Apprendimento auto-supervisionato - Compiti di pretesto
🎙️ Ishan MisraUna storia di successo della supervisione: il pre-addestramento
Nel decennio passato, una delle più grandi ricette del successo per svariati compiti di visione artificiale è stato l’apprendimento di rappresentazioni visive tramite l’esecuzione di tecniche di apprendimento supervisionato per la classificazione d’immagini del dataset ImageNet e usare queste rappresentazioni, o set di parametri già addestrati, come inizializzazione per altri compiti di visione artificiale laddove non fosse disponibile una grossa quantità di dati pre-catalogati.
Tuttavia, ottenere delle annotazioni per un dataset della grandezza di ImageNet è un’attività che consuma una quantità enorme di tempo. Ad esempio, l’etichettatura delle 14 milioni d’immagini di ImageNet è durata approssimativamente 22 anni.
A causa di ciò. la comunità scientifica ha iniziato a cercare processi di etichettatura alternativi, come gli hashtag delle immagini dei social media, dati provenienti dai processi di geolocalizzazione GPS, oppure approcci auto-supervisionati dove l’etichetta si può immaginare come essere una proprietà intrinseca del campione di dati.
Tuttavia, una domanda importante che ci si pone prima di cercare processi di catalogazione alternativi è:
Quanti dati catalogati possiamo ottenere dopotutto?
- Se ricerchiamo tutte le immagini con categorie a livello dell’oggetto e con coordinate dei bounding box (ndr, rettangolo che indica la posizione dell’oggetto all’interno dell’immagine) allora ci sono circa un milione d’immagini con queste caratteristiche.
- Se il vincolo delle coordinate sui bounding box viene rilassato, si hanno a disposizione circa 14 milioni d’immagini.
- Tuttavia, se si considerano tutte le immagini disponibili in internet, si fa un salto di 5 ordini nella quantità di dati a disposizione.
- E, ancora, ci sono altri dati diversi dalle immagini, dati che richiedono altri input sensoriali per essere colti o compresi.
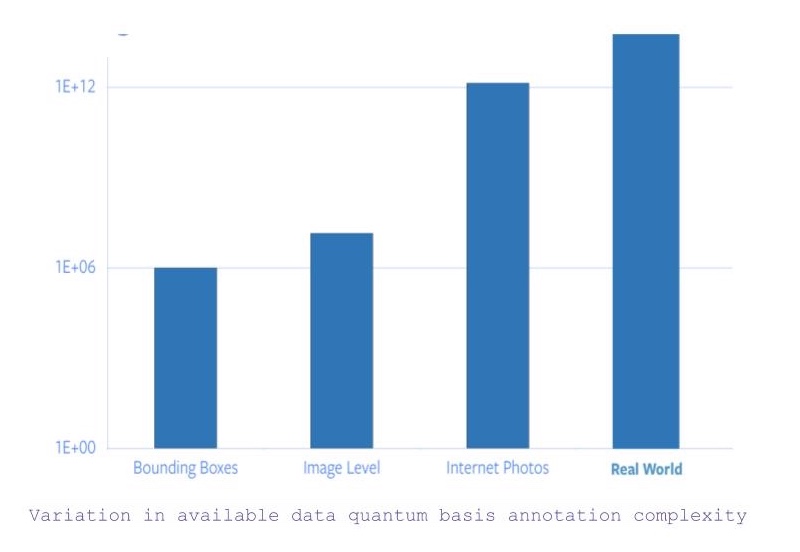
Fig. 1: variazione nella complessità quantica base delle annotazioni
Dunque, basandoci sul fatto che ad annotare le immagini del solo database di ImageNet si sono impiegati 22 anni di vita, scalare la categorizzazione a tutte le immagini disponibili in internet (o più di ciò) è un compito totalmente irrealistico.
Il problema dei concetti rari (o delle code lunghe)
Generalmente, il grafico che presenta la distribuzione delle annotazioni delle immagini di internet assomiglia ad una lunga coda. Ovvero, la maggior parte delle immagini è dotata di molto poche annotazioni, mentre esiste un grande numero di categorie in cui sono presenti poche immagini. Di conseguenza, ottenere campioni d’immagini annotate per le categorie alle fine della code richiede grosse quantità di dati da etichettare.
