Decodificare i modelli di linguaggio
🎙️ Mike LewisBeam Search
La Beam Search è un’altra tecnica per decodificare un modello di linguaggio e produrre un testo. Ad ogni passo, l’algoritmo tiene traccia delle $k$ traduzioni parziali (ipotesi) più probabili (migliori).
L’algoritmo seleziona l’ipotesi con miglior punteggio.
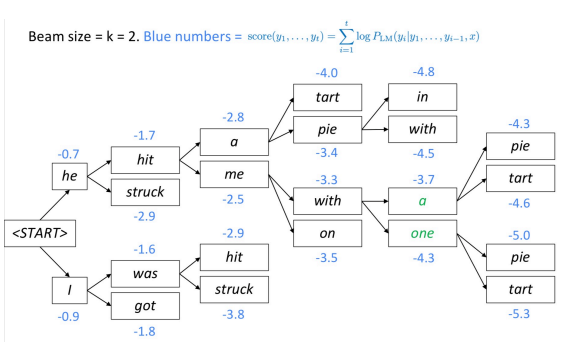
Fig. 1: decodificazione del Beam Search
Come funziona la ramificazione dell’albero di cui in Fig. 1?
L’albero continua a ramificare finché non raggiunge un simbolo che indichi la fine della frase. Quando il modello restituisce come output tale segnale, l’ipotesi è completa.
Come mai, nella traduzione automatica neurale, un’ampiezza del fascio (beam size) grande risulta spesso in traduzioni vuote?
In fase di addestramento l’algoritmo spesso non utilizza un fascio (beam) in quanto molto costoso. Usa invece una fattorizzazione auto-regressiva (ovvero, dato il precedente output corretto, predice delle possibili $n+1$ prime parole). Il modello non viene esposto ai propri errori durante la fase di addestramento, ed è quindi possibile che sia presente una certa dose di insensatezza nel fascio.
L’algoritmo continua finché tutte le $k$ ipotesi producono dei simboli di conclusione della frase o finché una lunghezza massima $T$ viene raggiunta.
Campionamento
Potremmo non desiderare di generare la sequenza più probabile, ma campionare dalla distribuzione del modello.
Tuttavia, questo tipo di campionamento ha i suoi problemi. Dal momento in cui viene campionata una sequenza non buona, il modello si trova ad essere esposto ad uno stato mai visto durante l’addestramento, il che aumenta le probabilità di continuare una catena di valutazioni “cattiva”. L’algoritmo potrebbe quindi rimanere bloccato in un circolo vizioso.
Campionamento top-k
Si va a campionare da una distribuzione di ipotesi limitata alle migliori $k$. Partendo dalla distribuzione complessiva delle ipotesi, è necessario ri-normalizzare la distribuzione troncata affinché sia effettivamente una distribuzione di probabilità. Fatto ciò, possiamo effettuare il campionamento.
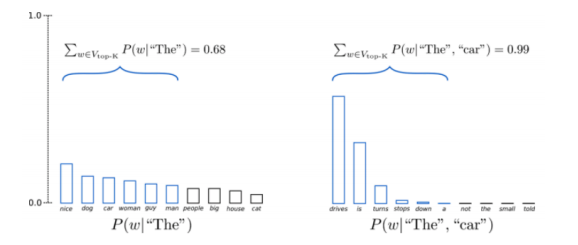
Fig. 2: campionamento top-k
Domanda: perché il campionamento top-k funziona così bene?
Questa tecnica funziona bene perché, essenzialmente, vuole prevenire l’uscita dalla varietà definita dal “buon linguaggio”, che invece si può incontrare (come visto nella sezione “Campionamento”); questa prevenzione si ottiene utilizzando solamente la testa della distribuzione complessiva, troncando la coda di ipotesi meno probabili.
Valutare la generazione del testo
La valutazione del modello di linguaggio richiede semplicemente il calcolo della log-verosimiglianza dei dati di test. Tuttavia, questo calcolo su dati testuali è complicato. Si possono valutare metriche, comunemente utilizzate, di sovrapposizione di parole con riferimento (es. BLUE, ROUGE), ma queste hanno i loro problemi.
Modelli sequenza-per-sequenza (sequence-to-sequence)
Modelli di linguaggio condizionali
I modelli di linguaggio condizionali (Conditional Language Models) non sono utili per la generazione di campioni casuali in inglese, ma per generare un testo dato un input.
