Aprendizaje auto-supervisado, tareas de pretexto
🎙️ Ishan MisraCaso de éxito de supervisión: Pre-entrenamiento
En la última década, una de las mayores recetas de éxito para muchos diferentes problemas de Visión por Computadora ha sido el aprendizaje de representaciones visuales mediante el aprendizaje supervisado para la clasificación de imágenes de ImageNet. Y luego usar estas representaciones aprendidas o los pesos de los modelos aprendidos como inicialización para otras tareas de Visión por Computadora, para los que una gran cantidad de datos etiquetados podría no estar disponible.
Sin embargo, obtener anotaciones para un conjunto de datos de la magnitud de ImageNet consume mucho tiempo y es caro. Ejemplo: el etiquetado de ImageNet con 14 millones de imágenes tomó aproximadamente 22 años humanos.
Debido a esto, la comunidad comenzó a buscar procesos de etiquetado alternativos, tales como hashtags para imágenes de redes sociales, ubicaciones de GPS o enfoques auto-supervisados donde la etiqueta es una propiedad de la muestra de datos en sí.
Pero una pregunta importante que surge antes de buscar procesos de etiquetado alternativos es:
¿Cuántos datos etiquetados podemos obtener después de todo?
- Si buscamos todas las imágenes con categorías a nivel de objeto y anotaciones de cuadro delimitador, hay aproximadamente 1 millón de imágenes.
- Ahora, si se relaja la restricción para las coordenadas del cuadro delimitador, el número de imágenes disponibles salta a 14 millones (aproximadamente).
- Sin embargo, si consideramos todas las imágenes disponibles en Internet, hay un salto de 5 órdenes en la cantidad de datos disponibles.
- Y, además de las imágenes, hay datos que requieren otra información sensorial para capturarlos o comprenderlos.
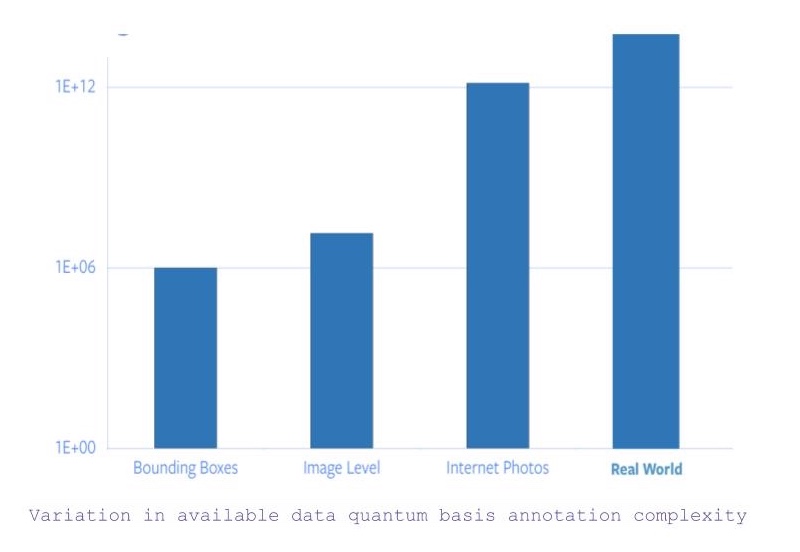
Figura 1: Variación en la complejidad básica de la anotación de los datos disponibles
Por lo tanto, partiendo del hecho de que la anotación específica de ImageNet por sí sola tomó 22 años humanos de tiempo, escalar el etiquetado a todas las fotos de Internet o más es completamente inviable.
Problema de Conceptos Raros (Problema de Cola Larga)
En general, el gráfico que presenta la distribución de las etiquetas de las imágenes de Internet parece una cola larga. Es decir, la mayoría de las imágenes corresponden a muy pocas etiquetas, mientras que existe una gran cantidad de etiquetas para las que no hay muchas imágenes. Por lo tanto, obtener muestras anotadas para categorías hacia el final de la cola requiere que se etiqueten grandes cantidades de datos debido a la naturaleza de la distribución de categorías.