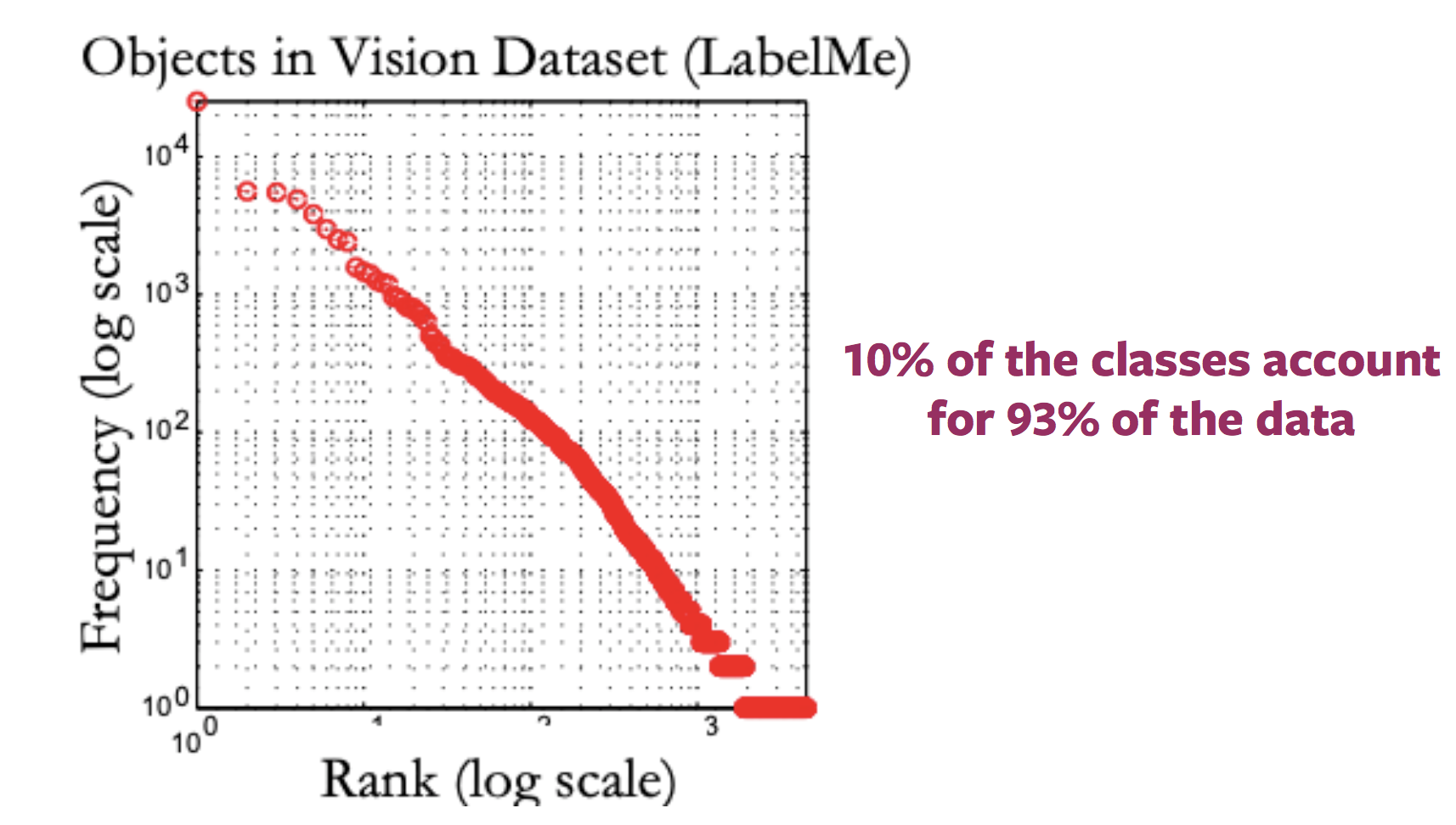
Fig. 2: Variazione nella distribuzione della disponibilità in immagini annotate
Il problema dei domini differenti
Il metodo, prima descritto, consistente nell’effettuare un pre-addestramento su ImageNet per poi operare un affinamento (fine-tuning) sul compito d’interesse diventa ancora più oscuro quando questo compito appartiene a domini differenti, come le immagini mediche, per fare un esempio. E, ottenere un dataset il cui ruolo di dataset “di riferimento” è analogo a quello di ImageNet, ma per domini differenti, è impossibile.
Che cos’è l’apprendimento auto-supervisionato?
Due definizioni di apprendimento auto-supervisionato
- Definizione di base dell’apprendimento auto-supervisionato, ovvero la rete è addestrata in maniera supervisionata, con le classificazioni effettuate in maniera semi-automatica, senza input umano.
- Problema predittivo, dove una parte dei dati è nascosta e i restanti sono visibili. Dunque, lo scopo è o di predire i dati nascosti o prevederne una determinata proprietà.
In cosa differiscono l’apprendimento auto-supervisionato e quello non supervisionato?
- I compiti di apprendimento supervisionato prevedono l’esistenza di annotazioni/classificazioni predefinite (usualmente generate da umani)
- L’apprendimento non-supervisionato considera solamente le istanze dei dati senza alcuna supervisione, ovvero etichetta o indicazione sull’output corretto.
- L’apprendimento auto-supervisionato determina dette annotazioni da determinate modalità co-occorrenti nell’insieme dei dati o da parti degli stessi dati che co-occorrono all’interno del campione.
Apprendimento auto-supervisionato nell’elaborazione automatica del linguaggio
Word2Vec
- Data una frase di input, il compito consiste nel prevedere una parola mancante da tale frase. La parola è omessa con lo scopo specifico di creare un compito di pretesto.
- Dunque, l’insieme di annotazioni diviene tutte le possibili parole del vocabolario e l’annotazione corretta è la parola omessa dalla frase.
- Quindi, la rete può essere addestrata usando un classico metodo a gradiente per imparare le rappresentazioni al livello delle parole.
Perché l’apprendimento auto-supervisionato?
- L’apprendimento auto-supervisionato permette d’imparare rappresentazioni dei dati a partire dalle osservazioni su come differenti parti dei dati interagiscono fra di loro.
- Di conseguenza, viene meno il requisito di disporre di grosse quantità di dati annotati.
