Deep Learning for NLP
🎙️ Mike LewisSíntesis
- Grandes avances en los últimos años:
- En algunos lenguajes, los usuarios prefieren traducciones realizadas por la máquina que por intérpretes humanos.
- Rendimiento superior al humano en varios conjuntos de datos de pregunta-respuesta
- Modelos de lenguaje generan párrafos fluídos (e.g Radford et al. 2019)
- Todo esto se puede lograr con cambios mínimos, partiendo de modelos genéricos.
Modelos de lenguaje
- Los modelos de lenguaje asignan una probabilidad a un texto: $p(x_0, \cdots, x_n)$
- Existen muchas combinaciones de oraciones coherentes, por consiguiente, no es viable entrenar a un clasificador.
- El método más popular es factorizar la distribución utilizando la regla de la cadena:
Modelos neuronales de lenguaje
La idea básica es introducir el texto a una red neuronal que mapeará el contexto a un vector. Este vector contiene la representación de la siguiente palabra y una matriz de incrustaciones. Esta matriz contiene un vector para cada palabra que el modelo es capaz de predecir. Después, se calcula la similaridad del vector de contexto usando el producto punto con cada vector de palabras, esto nos dará una probabilidad de cuál será la siguiente palabra y el modelo se puede entrenar con probabilidad máxima. Es importante recalcar que no lidiamos con las palabras directamente, pero con sub-palabras o caracteres.
\[p(x_0 \mid x_{0, \cdots, n-1}) = \text{softmax}(E f(x_{0, \cdots, n-1}))\]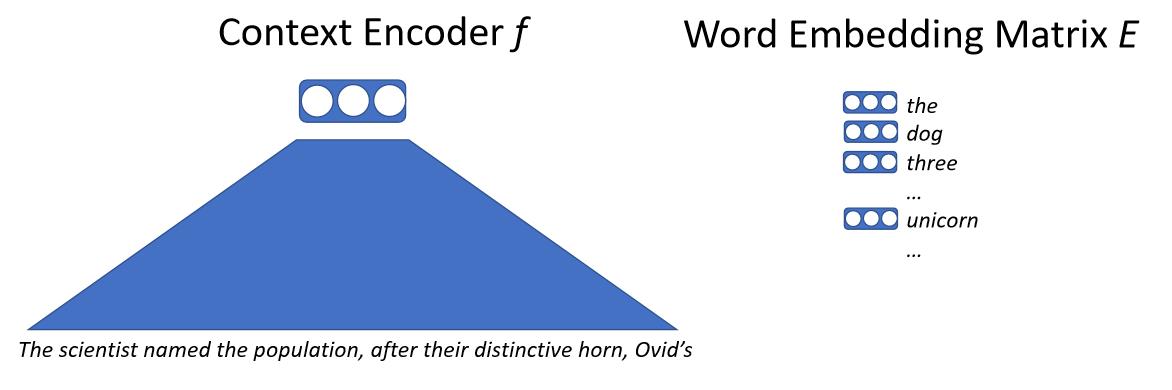
Modelos Convolucionales de Lenguaje
- Los primeros modelos de lenguaje
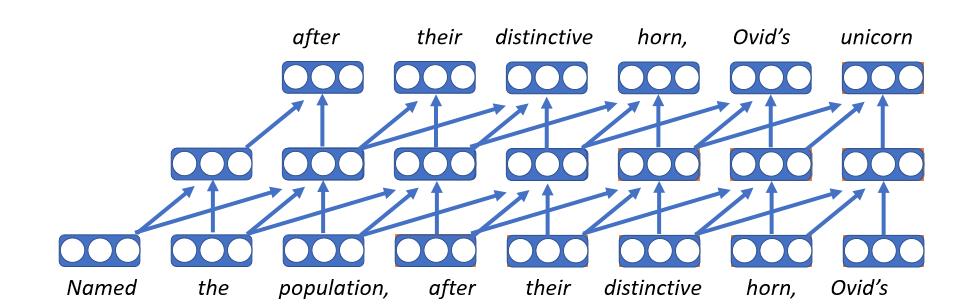
- Incorporan cada palabra como un vector, el cual es una tabla de búsqueda para la matriz de incrustaciones. Por consiguiente, la palabra obtendrá el mismo vector sin importar el contexto en el que aparezca.
- La misma red es utilizada en cada paso de tiempo.
- Una desventaja es que al tener una longitud fija sólo se puede utilizar en texto de longitud determinada.
- Estos modelos son muy rápidos.
