまり、ほとんどの画像が非常に少ないラベルに対応している一方で、対応する画像があまり存在しないラベルが多数存在しています。したがって、分布の裾のほうのカテゴリーについてのラベル付きサンプルを取得するには、膨大な量のデータをラベル付けする必要があります。
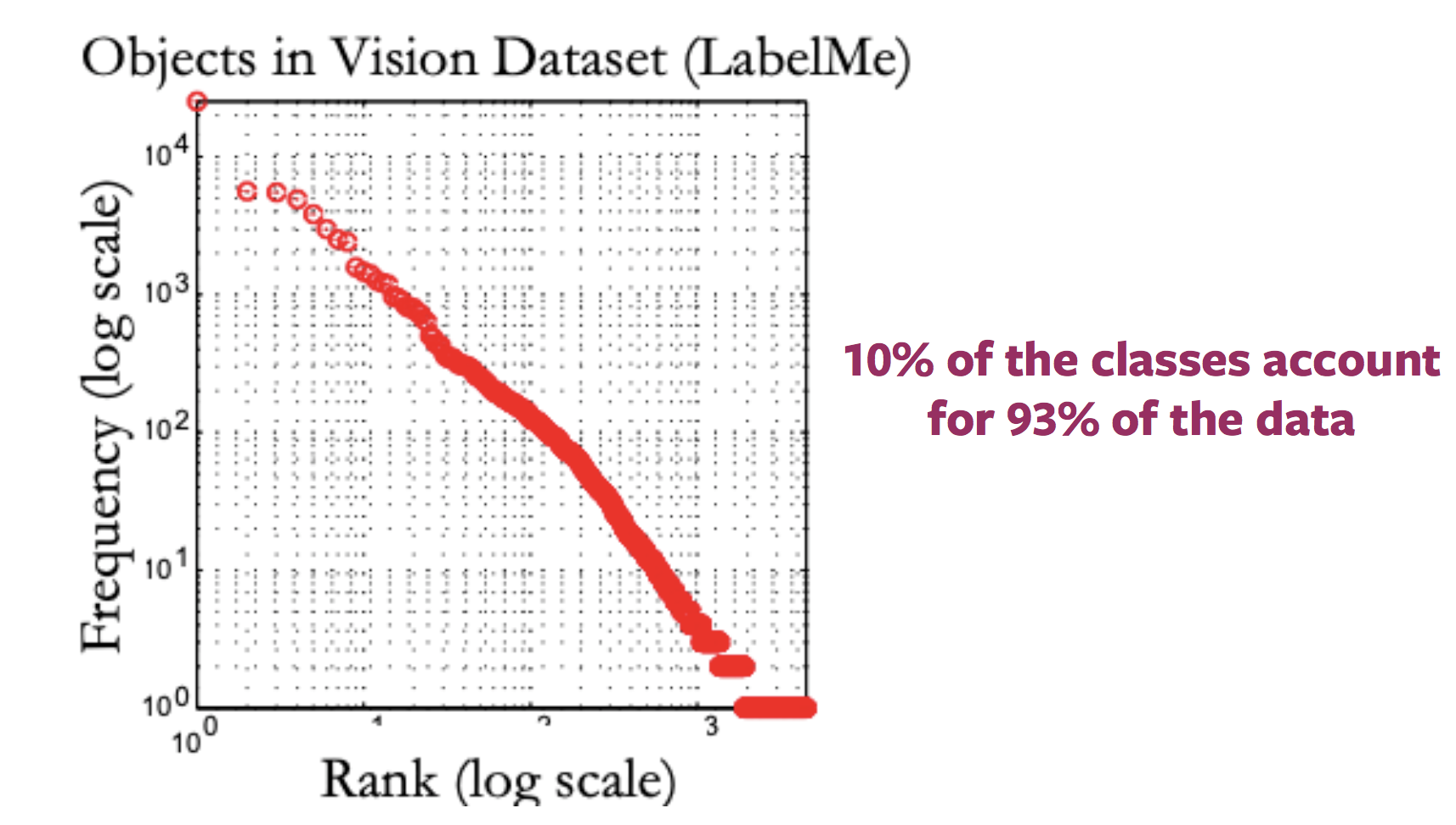
図2: 利用可能なラベル付き画像の分布のばらつき
異なるドメインという問題
このような、ImageNetで事前学習をして下流のタスク対してfine-tuningする方法は、下流タスクの画像が医用画像のように全く異なるドメインの画像である場合には、さらにうまくいかなくなってしまいます。また、ImageNetに相当する量のデータセットを異なるドメインの事前学習のために得ることは不可能です。
自己教師あり学習とは?
