Decodificando Modelos de Lenguaje
🎙️ Mike Lewis[Búsqueda por haces] (https://www.youtube.com/watch?v=6D4EWKJgNn0&t=2732s)
La búsqueda por haces es otra técnica para decodificar un modelo de lenguaje y producir texto. En cada paso, el algoritmo realiza un seguimiento de las $k$ traducciones parciales (hipótesis) más probables (mejores). La puntuación de cada hipótesis es igual a su probabilidad logarítmica.
El algoritmo selecciona la hipótesis con mejor puntuación.
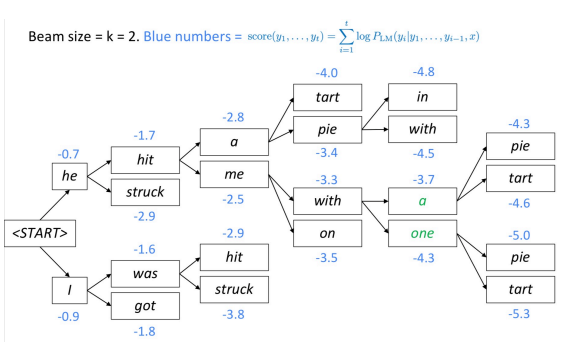
Fig. 1 : decodificación de haces
¿Cómo se ramifica el árbol de haces?
El árbol de haces continúa hasta que llega al token de final de oración. Al generar el final del token de oración, la hipótesis está terminada.
¿Por qué (en NMT) los tamaños de haces muy grandes a menudo dan como resultado traducciones vacías?
En el momento del entrenamiento, el algoritmo a menudo no usa un haz, porque es muy caro. En su lugar, usa factorización auto-regresiva (dados los resultados correctos anteriores, predice las primeras palabras $ n + 1 $). El modelo no está expuesto a sus propios errores durante el entrenamiento, por lo que es posible que aparezcan “sinsentidos”.
Resumen: Continúe la búsqueda por haces hasta que todas las $k$ hipótesis produzcan un token final o hasta que se alcance el límite máximo de decodificación T.
Muestreo
Puede que no queramos la secuencia más probable. En su lugar, podemos tomar muestras de la distribución del modelo.
Sin embargo, el muestreo de la distribución del modelo plantea su propio problema. Una vez que se muestrea una “mala” elección, el modelo se encuentra en un estado que nunca enfrentó durante el entrenamiento, lo que aumenta la probabilidad de una “mala” evaluación continua. Por lo tanto, el algoritmo puede atascarse en ciclos de retroalimentación horribles.
Muestreo de Top-K
Una técnica de muestreo pura en la que se trunca la distribución a los $ k $ mejores y luego se vuelve a normalizar y se muestrea la distribución.
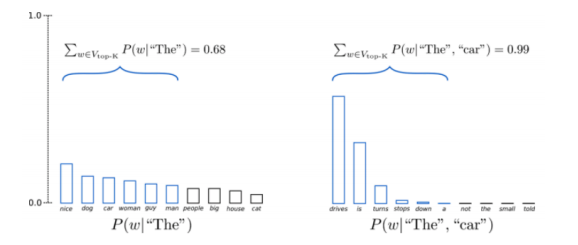
Fig. 2 : muestreo de los K mejores
Pregunta: ¿Por qué el muestreo Top-K funciona tan bien?
Esta técnica funciona bien porque esencialmente intenta evitar salirse de la región (variedad matemática) del buen lenguaje cuando probamos algo malo usando solo la cabeza de la distribución y cortando la cola.
Evaluación de la generación de texto
La evaluación del modelo de lenguaje requiere simplemente el logaritmo de la verosimilitud de los datos retenidos. Sin embargo, es difícil evaluar texto. Normalmente se utilizan métricas de superposición de palabras con una referencia (BLEU, ROUGE, etc.), pero tienen sus propios problemas.
Modelos de secuencia a secuencia
Modelos de lenguaje condicional
Los modelos de lenguaje condicional no son útiles para generar muestras aleatorias de inglés, pero son útiles para generar un texto dado una entrada.