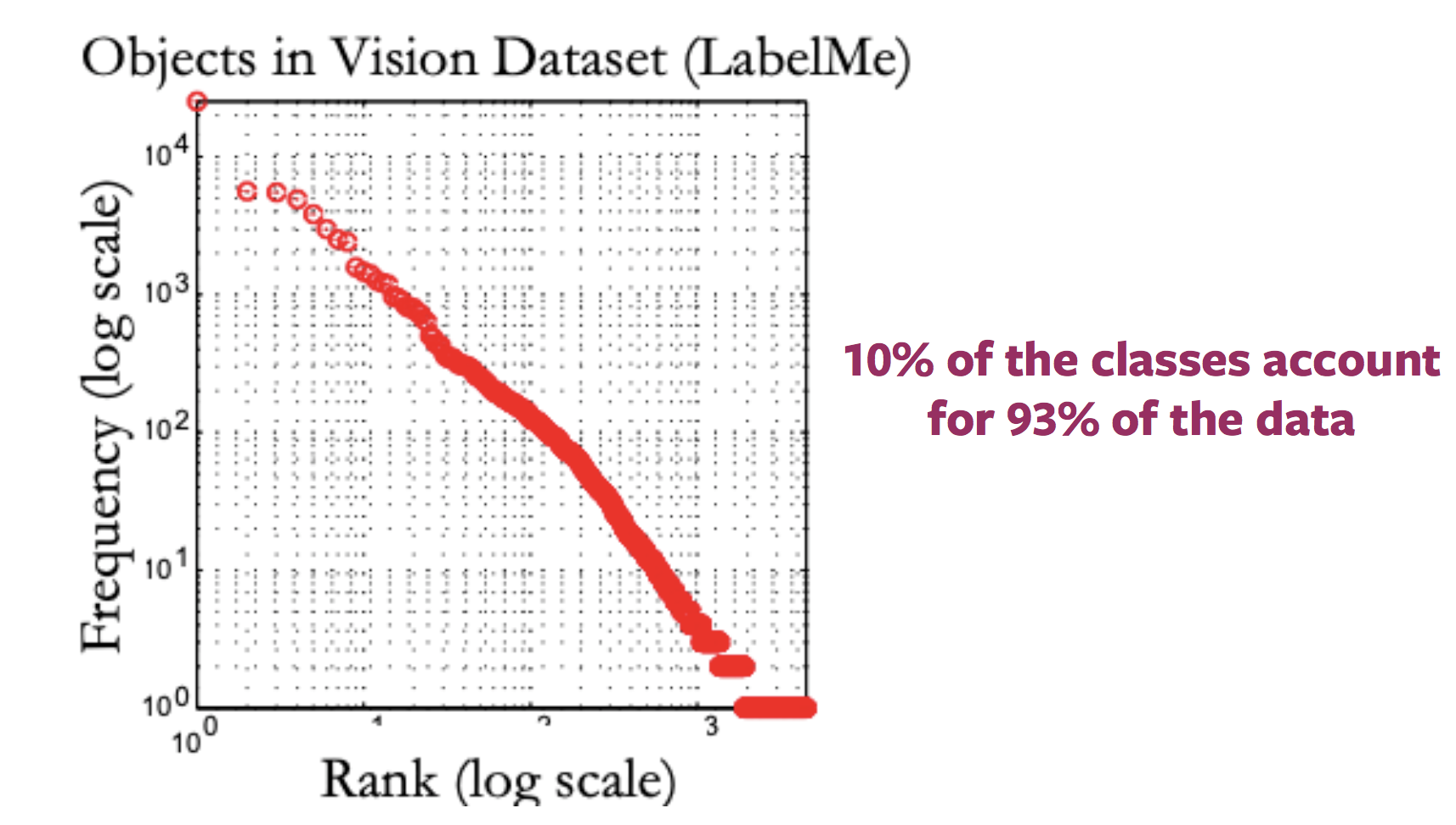
Figura 2: Variación en la distribución de imágenes disponibles con etiquetas
Problema de diferentes dominios
Este método de pre-entrenamiento y ajuste de ImageNet en tareas posteriores se vuelve aún más confuso cuando las imágenes de dichas tareas pertenecen a un dominio completamente diferente, como las imágenes médicas. Y, obtener un conjunto de datos del tamaño de ImageNet para el pre-entrenamiento para diferentes dominios no es posible.
¿Qué es el Aprendizaje auto-supervisado?
Dos formas de definir el Aprendizaje auto-supervisado
- Definición básica de aprendizaje supervisado, es decir, la red sigue el aprendizaje supervisado en el que las etiquetas se obtienen de forma semi-automatizada, sin intervención humana.
- Problema de predicción, donde una parte de los datos está oculta y el resto visible. Por tanto, el objetivo es predecir los datos ocultos o predecir alguna propiedad de los datos ocultos.
¿En qué se diferencia el aprendizaje auto-supervisado del aprendizaje supervisado y el aprendizaje no supervisado?
- Las tareas de aprendizaje supervisado tienen etiquetas predefinidas (y generalmente proporcionadas por humanos),
- El aprendizaje no supervisado tiene solamente las muestras de datos sin supervisión, etiqueta ni salida correcta.
- El aprendizaje auto-supervisado deriva sus etiquetas de una modalidad concurrente para la muestra de datos dada o de una parte concurrente de la muestra de datos misma.
Aprendizaje auto-supervisado en el procesamiento del lenguaje natural
Word2Vec
- Dada una oración de entrada, la tarea consiste en predecir una palabra que falta en esa oración, que se omite específicamente con el propósito de construir una tarea de pretexto.
- Por lo tanto, el conjunto de etiquetas se convierte en todas las palabras posibles en el vocabulario, y la etiqueta correcta es la palabra que se omitió de la oración.
- Por lo tanto, la red se puede entrenar utilizando los métodos usuales basados en gradientes para aprender representaciones a nivel de palabra.
¿Por qué aplicar aprendizaje auto-supervisado?
- El aprendizaje auto-supervisado permite aprender representaciones de datos solo con observaciones de cómo interactúan las diferentes partes de los datos.
- Por lo tanto, elimina el requisito de contar con una gran cantidad de datos anotados.
- Además, permite aprovechar múltiples modalidades que podrían estar asociadas con una sola muestra de datos.