自己教師あり学習を定義する2つの方法
- 教師あり学習に基づく定義:例えば、ラベルが人間の入力なしに半自動的に手に入る状況でネットワークを教師あり学習すること。
- 予測問題:データの一部が隠れていて、残りが観測可能であるような状況。したがって、目的は、隠されたデータを予測するか、隠されたデータの特性を予測すること。
自己教師あり学習は教師あり学習と教師なし学習とどのような点で異なるのか?
- 教師あり学習タスクには、あらかじめ定義された(一般的には人間が提供する)ラベルがあります。
- 教師なし学習では、教師信号、ラベル、正しい出力は無く、データサンプルのみがあります。
- 自己教師あり学習は、与えられたデータサンプルと共起するモダリティ、またはデータサンプル自体の共起する部分からラベルを導き出します。
自然言語処理における自己教師あり学習
Word2Vec
- このタスク(Word2Vec)では、入力文が与えられると、pretext task を構築する目的でその文から意図的に省略された単語を予測しなければなりません。
- したがって、ラベルの集合は語彙の中のすべての可能な単語になり、正しいラベルは文から省略された単語になります。
- このようにして、通常の勾配に基づく方法を用いて、ネットワークに単語レベルの表現を学習させることができます。
なぜ自己教師あり学習なのか?
- 自己教師あり学習では、データの異なる部分がどのように相互作用するかを観測するだけで、データの表現を学習することができます。
- これにより、膨大な量のラベル付きデータが必要なくなります。
- さらに、一つのデータサンプルに関連した複数のモダリティを活用することができます。
コンピュータービジョンにおける自己教師あり学習
一般的に、自己教師あり学習を採用したコンピュータビジョンの工程では、pretext taskと実際の(下流の)タスクの2つのタスクを実行します。
- 実際の(下流の)タスクは、分類タスクや検出タスクのように、アノテーションされたデータサンプルが不十分なものであれば何でも構いません。
- Pretext taskは、視覚的表現を学習するために解いた自己教師あり学習タスクであり、学習した表現やその過程で得られたモデルの重みを下流のタスクに利用することを目的としています。
Pretext task を開発する
- コンピュータビジョンの問題のためのpretext taskは、画像、動画、または動画と音声のどちらも、のいずれかを使用して開発することができます。
- それぞれのpretext taskには、観測可能なデータと不可能なデータがあり、観測されていないデータそのものもしくはその性質のいずれかを予測することがタスクとなります。