Esempi:
- data una frase in francese, generarne la traduzione in inglese
- dato un documento, generarne un riassunto
- dato un dialogo, generare la frase successiva
- data una domanda, generare una risposta
Modelli sequenza-per-sequenza
Generalmente, il testo di input viene codificato (encoded). Il risultato della codificazione viene chiamato “vettore di pensieri” (thought vector) e viene passato al decodificatore per generare dei simboli una parola alla volta.
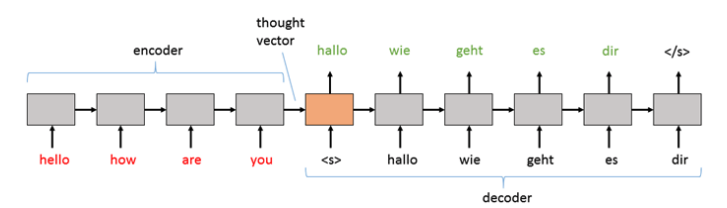
Fig. 3: vettore di pensieri
Transformer sequenza-per-sequenza
Il transformer sequenza-per-sequenza è composto di due livelli:
- Codificatore (Encoder stack) – all’auto-attenzione non sovrapposta una maschera, così ogni simbolo di input può rivolgere la sua attenzione a ogni altro simbolo di input
- Decodificatore (Decoder stack) – oltre ad utilizzare l’auto-attenzione, utilizza anche l’attenzione verso tutto l’input
Fig. 4: transformer sequenza-per-sequenza
Ogni simbolo di output ha una connessione diretta ad ogni simbolo di output precedente e ad ogni parola dell’input. Le connessioni rendono questi modelli molto espressivi e potenti: i transformer hanno migliorato i precedenti risultati delle traduzioni ad opera di modello ricorrenti e convoluzionali.
Traduzione inversa
L’addestramento di questi modelli richiede una gran quantità di dati etichettati. Una buona fonte di dati in questo senso sono gli atti del parlamento europeo: il testo è tradotto manualmente in varie lingue e lo possiamo utilizzare sia come input che come output del modello.
Problematiche
- Non tutte le lingue sono rappresentate nel parlamento europeo: ciò significa che non otterremo testi tradotti per tutte le lingue di nostro interesse. Come troviamo dati per l’addestramento in un’altra lingua?
- Poiché i modelli come i transformer funzionano molto meglio con grandi quantitativi di dati, come usiamo del testo monolinguistico (ovvero, senza accoppiate input/output) per l’addestramento?
Assumiamo di voler addestrare un modello per tradurre testo dal tedesco all’inglese. L’idea della traduzione inversa è quella di, innanzitutto, addestrare un “modello inverso” dall’inglese al tedeco.
- Usando un limitato numero di dati già tradotti, possiamo acquisire delle frasi in due diverse lingue
- Una volta ottenuto un modello inglese → tedesco, traduciamo un gran quantitativo di singole parole inglesi in tedesco
Infine, addestriamo il modello dal tedesco all’inglese utilizzando le parole tedesche che sono state “tradotte inversamente” nel passaggio precedente. Si noti che:
- Indipendentemente da quanto non sia buono il modello inverso, passiamo da traduzioni tedesche di scarsa qualità, ma le traduzioni verso l’inglese sono “pulite”
- Il modello deve imparare a capire bene l’inglese, ben oltre le accoppiate inglese/tedesco a nostra disposizione: dobbiamo quindi usare una gran quantità di testo monolingue in inglese.
Traduzione inversa iterativa
- La procedura di traduzione inversa può essere iterata così da generare un numero persino maggiore di dati testuali in entrambe le lingue, raggiungendo performance di molto maggiori: è necessario continuare ad addestrare il modello usando dati monolingue.