- In aggiunta a ciò, permette di considerare modalità multiple che potrebbero essere associate ad una singola istanza dei dati.
L’apprendimento auto-supervisionato nella visione artificiale
Usualmente, nella visione artificiale sono utilizzate delle pipeline che utilizzano tecniche di apprendimento auto-supervisionato. Queste tecniche sono composte in due parti: un compito di pretesto e un compito reale, denominato compito downstream.
- Il compito downstream può essere un compito qualsiasi, dalla classificazione all’individuazione di oggetti. La caratteristica è che si dispone di un numero insufficiente di dati annotati.
- Il compito di pretesto è il compito di apprendimento auto-supervisionato risolto per imparare le rappresentazioni visive, con lo scopo di applicare al compito downstream dette rappresentazioni (ovvero i pesi del modello) ottenute nel corso dell’addestramento.
Lo sviluppo di compiti di pretesto
- I compiti di pretesto per la visione artificiale possono essere sviluppati usando immagini, video, o video con tracce audio.
- Per ogni compito di pretesto, vi è una parte visibile dei dati e una parte nascosta; il compito sta nel formulare previsioni riguardanti i gli stessi dati nascosti, oppure una proprietà di questi ultimi.
Esempio di un compito di pretesto
- Input: 2 finestre di un’immagine, una agisce da riferimento (anchor), l’altra da termine d’interrogazione (query)
- Date le 2 finestre, la rete deve prevedere la posizione relativa della finestra di interrogazione nei confronti della posizione del riferimento
- Il problema può quindi essere modellato come una classificazione a 8 classi, essendovi 8 possibili posizioni della finestra d’interrogazione dato il riferimento.
- Le annotazioni per questo compito possono essere automaticamente generate dando in input la posizione relativa della finestra d’interrogazione rispetto al riferimento.
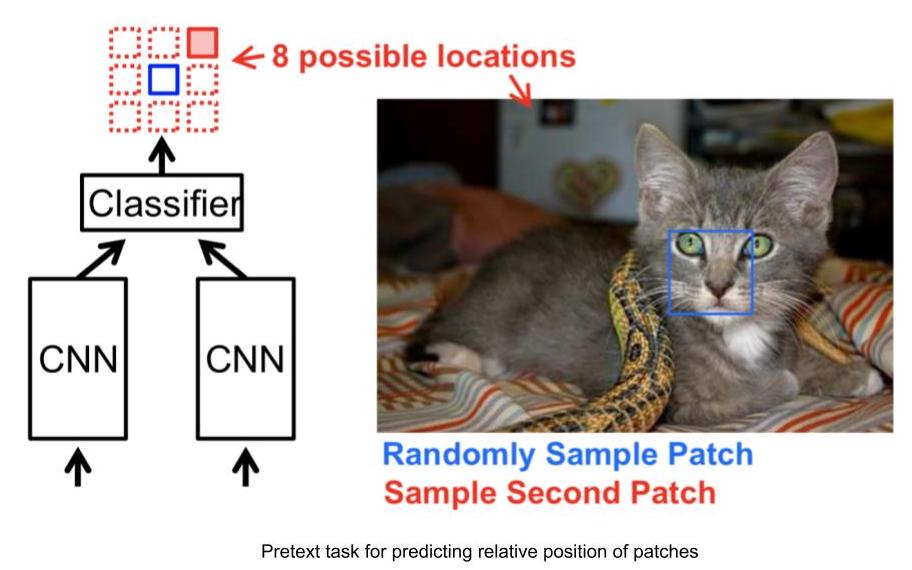
Fig. 3: Compito di posizionamento relativo
Rappresentazioni visive apprese dal compito di previsione del posizionamento relativo
Possiamo valutare l’efficacia delle rappresentazioni visive apprese andando a controllare i vicini più vicini (nearest neighbours) di una data finestra d’immagine nello spazio delle caratteristiche apprese dalla rete. Per ottenere i vicini più vicini:
- Ottenere le caratteristiche dalla CNN per tutte le immagini del dataset: questo agirà da base per l’identificazione dei vicini.
- Ottenere le caratteristiche dalla CNN per la finestra d’immagine desiderata.
- Identificare il vicino più vicino per il vettore di caratteristiche dell’immagine richiesta, dall’insieme dei vettori di caratteristiche ottenuto, in prima battuta, dalle immagini disponibili.
Il compito di posizionamento relativo trova finestre d’immagini che sono molto simili ad altre finestre dell’immagine di input, mantenendo al contempo invarianza a fattori come il colore degli oggetti. Di conseguenza, tale compito è in grado di imparare rappresentazioni visive, laddove finestre visivamente simili sono vicine anche nello spazio delle rappresentazioni.

Fig. 4: posizionamento relativo: vicini più vicini
Predire la rotazione d’immagini
- La previsione delle rotazioni è uno dei compiti di pretesto più popolari. Esso presenta un’architettura intuitiva e richiede un campionamento minimo.
- Applichiamo rotazioni di 0, 90, 180, 270 gradi all’immagine e diamo in input tutte queste immagini rotate alla rete per prevedere che tipo di rotazione è stata applicata all’immagine; la rete produce dunque una classificazione in 4 classi per prevedere la rotazione.