Modelos de Lenguaje Recurrente
- Fueron los más populares hasta hace algunos años
- Conceptualmente sencillos: en cada paso de tiempo se mantiene un estado (que es recibido del paso del tiempo anterior), el cual representada lo que se ha aprendido hasta ese punto. Este es combinado con la palabra que está siendo procesada, para utilizarse en el siguiente paso del tiempo. Este proceso es repetido en tantos pasos de tiempo como sea necesario.
- Utilizan longitudes de texto no determinadas: por ejemplo, el título de un libro afectará los estados ocultos de la última palabra del mismo.
- Desventajas:
- Toda la historia al leer el documento es comprimida en un vector de tamaño fijo en cada paso de tiempo, este es el cuello de botella del modelo.
- Los gradientes tienden a desvanecerse en textos largos
- No es posible paralelizar en pasos del tiempo, por consiguiente, el entrenamiento es lento.
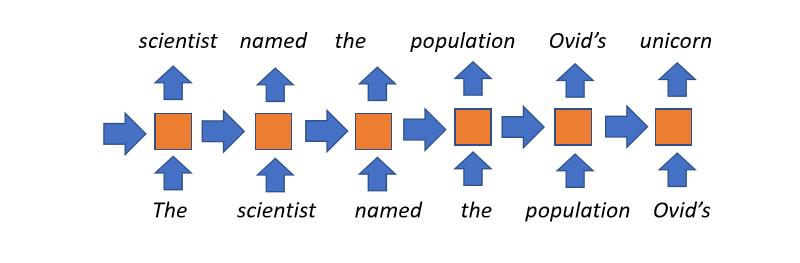
Fig.3: Modelo de lenguaje recurrente
Modelos Transformadores de Lenguaje
- Los modelos más recientes para NLP
- Revolucionó las sanciones
- Tres etapas principales
- Datos de entrada
- $n$ bloques transformadores (capas encodificadoras) con distintos parámetros
- Salida
- Ejemplo con seis módulos transformadores en el artículo original:
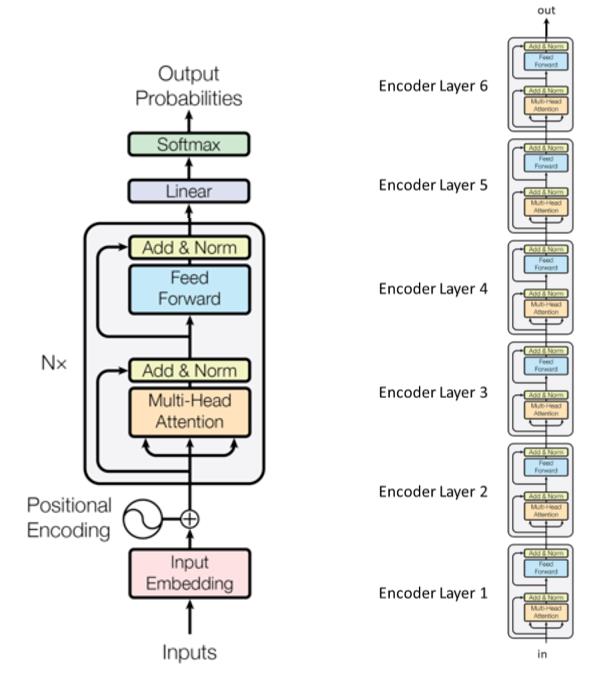
Las sub-capas están conectadas por cajas marcadas como “Add&Norm”. La adición se refiere a una conexión residual, la cual ayuda a transportar a los gradientes. La normalización indica una normalización por capa.
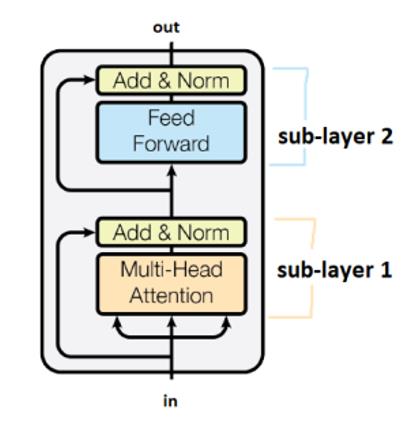
Nótese que los transformadores comparten pesos a lo largo de los pasos de tiempo.