Ejemplos:
- Dada una oración en francés, generar la traducción al inglés
- Dado un documento, generar un resumen
- Dado un diálogo, generar la siguiente respuesta
- Dada una pregunta, generar la respuesta
Modelos de secuencia a secuencia
Generalmente, el texto de entrada se codifica. Esta incrustación resultante se conoce como un “vector de pensamiento”, que luego se pasa al decodificador para generar tokens palabra por palabra.
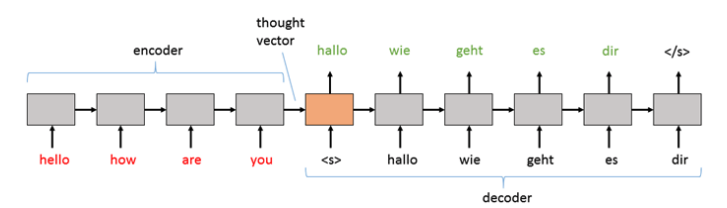
Fig. 3 : Vector de pensamiento
Transformador de secuencia a secuencia
La variación de secuencia a secuencia de transformadores tiene 2 pilas:
- Pila de codificadores: la atención personal no está enmascarada, por lo que cada token en la entrada puede mirar todos los demás tokens en la entrada
- Pila de decodificadores: además de prestar atención a sí mismo, también presta atención a las entradas completas
Fig. 4 : Transformador de secuencia a secuencia
Cada token en la salida tiene conexión directa con cada token anterior en la salida, y también con cada palabra en la entrada. Las conexiones hacen que los modelos sean muy expresivos y poderosos. Estos transformadores han realizado mejoras en la puntuación de traducción con respecto a los modelos recurrentes y convolucionales anteriores.
[Traducción inversa] (https://www.youtube.com/watch?v=6D4EWKJgNn0&t=3811s)
Al entrenar estos modelos, generalmente confiamos en grandes cantidades de texto etiquetado. Una buena fuente de datos son los procedimientos del Parlamento Europeo: el texto se traduce manualmente a diferentes idiomas que luego podemos utilizar como entradas y salidas del modelo.
Cuestiones
- No todos los idiomas están representados en el parlamento europeo, lo que significa que no obtendremos pares de traducción para todos los idiomas en los que podríamos estar interesados. ¿Cómo encontramos texto para la capacitación en un idioma del que no necesariamente podemos obtener los datos?
- Dado que los modelos como los transformadores funcionan mucho mejor con más datos, ¿cómo usamos el texto monolingüe de manera eficiente, i.e. sin pares de entrada/salida?
Supongamos que queremos entrenar un modelo para que traduzca del alemán al inglés. La idea de la retro-traducción es entrenar primero un modelo inverso del inglés al alemán
- Utilizando un bi-texto limitado podemos adquirir las mismas frases en 2 idiomas diferentes
- Una vez que tengamos un modelo de inglés a alemán, traducimos muchas palabras monolingües del inglés al alemán.
Finalmente, entrenamos el modelo de alemán a inglés usando las palabras alemanas que han sido ‘retro-traducidas’ en el paso anterior. Notamos que:
- No importa lo bueno que sea el modelo inverso: es posible que tengamos traducciones alemanas ruidosas pero terminemos traduciendo a un inglés limpio.
- Necesitamos aprender a entender el inglés mucho más allá de los datos de los pares inglés/alemán (ya traducidos) - use grandes cantidades de inglés monolingüe
Retro-traducción iterada
- Podemos iterar el procedimiento de retro-traducción para generar aún más datos bi-texto y alcanzar un rendimiento mucho mejor; solo hay que seguir entrenando con datos monolingües.