Pretext taskの例: 画像のパッチの相対的な位置を予測する
- 入力: アンカー画像パッチ(相対位置の起点となる画像パッチ)とクエリ画像パッチ(相対位置を知りたい画像パッチ)からなる2つの画像パッチ。
- 2つの画像パッチが与えられると、ネットワークはアンカー画像パッチに対するクエリ画像パッチの相対的な位置を予測しなければいけません。
- したがって、この問題は8-way分類問題としてモデル化することができます。
- また、アンカーに対するクエリー画像の相対位置を与えることで、この問題のラベルを自動的に生成することができます。
注:~way分類問題とは,~値分類だと思って差し支えないと思います。CV、few-shot学習の文脈とかでこのような使われ方を見かけます。クエリ画像などの用語も同様です。(by translator)
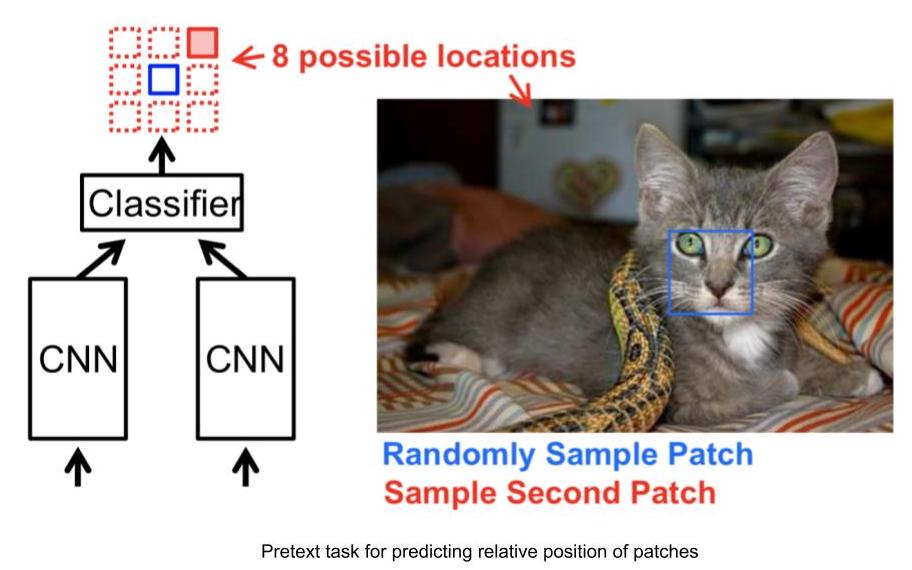
図3: 相対位置予測タスク
相対位置予測タスクで学習した視覚表現
学習した視覚表現の有効性を評価するために、ネットワークから提供された画像パッチベースの特徴表現に対する最近傍を調べることができます。与えられた画像パッチの最近傍を計算するために、
- データセット内のすべての画像について、CNNの出力を用いた特徴量(CNN特徴量)を計算します。これは、検索されるサンプルプールとして機能します。
- 要求された画像パッチのCNN特徴量を計算します。
- 利用可能な画像の特徴ベクトルのプールから、要求された画像の特徴ベクトルの最近傍を識別する。
相対位置予測タスクは、物体の色などの要素に対する不変性を保ちながら、入力画像パッチと非常に類似した画像パッチを見つけ出します。このようにして、相対位置予測タスクは、視覚的に類似した外観を持つ画像パッチの表現が表現空間においてもより近くなるような視覚表現を学習することができます。

図4: 相対位置: 最近傍
画像の回転の予測
- 回転の予測は、単純で簡単な構成で最小限のサンプリングで済む最もよく使われるpretext taskの一つです。
- 画像に0, 90, 180, 270度の回転を適用し、画像にどのような回転が適用されたかを予測するためにこれらの回転した画像をネットワークに入力します。ネットワークは単に回転を予測するために4つの回転方向の分類を行います。
- 回転を予測すること自体に意味はありません。私たちは、下流のタスクで使用するための特徴や表現を学習するための代わりとして、このpretext taskを使用しているだけです。
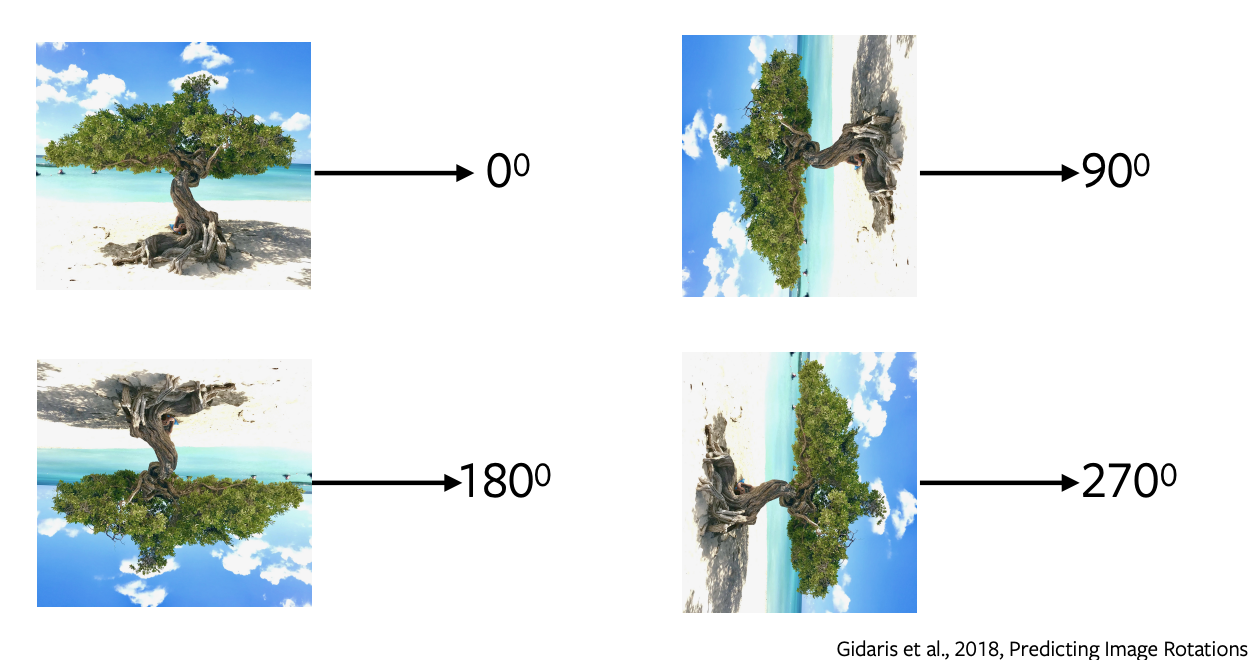
図5: 画像の回転
なぜ回転が役に立つのか、なぜうまくいくのか?
