Aplicaciones de las Redes Convolucionales
🎙️ Yann LeCunReconocimiento de Código ZIP
En la clase anterior, demostramos que una red convolucional puede reconocer dígitos, sin embargo, aún queda por saber como el modelo toma cada dígito y evita perturbaciones en los dígitos vecinos. El siguiente paso es detectar objetos que no se traslapen y utilizar el enfoque general de Supresión No-Máxima (NMSNon-Maximum Suppression). Ahora, dada la suposición que la entrada es una serie de dígitos que no se sobreponen, la estrategia es entrenar varias redes convolucionales y utilizar voto por mayoría o tomar los dígitos correspondientes a la puntación más alta generada por la red convolucional.
Reconocimiento con CNN
Aquí presentamos la tarea de reconocimiento de 5 códigos ZIP que no se sobreponen. Al sistema no se le dio instrucciones sobre como separar cada dígito, pero sabe que debe predecir 5 dígitos. El sistema (Figura 1) consiste en 4 redes convolucionales de diferente tamaño, cada una produciendo un conjunto de salidas. La salida es representada en matrices. Las cuatro matrices de salida son de modelos con un ancho de filtro diferente en la última capa. En cada salida, hay 10 filas, representando 10 categorías de 0 a 9. El cuadrado blanco más grande representa una puntuación más alta en esa categoría. En estos cuatro bloques de salida, los tamaños horizontales de las últimas capas filtro son 5,4,3, y 2 respectivamente. El tamaño del filtro decide el ancho de la ventana del modelo que observa la entrada, por lo tanto, cada modelo está prediciendo dígitos basándose en diferentes tamaños de ventana. Luego el modelo toma un voto por mayoría y selecciona la categoría que corresponderá a la puntuación más alta de esa ventana. Para extraer información de utilidad, uno debe tener en cuenta que no todas las combinaciones de caracteres son posibles, por lo tanto, la corrección de errores aprovechando las restricciones de la entrada es de utilidad para asegurarse que las salidas son códigos ZIP verdaderos.

Figura 1: Múltiples clasificadores en el reconocimiento de códigos ZIP
Ahora para ordenar los caracteres, el truco está en utilizar un algoritmo de distancia más corta. Desde que se nos ha dado rangos de caracteres posibles y el número total de dígitos a predecir, podemos afrontar este problema calculando el costo mínimo de producir dígitos y transiciones entre dígito. La ruta tiene que ser continua desde la celda más baja de la izquierda hacia la celda más arriba de la derecha en el grafo, y la ruta está restringida a solo contener movimientos de izquierda a derecha y de abajo hacia arriba. Note que, si el mismo número es repetido uno después de otro, el algoritmo debería ser capaz de distinguir que hay números repetidos en lugar de predecir un solo dígito.
Detección de Rostros
Las redes neuronales convolucionales funcionan bien en tareas de detección y la detección de rostros no es la excepción. Para realizar detección de rostros hemos recopilado un conjunto de datos de imágenes con rostros y sin rostros, en los cuales hemos entrenado una red convolucional con un tamaño de ventana de 30 $\times$ 30 píxeles y le pedimos a la red que nos diga si existe un rostro o no. Una vez entrenada, aplicamos el modelo a una nueva imagen y si hay rostros aproximadamente dentro de una ventana de 30 $\times$ 30 píxeles, la red convolucional activara las salidas en las ubicaciones correspondientes. Sin embargo, dos problemas existen.
- Falsos Positivos: Hay muchas formas de que un pedazo de una imagen no sea un rostro. Durante la etapa de entrenamiento, el modelo podría no ver todo (i.e. un conjunto completamente representativo.) Por lo tanto, el modelo podría sufrir de un montón de falsos positivos en el tiempo de prueba.
