Applications of Convolutional Network
🎙️ Yann LeCun郵便番号の識別
前回の講義では、畳み込みニューラルネットワークで数字を識別できることを示しましたが、モデルがどのようにして各数字を選択し、隣接する数字への摂動を回避するのかという疑問が残りました。次のステップでは、重なりのない物体を検出するために、NMS(Non-Maximum Suppression)と呼ばれる一般的なアプローチを用います。ここで、入力が重複していない数字の列であると仮定して、複数の畳み込みニューラルネットワークを訓練し、多数決、または、畳み込みニューラルネットワークによって生成された最も高いスコアに対応する数字を選ぶ、という戦略をとります。
畳み込みニューラルネットワーク(CNN)による識別
ここでは、5つの重複がない郵便番号を識別するタスクを示します。このシステムは、各数字をどのように分離するかについての指示は与えられていませんが、5つの数字を予測する必要があることを認識しています。このシステム(図1)は、4つの異なるサイズの畳み込みニューラルネットワークで構成されており、それぞれが1つの出力セットを生成します。出力は行列で表現されますが、4つの出力行列はそれぞれ、最終層のカーネル幅が異なる4つのモデルからのものです。各出力行列は、0から9までの10のカテゴリを表す10行から構成されます。白い四角が大きいほど、そのカテゴリのスコアが高いことを表しています。これら4つの出力ブロックは、最後のカーネル層の幅が、それぞれ5、4、3、2です。カーネルのサイズは、モデルの入力のどの程度をまとめて見るかの範囲(視認窓)を決定するものですので、各モデルは異なる視認窓の大きさに基づいて数字を予測していることになります。次に、モデルは多数決を取り、その窓内で最も高いスコアに対応するカテゴリを選択します。有用な情報を抽出するためには、すべての文字の組み合わせが可能ではないことを念頭に置いておく必要があります。そのため、入力に対する制限を利用した誤り訂正は、出力が真の郵便番号であることを保証するのに役立ちます。

図1: 郵便番号識別のための複数の分類器
今度は文字に順番をつけます。ポイントは、最短経路アルゴリズムを利用することです。可能な文字の範囲と予測すべき数字の合計が与えられているので、数字を生成して数字間を遷移するための最小のコストを計算することで、この問題にアプローチすることができます。経路はグラフ上の左下のセルから右上のセルまで連続していなければならず、経路は左から右へ、下から上への移動のみを含むように制限されています。同じ数字が隣り合わせで繰り返される場合、アルゴリズムは一つの数字を予測するのではなく、繰り返される数字があることを区別できるようにしなければならないことに注意してください。
顔検出
畳み込みニューラルネットワークは物体検出タスクに適しており、顔検出もその例外ではありません。顔検出を行うには、顔のある画像と顔のない画像のデータセットを収集し、その上で30 $\times$ 30ピクセルのようなウィンドウの大きさの畳み込みニューラルネットを訓練し、顔があるかどうかをネットワークに答えてもらいます。一度訓練されたモデルを新しい画像に適用し、30 $\times$ 30ピクセルのウィンドウ内に大体の顔があれば、畳み込みネットは対応する位置で出力を点灯させます。しかし、2つの問題があります。
- 偽陽性: 顔ではない画像のパッチには様々なものがあります。学習段階では、モデルはそれらのすべて(すなわち、完全な代表集合)を見ることはできないかもしれません。そのため、モデルはテスト時に多くの偽陽性を生み出す可能性があります。
- 顔の大きさの違い: すべての顔が30 $\times$ 30ピクセルではないので、大きさの違う顔は検出されないかもしれません。この問題を解決する方法の一つとして、同じ画像のマルチスケール版を生成する方法があります。オリジナルの検出器では、30 $\times$ 30ピクセル前後の顔を検出します。もし、$\sqrt 2$のスケールを適用すると、30 $\times$ 30だったものが 20 $\times$ 20ピクセルになるので、元の画像では小さかった顔が検出されることになります。大きな顔を検出するには、画像のサイズを小さくすれば良いということになります。この処理にかかるコストの半分は、縮小されていない元々の画像を処理することで得られるので、この処理は容易に行えます。他のすべてのネットワークでかかるコストの合計は、元の非拡大画像を処理するのとほぼ同じです。ネットワークのサイズは、片側の画像のサイズの二乗なので、画像を$\sqrt 2$だけスケールダウンすると、実行する必要のあるネットワークは2倍小さくなります。 なので、全体のコストは$1+1/2+1/4+1/8+1/16…$で、これは2です。 マルチスケールモデルを実行すると、計算コストが2倍になります。
マルチスケール顔検出システム

図2: 顔検出システム
(図3)に示すマップは、顔検出器のスコアを示しています。この顔検出器は、20 $\times$ 20ピクセルの大きさの顔を認識しています。細かいスケール(スケール3)では、高いスコアが多いですが、あまり確定的ではありません。スケーリング係数を上げると(スケール6)、白い領域が多くなってきます。これらの白い領域は検出された顔を表しています。次に、non-maximum suppressionを適用して、顔の最終的な位置を求めます。

