Architettura delle RNNs e modelli LSTM
🎙️ Alfredo CanzianiPanoramica
RNN è un tipo di architettura che possiamo utilizzare per gestire sequenze di dati. Cos’è una sequenza? Dalla lezione sulle CNN, abbiamo appreso che un segnale può essere 1D, 2D o 3D a seconda del dominio. Il dominio è definito dall’insieme di elementi di partenza che vogliamo tradurre all’insieme di elementi di arrivo, cioè da e verso cosa stiamo mappando. La gestione dei dati sequenziali ha a che fare essenzialmente con i dati 1D poiché il dominio consiste solo in input temporali di X. Tuttavia, puoi anche utilizzare RNN per gestire i dati 2D, dove hai due direzioni.
NN semplici vs. NN ricorrenti
La Figura 1 mostra un diagramma di rete neurali semplici (vanilla) a tre strati. “Vanilla” è un termine americano che significa semplice. La bolla rosa è il vettore di input x, al centro è lo strato nascosto in verde e il livello blu finale è l’output. Utilizzando un esempio dell’elettronica digitale sulla destra, possiamo vederlo come una logica combinatoria in cui l’uscita corrente dipende solo dall’ingresso corrente.

Figura 1: Architettura semplice
Contrariamente a una rete neurale semplice, nelle reti neurali ricorrenti l’uscita corrente dipende non solo dall’ingresso corrente ma anche dallo stato del sistema, mostrato in Figura 2. Quest’ultimo si può interpretare come una logica sequenziale nell’elettronica digitale, dove anche l’uscita dipende da un “flip-flop” (un’unità di memoria di base nell’elettronica digitale). Pertanto la differenza principale qui è che l’output di una rete neurale semplice dipende solo dall’input corrente, mentre quello di RNN dipende anche dallo stato del sistema.

Figura 3: Architettura RNN

Figura 4: Basic NN Architecture
Il diagramma di Yann aggiunge queste forme tra i neuroni per rappresentare la mappatura tra un tensore e un altro (un vettore all’altro). Ad esempio, nella Figura 3, il vettore di input x eseguirà la mappatura attraverso elemento aggiuntivo alla rappresentazione nascosta h. Questo oggetto è in realtà una trasformazione affine, cioè una rotazione più una distorsione. Quindi attraverso un’altra trasformazione, passiamo dallo strato nascosto all’output finale. Allo stesso modo, nel diagramma RNN, puoi avere gli stessi elementi aggiuntivi tra i neuroni.
Quattro tipi di architetture ed esempi di RNNs
Il primo caso è da vettore a sequenza. L’input è una bolla e poi ci saranno evoluzioni dello stato interno del sistema annotate come bolle verdi. Man mano che lo stato del sistema si evolve, ci sarà un output specifico ad ogni specifico momento.
Un esempio di questo tipo di architettura è avere un’immagine come input mentre l’output sarà una sequenza di parole che rappresentano la descrizione - in inglese - dell’immagine di input. Guardando la Figura 6, ogni bolla blu qui può essere un indice per un dizionario di parole inglesi. Ad esempio, se l’output è la frase “Questo è uno scuolabus giallo”. Prima ottieni l’indice della parola “Questo”, quindi ottieni l’indice della parola “è” e così via. Alcuni dei risultati di questa rete sono mostrati di seguito. Ad esempio, nella prima colonna la descrizione relativa all’ultima foto è “Una mandria di elefanti che cammina attraverso un campo di erba secca”, che è molto ben rifinita. Quindi nella seconda colonna, la prima immagine mostra “Due cani giocano nell’erba”, mentre in realtà sono tre cani. Nell’ultima colonna ci sono esempi più sbagliati come “Uno scuolabus giallo parcheggiato in un parcheggio”. In generale, questi risultati mostrano che questa rete possa fallire drasticamente e funzionare bene certe volte. Questo esempio rappresenta il caso in cui si parte da un vettore di input, che è la rappresentazione di un’immagine, a una sequenza di simboli, che sono ad esempio caratteri o parole che compongono le frasi inglesi. Questo tipo di architettura è chiamata rete autoregressiva. Una rete autoregressiva è una rete che fornisce un output prodotto dal ricevere in input l’output del passo precedente.

Figura 6: Esempio da vettore a sequenza: da immagine a testo
Il secondo tipo si ha partendo da una sequenza e arrivando ad un vettore finale. Questa rete continua a ricevere una sequenza di simboli e solo alla fine fornisce un output finale. Un’applicazione di questo può usare la rete per interpretare Python. Ad esempio, in ingresso si possono avere righe di codice Python come queste.

Figura 7: Da sequenza a vettore

Figura 8: Linee di codice Python in ingresso
Quindi la rete sarà in grado di generare la soluzione corretta a questo programma. Un altro programma più complicato come questo:

Figura 9: Linee di codice Python in ingresso in un caso più complicato
Quindi l’output dovrebbe essere 12184. Questi due esempi mostrano che è possibile addestrare una rete neurale per eseguire questo tipo di operazione. Dobbiamo solo alimentare una sequenza di simboli e imporre che l’output finale sia un valore specifico.
Il terzo esempio è da una sequenza ad un vettore e poi di nuovo a sequenza, mostrata in Figura 10. Questa architettura era il modo standard di eseguire traduzioni linguistiche. Inizi con una sequenza di simboli qui mostrati in rosa. Quindi tutto viene condensato in questa h finale, la quale rappresenta un concetto. Ad esempio, possiamo avere una frase come input e comprimerla temporaneamente in un vettore, che rappresenta il significato e il messaggio da inviare. Quindi, dopo aver ottenuto questo significato in qualunque rappresentazione, la rete lo srotola in una lingua diversa. Ad esempio “Today I’m very happy” (“Oggi sono molto felice”) in una sequenza di parole in inglese che possono essere tradotte in italiano o cinese. In generale, la rete ottiene una sorta di codifica come input e li trasforma in una rappresentazione compressa. Infine, esegue la decodifica data la stessa versione compressa. Negli ultimi tempi abbiamo visto reti come il Transformatore (Transformer), che tratteremo nella prossima lezione, sovraperformare questo metodo nelle attività di traduzione linguistica. Questo tipo di architettura era lo stato dell’arte all’incirca due anni fa (2018).
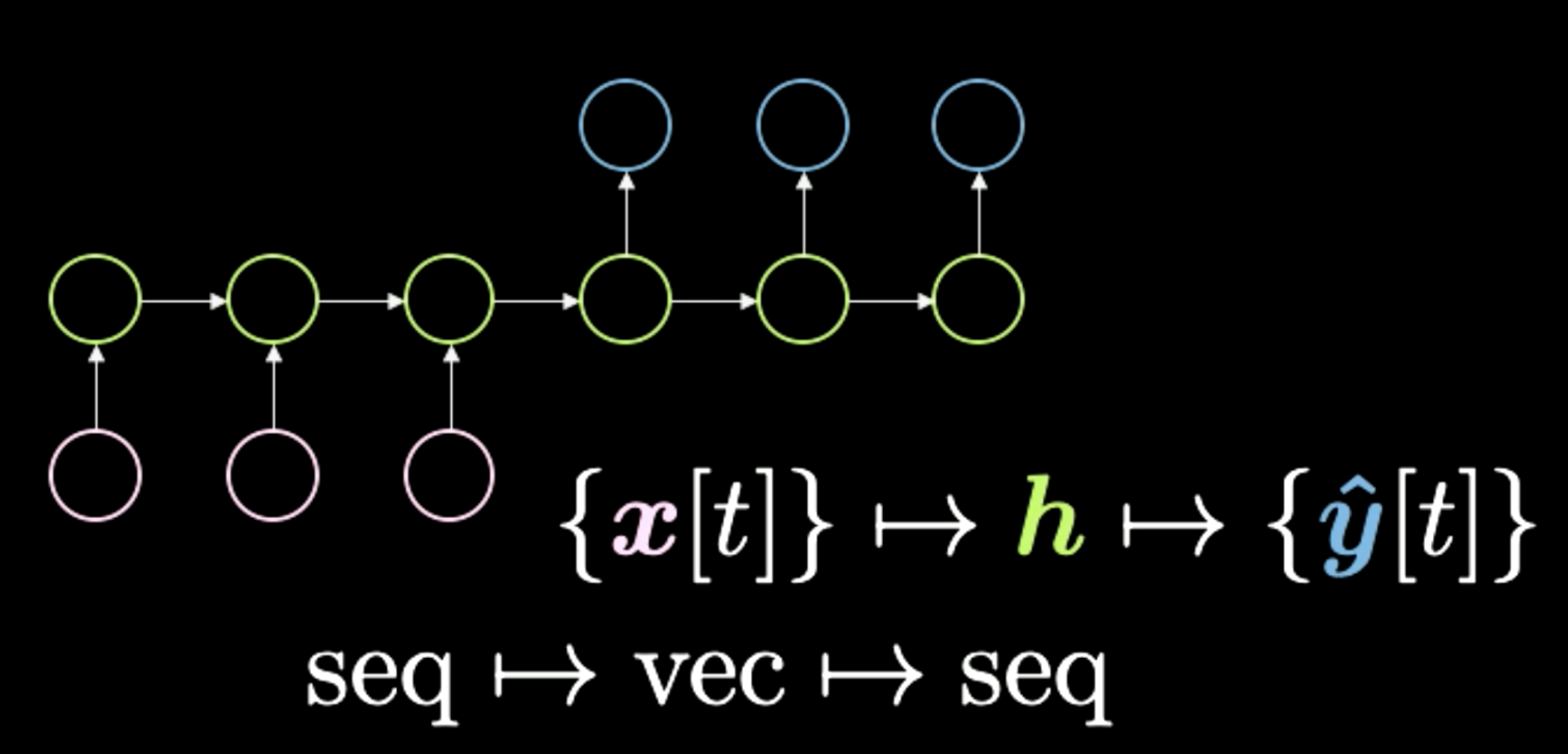
Figura 10: da sequenza a vettore a sequenza
Se eseguiamo un PCA nello spazio latente, otteremo le parole raggruppate per semantica come mostrato in questo grafico.