- Diferente Tamaño de Rostros: No todos los rostros son de 30 $\times$ 30 píxeles, por lo tanto, rostros de diferentes tamaños podrían no ser detectados. Una forma de manejar este problema es generar versiones multi-escala de la misma imagen. El detector original detectará rostros cerca de 30 $\times$ 30 píxeles. Si aplicamos un escalamiento en la imagen por un factor de $\sqrt 2$, el modelo detectará rostros que son más pequeños en la imagen original ya que lo que eran 30 $\times$ 30 píxeles son ahora aproximadamente20 $\times$ 20 píxeles. Para detectar imágenes más grandes, podemos reducir el tamaño de la imagen. Este proceso no es costoso porque la mitad del costo viene de procesar la imagen original no-escalada. La suma de los costos de todas las otras redes combinadas es casi el mismo que procesar las imágenes originales no-escaladas. El tamaño de la red es el cuadrado del tamaño de la imagen en un lado, por lo tanto, si se reduce la escala de la imagen por $sqrt 2$, la red que necesitarías ejecutar es más pequeña por un factor de 2. Por lo tanto, el costo global es $1+1/2+1/4+1/8+1/16…$, el cual es igual a 2. Ejecutar un modelo multi-escala solo duplica el costo computacional.
Un Sistema de Detección de Rostros Multi-escala

Figura 2: Sistema de detección de rostros
Los mapas mostrados en la (Figura 3) indican las puntuaciones de los detectores de rostro. Este detector de rostros reconoce rostros que son de 20 $\times$ 20 píxeles de tamaño. En la escala-fina (Escala 3) hay varias puntuaciones altas, pero no son muy definitivas. Cuando el factor de escalamiento aumenta (Escala 6), observamos más regiones blancas agrupadas. Esas regiones blancas representan rostros detectados cuando aplicamos supresión no-máximanon-maximum suppression para obtener la ubicación final del rostro.

Figura 3: Puntuaciones del detector de rostros para varios factores de escalamiento
Supresión No-MáximaNon-maximum suppression
Para cada región de alta-puntuación, existe probablemente un rostro por debajo. Si más rostros son detectados muy cerca del primero, significa que solo uno debería ser considerado correcto y el resto son incorrectos. Con supresión no-máxima, tomamos la puntuación más alta de los cuadros delimitadores que se traslapan y eliminamos los otros. El resultado será un solo cuadro delimitador en la ubicación óptima.
Extracción NegativaNegative mining
En la última sección, discutimos como el modelo ejecutará un gran número de falsos positivos en tiempo de prueba como tantas formas para los objetos sean similares a un rostro. Ningún conjunto de entrenamiento incluirá todos los objetos que no sean rostros que parezcan rostros. Podemos mitigar este problema a través de extracción negativanegative mining. En extracción negativanegative mining, creamos un conjunto de datos negativo de regiones de imágenes que no son rostros, que el modelo detecta como rostros. Los datos son recopilados ejecutando el modelo en entradas que se sabe no contienen rostros. Luego reentrenamos el detector utilizando el conjunto de datos negativo. Podemos repetir este proceso para incrementar la robustez de nuestro modelo contra los falsos positivos.
Segmentación Semántica
Segmentación semántica es la tarea de asignar una categoría a cada píxel en una imagen de entrada.
CNN para Visión Robótica Adaptativa de Largo Alcance
En este proyecto, el objetivo fue etiquetar regiones de imágenes de entrada para que un robot pueda distinguir entre caminos y obstáculos. En la figura, las regiones verdes son áreas en las que el robot se puede conducir y las regiones rojas son obstáculos como grama alta. Para entrenar la red para esta tarea, tomamos un pedazo de la imagen y manualmente la etiquetamos como transitable o no (verde o roja). Luego entrenamos la red convolucional en los pedazos de imagen pidiéndole a la red predecir el color del pedazo de imagen. Una vez el sistema este suficientemente entrenado, es aplicado a la imagen completa, etiquetando todas las regiones de la imagen como verde o roja.

Figura 4: CNN para Visión Robótica Adaptativa de Largo Alcance (DARPA LAGR programa 2005-2008)
Existen cinco categorías para la predicción 1) súper verde, 2) verde, 3) purpura: obstáculo a nivel de línea de pie, 4) obstáculo rojo 5) súper rojo: definitivamente un obstáculo.