図3: 様々なスケーリングについての顔検出スコア
Non-maximum suppression
それぞれのスコアが高い領域には、おそらくその下に顔があります。より多くの顔が最初の顔に非常に近い位置で検出された場合、それは1つだけが正しく、残りは間違っていると考えるべきであることを意味します。 Non-maximum suppressionでは、重複するバウンディングボックスの中で最もスコアの高いものを取り、それ以外のものを除去します。その結果、最適な位置に1つのバウンディングボックスができます。
Negative mining
最後のセクションでは、物体が顔に似て見える方法がたくさんあることによって、テスト時にモデルがどのようにして大量の偽陽性を生み出すのかを説明しました。訓練セットには、顔に似ているように見える顔以外のオブジェクトがすべて含まれているわけではありません。この問題は、negative miningによって軽減することができます。Negative miningでは、モデルが顔として検出した非顔パッチのネガティブデータセットを作成します。このデータは、顔が含まれていないことが知られている入力に対してモデルを実行することで収集されます。次に、ネガティブデータセットを使って検出器を再訓練します。このプロセスを繰り返すことで、偽陽性に対するモデルの頑健性を高めることができます。
セマンティックセグメンテーション
セマンティックセグメンテーションとは、入力画像の各ピクセルにカテゴリを割り当てる作業です。
遠くまで視認できる適応的なロボットの視覚のためのCNN
このプロジェクトでは、ロボットが道路と障害物を区別できるように、入力画像から領域をラベル付けすることを目的としています。図では、緑色の領域がロボットが走行可能な領域であり、赤色の領域が背の高い草などの障害物です。このタスクのためのネットワークを訓練するために、画像からパッチを取り出し、それが横断可能かどうか(緑か赤か)を手動でラベル付けしました。次に、パッチの色を予測してもらうことで、パッチ上の畳み込みニューラルネットワークを訓練します。システムが十分に訓練されると、画像全体に適用され、画像のすべての領域に緑または赤のラベルが付けられます。

図4: 遠くまで視認できる適応的なロボットの視角のためのCNN (DARPA LAGR program 2005-2008)
予測には5つのカテゴリーがありました。1)スーパー緑、2)緑、3)紫:障害物足線、4)赤の障害物5)スーパー赤:間違いなく障害物。
ステレオラベル(図4、コラム2) 画像はロボットに搭載された4つのカメラによって撮影され、2つのステレオビジョンペアにグループ化されています。ステレオペアのカメラ間の既知の距離を使用して、ステレオペアの両方のカメラに現れるピクセル間の相対距離を測定することによって、3D 空間における各ピクセルの位置を推定します。これは、私たちの脳が目に見える物体の距離を推定するのと同じプロセスです。推定された位置情報を用いて、平面を地面にフィットさせ、地面に近い場合は緑、地面より上にある場合は赤のラベルを付けます。
- 限界と畳み込みニューラルネットを用いる動機: ステレオビジョンは10mまでしか使えませんが、ロボットを運転するためには長距離の視野が必要となります。しかし、畳み込みニューラルネットは正しく訓練されていれば、はるかに遠くの物体を検出することができます。