Figura 11: Parole raggruppate secondo la semantica dopo una PCA
Se ingrandiamo, vedremo che nella stessa posizione ci sono tutti i mesi, come gennaio e novembre.
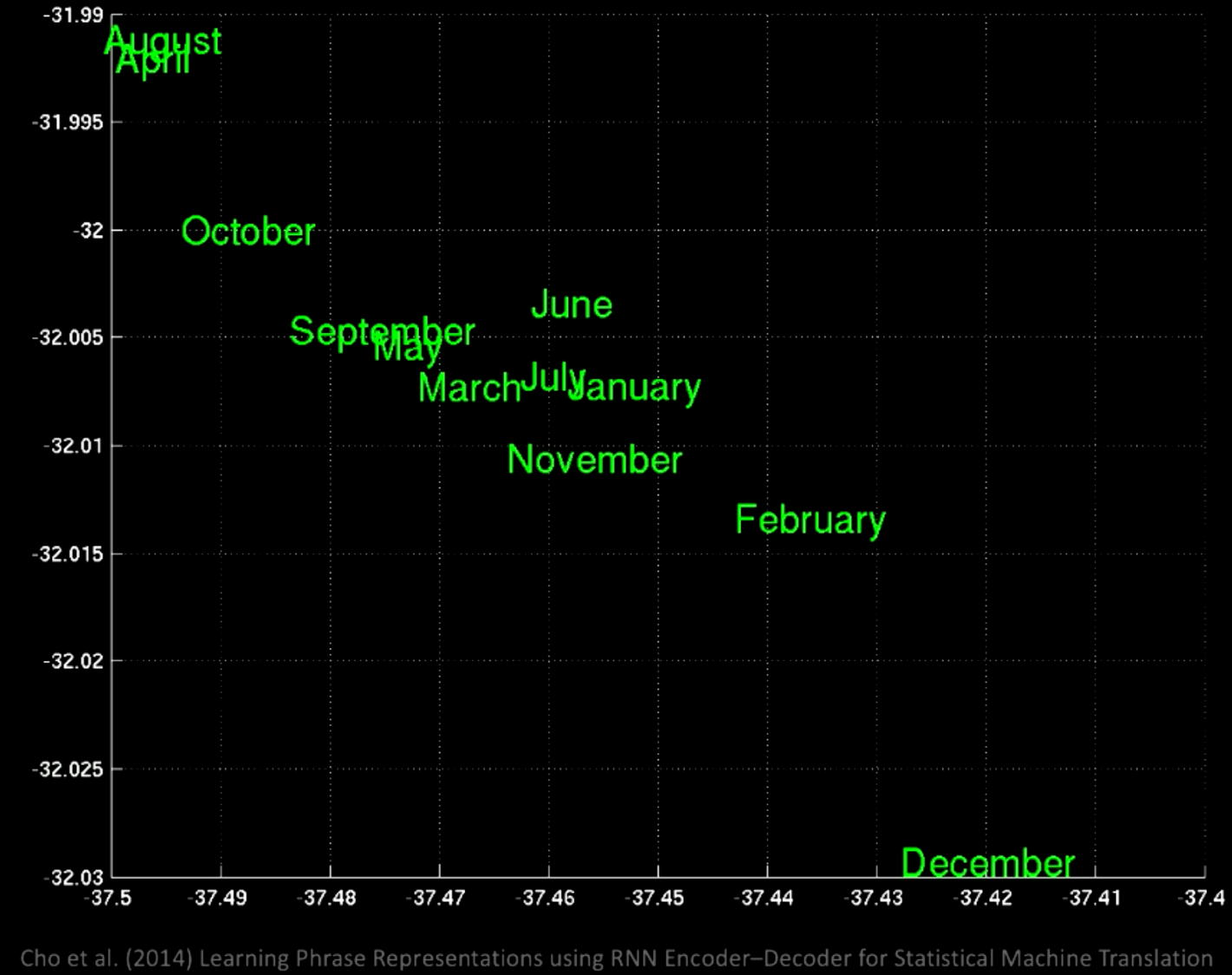
Figura 12: Gruppi di parole visti da vicino
Se ci concentriamo su una regione diversa, troviamo frasi come “pochi giorni fa”, “i prossimi mesi”, ecc.

Figura 13: Gruppe di parole in un'altra regione
Da questi esempi vediamo che posizioni diverse avranno alcuni specifici significati in comune.
La Figura 14 mostra come l’addestramento di questo tipo di rete rileverà alcune features semantiche. Per esempio, in questo caso puoi vedere che esiste un vettore che collega l’uomo alla donna e un altro tra re e regina, il che significa che la donna meno l’uomo sarà uguale alla regina meno il re. Si ottiene la stessa distanza in questo embedding applicato a casi come “maschio-femmina”. Un altro esempio sarà “camminare” per “camminato” e “nuotare” per “nuotato”. Puoi sempre applicare questo tipo di specifica trasformazione lineare che va da una parola all’altra o da un paese alla sua capitale.
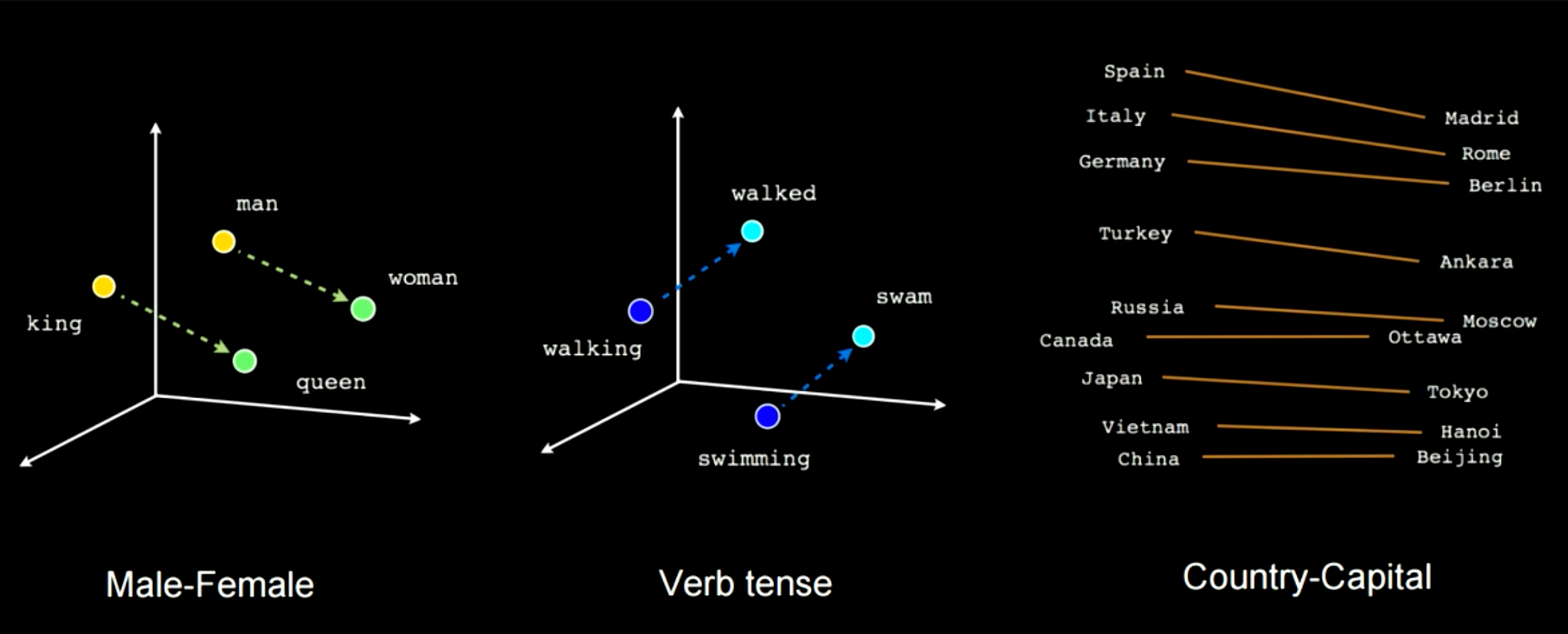
Figura 14: Caratteristiche semantiche apprese durante l'addestramento
Il quarto e ultimo caso è da sequenza a sequenza. In questa rete, quando si inizia a dare input alla rete, questa inizia subito a generare output. Un esempio di questo tipo di architettura è il celebre T9, se ricordi di aver utilizzato un telefono Nokia, si ricevevano suggerimenti di testo durante la digitazione. Un altro esempio è la traduzione “conversazione a didascalia”. Un bell’esempio è la “RNN scrittore”. Quando inizi a digitare “gli anelli di Saturno luccicano mentre”, suggerisce quanto segue “due uomini si guardarono l’un l’altro”. Questa rete è stata formata su alcuni romanzi di fantascienza in modo che tu possa semplicemente scrivere qualcosa e lasciarti dare suggerimenti per aiutarti a scrivere un libro. Un altro esempio è mostrato nella Figura 16. Inserisci il prompt principale e quindi questa rete proverà a completare il resto.