Aprendizaje auto-supervisado en Visión por Computadora
En general, los pipelines de Visión por Computadora que emplean aprendizaje auto-supervisado implican la realización de dos tareas, una tarea de pretexto y una tarea real (posterior).
- La tarea real (posterior) puede ser cualquier cosa, como una tarea de clasificación o detección, con insuficientes muestras de datos anotados.
- La tarea de pretexto es la tarea de aprendizaje auto-supervisado que se resuelve para aprender representaciones visuales, con el objetivo de utilizar las representaciones aprendidas o los pesos de los modelos obtenidos en el proceso, para la tarea posterior.
Desarrollando tareas de pretexto
- Las tareas de pretexto para problemas de Visión por Computadora se pueden desarrollar utilizando imágenes, video o video y sonido.
- En cada tarea de pretexto hay datos en parte visibles y en parte ocultos, mientras que la tarea es predecir los datos ocultos o alguna propiedad de los datos ocultos.
Ejemplo de tareas de pretexto: predecir la posición relativa de parches de imagen
- Entrada: 2 parches de imagen, uno es el parche de imagen anclado y el otro es el parche de imagen de consulta.
- Dados los 2 parches de imagen, la red necesita predecir la posición relativa del parche de imagen de consulta con respecto al parche de imagen anclado.
- Por lo tanto, este problema se puede modelar como un problema de clasificación de 8 vías, ya que hay 8 ubicaciones posibles para una imagen de consulta, dada una imagen anclada.
- Y, la etiqueta para esta tarea se puede generar automáticamente al proporcionar la posición relativa del parche de consulta con respecto al ancla.
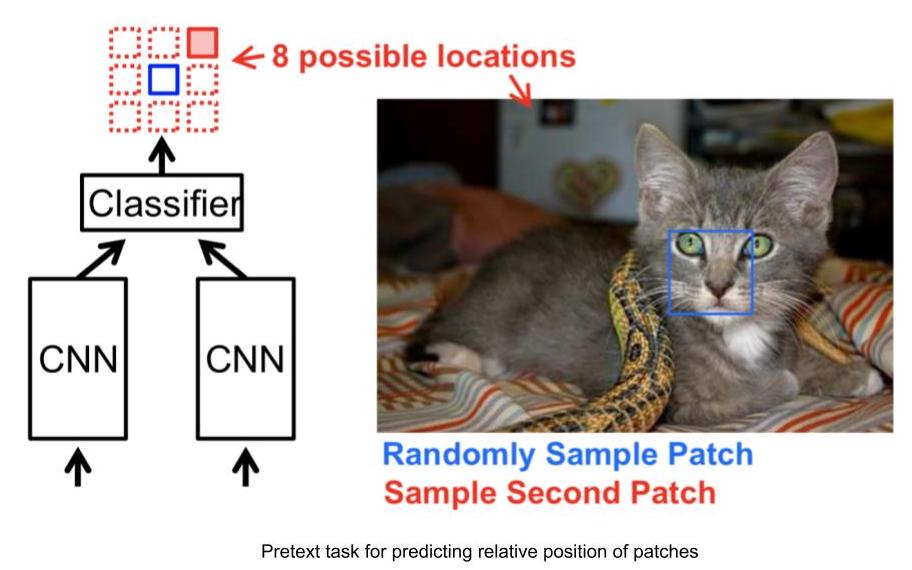
Figura 3: Tarea de posición relativa
Representaciones visuales aprendidas por la tarea de predicción de posición relativa
Podemos evaluar la eficacia de las representaciones visuales aprendidas comprobando los vecinos más cercanos para una dada representación de características de un parche de imagen provista por la red. Para calcular los vecinos más cercanos de un parche de imagen determinado,
- Calcular las características visuales de la CNN para todas las imágenes del conjunto de datos, que actuarán como grupo de muestras para su recuperación.
- Calcular las características visuales de la CNN para el parche de imagen requerido.
- Identificar los vecinos más cercanos para el vector de características de la imagen requerida, a partir del conjunto de vectores de características de imágenes disponibles.
La tarea de posición relativa descubre parches de imagen que son muy similares al parche de imagen de entrada, mientras que a su vez mantiene la invariancia a factores como el color del objeto. Por lo tanto, la tarea de posición relativa es capaz de aprender representaciones visuales, donde las representaciones de parches de imagen con apariencia visual similar también están más cerca en el espacio de representación.

Figura 4: Posición relativa: vecinos más cercanos
Predicción de la rotación de imágenes
- La predicción de rotaciones es una de las tareas de pretexto más populares, la cual tiene una arquitectura simple y directa y requiere un muestreo mínimo.
- Aplicamos rotaciones de 0, 90, 180, 270 grados a la imagen y enviamos estas imágenes rotadas a la red para predecir qué tipo de rotación se aplicó a la imagen y la red simplemente realiza una clasificación de 4 vías para predecir la rotación.
- Predecir rotaciones no tiene ningún sentido semántico, solo estamos usando esta tarea de pretexto para aprender algunas características y representaciones que se utilizarán en una tarea posterior.