図5: 距離が正規化された画像のスケール不変なピラミッド
- モデルの入力:重要な前処理の一つとして、距離で正規化された画像のスケール不変なピラミッドを構築することが含まれます(図5)。これは、この講義の前半に複数のスケールの顔を検出しようとしたときに行ったことと似ています。
- モデルの出力 (図4、コラム3): このモデルは、画像の水平線までのピクセルごとにラベルを出力します。これらは、マルチスケール畳み込みニューラルネットワークの分類器の出力です。
- モデルを適応的にする方法: ロボットはステレオラベルに継続的にアクセスしているため、ネットワークは新しい環境に適応して再訓練を行うことができます。ネットワークの最後の層だけが再訓練されることに注意してください。前の層は事前に訓練され、固定されます。
システムのパフォーマンス
障壁の向こう側のGPS座標にたどり着こうとすると、ロボットは遠くから障壁を「見て」、それを避けるルートを計画しました。これはCNNが50~100m先までの物体を検知しているおかげです。
限界
2000年年代前半には、計算リソースは限られていました。ロボットは1秒間に1フレーム程度の処理が可能でしたが、これは、ロボットが反応するまでの1秒間は、自分の前を歩いてきた人を検出できないことを意味します。この制限を解決するのが、Low-Cost Visual Odometryモデルです。これは、ニューラルネットワークに基づいておらず、2.5m程度の視野を持ちながらも、素早く反応します。
シーンの解析とラベリング
このタスクでは、モデルはピクセルごとにオブジェクトのカテゴリ(建物、車、空など)を出力します。アーキテクチャもマルチスケールです(図6)。 <!–
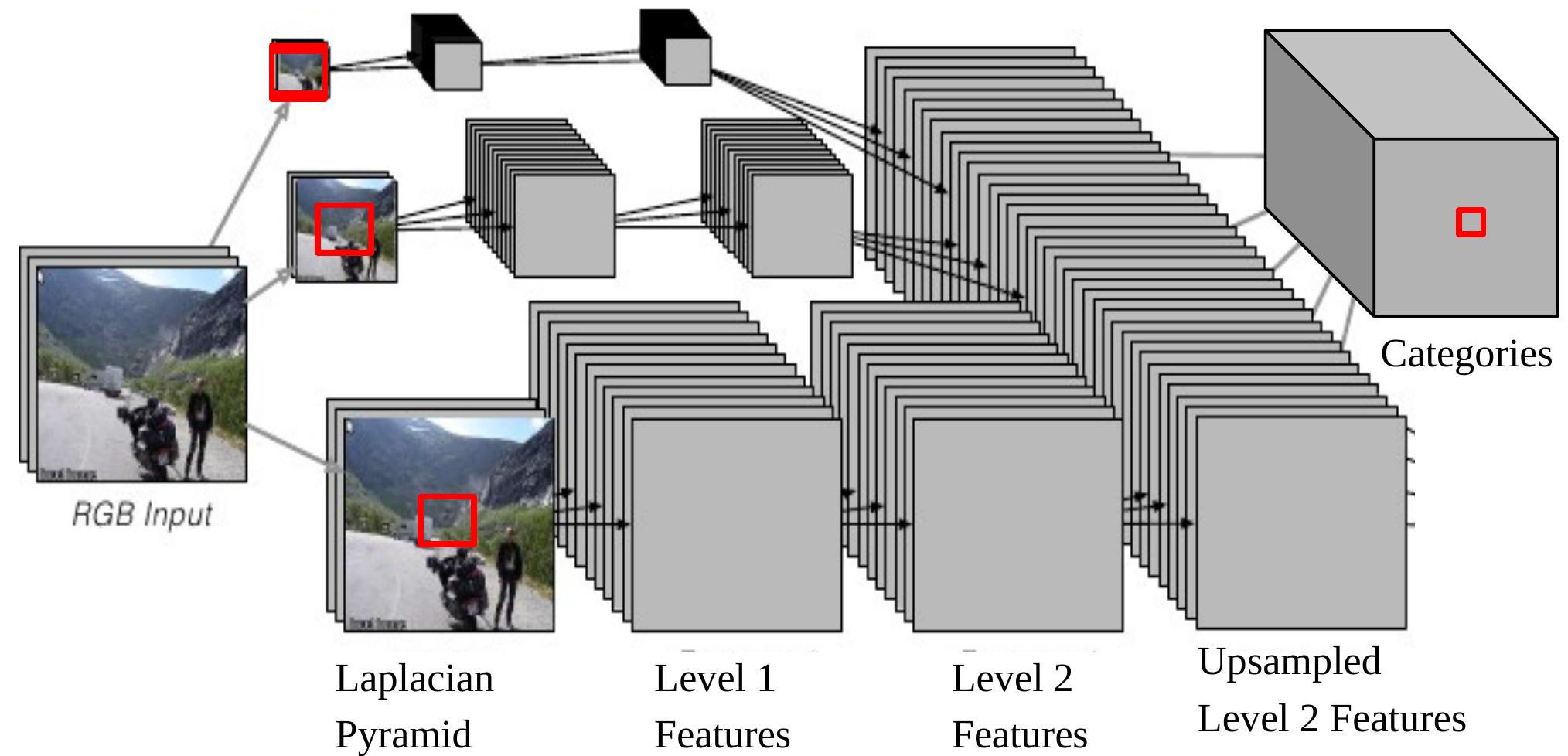
Figure 6: Multi-scale CNN for scene parsing
–>
Figure 6: シーン解析のためのマルチスケールCNN
CNNの出力を入力に逆射影することは、ラプラシアンピラミッドの底にある原画像上のサイズ$46 \times 46$の入力ウィンドウに相当することに注意してください。つまり、中心画素のカテゴリを決めるために、$46 \times 46$ ピクセルのコンテキストを使っていることになります。
しかし、大きなオブジェクトの場合、このコンテキストサイズだけではカテゴリを決定できないことがあります。
マルチスケール法では、リスケーリングされた画像を入力として提供することで、より広い視野を得ることができます。次のようなステップで行われます。
- 同じ画像を、2倍と4倍の係数で別々に縮小します。
- これら2つの余分なリスケーリングされた画像を同じ畳み込みニューラルネット(同じ重み、同じカーネル)に投入し、レベル2の特徴量を2セット取得します。
- これらの特徴量をアップサンプルして、元の画像のレベル2の特徴量と同じサイズになるようにします。
- (アップサンプルされた)特徴量の3つのセットを重ねて、分類器に送ります。
これで、1/4サイズにリサイズされた画像から得られる最大の実効的なサイズは、$184 \times 184 (46 \times 4=184)$です。
パフォーマンス:事後処理を行わず、フレーム単位で実行しているため、標準的なハードウェアでも非常に高速に動作します。訓練データのサイズがやや小さい(2k~3k)ですが、非常に優れた結果を出します。
📝 Shiqing Li, Chenqin Yang, Yakun Wang, Jimin Tan
Shiro Takagi
2 Mar 2020