これは経験的にうまくいくことが示めされています。その背後にある直感は、回転を予測するためには、モデルが画像の大まかな境界や表現を理解する必要があるということです。例えば、水から空を分離したり、水から砂を分離したり、木が上向きに成長することを理解する必要があります。
色付け

図6: 色付け
このpretext taskでは、グレースケール画像の色を予測します。これはどのような画像に対しても定式化することができます。画像の色を除去して、その色を予測するためにこのグレースケール画像をネットワークに与えるだけです。このタスクは、例えば古いグレースケールのフィルムの色付けに使えるように、いくつかの点で有用です[//]: <> (このpretext taskを適用することができます)。このタスクの背後にある直感は、このタスクを解くためには、木が緑であること、空が青であることなどの意味のある情報を、ネットワークが理解しなければならないということです。
カラーマッピングは決定論的ではなく、いくつかの真の解が存在することに注意することが重要です。つまり、ある物体の色にいくつかの可能性がある場合、ネットワークはそれをすべての可能な解の平均値である灰色に着色します。最近では、多様な色付けのために変分オートエンコーダーと潜在変数を使用したものがあります。
空白を埋める
画像の一部を隠して、残りの周囲の部分から隠された部分を予測します。これがうまくいくのは、車は道路を走っている、建物は窓とドアで構成されているなど、データの暗黙の構造をネットワークが学習するためです。
動画のPretext Task
動画は連続したフレームで構成されており、フレームの順番を予測したり、空白を埋めたり、オブジェクトを追跡したりするような、いくつかのpretext taskに活用することができます。
シャッフルして学習する(Shuffle & Learn)

図7: 補完
いくつかの動画フレームが与えられたとして、その中の3つのフレームを抽出して、それらが正しい順序で抽出されていれば正のラベルを付け、そうでなくてシャッフルされていれば負のラベルを付けます。これは、フレームが正しい順番にあるかどうかを予測する二値分類問題になります。そこで、開始点と終了点が与えられている場合、中間点が有効な補間であるかどうかを確かめます。
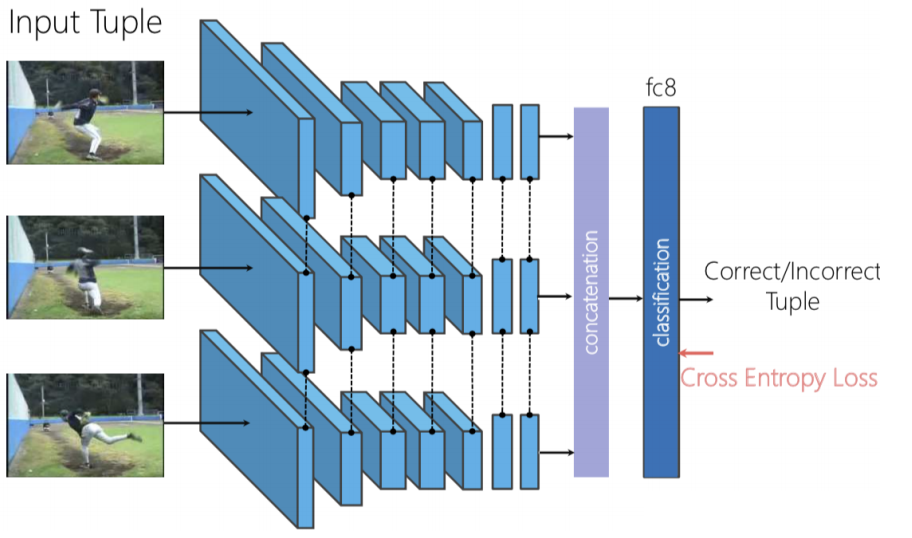