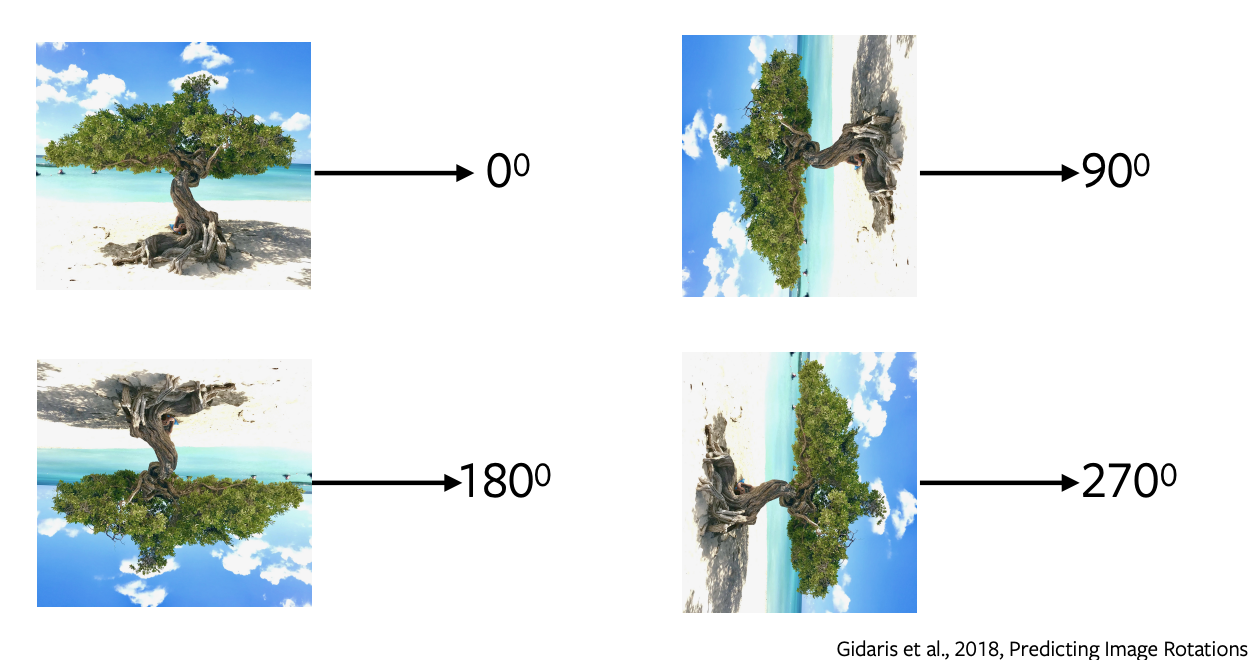
Figura 5: Rotaciones de una imagen
¿Por qué la rotación ayuda o por qué funciona?
Está comprobado que funciona empíricamente. La intuición detrás de esto es que para predecir las rotaciones, el modelo necesita comprender los límites aproximados y la representación de una imagen. Por ejemplo, tendrá que separar el cielo del agua o la arena del agua o comprender que los árboles crecen hacia arriba y así sucesivamente.
Coloración

Figura 6: Coloración
En esta tarea de pretexto, predecimos los colores de una imagen gris. Se puede formular para cualquier imagen, simplemente eliminamos el color y proporcionamos esta imagen en escala de grises a la red para predecir su color. Esta tarea es útil en algunos aspectos como para colorear las viejas películas en escala de grises [//]: <> (podemos aplicar esta tarea de pretexto). La intuición detrás de esta tarea es que la red necesita comprender alguna información significativa, como que los árboles son verdes, el cielo es azul, y así sucesivamente.
Es importante tener en cuenta que el mapeo de colores no es determinista y existen varias posibles soluciones verdaderas. Entonces, para un objeto, si hay varios colores posibles, la red lo coloreará como gris, que es la media de todas las soluciones posibles. Se han realizado trabajos recientes utilizando autoencoders variacionales y variables latentes para coloración diversa.
Rellenar los espacios en blanco
Ocultamos una parte de una imagen y predecimos la parte oculta a partir de la parte circundante restante de la imagen. Esto funciona porque la red aprenderá la estructura implícita de los datos, como por ejemplo, para representar que los automóviles circulan por las carreteras, los edificios están compuestos por ventanas y puertas, y así sucesivamente.
Tareas de pretexto para videos
Los videos están compuestos por secuencias de fotogramas y esta noción es la idea detrás de la auto-supervisión, la cual se puede aprovechar para algunas tareas de pretexto como predecir el orden de los fotogramas, completar los espacios en blanco y rastrear objetos.
Mezclar y Aprender

Figura 7: Interpolación
Dado un conjunto de fotogramas, extraemos tres fotogramas y, si se extraen en el orden correcto, los etiquetamos como positivos, de lo contrario, si están mezclados, los etiquetamos como negativos. Esto se vuelve un problema de clasificación binaria para predecir si los fotogramas están en el orden correcto o no. Entonces, dado un punto inicial y final, verificamos si el del medio es una interpolación válida de los otros dos.