Etiquetas estéreo (Figura 4, Columna 2) Imágenes son capturadas por las 4 cámaras en el robot, las cuales son agrupadas en 2 pares de visión estéreo. Utilizando las distancias conocidas entre los pares de cámaras estéreo, las posiciones de cada píxel en el espacio 3D son posteriormente estimadas midiendo las distancias relativas entre los píxeles que aparecen en ambas cámaras en un par estéreo. Este es el mismo proceso que nuestro cerebro utiliza para estimar la distancia de los objetos que observamos. Utilizando la información de la posición estimada, un plano es ajustado al suelo, y luego los píxeles son etiquetados como verdes si están cerca del suelo y rojos si están arriba de él.
- Limitaciones y Motivación para la Red Convolucional: La visión estéreo solo funciona hasta 10 metros y conducir un robot requiere una visión de largo alcance. Una Red Convolucional sin embargo, es capaz de detectar objetos a muchas más grandes distancias, si es entrenada correctamente.

Figura 5: Pirámide invariante a la escala de imágenes con distancia normalizadaScale-invariant Pyramid of Distance-normalized Images
- Entregadas como Entradas del Modelo: Un pre-procesamiento importante incluye construir una pirámide invariante a la escala de imágenes con distancia normalizada (Figura 5). Esto es similar a lo que realizamos anteriormente en esta clase cuando intentamos detectar rostros de múltiples escalas.
Salidas del Modelo (Figura 4, Columna 3)
El modelo entrega como salidas una etiqueta para cada píxel en la imagen hasta el horizonte. Estas son las salidas una red convolucional clasificadora multi-escala.
- Como el Modelo se Vuelve Adaptativo: Los robots tienen acceso continuo a las etiquetas estéreo, permitiéndole a la red reentrenarse, adaptándose al nuevo ambiente en el que se encuentra. Por favor note que solo la última capa de la red habrá sido re-entrenada. Las capas previas son entrenadas y fijadas en el laboratorio.
Rendimiento del Sistema
Cuando se está intentando obtener una coordenada GPS en el otro lado de una barrera, el robot “observo” la barrera desde muy lejos y planificó una ruta que la evita. Esto es gracias a la CNN detectando objetos hasta 50-100m lejos.
Limitación