Figura 15: Sequenza a Sequenza

Figura 16: Modello di completamento automatico del testo di un modello sequenza a sequenza
Retropropagazione nel tempo
Architettura del Modello
Per addestrare un RNN, è necessario utilizzare la retroprogazione nel tempo (BPTT, BackPropagation Through Time). L’architettura del modello di RNN è riportata nella figura seguente. Il design di sinistra utilizza la rappresentazione del ciclo mentre la figura a destra srotola il ciclo in un riga unica nel tempo.

Figura 17: Retropropagazione nel tempo
Le rappresentazioni nascoste sono indicate come:
\[\begin{aligned} \begin{cases} h[t]&= g(W_{h}\begin{bmatrix} x[t] \\ h[t-1] \end{bmatrix} +b_h) \\ h[0]&\dot=\ \boldsymbol{0},\ W_h\dot=\left[ W_{hx} W_{hh}\right] \\ \hat{y}[t]&= g(W_yh[t]+b_y) \end{cases} \end{aligned}\]La prima equazione indica una funzione non lineare applicata ad una rotazione di una versione dello stack di input in cui viene aggiunta la configurazione precedente del livello nascosto. All’inizio $h[0]$ è impostato a 0. Per semplificare l’equazione, $W_h$ può essere scritto come due matrici separate, $\left[W_{hx}\ W_{hh}\right]$, quindi a volte la trasformazione può essere dichiarata come:
\[W_{hx}\cdot x[t]+W_{hh}\cdot h[t-1]\]che corrisponde alla rappresentazione dello stack dell’input.
Batch-ificazione nella modellazione del linguaggio
Quando si ha a che fare con una sequenza di simboli, possiamo raggruppare il testo in diverse dimensioni. Ad esempio, quando si ha a che fare con le sequenze mostrate nella figura seguente, è possibile applicare prima la batch-ificazione, in cui il dominio del tempo viene conservato verticalmente. In questo caso, la dimensione del batch è impostata su 4.

Figura 18: Batch-ificazione
Se il periodo BPTT $T$ è impostato su 3, il primo input $x[1:T]$ e output $y[1:T]$ per RNN è determinato come:
\[\begin{aligned} x[1:T] &= \begin{bmatrix} a & g & m & s \\ b & h & n & t \\ c & i & o & u \\ \end{bmatrix} \\ y[1:T] &= \begin{bmatrix} b & h & n & t \\ c & i & o & u \\ d & j & p & v \end{bmatrix} \end{aligned}\]Quando eseguiamo RNN sul primo batch, in primo luogo, diamo $x[1] = [a\ g\ m\ s]$ in ingresso alla RNN e forziamo l’output a $y[1] = [b\ h\ n\ t]$. La rappresentazione nascosta $h[1]$ verrà inviata nel passaggio successivo per aiutare l’RNN a prevedere $y[2]$ da $x[2]$. Dopo aver inviato $h[T-1]$ al set finale di $x[T]$ e $y[T]$, viene tagliato il processo di propagazione del gradiente sia per $h[T]$ che per $h[0]$ in maniera tale che i gradienti non si propagheranno all’infinito (.detach () in Pytorch). L’intero processo è mostrato nella figura seguente.