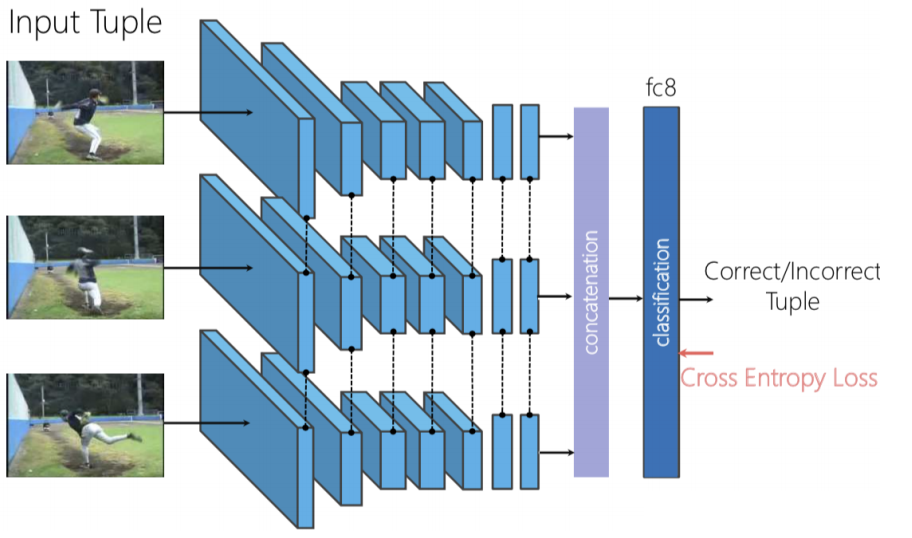
Figure 8: Arquitectura de Mezclar y Aprender
Podemos usar una red Siamese Triplet, donde los tres fotogramas son proporcionados independientemente y luego concatenamos las características visuales generadas y realizamos la clasificación binaria para predecir si los fotogramas están mezclados o no.

Figura 9: Representación de vecinos más cercanos
Nuevamente, podemos usar el algoritmo de vecinos más cercanos para visualizar lo que nuestras redes están aprendiendo. En la fig. 9, primero tenemos un fotograma de consulta (Query) que proporcionamos para obtener una representación de características visuales y luego observamos los vecinos más cercanos en el espacio de representación. Al comparar, podemos observar una gran diferencia entre los vecinos obtenidos de ImageNet, Mezclar y Aprender (Shuffle & Learn) y Aleatorio (Random).
ImageNet es bueno para capturar toda la semántica, ya que pudo descubrir que es una escena de gimnasio para la primera entrada. Del mismo modo, pudo descubrir que es una escena al aire libre con césped, etc. para la segunda consulta. Mientras que, cuando observamos Aleatorio (Random), podemos ver que le da mucha importancia al color de fondo.
Al observar Mezclar y Aprender (Shuffle & Learn), no queda claro de inmediato si se centra en el color o en el concepto semántico. Después de una inspección más profunda y de observar varios ejemplos, se observó que está mirando la pose de la persona. Por ejemplo, en la primera imagen la persona está boca abajo y en la segunda los pies están en una posición particular similar al fotograma de consulta, ignorando la escena o el color de fondo. El razonamiento detrás de esto es que nuestra tarea de pretexto era predecir si los fotogramas están en el orden correcto o no, y para hacer esto, la red debe enfocarse en lo que se mueve en la escena, en este caso, la persona.
Se realizó una verificación cuantitativa ajustando esta representación a la tarea de estimación de puntos clave humanos, donde dada una imagen humana predecimos dónde están ciertos puntos clave como nariz, hombro izquierdo, hombro derecho, codo izquierdo, codo derecho, etc. Este método es útil para el seguimiento y la estimación de pose.
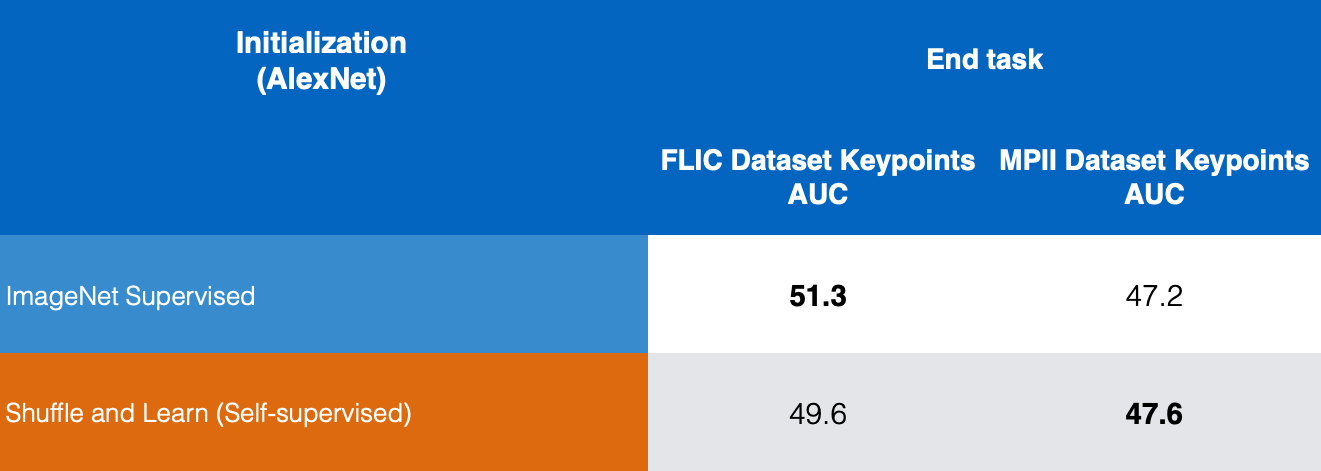
Figura 10: Comparación de estimación de puntos claves
En la figura 10, comparamos los resultados de ImageNet supervisado y Mezclar y Aprender auto-supervisado en los conjuntos de datos FLIC y MPII y podemos ver que Mezclar y Aprender da buenos resultados para la estimación de puntos clave.