- Aiuta molto quando non sono presenti dall’inizio dati “paralleli” in entrambe le lingue
Traduzione automatica multilingue massiva
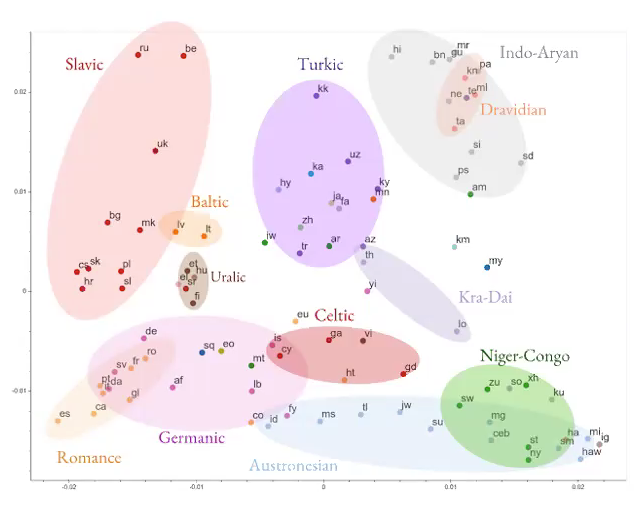
Fig. 5: traduzione multilingue massiva
- Anziché provare ad apprendere una traduzione da una lingua all’altra, si costruisce una rete neurale per imparare a tradurre in più lingue.
- Il modello impara delle generiche informazioni indipendenti dalla singola lingua.

Fig. 6: risultati della rete neurale per traduzione multilingue
Si hanno degli ottimi risultati risultati, specialmente se vogliamo addestrare un modello a tradurre verso lingue per le quali non si hanno molti dati a disposizione (“linguaggi a basse risorse”).
Apprendimento non supervisionato per l’NLP
Ci sono enormi quantità di testi non etichettati e pochi dati supervisionati. Come si può apprendere cose a proposito di un linguaggio semplicemente leggendo del testo non etichettato?
word2vec
Intuizione: parole che compaiono vicine in un testo sono probabilmente correlate; speriamo così che, solamente osservando un testo in inglese non catalogato, possiamo impararne il significato.
- L’obiettivo è apprendere una rappresentazione di uno spazio vettoriale delle parole (ovvero di impararne una codificazione).
Compito di pre-addestramento - mascherare delle parole e usare le parole vicine per riempire gli spazi mancanti.

Fig. 7: rappresentazione visiva della mascheratura operata per word2vec
Ad esempio, qui, l’indea è che sia più plausibile che le parole horned (“dotato di corna”) e silver-haired (“dai capelli d’argento”) compaiano nel contesto dell’“unicorno” (unicorn) rispetto ad altri animali.
Si prendono le parole e vi si applica una proiezione lineare
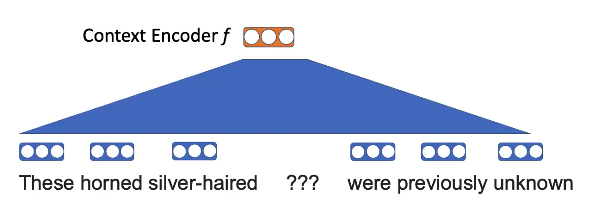
Fig. 8: codificazione operata da word2vec
Vogliamo conoscere
\[p(\texttt{unicorno} \mid \texttt{Gli oggetti "???" dai capelli d'argento siano precedentemente sconosciuti})\] \[p(x_n \mid x_{-n}) = \text{softmax}(\text{E}f(x_{-n})))\]Le codificazioni delle parole hanno una determinata struttura
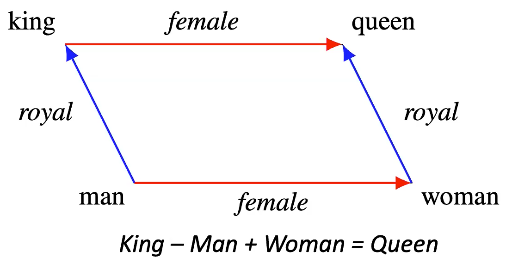
Fig. 9: esempio di struttura della codificazione
- L’idea è che se prendiamo la codificazione di “re” (king) dopo l’addestramento e vi sommiamo la codificazione di “femmina” (female), otteniamo una codificazione che sia molto vicina a quella di “regina” (queen)
- Vengono esposte delle differenze semantiche significative nello spazio vettoriale
Domanda: le rappresentazioni delle parole sono dipendenti o indipendenti dal contesto?
Indipendenti e non hanno idea di come si relazionano con altre parole.
Domanda: quale sarebbe un esempio di una situazione in cui questo modello farebbe difficoltà?