- Prevedere le rotazioni non ha alcun significato semantico, stiamo solo usando questo compito come un pretesto per apprendere alcune caratteristiche e rappresentazioni da utilizzare in un compito downstream.
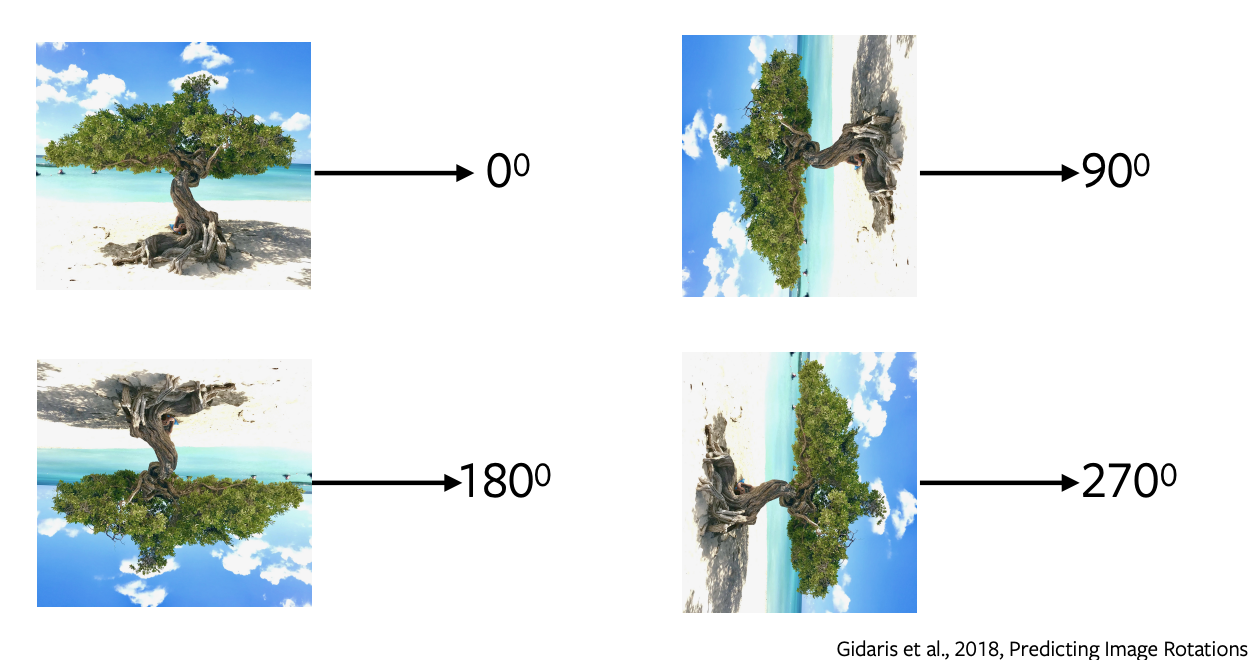
Fig. 5: rotazioni di immagini
Perché le rotazioni sono d’aiuto, come funziona?
È stato provato che questo compito funziona in maniera empirica. L’intuizione dietro esso è che, per prevedere le rotazioni, il modello necessita di comprendere i confini grezzi e le rappresentazioni di un’immagine. Ad esempio, dovrà distinguere il cielo dall’acqua o l’acqua dalla sabbia o dovrà comprendere che gli alberi crescono all’insù e così via.
Colorazione

Fig. 6: colorazione
In questo compito di pretesto, prevediamo i colori data un’immagine in scala di grigi. Può essere formulato per un’immagine: semplicemente si rimuove il colore e si dà quest’immagine in scala di grigi alla rete per predirne i colori. Il compito è utile ad esempio nella colorazione di vecchi filmati in bianco e nero. L’intuizione dietro questo compito è che la rete deve comprendere informazioni utili come il fatto che gli alberi sono verdi, il cielo è blu e così via.
È importante notare che la mappatura dei colori non è deterministica e che vi sono diverse soluzioni possibili. Così, se per un oggetto vi sono svariati possibili colori, allora la rete lo colorerà di grigio, ovvero la media di tutte le possibili soluzioni. Vi sono stati lavori recenti che utilizzano Autoencoder variazionali e variabili latenti per diversi colori.
Riempire i buchi
Si nasconde una porzione dell’immagine e si predice la parte occultata dalla restante parte d’immagine. Questo funziona perché la rete imparerà la struttura implicita dei dati; ad esempio come rappresentare il fatto che le macchine si trovano sulle strade, che gli edifici sono composti da finestre e porte e così via.
Compiti di pretesto per video
I video sono composti di sequenze di frame e questa nozione è l’idea di fondo dell’auto-supervisione. Essa può essere utilizzata a proprio favore per alcuni compiti di pretesto come prevedere l’ordine dei frame, riempire i buchi e tracciamento di oggetti.
Mescola e Impara (Shuffle & Learn)

Fig. 7: interpolazione
Dato un insieme di frame, ne estraiamo casualmente tre: se sono estratti nell’ordine corretto, etichettiamo il campione come positivo; se sono mescolati, lo etichettiamo come negativo. Questo diviene un problema di classificazione binaria: prevedere se i frame sono in ordine corretto oppure no. Ovvero, dato un frame di partenza e di destinazione, verifichiamo se quello di mezzo è un’interpolazione valida dei due.