- Ayuda mucho que hayan pocos datos paralelos
MT multilingüe masiva
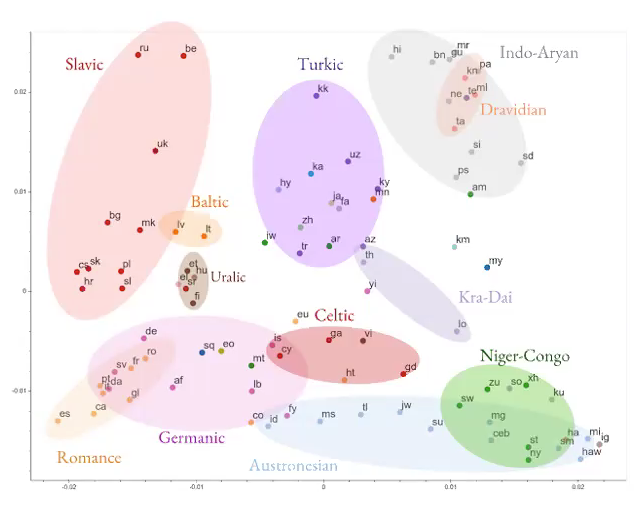
Fig. 5 : MT multilingüe
- En lugar de intentar aprender una traducción de un idioma a otro, intente construir una red neuronal para aprender traducciones en varios idiomas.
- El modelo está aprendiendo información general independiente del lenguaje.

Fig. 6 : Resultados NN multilingües
Excelentes resultados, especialmente si queremos entrenar un modelo para traducir a un idioma que no tiene muchos datos disponibles para nosotros (idioma de bajos recursos).
Aprendizaje no supervisado para NLP
Hay grandes cantidades de texto sin etiquetas y poca información supervisada. ¿Cuánto podemos aprender sobre el idioma con solo leer texto sin etiquetar?
word2vec (palabra a vector)
Intuición - si las palabras aparecen juntas en el texto, es probable que estén relacionadas, por lo que esperamos que con solo mirar el texto en inglés sin etiquetar, podamos aprender lo que significan.
- El objetivo es aprender representaciones de espacios vectoriales para palabras (aprender incrustaciones)
Tarea de preentrenamiento - enmascare alguna palabra y use palabras vecinas para completar los espacios en blanco.

Fig. 7 : visual del enmascaramiento de word2vec
Por ejemplo, aquí, la idea es que “cuernos” y “cabello plateado” tienen más probabilidades de aparecer en el contexto de “unicornio” que cualquier otro animal.
Toma las palabras y aplica una proyección lineal.
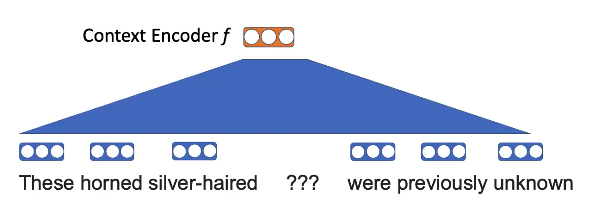
Fig. 8 : incrustaciones de word2vec
Quieren saber
\[p (\texttt {unicornio} \mid \texttt {¿Estos ??? de pelo plateado eran previamente desconocidos})\] \[p (x_n \mid x _ {- n}) = \text {softmax} (\text {E} f (x _ {- n})))\]Las incrustaciones de palabras tienen cierta estructura
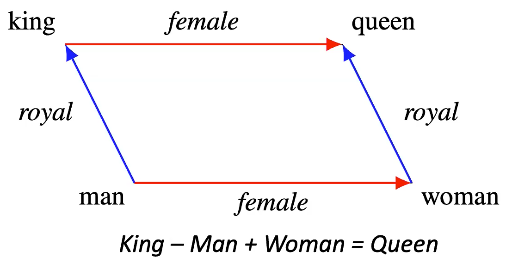
Fig. 9 : ejemplo de estructura de inserción
- La idea es que si tomamos la incrustación de “rey” después del entrenamiento y agregamos la incrustación de “mujer” obtendremos una incrustación muy cercana a la de “reina”
- Muestra algunas diferencias significativas entre vectores.
Pregunta: ¿La representación de la palabra es dependiente o independiente del contexto?
Independiente y ajena a la representación de otras palabras
Pregunta: ¿Cuál sería un ejemplo de una situación en la que este modelo tendría dificultades?
La interpretación de palabras depende en gran medida del contexto. Entonces, en el caso de palabras ambiguas, palabras que pueden tener múltiples significados, el modelo tendrá dificultades, ya que los vectores de incrustación no capturarán el contexto necesario para comprender correctamente la palabra.