Figura 19: Batch-Ificazione
Scomparsa ed Esplosione del Gradiente
Problema
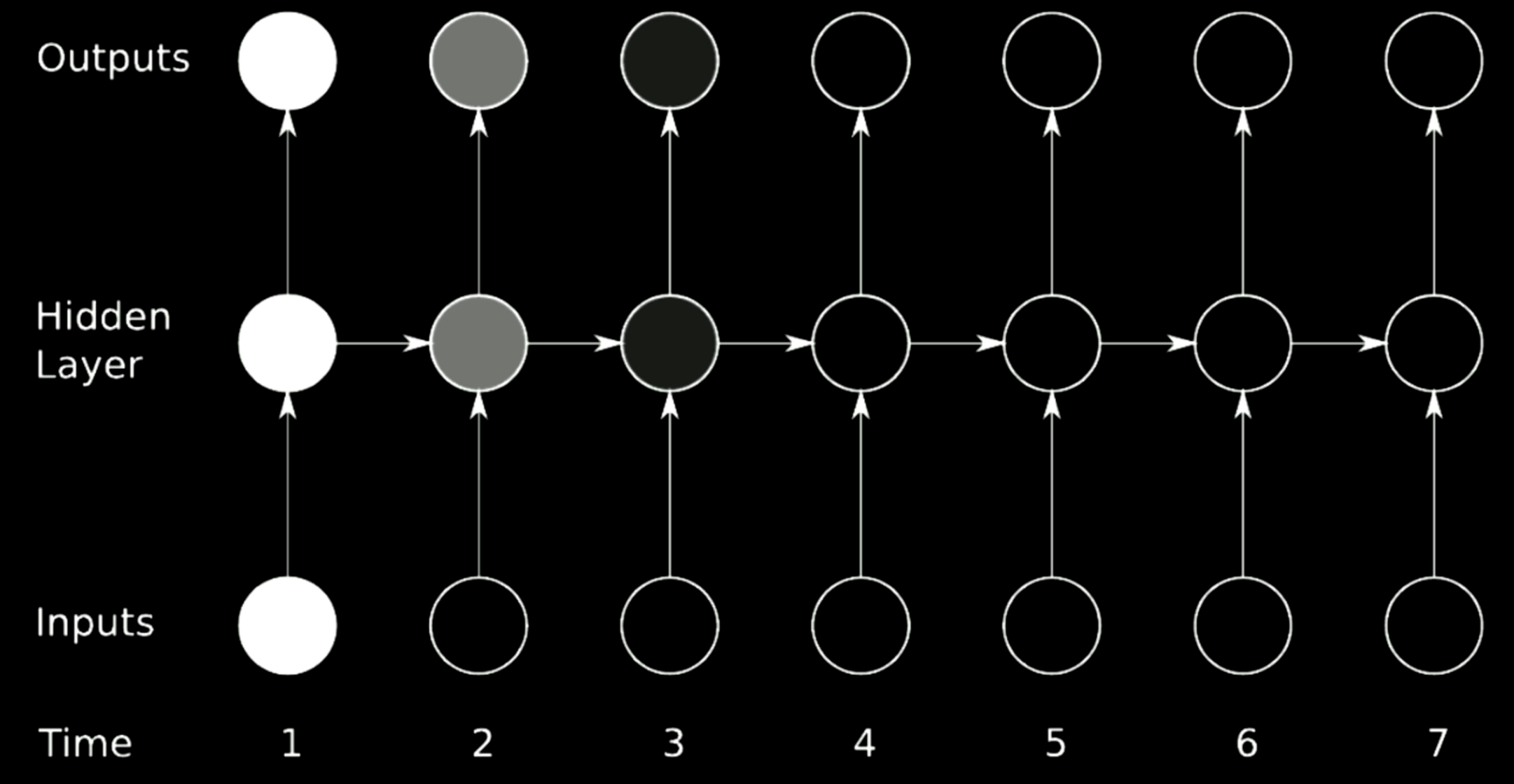
Figura 20: Scomparsa del gradiente
La figura sopra è una tipica architettura RNN. Per eseguire la rotazione sui passaggi precedenti in una RNN, utilizziamo le matrici, che possono essere indicate con le frecce orizzontali nel modello sopra. Poiché le matrici possono modificare le dimensioni degli output, se il determinante che selezioniamo è maggiore di 1, il gradiente si gonfia nel tempo arrivando a provocare un’esplosione del gradiente. Relativamente parlando, se l’autovalore che selezioniamo è piccolo vicino 0, il processo di propagazione ridurrà i gradienti e porterà alla scomparsa del gradiente.
In tipiche RNNs, i gradienti saranno propagati attraverso tutte le possibili frecce, il che fornisce ai gradienti una grande possibilità di scomparire od esplodere. Ad esempio, il gradiente al tempo 1 è grande, indicato dal colore brillante. Quando attraversa una rotazione, il gradiente diminuisce di molto e al passo temporale 3 viene ucciso.
Soluzione
Un metodo ideale per evitare che l’esplosione o la scomparsa del gradiente è quello di saltare le connessioni (dall’inglese “skip connection”). A tale scopo, è possibile utilizzare reti di moltiplicazioni.
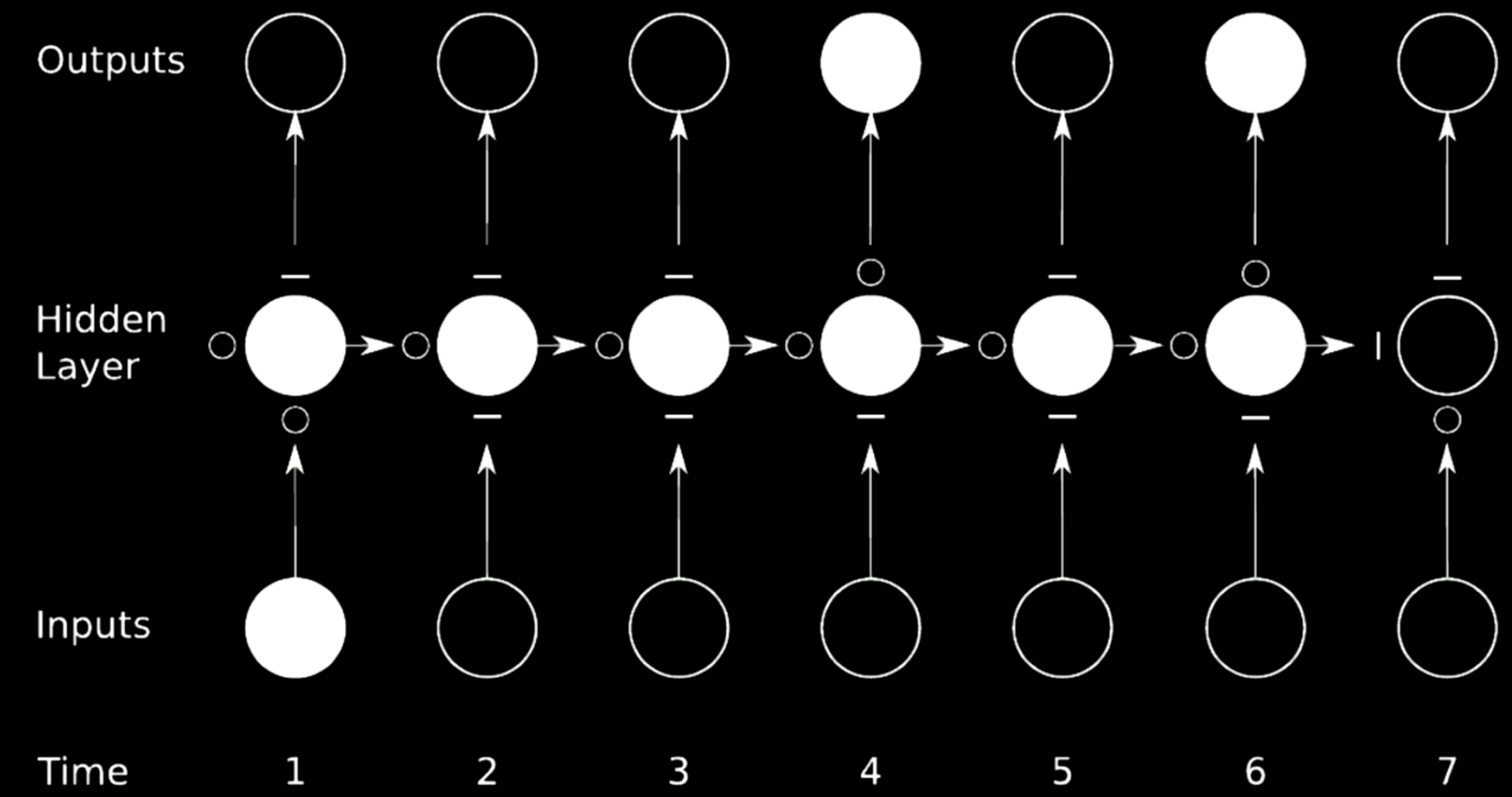
Figura 21: Connessione diretta (Skip connection)
Nota per il revisore: gated recurrent network non è facile da tradurre. Nel caso sopra, abbiamo diviso la rete originale in 4 reti. Prendi la prima rete per esempio. Prende un valore dall’input al tempo 1 e invia l’output al primo stato intermedio nel layer nascosto. Lo stato ha altre 3 reti in cui $\circ$s consente il passaggio dei gradienti mentre $-$s blocca la propagazione. Tale tecnica si chiama gated recurrent network (rete ricorrente “con porte logiche”)
La LSTM è la principale RNN gated ed è introdotta in dettaglio nelle sezioni seguenti.
Long Short-Term Memory
Architettura del Modello
Di seguito sono riportate le equazioni che descrivono una LSTM. La porta di input è evidenziata da caselle gialle, che saranno una trasformazione affine. Questa trasformazione di input moltiplicherà $c [t]$, che è la nostra porta candidato.