Atención con cabezas múltiples
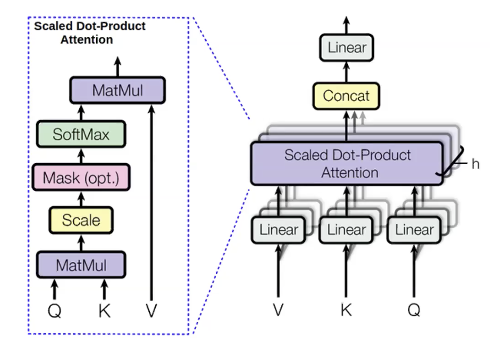
Para las palabras que queremos predecir, calculamos valores llamados consulta(q). A las palabras previas las llamamos llaves(k). Una consulta tiene contexto, por ejemplo, adjetivos anteriores. Una llave es una etiqueta que contiene información acerca de la palabra actual, por ejemplo, si esta es un adjectivo. Una vez que q es calculada, podemos derivar la distribución de las palabras anteriores ($p_i$):
\[p_i = \text{softmax}(q,k_i)\]Acto seguido, podemos también calcular cantidades llamadas valores(v) para las palabras anteriores. Los valores representan el contenido de las palabras.
Una vez que calculamos los valores, podemos calcular los estados ocultos al maximizar la distribución de la atención:
\[h_i = \sum_{i}{p_i v_i}\]Calculamos lo mismo con distintas consultas, valores, y llaves múltiples veces en paralelo. La razón detrás de esto es que queremos predecir la siguiente palabra utilizando distintas cosas. Por ejemplo, cuando predecimos la palabra “unicornios” utilizando tres palabras anteriores: “Estos”, “cornudos” y “plateados”. Podemos ver que el plural viene de “Estos”, así que estas tres palabras son necesarias. La atención con cabezas múltiples es una manera de dejar que cada palabra busque en múltiples palabras anteriores.
Una gran ventaja de la atención con cabezas múltiples es que es paralelizable. Contrario a las RNNs, esta calcula todas las cabezas en los módulos y todos los pasos de tiempo simultáneamente. El problema de calcular todos los pasos de tiempo simultáneamente es que también puede ver palabras futuras, cuando únicamente queremos condicionar al modelo con palabras pasadas. Una posible solución es el llamado enmascaramiento de atención, donde la máscara es una matriz triangular superior con infinitos negativos y ceros en la sección inferior. Al añadir esta matriz al resultado del módulo de atención es que cada palabra a la izquierda tiene un puntaje de atención mucho más alto que las palabras a la derecha, entonces en práctica, el modelo sólo se concentra en las palabras previas. Esta técnica es crucial, sin embargo, en encodificadores de texto, el contexto bidireccional puede ser útil.
Un detalle que hace al modelo transformador funcionar es añadir la incrustación de posición a los datos de entrada. En el lenguaje, algunas propiedades como el orden son muy importantes. La técnica mostrada aquí es aprender incrustaciones separadas en distintos pasos de tiempo y añadir etas a los datos de entrada. Por consiguiente, estos datos son la suma del vector de palabras y el de posición. Esto le da al modelo información del orden.
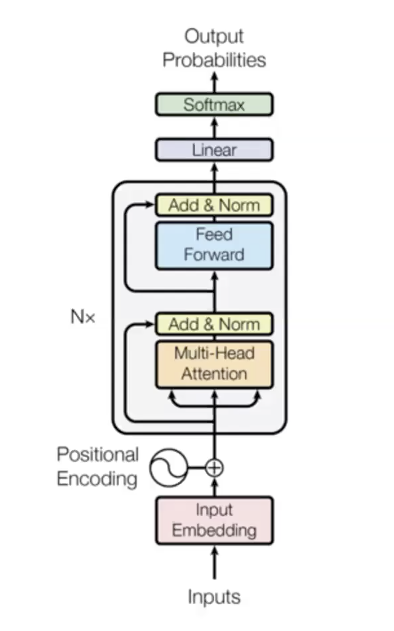
¿Por qué el modelo es tan bueno?:
-
Da conexiones directas entre cada par de palabras. Cada palabra puede acceder directamente el estado oculto de las palabras previas, evitando que desaparezcan los gradientes. Aprende funciones complejas con facilidad.
-
Todos los pasos de tiempo son calculados en paralelo.
-
La auto-atención es cuadrática (todos los pasos de tiempo atienden a los otros), esto limita la longitud máxima.
Algunos trucos (especialmente para atención con cabezas múltiples e incrustaciones posicionales) y decodificadores de lenguaje
Técnica 1: Es muy útil el uso extenso de normalización por capa para estabilizar el entrenamiento
- Esto es muy importante para los transformadores
Técnica 2: Calentamiento + esquema de entrenamiento con la raíz-cuadrada inversa
- El uso de los esquemas de planificación de la tasa de aprendizaje: para que los transformadores funcionen adecuadamente, la tasa de aprendizaje debe de decaer linealmente de cero hasta el paso de tiempo número mil.