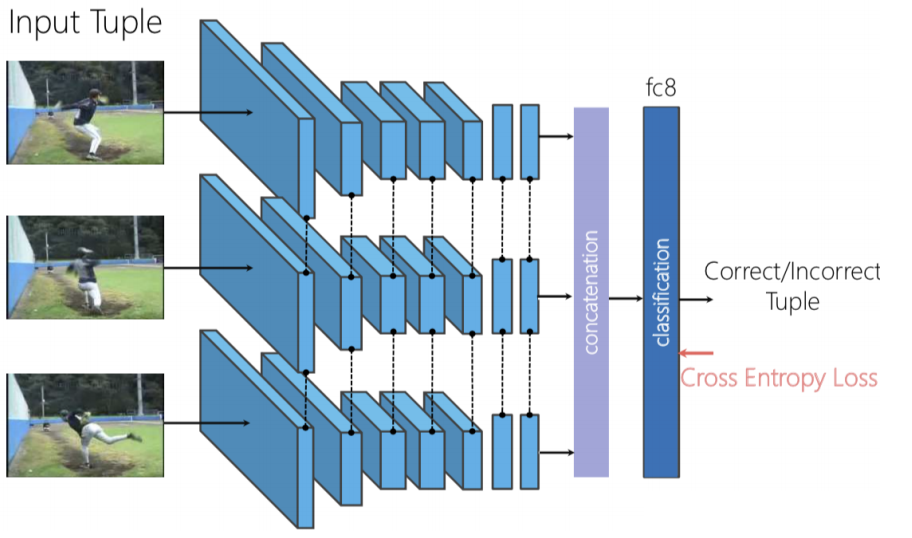
Fig. 8: architettura per "Mescola e Impara"
Possiamo usare un trio di reti siamesi, dove i tre frame sono indipendentemente dati in input alla rete; dopodiché, concateniamo le caratteristiche generate ed effettuiamo una classificazione binaria per predire se i frame sono mescolati oppure no.

Fig. 9: rappresentazione dei vicini più vicini
Nuovamente, possiamo usare l’algoritmo dei vicini più vicini per visualizzare che cosa sta imparando la nostra rete. Nella Fig. 9 qui sopra, innanzitutto abbiamo un frame d’interrogazione (Query) che diamo in input alla rete ad ottenere la rappresentazione, dopodiché guardiamo i vicini più vicini nello spazio delle rappresentazioni. Effettuando la comparazione, possiamo osservare una netta differenza fra i vicini ottenuti da ImageNet, Mescola e Impara e casualmente (Random).
ImageNet funziona bene nel collassare interamente le semantiche, giacché è in grado di identificare che si tratta di una scena di una palestra per quanto riguarda il primo input. Similarmente, è in grado di riconoscere che è una scena all’aperto con erba ecc. per la seconda interrogazione. Osservando i vicini casuali (Random), possiamo notare che viene data molta importanza al colore dello sfondo.
Osservando Mescola e Impara, non è immediatamente chiaro se la rete si focalizzi sul colore o sui concetti semantici. Dopo ulteriori analisi su vari esempi, è stato osservato che si sta focalizzando sulla posa delle persone: ad esempio, nella prima immagine la persona è a testa in giù e, nella seconda, i piedi si trovano in una posizione specifica analoga al frame d’interrogazione; vengono ignorati la scena e il colore di sfondo. Il ragionamento sottostante è che il compito di pretesto era di prevedere se i frame si trovavano nell’ordine corretto oppure no, e per fare ciò la rete deve focalizzarsi su ciò che nella scena si sta muovendo: in tal caso, la persona.
È stato verificato in maniera quantitativa, attraverso il fine-tuning (affinamento) della rappresentazione per il compito della stima dei punti chiave umani, dove data un’immagine umana bisogna prevedere la posizione di determinati punti chiave (come il naso, la spalla sinistra, la spalla destra, i gomiti sinistro e destro, ecc.), che questo metodo è utile per il tracciamento e la stima della posa umana.
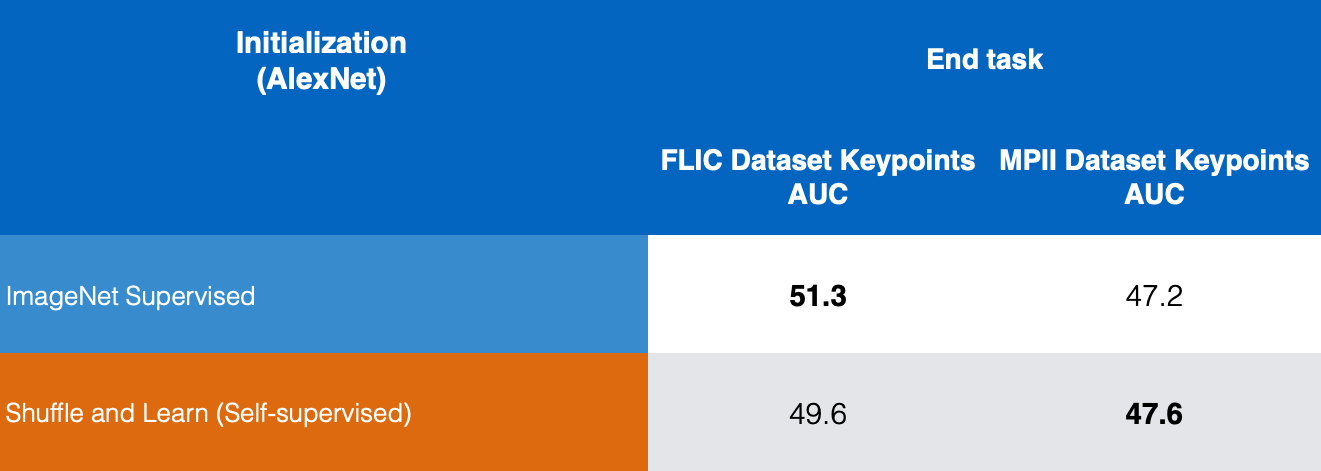
Fig. 10: Paragone della stima dei punti chiave
Nella Fig. 10, sono comparati i risultati, per quanto riguarda la stima dei punti chiave, di ImageNet supervisionato e di Impara e Mescola auto-supervisionato sui dataset FLIC e MPII; possiamo vedere come Impara e Mescola dia dei buoni risultati.