図8: シャッフルして学習(Shuffle & Learn)、の概念図
3つのフレームを独立に順伝播させ、生成された特徴量を連結して2値分類を行い、フレームがシャッフルされているかどうかを予測するtriplet Siameseネットワークを使用することができます。

図9: 最近傍表現
ここでも、最近傍アルゴリズムを使用して、ネットワークが何を学習しているかを可視化することができます。上の図9では、まずクエリフレームを順伝播して特徴表現を取得し、その表現空間内の最近傍を見ています。比較してみると、ImageNetの学習、Shuffle & Learn、ランダムで得られた近傍の間には大きな違いがあることがわかります。
ImageNetを学習したモデルは、最初の入力からジムの写真であることが分かるように、意味的な情報全体を取り出すことを得意としています。同様に、2番目のクエリでは、草などが生えている屋外の写真であることがわかります。一方、ランダムを観察すると、背景色を重視していることがわかります。
Shuffle & Learnを観察しても、色を重視しているのか、意味的な概念を重視しているのかはすぐにはわかりません。さらに調べてみると、様々な例を観察した結果、人のポーズを見ていることがわかりました。例えば、最初の画像では人物が逆さまになっており、2番目の画像ではシーンや背景色を無視して、足の位置がクエリフレームと同じような特定の位置にあることがわかります。これは、私たちののpretext taskがフレームの順番が正しいかどうかを予測していたためで、そのためには動画内で動いているもの、この場合は人物に焦点を当てる必要があったからです。
この表現を、人間のキーポイント推定のタスクに対してfine-tuningすることで、定量的に検証しました。このタスクでは人間の画像が与えられたときに、鼻、左肩、右肩、左肘,右肘などのキーポイントを予測します。この手法はトラッキングや姿勢推定に有効です。
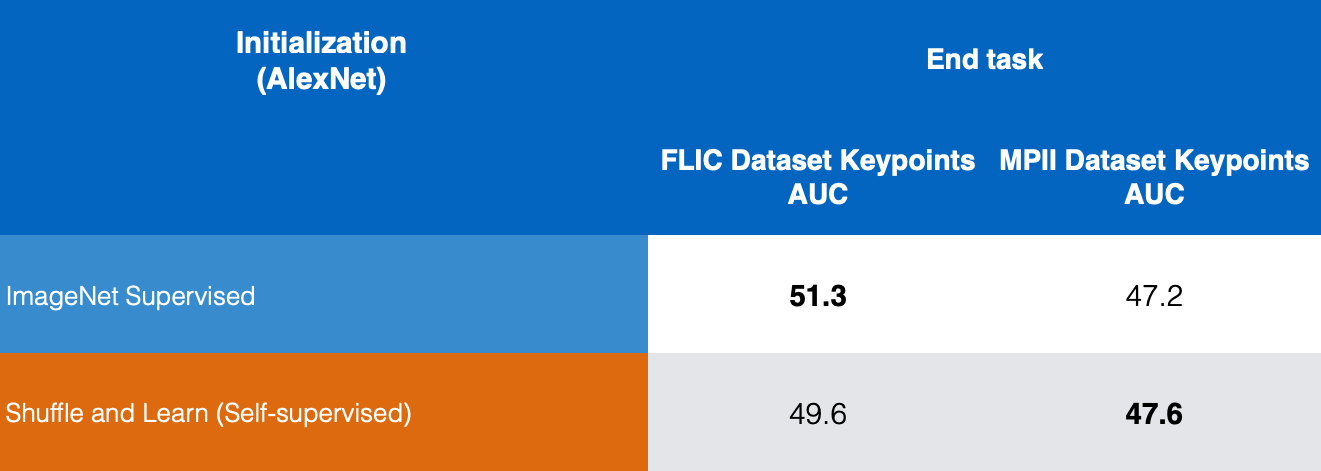
図10: キーポイント推定の比較
図10から、ImageNetを用いた教師あり学習の結果と、FLICとMPIIのデータセットを用いたShuffle & Learnによる自己教師あり学習の結果を比較したところ、Shuffle & Learnがキーポイント推定に対して良い結果を示していることがわかります。