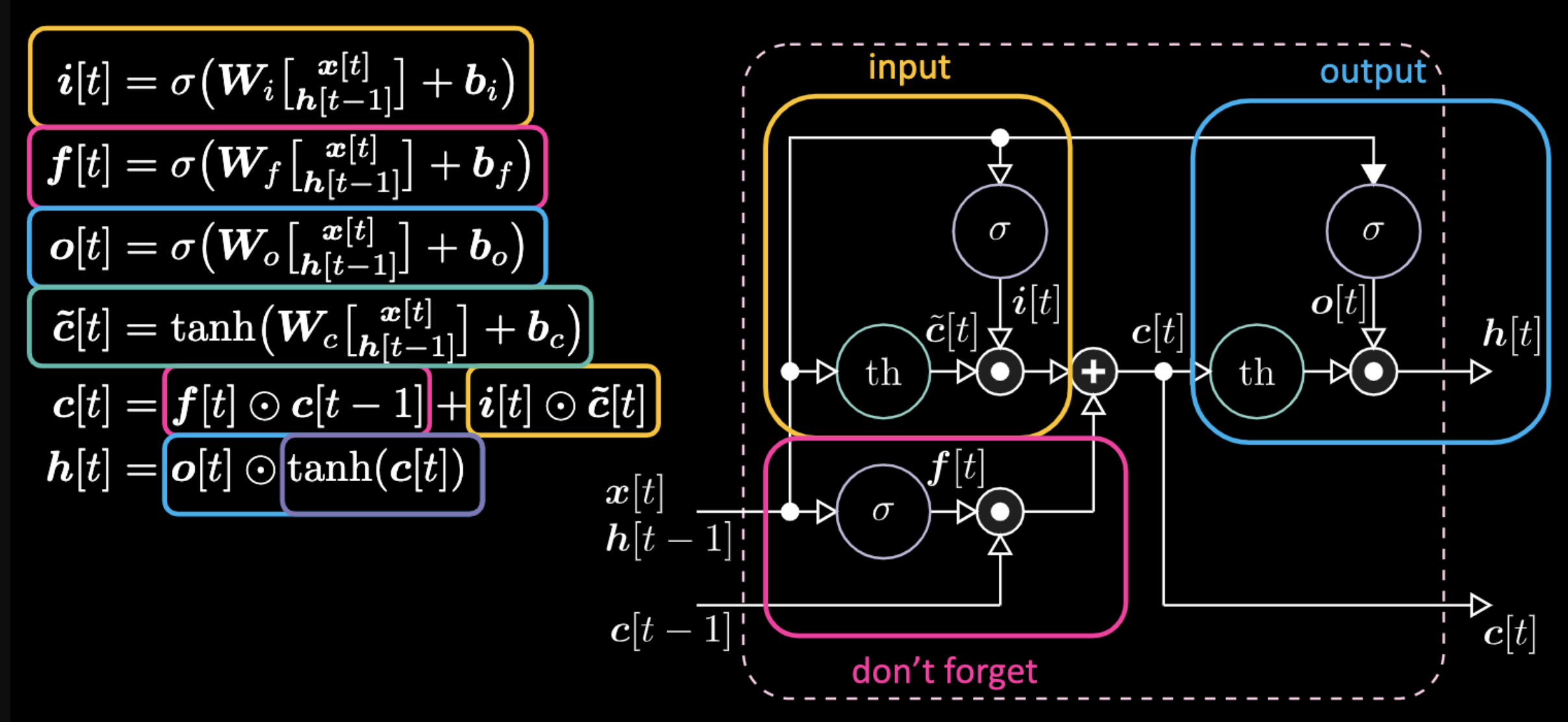
Figura 22: Architectura di una LSTM
nota per il revisore: forget gate and candidate gate possono essere cambiate se non suonano bene come sono tradotte qui. La porta per “non dimenticare” sta moltiplicando il valore precedente della memoria della cella $c[t-1]$. Il valore totale della cella $c[t]$ è uguale al valore della cella per non dimenticare più la porta di ingresso. La rappresentazione nascosta finale è la moltiplicazione dell’elemento tra la porta di output $o[t]$ e la versione in tangente iperbolica della cella $c[t]$, in modo tale che le cose siano limitate. Infine, la porta candidata $\tilde{c}[t]$ è semplicemente una rete ricorrente. Quindi abbiamo $o[t]$ per modulare l’output, $f[t]$ per modulare la porta per non dimenticare e $i[t]$ per modulare la porta di input. Tutte queste interazioni tra memoria e porte sono interazioni moltiplicative. $i[t]$, $f[t]$ e $o[t]$ sono tutte sigmoidi, che vanno da zero a uno. Quindi, moltiplicando per zero, ottieni una porta chiusa. Quando si moltiplica per uno, al contrario, ottieni una porta aperta.
Come disattiviamo l’output? Diciamo che abbiamo una rappresentazione interna viola $th$ e mettiamo uno “zero” nella porta di uscita. Quindi l’output sarà zero moltiplicato per qualcosa e otterremo uno zero. Se ne inseriamo un “uno” nella porta di output, otterremo lo stesso valore della rappresentazione viola.
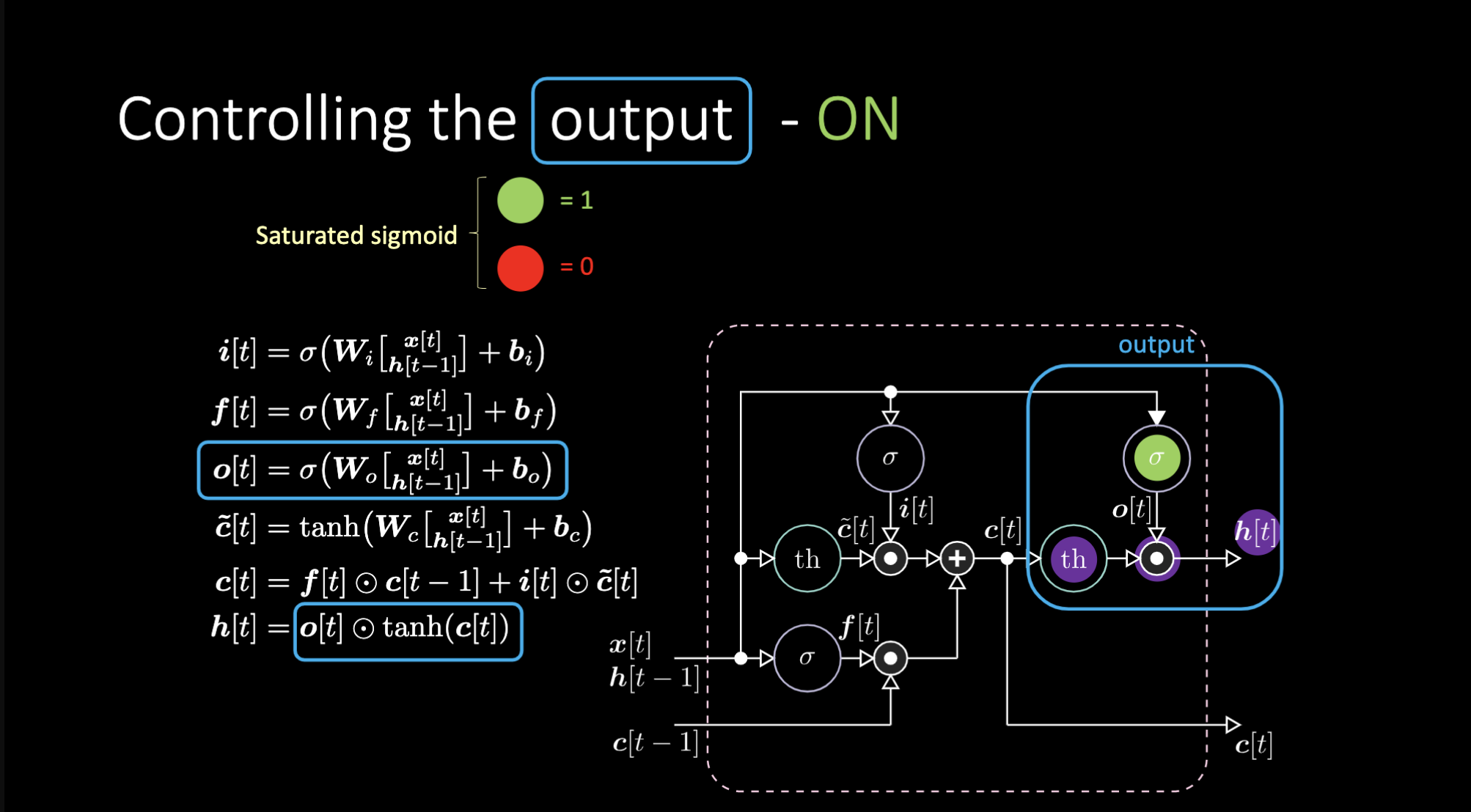
Figura 23: Architettura LSTM - Output attivo
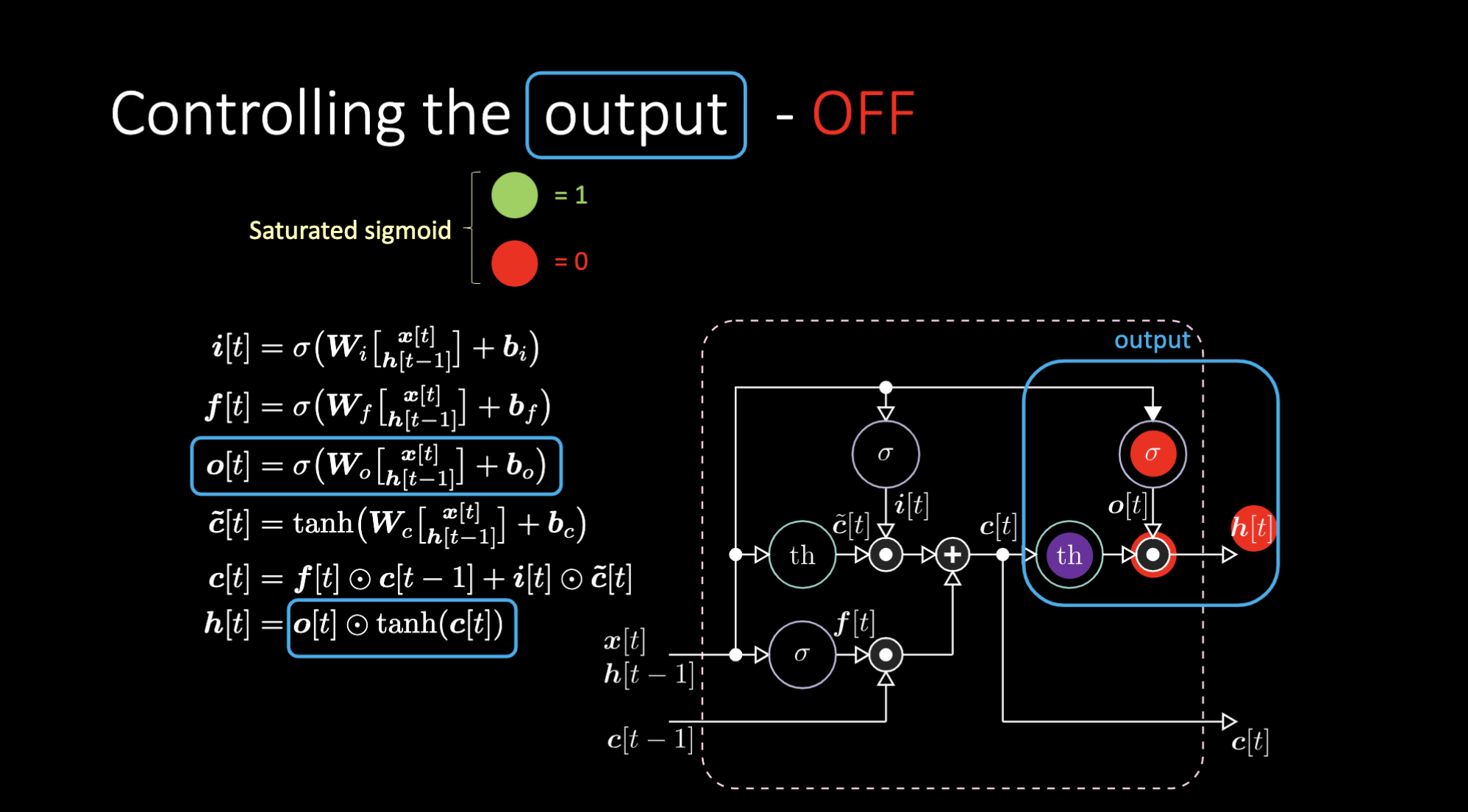
Figura 24: Architectura LSTM - Output non attivo
Allo stesso modo, possiamo controllare la memoria. Ad esempio, possiamo resettarlo settando $f[t]$ e $i[t]$ a zero. Dopo la moltiplicazione e la somma, abbiamo uno zero nella memoria. Altrimenti, possiamo conservare la memoria, annullando comunque la rappresentazione interna $th$ ma mantenendone una in $f[t]$. Quindi, la somma ottiene $c[t-1]$ e continua a inviarlo in output. Infine, possiamo scrivere in modo tale da poterne ottenere “uno” nella porta di input, la moltiplicazione diventa viola, quindi impostare uno zero nella porta per non dimenticare in modo che effettivamente dimentichi l’informazione.