Compiti di pretesto per video con audio
I video con audio sono dati multimodali, ovvero vi sono due modalità o input sensoriali, una per il video, l’altra per il suono. Si cerca di prevedere la corrispondenza di una data traccia video ad una data traccia audio.

Fig. 11: campionamento video e audio
Data una traccia audio/video di una batteria, si campiona un frame video con la sua corrispondente traccia audio: si definisce che questa coppia appartiene ad un insieme positivo. Dopodiché, si prende l’audio di una batteria e lo si accoppia ad un frame video di una chitarra: questa coppia appartiene ad un insieme negativo. Addestriamo una rete a risolvere questo problema di classificazione binaria.
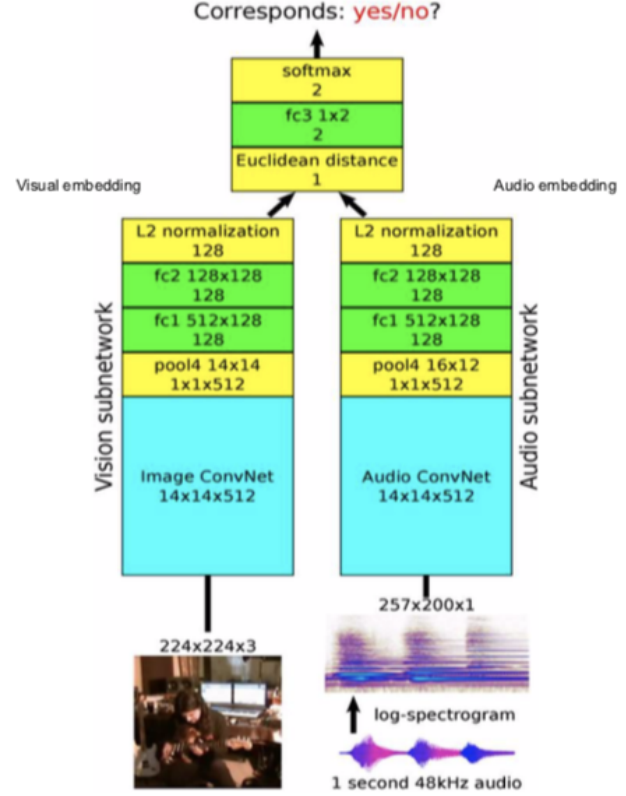
Fig. 12: architettura
Architettura: i frame video vengono passati alla sottorete della visione (vision subnetwork), la traccia del suono alla sottorete dell’auto (audio subnetwork). Entrambe le reti producono una rappresentazione 128-dimensionale. Le due rappresentazioni vengono quindi fuse assieme per risolvere il problema di classificazione binaria concernente la (non) corrispondenza fra le due tracce.
Questa rete può essere utilizzata per prevedere che cosa in quel frame sta producendo un suono. L’intuizione è che, se il suono è prodotto da una chitarra, la rete deve imparare, a grandi linee, come la chitarra è fatta; lo stesso deve valere per la batteria.