Tareas de pretexto para videos y sonido
El Video y el Sonido son multimodales donde tenemos dos modalidades o entradas sensoriales, una para video y otra para sonido. Aquí intentamos predecir si el clip de video dado corresponde al clip de audio o no.

Figura 11: Muestreo de video y sonido
Dado un video con audio de un tambor, muestrear el fotograma de video con el audio correspondiente y llamarlo conjunto positivo. A continuación, tomar el audio de un tambor y el fotograma de video de una guitarra y etiquetarlo como conjunto negativo. Ahora podemos entrenar una red para resolver esto como un problema de clasificación binaria.
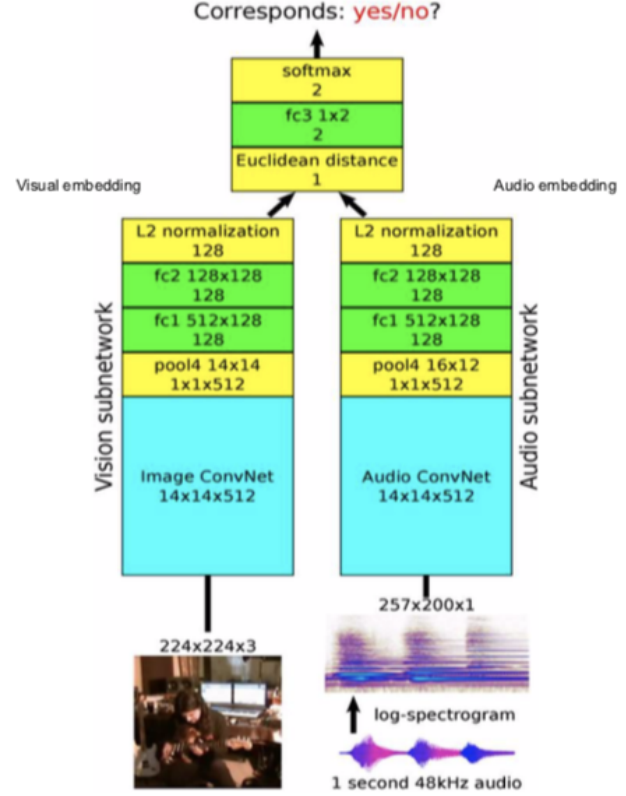
Figura 12: Arquitectura
Arquitectura: Pasar los fotogramas de video a la subred de visión y pasar el audio a la subred de audio, que proporciona características visuales y embeddings de 128 dimensiones, luego las fusionamos y lo resolvemos como un problema de clasificación binaria prediciendo si se corresponden con el uno al otro o no.
Se puede usar para predecir qué podría estar emitiendo un sonido en el fotograma. La intuición es que si se trata del sonido de una guitarra, la red necesita entender aproximadamente cómo se ve la guitarra y lo mismo debería ser cierto para la batería.
Comprender lo que aprende la tarea de “pretexto”
- Las tareas de pretexto deben ser complementarias
- Tomemos por ejemplo las tareas de pretexto Posición relativa y Coloración. Podemos aumentar el rendimiento entrenando un modelo para aprender ambas tareas de pretexto como se muestra a continuación:
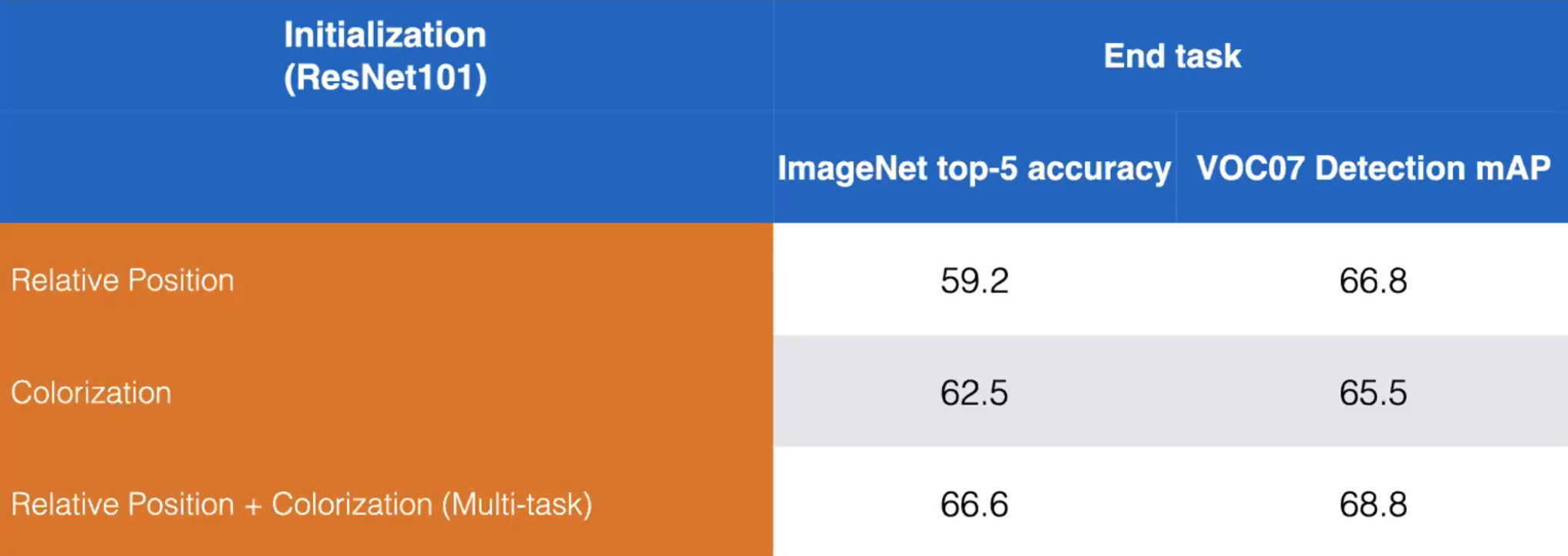
Figura 13: Comparación de entrenamiento disjunto vs. entrenamiento combinado de tareas de pretexto de Posición relativa y Coloración. ResNet101. (Misra)
- Una sola tarea de pretexto puede no ser la respuesta correcta para aprender representaciones auto-supervisadas
- Las tareas de pretexto varían mucho en lo que intentan predecir (en cuanto a la dificultad)
<!– * Relative position is easy since it’s a simple classification
- Masking and fill-in is far harder -> better representation
-
Contrastive methods generate even more info than pretext tasks–>
- La posición relativa es fácil ya que es una clasificación simple