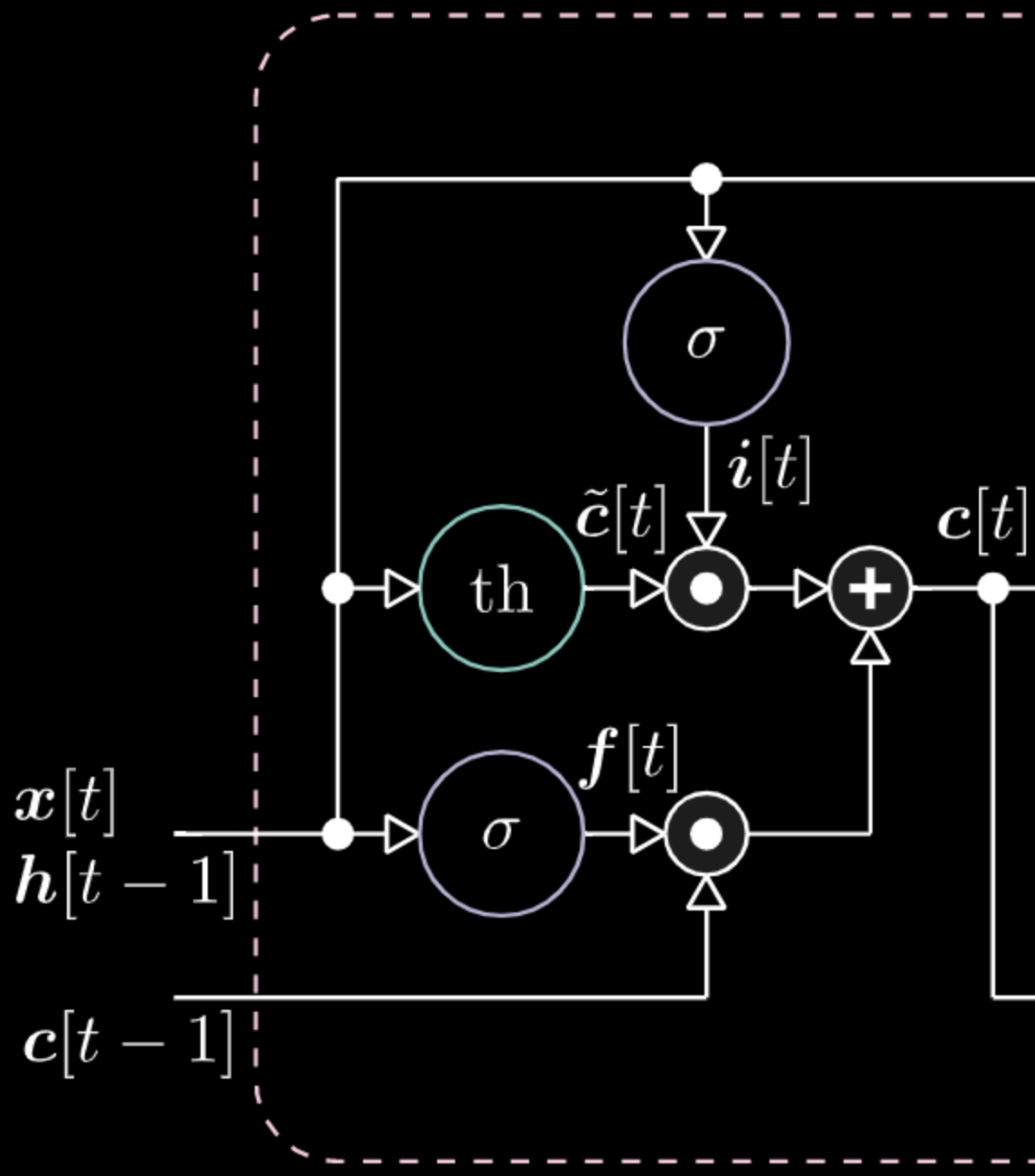
Figura 25: Visualizazione di una cella di memoria
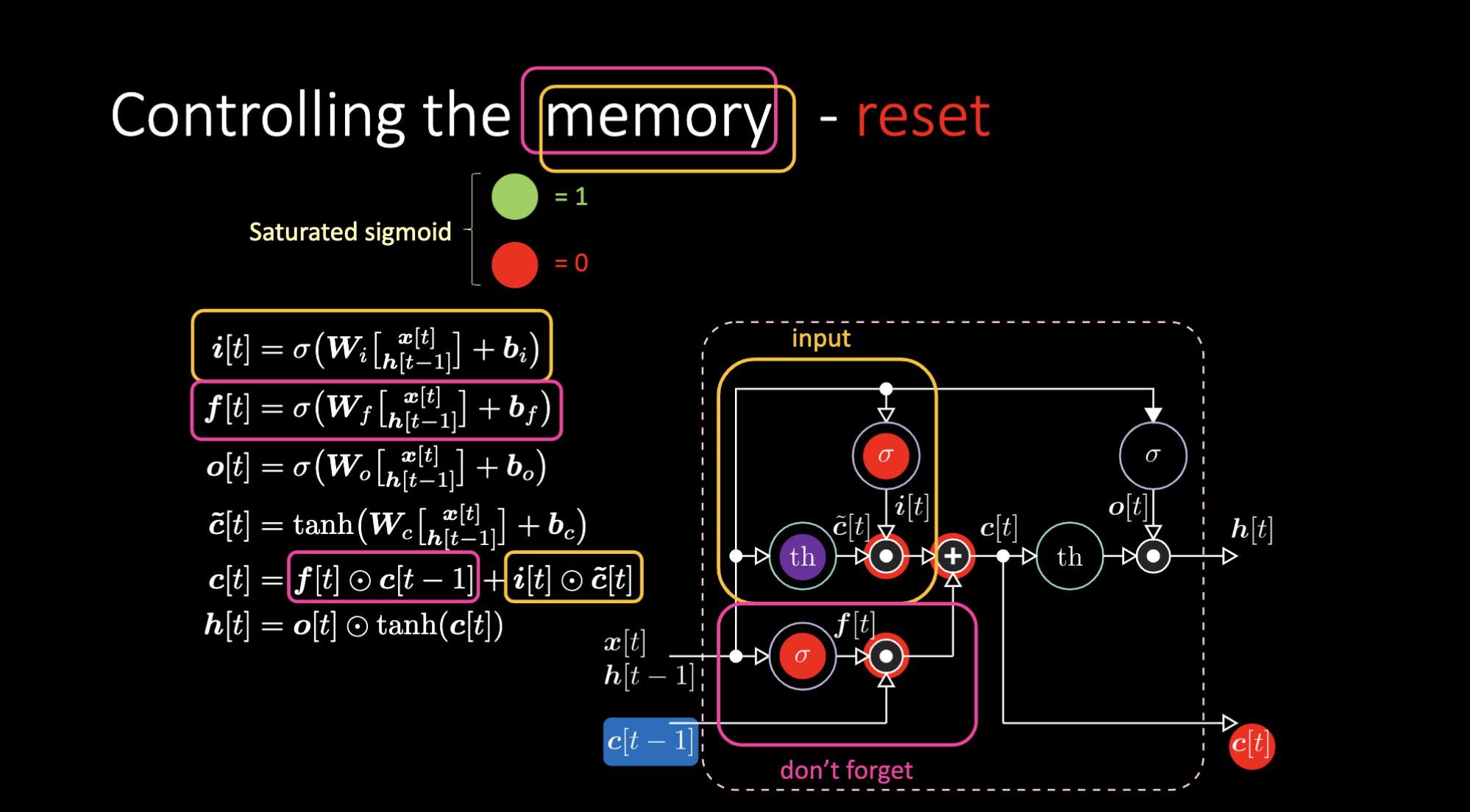
Figura 26: Architettura LSTM - ripristino della memoria
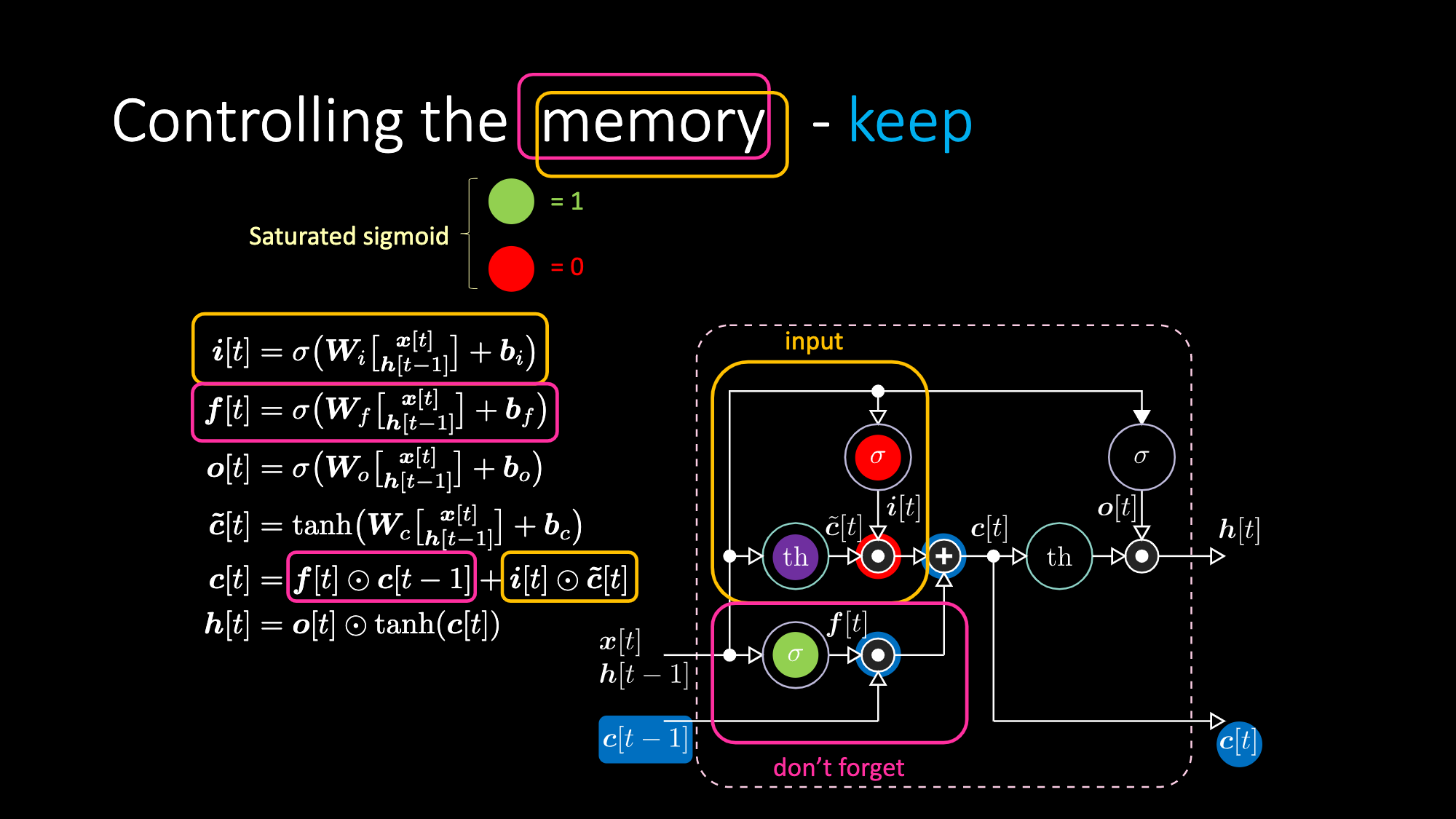
Figura 27: Architettura LSTM - conservare la memoria
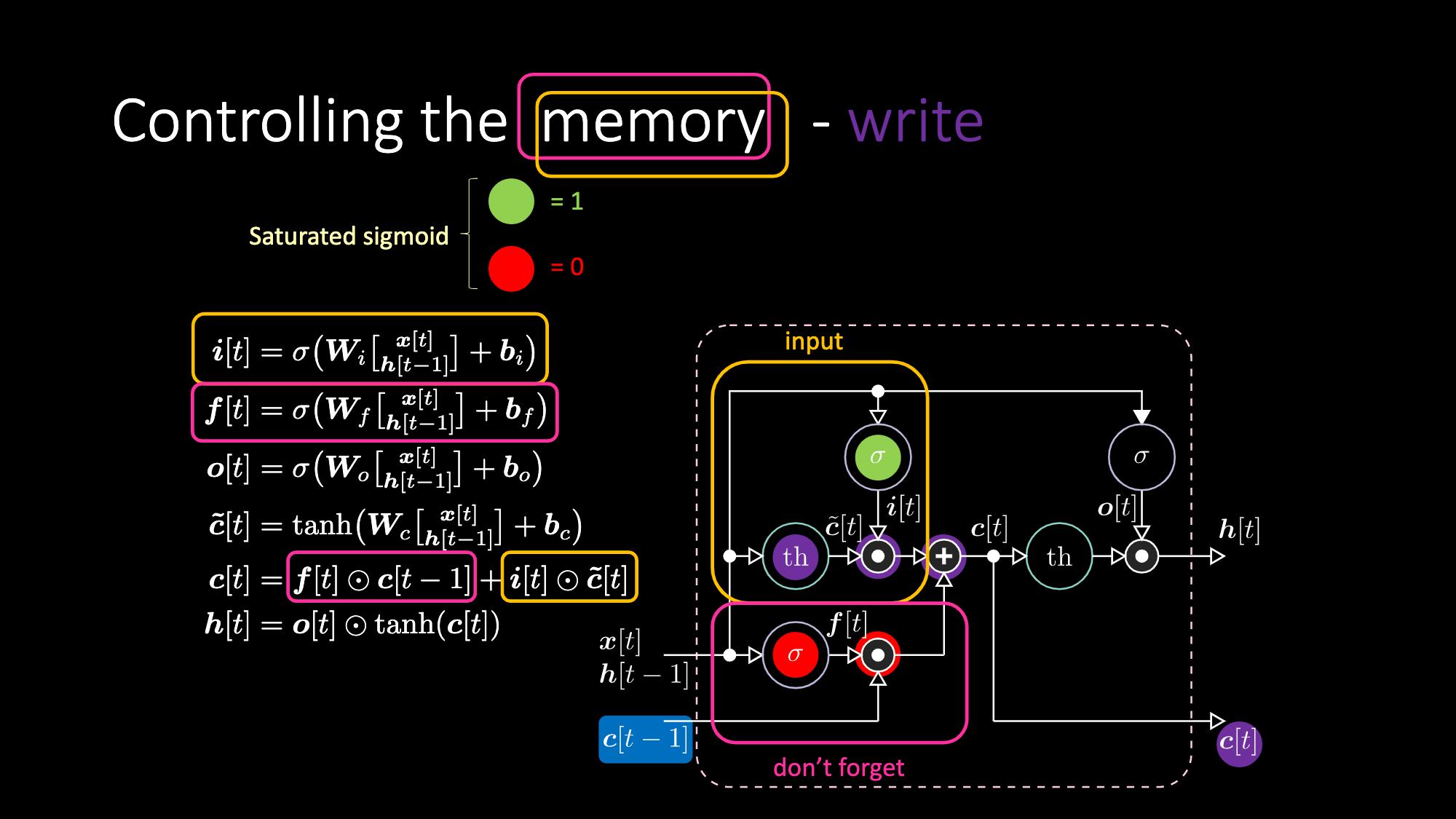
Figura 28: Architettura LSTM - Scrittura della memoria
Esempi del notebook
Classificazioni di sequenze
L’obiettivo è classificare le sequenze. Gli elementi e gli obiettivi sono rappresentati localmente (vettori di input con un solo bit diverso da zero). La sequenza comincia con una B e termina con una E (il “simbolo di innesco”), e altrimenti consiste in simboli scelti casualmente dall’insieme {a, b, c , d}, ad eccezione di due elementi nelle posizioni $t_1$ e $t_2$ che sono X o Y. Per il caso DifficultyLevel.HARD, la lunghezza della sequenza viene scelta casualmente tra 100 e 110, $t_1$ viene scelta casualmente tra 10 e 20 e $t_2$ viene scelta casualmente tra 50 e 60. Ci sono 4 classi di sequenza Q,R, S e U, che dipendono dall’ordine temporale di X e Y. Le regole sono: X, X -> Q; X, Y -> R; Y, X -> S; Y, Y -> U.
1). Esplorazione del dataset
Il tipo restituito da un generatore di dati è una tupla con lunghezza 2. Il primo elemento nella tupla è il batch di sequenze con forma $ (32, 9, 8) $. Questi sono i dati che verranno inseriti nella rete. Ci sono otto simboli diversi in ogni riga (X, Y, a, b, c, d, B, E). Ogni riga è un vettore a uno caldo. Una sequenza di righe rappresenta una sequenza di simboli. Il primo aLa riga zero-zero è il riempimento. Usiamo il riempimento quando la lunghezza della sequenza è inferiore alla lunghezza massima nel batch. Il secondo elemento nella tupla è il corrispondente batch di etichette di classe con forma $ (32, 4) $, poiché abbiamo 4 classi (Q, R, S e U). La prima sequenza è: BbXcXcbE. Quindi la sua etichetta di classe decodificata è $ [1, 0, 0, 0] $, corrispondente a Q.