Comprendere che cosa viene imparato dal compito di “pretesto”
- I compiti di pretesto dovrebbero essere complementari
- Prendiamo come esempio i compiti di pretesto “Posizionamento relativo” e “Colorazione”. Possiamo migliorarne le performance addestrando un modello ad imparare entrambi i compiti di pretesto, come mostrato di sotto:
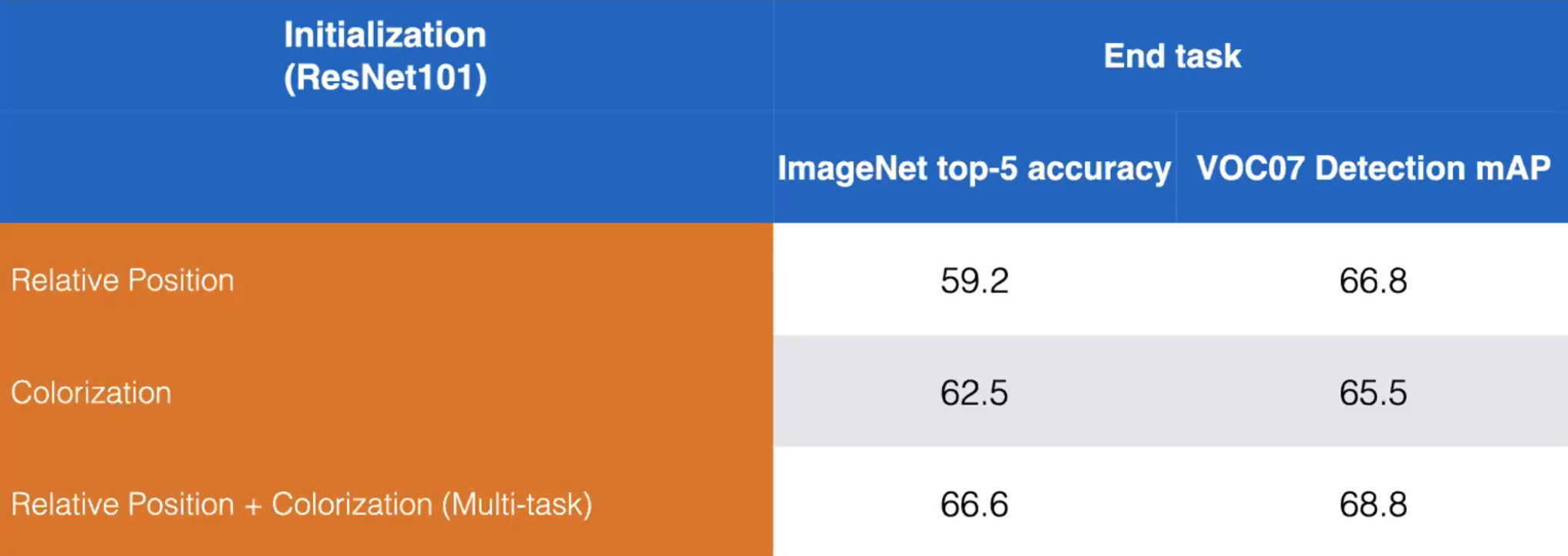
Fig. 13: paragone di addestramento disgiunto vs combinato per i compiti di pretesto "Posizionamento relativo" e "Colorazione". ResNet101. (Misra)
-
Un singolo compito di pretesto potrebbe non essere la soluzione giusta per imparare le rappresentazioni
-
Vi è molta variabilita a livello di difficoltà in ciò che i compiti di pretesto cercano di prevedere
- “Posizione relativa” è una semplice classificazione
- “Riempire i buchi” è molto più difficile (vengono apprese migliori rappresentazioni)
- I metodi contrastivi generano ancora più informazione dei compiti di pretesto
<!– * Relative position is easy since it’s a simple classification
- Masking and fill-in is far harder better representation
-
Contrastive methods generate even more info than pretext tasks –>
-
Domanda: come si addestrano più compiti di pretesto contemporaneamente?
- L’output dipende dall’input. Lo strato densamente connesso della rete può essere scambiato dipendentemente dal tipo del batch.
- Ad esempio: un batch d’immagini in bianco e nero è passato ad una rete con lo scopo di produrre un’immagine a colori. Lo strato finale è cambiato in base al nuovo compito (ad esempio, prevedere la posizione relativa)
Scalare l’addestramento auto-supervisionato
Tecnica del Puzzle
-
Si partiziona un’immagine in più caselle e si mescolano queste ultime. Il compito del modello è quello di ri-mescolare le caselle a formare la configurazione originale dell’immagine (Noorozi & Favaro, 2016).
- Si prevede quale permutazione è stata applicata all’input
- Ciò viene effettuato creando dei batch di caselle in modo tale che ogni casella di un’immagine viene valutata indipendentemente. Gli output delle reti sono quindi concatenati e la permutazione viene prevista come dalla figura sotto.