- Enmascarar y rellenar es mucho más difícil -> mejor representación
- Los métodos contrastivos generan incluso más información que las tareas de pretexto
- Pregunta: ¿Cómo entrenamos múltiples tareas de pre-entrenamiento?
<!– * The pretext output will depend on the input. The final fully-connected layer of the network can be swapped depending on the batch type.
-
For example: A batch of black-and-white images is fed to the network in which the model is to produce a coloured image. Then, the final layer is switched, and given a batch of patches to predict relative position.–>
- La salida de pretexto dependerá de la entrada. La capa totalmente conectada final de la red se puede intercambiar según el tipo del batch.
- Por ejemplo: un batch de imágenes en blanco y negro es proporcionado a la red cuyo modelo va a producir una imagen en color. Luego, se cambia la capa final y se le da un batch de parches para predecir la posición relativa.
-
- Pregunta: ¿Cuánto deberíamos entrenar en una tarea de pretexto?
- Regla de oro: Tener una tarea de pretexto muy difícil de tal manera que mejore la tarea posterior.
- En la práctica, la tarea de pretexto está entrenada y no puede volver a entrenarse. En desarrollo, se entrena como parte de todo el proceso.
Escalando el aprendizaje auto-supervisado
Rompecabezas
- Dividir una imagen en varios mosaicos y luego mezclar estos mosaicos. El modelo tiene entonces la tarea de volver a ordenar los mosaicos con la configuración original. (Noorozi & Favaro, 2016)
<!– * Predict which permutation was applied to the input
-
This is done by creating batches of tiles such that each tile of an image is evaluated independently. The convolution output are then concatenated and the permutation is predicted as in figure below–>
- Predecir qué permutación se aplicó a la entrada
- Esto se hace creando batches de mosaicos de modo que cada mosaico de una imagen se evalúe de forma independiente. Luego, la salida de la convolución se concatena y la permutación se predice como en la figura siguiente
-
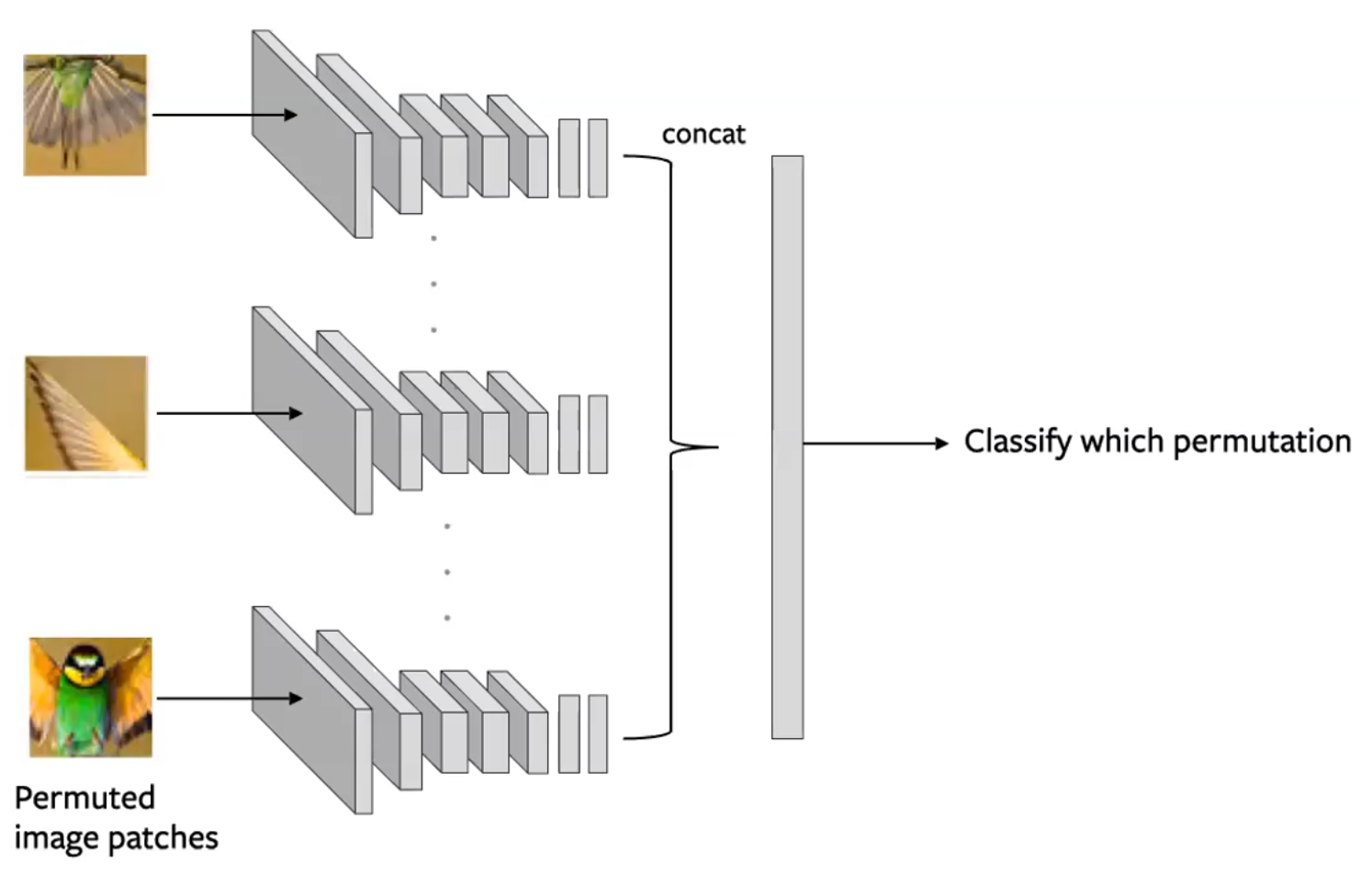
Figura 14: Arquitectura de una red siamesa (Siamese) para una tarea de pretexto de Rompecabezas. Cada mosaico se pasa de forma independiente, con codificaciones concatenadas para predecir una permutación. (Misra)