Figura 29: Esempio di vettore di input
2). Definizione del modello e addestramento
Creiamo una rete ricorrente semplice, una LSTM e addestriamole per 10 epoche. Nelle iterazioni di addestramento dovremmo sempre cercare cinque passaggi:
- Eseguire il forward pass del modello
- Calcolare l’errore
- Azzerare la cache del gradiente
- Retropropagare per calcolare la derivata parziale dell’errore rispetto ai parametri
- Passo nella direzione opposta al gradiente

Figura 30: Semplice RNN vs. LSTM - 10 Epoche
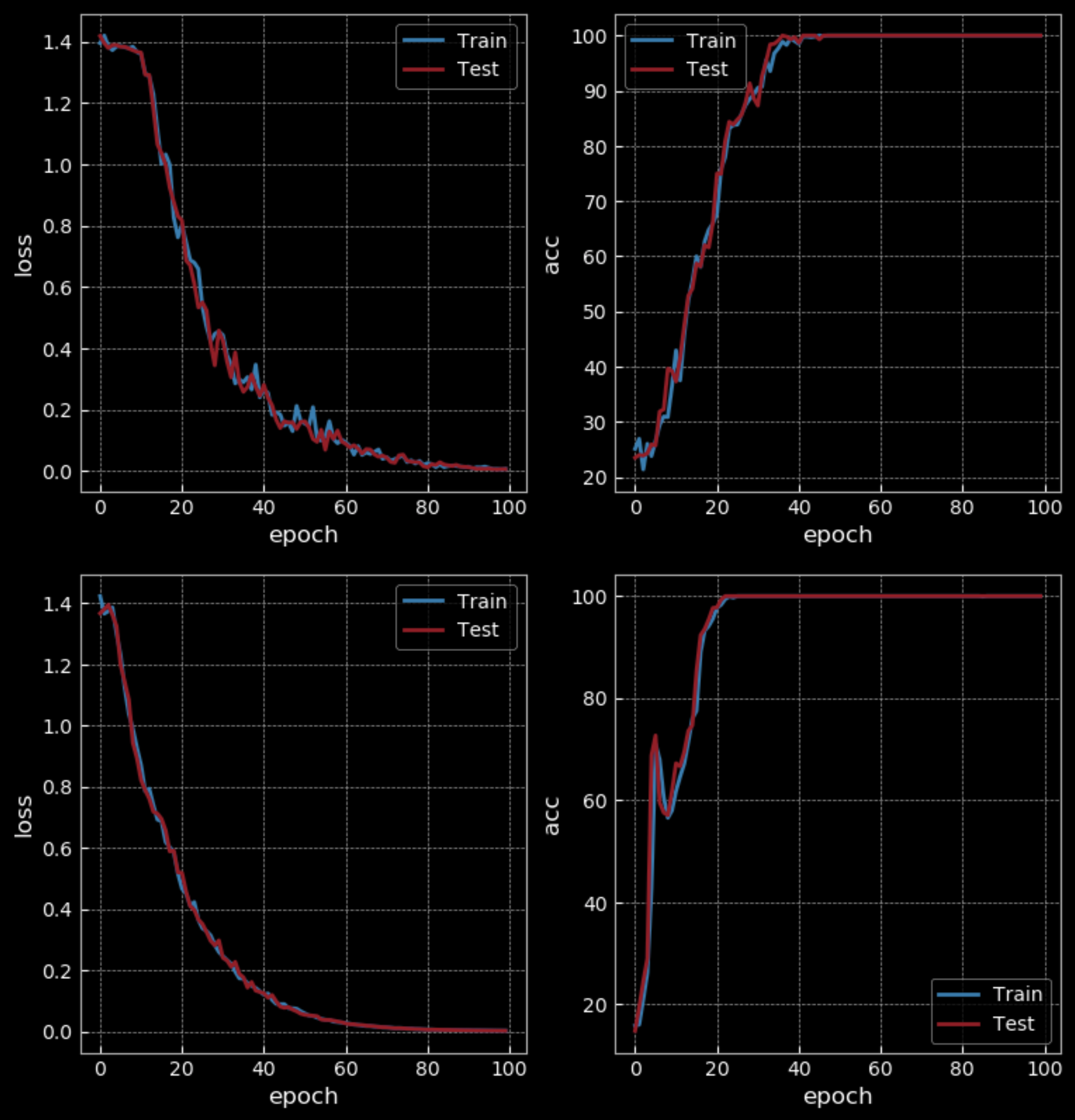
Figura 31: Semplice RNN vs LSTM - 100 Epoche