GPT
Para agregar contexto, podemos entrenar un modelo de lenguaje condicional. Luego, dado este modelo de lenguaje, que predice una palabra en cada paso de tiempo, reemplace cada salida del modelo con alguna otra característica.
- Entrenamiento previo: predice la siguiente palabra
- Ajuste fino: cambie a una tarea específica. Ejemplos:
- Predecir si es sustantivo o adjetivo
- Dado un texto que comprende una reseña de Amazon, predice la puntuación de sentimiento para la revisión
Este enfoque es bueno porque podemos reutilizar el modelo. Entrenamos previamente un modelo grande y podemos ajustarnos a otras tareas.
ELMo
GPT solo considera el contexto hacia la izquierda, lo que significa que el modelo no puede depender de ninguna palabra futura; esto limita mucho lo que el modelo puede hacer.
Aquí el enfoque es entrenar dos modelos de lenguaje
- Uno en el texto de izquierda a derecha
- Uno en el texto de derecha a izquierda
- Concatenar la salida de los dos modelos para obtener la representación de la palabra. Ahora puede condicionar tanto el contexto hacia la derecha como hacia la izquierda.
Esta sigue siendo una combinación “superficial” y queremos una interacción más compleja entre el contexto izquierdo y derecho.
BERT
BERT es similar a word2vec en el sentido de que también tenemos una tarea de rellenar un espacio en blanco. Sin embargo, en word2vec teníamos proyecciones lineales, mientras que en BERT hay un gran transformador que es capaz de mirar más contexto. Para entrenar, enmascaramos el 15% de los tokens e intentamos predecir el espacio en blanco.
Puede escalar BERT (RoBERTa):
- Simplificando el objetivo de preentrenamiento de BERT
- Escalando el tamaño del lote
- Entrenando con grandes cantidades de GPUs
- Entrenando aún con más texto
Mejoras aún mayores sobre el rendimiento de BERT: el rendimiento de las tareas de respuesta a preguntas es ahora sobrehumano.
[Entrenamiento previo para NLP] (https://www.youtube.com/watch?v=6D4EWKJgNn0&t=4963s)
Echemos un vistazo rápido a los diferentes enfoques de formación previa autodirigidos que se han investigado para el NLP.
-
XLNet:
En lugar de predecir todos los tokens enmascarados de forma condicionalmente independiente, XLNet predice los tokens enmascarados de forma autorregresiva en orden aleatorio
-
SpanBERT
Enmascara tramos (secuencias de palabras consecutivas) en lugar de tokens
-
ELECTRA:
En lugar de enmascarar palabras, sustituimos tokens por otros similares. Luego, resolvemos un problema de clasificación binaria tratando de predecir si los tokens han sido sustituidos o no.
-
ALBERT:
Un Bert liviano: modificamos BERT y lo hacemos más liviano atando los pesos a través de las capas. Esto reduce los parámetros del modelo y los cálculos involucrados. Curiosamente, los autores de ALBERT no tuvieron que comprometer mucho la precisión.
-
XLM:
BERT multilingüe: en lugar de introducir texto en inglés, lo hacemos en varios idiomas. Como era de esperar, aprendió mejor las conexiones entre idiomas.
Las conclusiones clave de los diferentes modelos mencionados anteriormente son
-
¡Muchos objetivos diferentes de preentrenamiento funcionan bien!
-
Es muy importante modelar interacciones profundas y bi-direccionales entre palabras
-
Grandes beneficios de agrandar el preentrenamiento, aún sin límites claros
La mayoría de los modelos discutidos anteriormente están diseñados para resolver el problema de clasificación de texto. Sin embargo, para resolver el problema de la generación de texto, donde generamos resultados secuencialmente como el modelo seq2seq, necesitamos un enfoque ligeramente diferente al preentrenamiento.
Entrenamiento previo para generación condicional: BART y T5
BART: preentrenamiento de modelos seq2seq mediante la eliminación de ruido en el texto
En BART, para el entrenamiento previo, tomamos una oración y la corrompemos enmascarando tokens al azar. En lugar de predecir los tokens de enmascaramiento (como en el objetivo de BERT), alimentamos la secuencia corrupta completa e intentamos predecir la secuencia correcta completa.