- Consideraciones:
- Use un subconjunto de permutaciones, es decir, de 9!, use 100
- La red convolucional de n vías utiliza parámetros compartidos
- La complejidad del problema es el tamaño del subconjunto. La cantidad de información a predecir.
- A veces, este método puede funcionar mejor en tareas posteriores que los métodos supervisados, ya que la red es capaz de aprender algunos conceptos sobre la geometría de su entrada.
-
Deficiencias: Few Shot Learning: número limitado de ejemplos de entrenamiento
- Las representaciones auto-supervisadas no son tan eficientes en la muestra
Evaluación: Ajuste (Fine-tuning) vs. Clasificador lineal
Esta forma de evaluación es una especie de Aprendizaje por Transferencia.
- Ajuste (Fine-tuning): cuando la aplicamos a nuestra tarea posterior, usamos toda nuestra red como una inicialización para entrenar una nueva red, actualizando todos los pesos.
- Clasificador lineal: sobre nuestra red de pretexto, entrenamos un pequeño clasificador lineal para realizar nuestra tarea posterior, dejando el resto de la red intacto.
Una buena representación debería transferirse con un poco de entrenamiento.
- Es útil evaluar el aprendizaje de pretexto en múltiples tareas diferentes. Podemos hacerlo extrayendo la representación creada por diferentes capas en la red como características fijas y evaluando su utilidad en estas diferentes tareas.
- Medición: Mean Average Precision (mAP): la precisión promediada en todas las diferentes tareas que estamos considerando.
- Algunos ejemplos de estas tareas incluyen: Detección de objetos (mediante el Ajuste), Estimación normal de la superficie (ver conjunto de datos NYU-v2)
- ¿Qué aprende cada capa?
- Generalmente, a medida que las capas se vuelven más profundas, aumentará el mAP en las tareas posteriores que utilizan sus representaciones.
- Sin embargo, la capa final verá una fuerte caída en el mAP debido a que la capa se vuelve demasiado especializada.
- Esto contrasta con las redes supervisadas, en las que el mAP generalmente siempre aumenta con la profundidad de la capa.
- Esto muestra que la tarea de pretexto no está bien alineada con la tarea posterior.
📝 Aniket Bhatnagar, Dhruv Goyal, Cole Smith, Nikhil Supekar
jcremona
6 Apr 2020