L’interpretazione delle parole dipende fortemente dal contesto. Quindi, nel caso di parole ambigue - che hanno significati multipli - il modello farà difficoltà in quanto le codificazioni dei vettori non cattureranno il contesto necessario a comprendere correttamente la parola.
GPT
Per aggiungere il contesto, possiamo addestrare un modello di linguaggio condizionale. Dato questo modello, il quale predice una parola ad ogni istante temporale, si rimpiazza ogni output del modello con una qualche altra caratteristica.
- Pre-addestramento - predire la prossima parola
- Affinamento - adattarsi ad un compito specifico. Esempi:
- predire se una parola è un sostantivo o un aggettivo
- dato del testo che include delle recensioni di Amazon, predire il valore del sentimento per queste recensioni
Questo approccio è buono perché possiamo ri-utilizzare il modello. Possiamo pre-addestrarne uno grande ed affinarlo su altri compiti.
ELMo
GPT considera solamente il contesto verso sinistra, il che significa che il modello non può dipendere da parole future - ciò limita di parecchio le cose che il modello può ottenere.
L’approccio diviene quindi quello di addestrare due modelli:
- uno sul testo da sinistra a destra
- uno sul testo da destra a sinistra
- si concatena l’output dei due modelli al fine di ottenere la rappresentazione della parola. Quindi, si condiziona su entrambi i contesti (destra e sinistra).
Questa è comunque ancora una combinazione superficiale, vorremmo delle interazioni più complesse fra i due contesti.
BERT
BERT è simile a word2vec nel senso che abbiamo un compito di “riempire i vuoti”. Tuttavia, in word2vec avevamo delle proiezioni lineari, mentre in BERT c’è un grosso transformer che riesce a concentrarsi su più contesti. Per addestrarlo, mascheriamo il 15% dei simboli e proviamo a predire quanto abbiamo mascherato.
Si può scalare BERT (RoBERTa):
- semplificare l’obiettivo di pre-addestramento di BERT
- aumentare la dimensione del batch
- addestrare su un grosso numero di GPU
- addestrare su ancora più testo
Vi sono dei grossi miglioramenti sulle performance di BERT: nel compito di rispondere alle domande ottiene ora performance sovrumane.
Pre-addestramento per NLP
Diamo ora una rapida occhiata a diversi approcci di pre-addestramento auto-supervisionato finora ricercati per l’NLP.
-
XLNet:
Anziché predire tutti i simboli mascherati indipendenemente fra loro, XLNet li predice in maniera autoregressiva in ordine casuale
-
SpanBERT:
Maschera sequenze di parole consecutive anziché singoli simboli.
-
ELECTRA:
Anziché mascherare le parole sostituiamo i simboli con altri simboli similari. Quindi, risolviamo un problema di classificazione binaria provando a prevedere se i simboli sono stati sostituiti oppure sono originali.
-
ALBERT:
Una versione leggera di BERT: si modifica BERT e lo si rende più leggero tramite la condivisione dei pesi fra i vari strati. Ciò riduce i parametri del modello e le computazioni coinvolte. È interessante notare come gli autori di ALBERT non hanno dovuto fare molti compromessi per quanto concerne l’accuratezza del loro modello.
-
XLM:
BERT multilinguistico: anziché fornire al modello testo solo in inglese, gli forniamo input in più lingue. Come atteso, impara meglio le connessioni comuni fra varie lingue.
I punti chiave dei modelli sopra menzionati sono:
- Molti obiettivi di pre-addestramento funzionano bene
- Le interazioni profonde bidirezionali fra parole sono cruciali per l’efficacia del modello
- Si hanno grossi guadagni dallo scalamento verso l’alto del pre-addestramento, e non si sono ancora trovati chiari limiti
La maggior parte dei modelli finora discussi sono costruiti al fine di risolvere problemi di classificazione testuale. Tuttavia, per risolvere problemi di generazione del testo, dove si genera l’ouptut in maniera sequenziale, come nel modello seq2seq, abbiamo bisogno di un approccio di pre-addestramento leggermente diverso.
Tecniche di pre-addestramento per una generazione condizionata: BART e TS
BART: pre-addestramento di modelli seq2seq tramite la rimozione di rumore dal testo
Per il pre-addestramento di BART, prendiamo in considerazione una frase e la corrompiamo tramite la mascherazione di simboli a caso. Anziché predire i simboli mascherati (come nell’obiettivo di BERT), diamo in input l’intera sequenza corrotta e cerchiamo di predire l’intera frase corretta.