動画と音声に対するPretext Tasks
動画と音声は、それぞれが一つの感覚入力に対応したマルチモーダルな情報です。ここで、与えられた動画クリップが音声クリップに対応しているかどうかを予測することを考えます。

図11: 動画と音声のサンプリング
ドラムの音が入った動画に対して、それに対応する音が入った動画フレームをサンプリングして、それを正のセットと呼びます。次に、ドラムの音とギターの動画フレームをサンプリングして、それを負の集合としてタグ付けします。これで、動画と音を対応づける問題を二値分類問題として解くためのネットワークを訓練することができるようになりました。
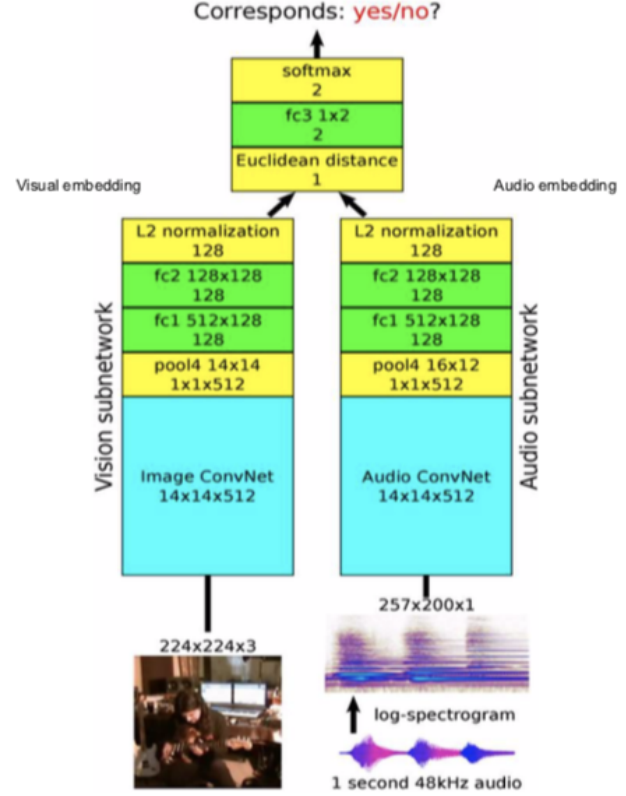
図12: アーキテクチャ
アーキテクチャ: 動画フレームを視覚タスクを解く部分ネットワークに入力し、音を音声タスクを解くサブネットワークに入力し、128次元の特徴量と埋め込みを得ます。そしてそれらを融合させて互いに対応しているかどうかを予測する二値分類問題として解きます。
これは、フレーム内の何が音を出しているのかを予測するのに使われます。直感的には、ギターの音であれば、ネットワークはギターがどのように見えるかを大まかに理解する必要があり、ドラムについても同じことが言えます。
「pretext」task が何を学習するかを理解する
-
Pretext taskは、補完的なものでなければなりません。
- 例えば、相対位置予測タスク と 色付けタスク というpretext taskを例に挙げてみましょう。以下に示すように,両方のpretext taskを学習するモデルを学習することで,パフォーマンスを向上させることができます。
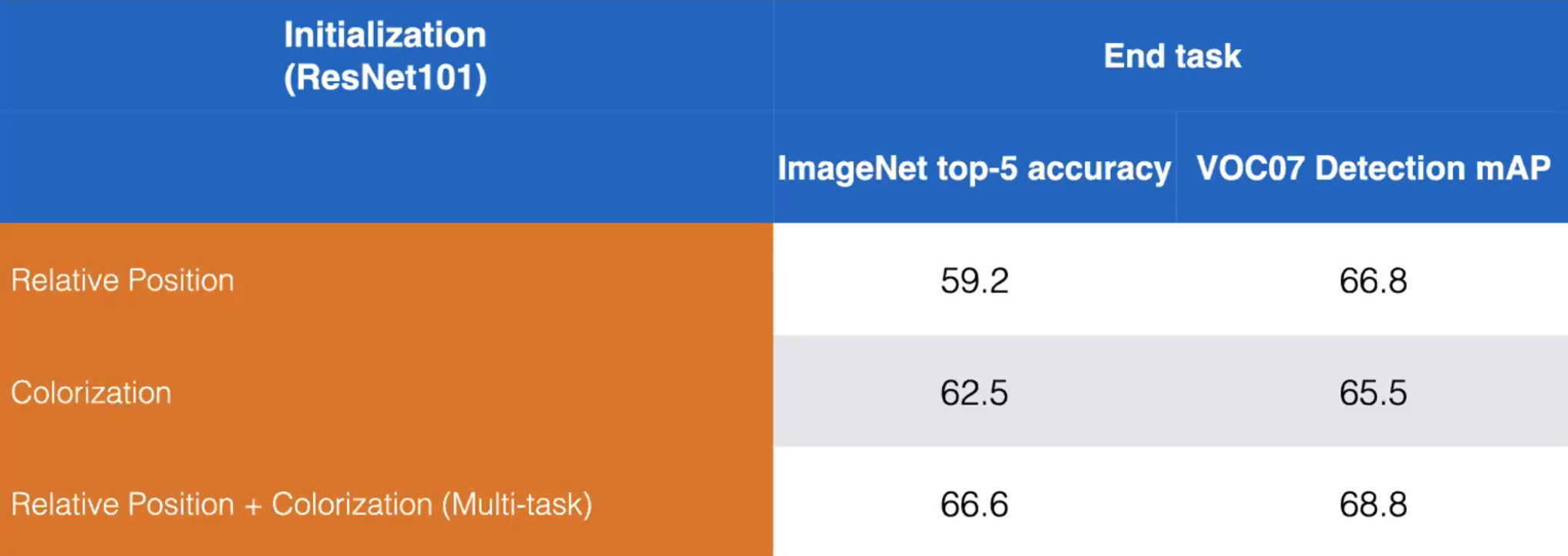
図13: 相対位置予測タスクと色付けタスクをそれぞれ解かせた場合と一緒に解かせた場合の比較。ResNet101。(Misra)
- 自己教師あり学習の表現を学習するためには、ただ一つのpretext taskを解かせることが正解ではないかもしれません。
-
Pretext taskは何を予測しようとしているかの点で大きく異なります(難しさ)
- 相対位置予測タスクは単純な分類問題なので簡単です。
- マスキングや補完ははるかに難しいです。したがって、より良い表現が得られます。