Anteriormente en los 2000s, los recursos de computación eran restringidos. El robot era capaz de procesar cerca de 1 cuadro por segundo, lo que significaba que no podría ser capaz de detectar a una persona que camina en su trayectoria por un segundo completo antes de ser capaz de reaccionar. La solución para esta limitación es un modelo de Odometría Visual de Bajo Costo. No está basado en redes neuronales, tiene una visión de ~2.5m, pero reacciona rápidamente.
Análisis de la escenaScene Parsing y Etiquetado
En esta tarea, el modelo entrega en la salida una categoría de objeto (edificios, carros, cielo, etc.) para cada píxel. La arquitectura es también multi-escala (figura 6).
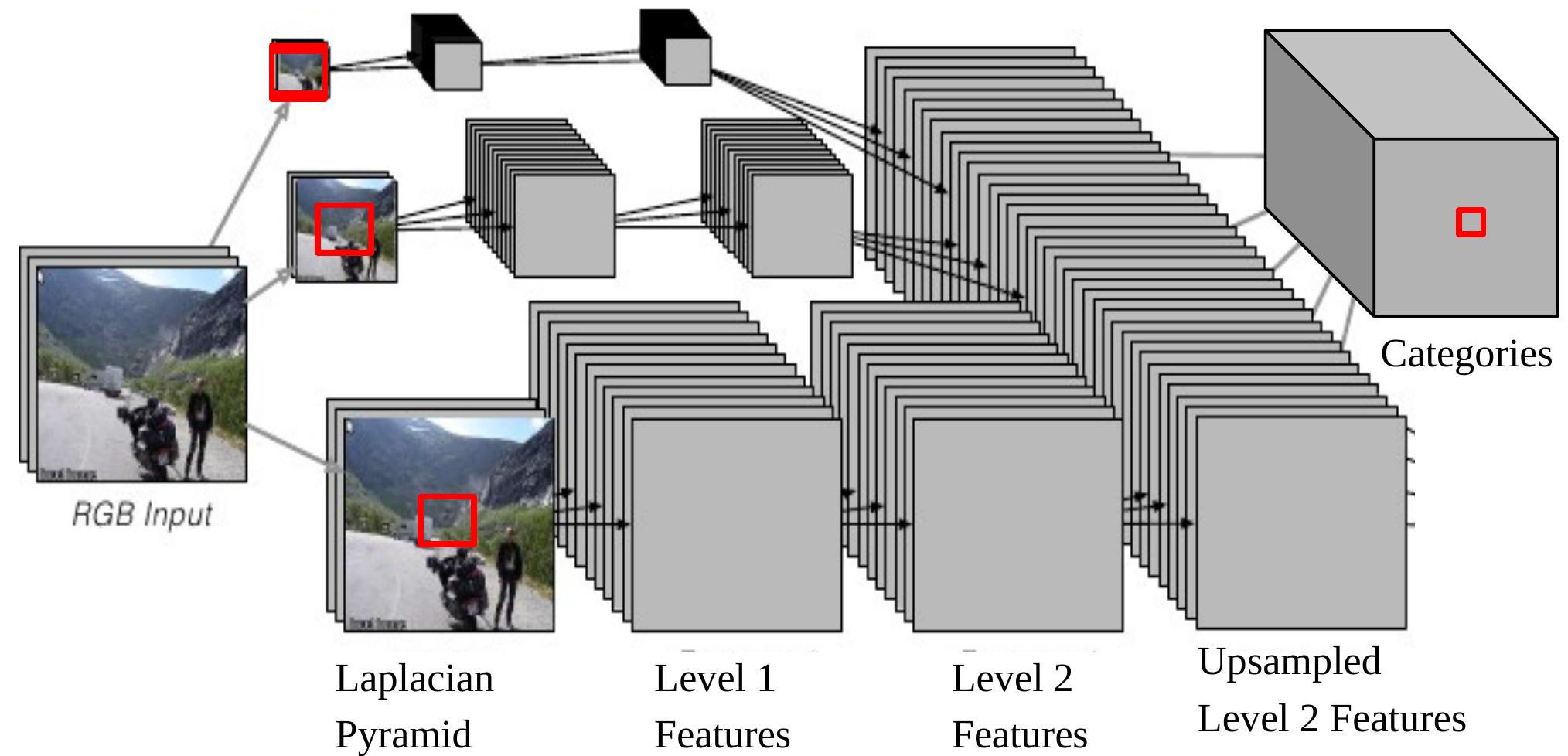
Figura 6: CNN multi-escala para análisis de escena
Nótese que si retro-proyectamos una salida de la CNN en la entrada, esta corresponderá a una ventana de entrada de tamaño $46\times46$ en la imagen original en la parte más baja de la Pirámide Laplaciana. Esto significa que estamos utilizando el contexto de $46\times46$ píxeles para decidir la categoría del píxel central.
Sin embargo, algunas veces este tamaño de contexto no es suficiente para determinar la categoría para objetos grandes. El enfoque multi-escala permite una visión más amplia suministrando imágenes adicionales re-escaladas como entradas. Los pasos son los siguientes:
- Tomar la misma imagen, reducirla por un factor de 2 y un factor de 4, separadamente.
- Estas dos imágenes re-escaladas adicionales alimentan la misma Red Convolucional (mismos pesos, mismos filtros) y obtenemos otros dos conjuntos de características de Nivel 2.
- Sobre-muestrearUpsample estas características para que ellas tengan el mismo tamaño que las Características de Nivel 2 de la imagen original.
- Apilar los tres conjuntos de características (sobre-muestreadas) todos juntos y alimentar al clasificador con ellas.
Ahora el tamaño más largo efectivo de contenido, el cual es del 1/4 de la imagen modificada en tamaño, es $184\times 184\, (46\times 4=184)$.
Rendimiento: Sin procesamiento posterior y ejecutando cuadro-por-cuadro, el modelo se ejecuta muy rápidamente incluso en hardware estándar. Tiene un tamaño pequeño de datos de entrenamiento (2k~3k), pero aun así los resultados son rompe récords.
📝 Shiqing Li, Chenqin Yang, Yakun Wang, Jimin Tan
Victor Peñaloza
2 Mar 2020