Este enfoque de preentrenamiento seq2seq nos da flexibilidad para diseñar nuestros esquemas de corrupción. Podemos barajar las oraciones, eliminar frases, introducir nuevas frases, etc.
BART pudo igualar a RoBERTa en las tareas SQUAD y GLUE. Sin embargo, fue el nuevo estado del arte sobre resumenes, diálogos y conjuntos de datos de control de calidad abstractos. Estos resultados refuerzan nuestra motivación por BART, siendo mejores en tareas de generación de texto que BERT/RoBERTa.
Algunas preguntas abiertas en NLP
- ¿Cómo deberíamos integrar el conocimiento mundial?
- ¿Cómo modelamos documentos largos? (Los modelos basados en BERT suelen utilizar 512 tokens)
- ¿Cuál es la mejor manera de hacer el aprendizaje multitarea?
- ¿Podemos realizar ajustes finos con menos datos?
- ¿Estos modelos realmente comprenden el lenguaje?
Resumen
- La formación de modelos sobre una gran cantidad de datos supera al modelado explícito de la estructura lingüística.
Desde una perspectiva de sesgo y varianza, los transformadores son modelos de bajo sesgo (muy expresivos). Alimentar estos modelos con mucho texto es mejor que modelar explícitamente la estructura lingüística (alto sesgo). Las arquitecturas deben comprimir secuencias a través de cuellos de botella
- Los modelos pueden aprender mucho sobre el lenguaje al predecir palabras en texto sin etiquetar. Esto resulta ser un gran objetivo de aprendizaje sin supervisión. La puesta a punto para tareas específicas se vuelve entonces fácil
- El contexto bidireccional es crucial
Información adicional de las preguntas después de la clase:
¿Cuáles son algunas formas de cuantificar la “comprensión del lenguaje”? ¿Cómo sabemos que estos modelos realmente entienden el lenguaje?
“El trofeo no cabía en la maleta porque era demasiado grande”: Resolver la referencia de ‘era’ en esta oración es complicado para las máquinas. Los humanos somos buenos en esta tarea. Hay un conjunto de datos que consta de ejemplos igual de difíciles y los humanos lograron 95% de rendimiento en ese conjunto de datos. Los programas de computadora solo podían alcanzar alrededor del 60% antes de la revolución provocada por los transformadores. Los modelos modernos de transformadores pueden lograr más del 90% en ese conjunto de datos. Esto sugiere que estos modelos no solo están memorizando/manipulando los datos sino también aprendiendo conceptos y objetos a través de los patrones estadísticos en los datos.
Además, BERT y RoBERTa logran un rendimiento sobrehumano en SQUAD y Glue. Los resúmenes textuales generados por BART parecen muy reales para los humanos (puntajes BLEU altos). Estos hechos son evidencia de que los modelos entienden el lenguaje de alguna manera.
Lenguaje Fundamentado
Curiosamente, el profesor (Mike Lewis, investigador científico, FAIR) está trabajando en un concepto llamado “Lenguaje Fundamentado”. El objetivo de ese campo de investigación es construir agentes conversacionales que sean capaces de charlar o negociar. Charlar y negociar son tareas abstractas con objetivos poco claros en comparación con la clasificación o el resumen del texto.
¿Podemos evaluar si el modelo ya tiene conocimiento del mundo real?
El “conocimiento del mundo real” es un concepto abstracto. Podemos probar el conocimiento del mundo real que tienen los modelos (en un nivel muy básico) haciéndoles preguntas simples sobre los conceptos que nos interesan. Modelos como BERT, RoBERTa y T5 tienen miles de millones de parámetros. Teniendo en cuenta que estos modelos están entrenados en un enorme corpus de texto informativo como Wikipedia, habrían memorizado hechos usando sus parámetros y podrían responder nuestras preguntas. Además, también podemos pensar en realizar la misma prueba de conocimientos antes y después de ajustar un modelo en alguna tarea. Esto nos daría una idea de cuánta información ha “olvidado” el modelo.
📝 Trevor Mitchell, Andrii Dobroshynskyi, Shreyas Chandrakaladharan, Ben Wolfson
GastonMazzei (Gaston Mazzei)
20 Apr 2020