Figura 32: Visualizzazione del valore dello stato nascosto
La visualizzazione sopra mostra il valore dello stato nascosto nel tempo in una LSTM. Verrà applicata una tangente iperbolica agli input, in modo tale che se l’input è inferiore a $-2,5$, verrà mappato a $-1$ e se sarà superiore a $2,5$, verrà mappato a $1$. Quindi, in questo caso, possiamo vedere lo specifico livello nascosto scelto su X (quinta fila nella foto) che poi diventa rosso fino a quando non otteniamo l’altra X. Quindi, la quinta unità nascosta della cellula viene attivata osservando la X e diventa silenziosa dopo aver visto l’altra X. Questo ci consente di riconoscere la classe di sequenza.
Eco del segnale
L’eco del segnale ad n step è un esempio di un compito molti-a-molti sincronizzato. Ad esempio, la prima sequenza di input è " 1 1 0 0 1 0 1 1 0 0 0 0 0 0 0 0 1 1 1 1 ... ", e la prima sequenza target è " 0 0 0 1 1 0 0 1 0 1 1 0 0 0 0 0 0 0 0 0 1 ... ". In questo caso, l’output è tre passi dopo. Quindi abbiamo bisogno di una memoria di lavoro di breve durata per conservare le informazioni. Nel modello linguistico invece dice qualcosa che non è già stato detto.
Prima di inviare l’intera sequenza alla rete e forzare l’obiettivo finale ad essere qualcosa, dobbiamo tagliare la lunga sequenza in piccoli pezzi. Quando un nuovo blocco viene dato in ingresso, è necessario tenere traccia dello stato nascosto e inviarlo come input allo stato interno quando si aggiunge il successivo nuovo blocco. Laddove una RNN inizia a dimenticare cosa è successo in passato dopo una certa lunghezza, una LSTM è invece capace di conservare la memoria per lungo tempo, purchè si disponga di capacità sufficiente.
📝 Zhengyuan Ding, Biao Huang, Lin Jiang, Nhung Le
Alessio Salman
3 Mar 2020