Questo approccio di pre-addestramento seq2seq ci dà una flessibilità nella progettazione degli schemi di corruzione. Possiamo decidere di cambiare l’ordine delle frasi, di rimuoverne, di introdurne di nuove, ecc.
BART è stato in grado di comportarsi al pari di RoBERTa nei compiti SQUAD e GLUE. Tuttavia, dettò un nuovo stato dell’arte nella generazione di riassunti, di dialogo e sui dataset di risposta alle domande astrattiva.
Questioni aperte nell’NLP
- Come si integra la conoscenza del mondo?
- Come modelliamo documenti lunghi? (usualmente, i modelli basati su BERT usano 512 simboli)
- Come espletiamo compiti di apprendimento multiobiettivo al meglio?
- Si può effettuare un affinamento con meno dati?
- Questi modelli sono veramente in grado di comprendere il linguaggio?
Riassunto
- Addestrare modelli su una grande quantità di dati dà risultati migliori rispetto alla modellazione esplicita della struttura del linguaggio.
Secondo una prospettiva di varianza vs. distorsione, i transformer sono modelli a bassa distorsione (molto espressivi). Addestrare questi modelli su molti dati è meglio di modellare esplicitamente la struttura linguistica (alta distorsione). Le archietture dovrebbero comprimere le sequenze tramite colli di bottiglia (bottlenecks).
- I modelli possono apprendere molto del linguaggio predicendo parole in testo non categorizzato. Ciò è un ottimo obiettivo di apprendimento non supervisionato. Dopo di ciò, l’affinazione per compiti specifici è cosa facile.
- Il contesto bidirezionale è cruciale ai fini del corretto funzionamento del modello
Ulteriori approfondimenti da domande pervenute dopo la lezione
Quali sono altri modi di quantificare la “comprensione del linguaggio”? Come capiamo se questi modelli sono veramente in grado di comprendere il linguaggio?
«La coppa non entrava nella valigia perché era troppo grande»: comprendere qual è il soggetto del secondo periodo è complicato per le macchine. Gli umani sono bravi in questo compito. C’è un dataset che si concentra su esempi di questa difficoltà; gli umani vi ottengono una performance del 95%. I programmi informatici sono stati in gradi di arrivare attorno al 60% prima della rivoluzione introdotta dai transformer. I transformer moderni sono in grado di ottenere più del 90% su questo dataset: ciò suggerisce che tali modelli non stanno solo memorizzando o “sfruttando” i dati, ma imparano concetti e oggetti tramite i motivi statistici contenuti nei dati.
Inoltre, BERT e RoBERTa ottengono performance sovrumane su SQUAD e GLUE. I riassunti testuali generati da BART sembrano molto realistici all’occhio umano (alti valori di BLEU). Questi fatti sono prova che i modelli comprendono il linguaggio in un certo modo.
Linguaggio concreto
L’insegnante (Mike Lewis, ricercatore presso Facebook AI Research) sta lavorando ad un concetto denomimato “linguaggio concreto”. L’obiettivo di questo campo di ricerca è la costruzione di agenti conversanti che possano chiacchierare o negoziare. Questi sono due compiti astratti che non hanno dei chiari obiettivi se comparati alla classificazione o alla generazione di riassunti di testo.
Siamo in grado di valutare se il modello ha già una conoscenza del mondo?
La “conoscenza del mondo” è un concetto astratto. Possiamo testare i modelli, ad un livello molto base, nella loro conoscenza del mondo ponendo loro domande a proposito dei concetti di cui siamo interessati. Modelli come BERT, RoBERTa e T5 hanno miliardi di parametri. Considerato che tali modelli sono addestrati sulla base di enormi raccolte di testo informativo come Wikipedia, avranno memorizzato dei fatti usando i loro parametri e saranno quindi in grado di rispondere alle nostre domande. Inoltre, possiamo anche pensare di condurre i medesimi test di conoscenza prima e dopo l’affinazione del modello su un dato obiettivo. Ciò ci potrebbe dare un’idea di quanta informazione il modello avrà “dimenticato”.
📝 Trevor Mitchell, Andrii Dobroshynskyi, Shreyas Chandrakaladharan, Ben Wolfson
Marco Zullich
20 Apr 2020