Técnica 3: Inicialización cuidadosa
- Ayuda en tareas como la traducción de máquina
Técnica 4: Suavizar las etiquetas
- Ayuda en tareas como la traducción de máquina
En seguida presentaremos resultados de las técnicas mencionadas anteriormente. En estas pruebas, la métrica utilizada a la derecha es llamada perplejidad ppl (esta debe de minimizarse).
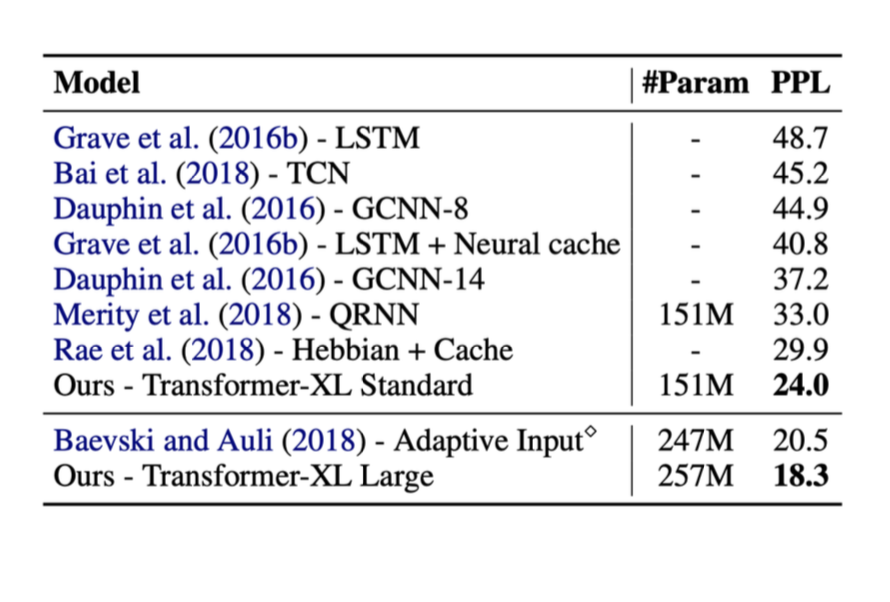
Cuando los transformadores fueron introducidos, el rendimiento en estas tareas aumentó considerablemente.
Algunos datos importantes de los transformadores
- El sesgo inductivo es mínimo.
- Todas las palabras están directamente conectadas, esto evita que los gradientes desaparezcan.
-
Todos los pasos del tiempo se calculan en paralelo.
- La auto-atención es cuadrática (todos los pasos de tiempo atienden a los otros), esto limita la longitud máxima.

Los transformadores son muy escalables
- Datos para entrenamiento ilimitados, muchos más de los necesarios.
- GPT-2 utilizó 2 billones de parámetros en 2019.
- Modelos recientes han utilizado hasta 17B (2020).
Modelos decodificadores de lenguaje
Podemos entrenar una distribución de probabilidad con texto - con esto podemos obtener datos de salida en cantidades exponenciales, por consiguiente, no podemos calcular el más probable. Cualquier decisión que se haga para la primera palabra afectará todas las decisiones futuras. Con esto en mente, se introdujo el decodificado codicioso.
El decodificado codicioso no funciona
Podemos tomar la palabra más probable en cada paso de tiempo. sin embargo, eso no garantiza que obtengamos la secuencia más probable porque si se tiene que realizar ese paso en algún punto, no tenemos manera de regresar la búsqueda para deshacer cualquier decisión pasada.
El decodificado exhaustivo tampoco funcionar
Este requiere calcular todas las secuencias posibles y debido a la complejidad $O(V^T)$, esto sería demasiado costoso.
Preguntas de comprehensión
-
¿Cuál es el beneficio de la atención de cabezas múltiples contra a un modelo de una sola cabeza?
- Para predecir la siguiente palabra es necesario observar distintas cosas, en otras palabras, la atención pude ser puesta en múltiples palabras anteriores para tratar de obtener el contexto necesario para predecir la siguiente palabra.
-
¿Cómo resuelven los transformadores los cuellos de botella de información de las CNNs y las RNNs?
- Los modelos con atención permiten la conexión direccional entre todas las palabras permitiendo que cada palabra sea condicionada por todas las palabras anteriores, eliminando efectivamente el cuello de botella.
-
¿Cómo se diferencian los transformadores de las RNNs en cómo explotan la paralelización en GPU?
- Los módulos de atención con cabezas múltiples en los transformadores son altamente paralelizables debido a que calculan todos los pasos de tiempo en un sólo pase hacia adelante.
📝 Jiayu Qiu, Yuhong Zhu, Lyuang Fu, Ian Leefmans
je-santos
20 Apr 2020