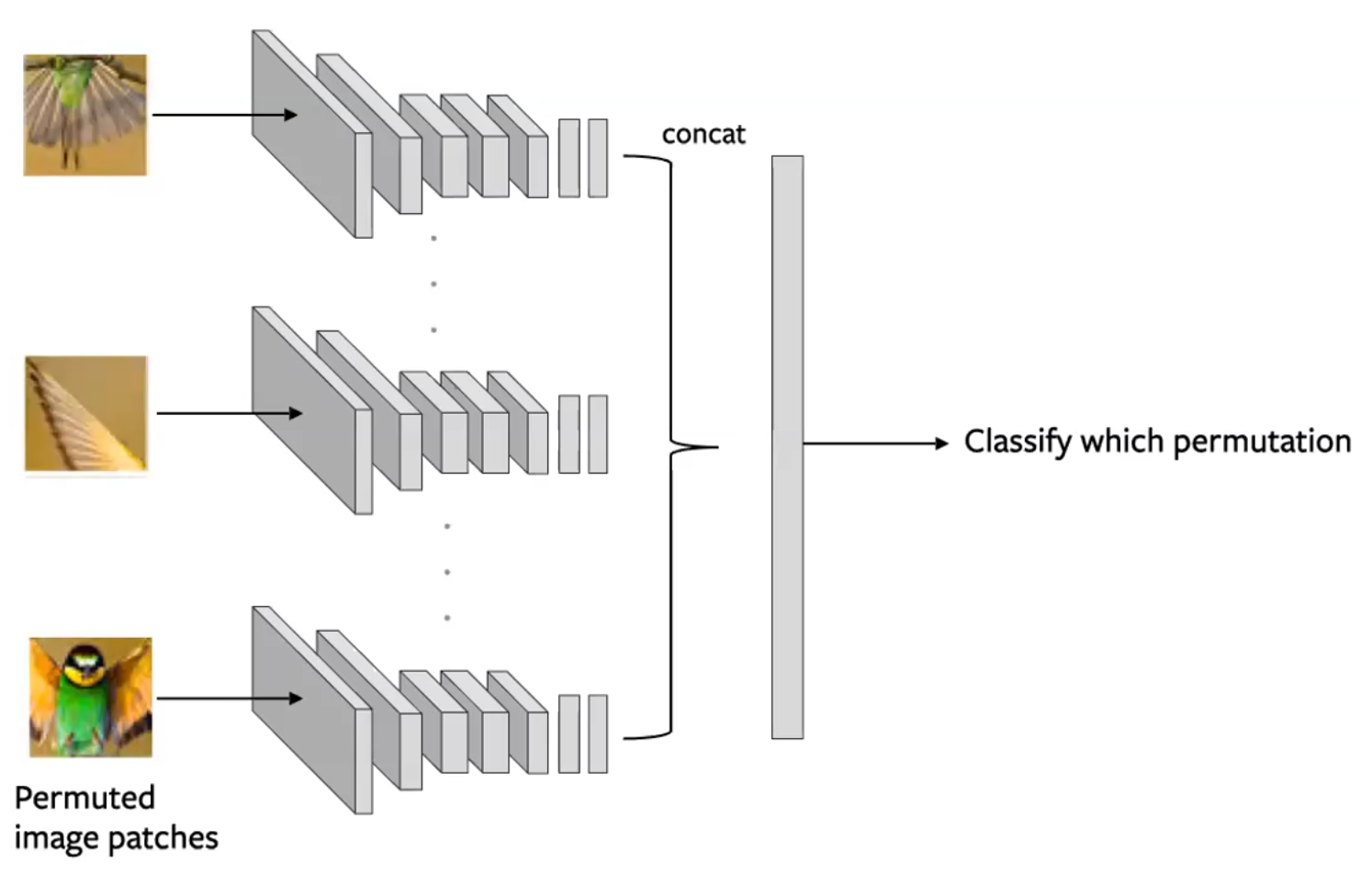
Fig. 14: architettura di rete siamese per un compito di pretesto del tipo Puzzle. Ogni casella è valutata indipendentemente, e le codifiche sono concatenate a prevedere una permutazione. (Misra)
- Considerazioni:
- Usare un sottoinsieme di tutte le possibili permutazioni (es.: se si dispongono $9!$ permutazioni, se ne usino 100)
- Le reti convoluzionali a n vie utilizzano parametri condivisi
- La complessità del problema coincide con la dimensione del sottoinsieme, l’ammontare d’informazione che si sta prevedendo
- A volte, questo metodo può dare performance migliori sui compiti downstream rispetto ai metodi supervisionati, in quanto la rete è in grado di imparare alcuni concetti relativi alla geometria dell’input.
- Difetti: apprendimento few shot: numero limitato di esempi di addestramento
- Le rappresentazioni ottenute tramite apprendimento auto-supervisionato non sono efficienti dal punto di vista del campionamento
Valutazione: affinamento vs classificazione lineare
Questa forma di valutazione è una specie di Apprendimento per trasferimento.
-
Affinamento (fine-tuning): per risolvere il compito downstream, si utilizza un’intera rete pre-addestrata come inizializzazione. Questa rete viene addestrata in toto, aggiornandone i pesi.
-
Classificazione lineare: in cima alla rete di pretesto, si addestra un piccolo classificatore lineare per portare a fine il compito downstream, lasciando intatto il resto della rete.
Una buona rappresentazione dovrebbe trasferirsi con poco apprendimento.
- È di aiuto valutare il compito di pretesto su una moltitudine di compiti differenti. Possiamo farlo estraendo le rappresentazioni create da diversi strati della rete, trattando queste rappresentazioni come caratteristiche fisse e andando a valutare la loro utilità attraverso questi compiti di diversa natura:
- Misurazione: Mean Average Precision (MAP) – La media della precisione attraverso tutti i compiti considerati.
- Alcuni esempi di questi compiti: riconoscimento di oggetti (object recognition) utilizzando l’affinamento, stima della superficie (Surface Normal Estimation – si veda il dataset NYU-v2).
- Che cosa viene appreso da ogni strato?
- Generalmente, più profondo è lo strato all’interno della rete, più alta è la MAP dei compiti downstream portati a termine utilizzando le rappresentazioni dello stesso strato.
- Tuttavia, sullo strato finale si noterà un calo notevole nella MAP a causa della sovra-specializzazione dello strato.
- Questo si contrappone alle reti addestrate in maniera supervisionata, dove si nota un generale aumento della MAP all’aumentare della profondità dello strato.
- Ciò mostra che il compito di pretesto non è ben allineato con il compito downstream.
📝 Aniket Bhatnagar, Dhruv Goyal, Cole Smith, Nikhil Supekar
Marco Zullich
6 Apr 2020