- コントラスティブ法 はpretext taskよりもさらに多くの情報を生み出します。
-
質問: どのようにして複数の事前学習を行うのですか?
- Pretextの出力は入力に依存します。最後の全結合層はバッチの種類に応じて取り換えることができます。
- 例えば、白黒画像のバッチデータがネットワークに入力され、モデルがカラー画像を生成するとします。次に、最終レイヤーを切り替え、相対位置を予測するためのパッチのバッチデータを与えます。
- Pretextの出力は入力に依存します。最後の全結合層はバッチの種類に応じて取り換えることができます。
- 質問: Pretext taskでどの程度学習した方が良いですか?
<!– * Rule of thumb: Have a very difficult pretext task such that it improves the downstream task.
- In practice, the pretext task is trained, and may not be re-trained. In development, it is trained as part of the entire pipeline. –>
- 経験則:下流のタスクを改善するように非常に難しいpretext taskを使用します。
- 実応用上は、pretext taskは再訓練されることはありません。開発では、全工程の一部として訓練されます。
自己教師あり学習をスケールさせる
ジグゾーパズル
-
画像を複数のタイルに分割し、これらのタイルをシャッフルします。モデルはその後、タイルを元の位置に戻すためにシャッフルを解除する作業を行います(Noorozi & Favaro, 2016)。
- 入力にどの並び替えが適用されたかを予測します。
- これは、画像の各タイルが独立して評価されるようなタイルのバッチを作成することで行われます。次に、畳み込みネットワークからの出力が連結され、以下の図のようにタイルの並べ替えの予測が行われます。
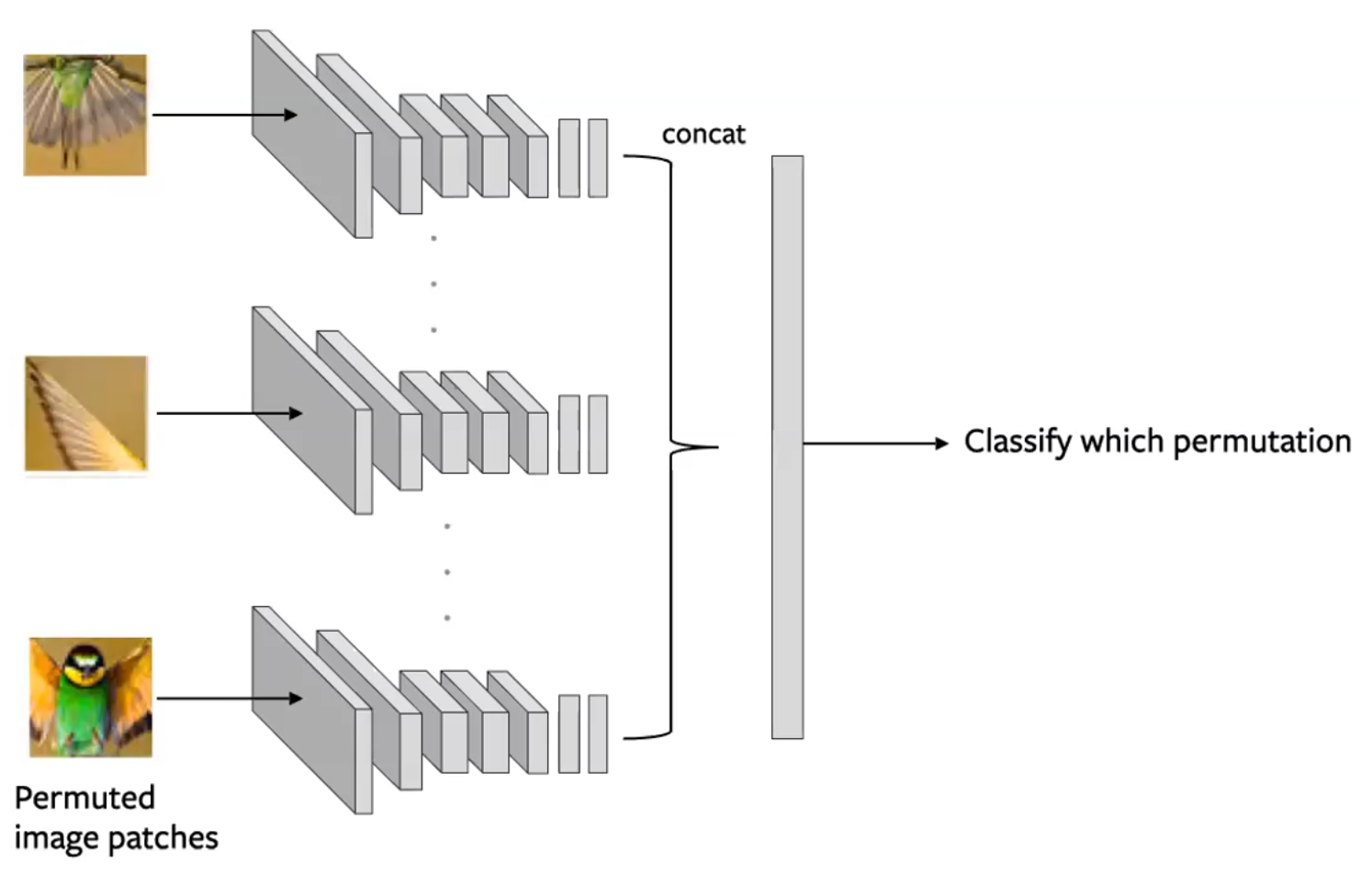
図14: ジグゾーpretext taskを解くためのSiameseネットワークアーキテクチャ。各タイルは独立に入力され、並び順を予測するために連結された埋め込みを使用します。(Misra)
- 考慮すべきこと
- 並び順の部分集合を使用してください(例:9から100を使用してください)。
- n-way ConvNetはパラメータ共有をします。
- 問題の複雑さは、部分集合の大きさです。これはすなわち予測している情報の量です。
- この方法は、ネットワークが入力の形状に関する概念を学習することができるため、教師ありの手法よりも下流のタスクで優れた性能を発揮することがあります。
-
欠点: few-shot学習のような訓練データ数が限られている場合
- 自己教師あり表現はサンプル効率が悪いです
評価: Fine-tuning vs 線形分類器
この形の評価は、ある種の転移学習です。
- Fine Tuning:下流のタスクに適用する場合は、ネットワーク全体を初期状態として使用し、そこからすべての重みを更新して新しいネットワークを訓練します。
- 線形分類器:ネットワークの残りの部分をそのままにして、Pretext task を解かせたネットワークの上に、 下流のタスクを実行するための小さな線形分類器を追加し、これを訓練します。
- Pretextの学習を 様々なタスク で評価することは有用です。これは、ネットワークの異なる層が生成した表現を固定特徴として抽出し、これらの異なるタスクでの有用性を評価することで可能になります。
- 測定法: Mean Average Precision (mAP)(平均適合率の平均):考慮しているすべての異なるタスクで平均化された平均適合率。
- これらのタスクのいくつかの例として次のようなものがあります: 物体検出(fine-tuningを使用)、表面法線推定(Surface Normal Estimation)(NYU-v2 データセットをみてください)
- 各層は何を学習しているのか?
- 一般に、深い層の表現を用いるほど下流のタスクでのmAPは高くなります。
- しかし、最終層では、層が専門化しすぎているため、mAPが急激に低下します。
- これは一般的にmAPが層の深さに応じて常に増加する教師ありネットワークとは対照的です。
- このことは、pretext taskが下流のタスクにうまく調整されていないことを示しています。
📝 Aniket Bhatnagar, Dhruv Goyal, Cole Smith, Nikhil Supekar
Shiro Takagi
6 Apr 2020